Compositional Skill Routing for LLM Agents: Decompose, Retrieve, and Compose
Pith reviewed 2026-06-27 00:34 UTC · model grok-4.3
The pith
Iterative skill-aware decomposition raises accuracy from 51% to 67.7% for routing complex queries to multiple LLM skills.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
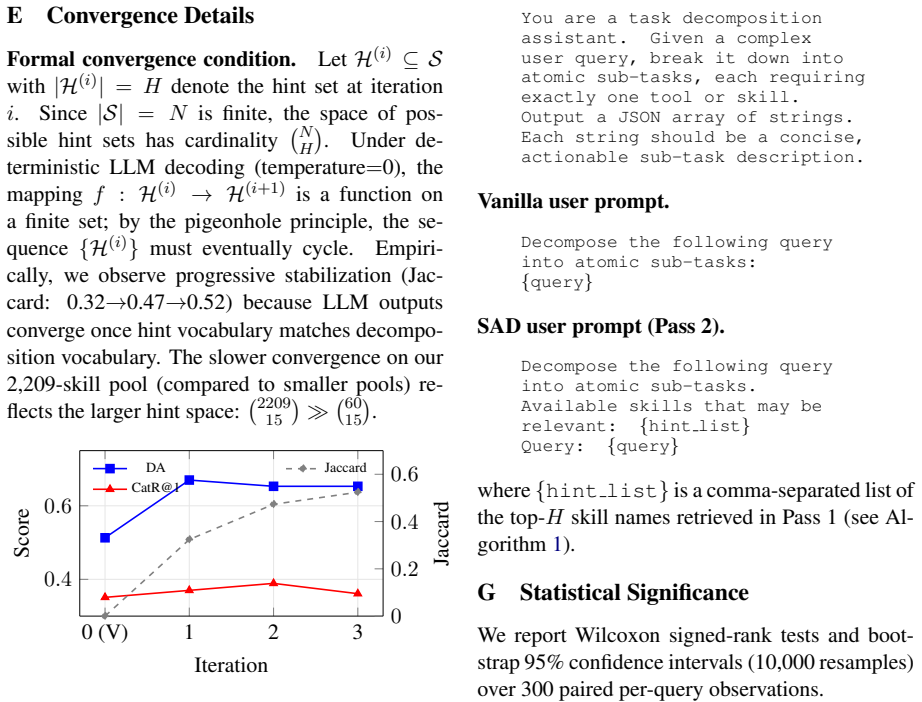
Task decomposition quality is the primary bottleneck in compositional skill routing, and Iterative Skill-Aware Decomposition improves decomposition accuracy from 51.0 percent to 67.7 percent in a single iteration by iteratively aligning sub-tasks with the skills present in the library.
What carries the argument
Iterative Skill-Aware Decomposition (SAD), a retrieval-augmented feedback loop that uses retrieved skills to refine the LLM's task decomposition.
If this is right
- When decomposition reaches correct granularity, category recall at retrieval rises from 34 percent to 41 percent.
- SkillWeaver reduces context window consumption by over 99 percent compared with direct prompting.
- The gains transfer to skill categories absent from the retrieval pool, yielding a 35.6 percent relative improvement in decomposition accuracy.
Where Pith is reading between the lines
- The same feedback loop could be applied to other agent frameworks that already maintain large tool libraries.
- Running more than one iteration of SAD might produce further gains if the marginal improvement curve is measured.
- Replacing the static benchmark with live, changing skill sets would test whether the reported generalization holds under distribution shift.
Load-bearing premise
Correct task granularity is required before retrieval can succeed, and the benchmark queries and skill library reflect the compositional demands that arise in practice.
What would settle it
An end-to-end evaluation in which high decomposition accuracy fails to produce better executable plans on tasks drawn from a different skill ecosystem would show that decomposition quality is not the primary bottleneck.
Figures

read the original abstract
LLM agents increasingly rely on external skills -- reusable tool specifications -- but real-world tasks often require composing multiple skills, not just selecting one. We formalize this as the Compositional Skill Routing problem: given a complex user query and a large skill library, decompose the query into atomic sub-tasks, retrieve the appropriate skill for each sub-task, and compose an executable plan. We present SkillWeaver, a decompose-retrieve-compose framework combining an LLM task decomposer, a bi-encoder skill retriever with FAISS indexing, and a dependency-aware DAG planner. To support evaluation, we introduce CompSkillBench, a benchmark of 300 compositional queries over 2,209 real MCP server skills spanning 24 functional categories, sourced from the public MCP ecosystem. Our experiments reveal that task decomposition quality is the primary bottleneck: standard LLM decomposition reaches only 34.2% category recall at the step level. To address this, we propose Iterative Skill-Aware Decomposition (SAD), a retrieval-augmented feedback loop that iteratively aligns decomposition with available skills. SAD improves decomposition accuracy from 51.0% to 67.7% (+32.7%, Wilcoxon p < 10^-6) in a single iteration; DA-conditioned analysis confirms that correct granularity is the prerequisite for effective retrieval (CatR@1 rises from 34% to 41% when DA=1). SkillWeaver reduces context window consumption by over 99%, and transfer experiments confirm generalization (+35.6% relative DA gain even when target categories are absent from the retrieval pool).
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper formalizes the Compositional Skill Routing problem for LLM agents and introduces SkillWeaver, a decompose-retrieve-compose framework using an LLM task decomposer, bi-encoder retriever with FAISS, and dependency-aware DAG planner. It presents CompSkillBench (300 queries over 2,209 MCP skills in 24 categories) and proposes Iterative Skill-Aware Decomposition (SAD) to address decomposition bottlenecks. Key claims include SAD raising decomposition accuracy from 51.0% to 67.7% (+32.7%, Wilcoxon p < 10^-6), >99% context reduction, and +35.6% relative DA gain on unseen categories, with DA=1 shown as prerequisite via conditioned analysis (CatR@1 34%→41%).
Significance. If the empirical claims hold after addressing gaps in experimental detail, the work would provide a practical framework and benchmark for compositional tool use in agents, highlighting decomposition as the primary bottleneck and demonstrating substantial efficiency gains. The introduction of a benchmark grounded in real MCP skills and the use of a statistical test are positive elements that could support follow-on research.
major comments (3)
- [Abstract] Abstract: The central claim of SAD improving decomposition accuracy from 51.0% to 67.7% lacks any definition of the accuracy metric, description of how the 51.0% baseline was obtained, or details on error bars/variance; this directly undermines evaluation of the reported +32.7% lift and Wilcoxon test.
- [Abstract] Abstract (DA-conditioned analysis): The statement that correct granularity (DA=1) is a prerequisite for effective retrieval rests on a correlational observation (CatR@1 rising from 34% to 41%) without controls for confounders such as query phrasing or skill-description overlap, nor any causal isolation experiment.
- [Abstract] Abstract (CompSkillBench): No information is supplied on sampling method for the 300 queries, how ground-truth decompositions were created, or inter-annotator agreement; these omissions make it impossible to assess whether the benchmark supports the representativeness assumption underlying all transfer and generalization claims.
minor comments (1)
- [Abstract] Abstract: The abbreviation 'DA' appears in 'DA-conditioned analysis' and 'DA gain' without an explicit first-use definition or expansion.
Simulated Author's Rebuttal
Thank you for your detailed and constructive review. We appreciate the identification of omissions in the abstract that affect clarity and interpretability. We will revise the abstract to incorporate definitions, baseline descriptions, benchmark construction details, and more cautious phrasing for the analysis. Our point-by-point responses are below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of SAD improving decomposition accuracy from 51.0% to 67.7% lacks any definition of the accuracy metric, description of how the 51.0% baseline was obtained, or details on error bars/variance; this directly undermines evaluation of the reported +32.7% lift and Wilcoxon test.
Authors: We agree the abstract requires additional context. Decomposition accuracy is the fraction of steps where both granularity (DA=1) and category match the ground truth. The 51.0% baseline is the performance of a standard LLM decomposer without SAD's retrieval-augmented iteration. Error bars appear in the main results (Table 2), and the Wilcoxon test was applied to paired per-query differences. We will add a concise definition and baseline description to the revised abstract. revision: yes
-
Referee: [Abstract] Abstract (DA-conditioned analysis): The statement that correct granularity (DA=1) is a prerequisite for effective retrieval rests on a correlational observation (CatR@1 rising from 34% to 41%) without controls for confounders such as query phrasing or skill-description overlap, nor any causal isolation experiment.
Authors: We acknowledge the analysis is correlational and does not include explicit controls or causal experiments. The conditioned results demonstrate a clear association between DA=1 and improved CatR@1. We will revise the abstract to use more cautious language such as 'empirical evidence indicates' and add a limitations discussion in the main text noting potential confounders like query phrasing. A dedicated causal isolation study is beyond the current scope but noted as future work. revision: partial
-
Referee: [Abstract] Abstract (CompSkillBench): No information is supplied on sampling method for the 300 queries, how ground-truth decompositions were created, or inter-annotator agreement; these omissions make it impossible to assess whether the benchmark supports the representativeness assumption underlying all transfer and generalization claims.
Authors: We agree these details are necessary. The queries were sampled for compositional diversity across the 24 categories from the public MCP ecosystem; ground-truth decompositions were produced by experts with MCP skill knowledge; and inter-annotator agreement was assessed via Cohen's kappa. We will add a brief summary of the benchmark construction process to the revised abstract. revision: yes
Circularity Check
No circularity; claims rest on external benchmark measurements
full rationale
The paper's central claims (SAD accuracy lift 51.0%→67.7%, SkillWeaver context reduction and generalization gains) are empirical measurements on the introduced CompSkillBench (300 queries, 2209 skills) with reported Wilcoxon p-values. No equations, fitted parameters renamed as predictions, or self-citation chains appear in the abstract or described framework. The derivation chain consists of standard decompose-retrieve-compose steps evaluated against an external benchmark rather than reducing to inputs by construction. This matches the default expectation of no significant circularity.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
Toolformer: Language Models Can Teach Themselves to Use Tools , author=. Advances in Neural Information Processing Systems , volume=
-
[3]
Proceedings of the 41st International Conference on Machine Learning , year=
Gorilla: Large Language Model Connected with Massive APIs , author=. Proceedings of the 41st International Conference on Machine Learning , year=
-
[5]
2024 , note=
Model Context Protocol , author=. 2024 , note=
2024
-
[6]
2025 , note=
Agent Skills Specification , author=. 2025 , note=
2025
-
[7]
Advances in Neural Information Processing Systems , volume=
ToolkenGPT: Augmenting Frozen Language Models with Massive Tools via Tool Embeddings , author=. Advances in Neural Information Processing Systems , volume=
-
[8]
Proceedings of the 39th International Conference on Machine Learning , year=
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents , author=. Proceedings of the 39th International Conference on Machine Learning , year=
-
[9]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models , author=. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year=
-
[10]
Advances in Neural Information Processing Systems , volume=
Chain-of-Thought Prompting Elicits Reasoning in Large Language Models , author=. Advances in Neural Information Processing Systems , volume=
-
[12]
Proceedings of the International Conference on Learning Representations , year=
ReAct: Synergizing Reasoning and Acting in Language Models , author=. Proceedings of the International Conference on Learning Representations , year=
-
[13]
Advances in Neural Information Processing Systems , volume=
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. Advances in Neural Information Processing Systems , volume=
-
[15]
Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year=
Dense Passage Retrieval for Open-Domain Question Answering , author=. Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing , year=
2020
-
[16]
Findings of the Association for Computational Linguistics: ACL 2022 , year=
Sentence-T5: Scalable Sentence Encoders from Pre-trained Text-to-Text Models , author=. Findings of the Association for Computational Linguistics: ACL 2022 , year=
2022
-
[18]
IEEE Transactions on Big Data , volume=
Billion-scale similarity search with GPUs , author=. IEEE Transactions on Big Data , volume=
-
[20]
The Llama 3 Herd of Models , author=. arXiv preprint arXiv:2407.21783 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[21]
Mistral 7B , author=. arXiv preprint arXiv:2310.06825 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[23]
arXiv preprint arXiv:2408.04682 , year=
ToolSandbox: A Stateful, Conversational, Interactive Evaluation Framework for LLM Tool Use Capabilities , author=. arXiv preprint arXiv:2408.04682 , year=
-
[24]
Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
API-Bank: A Comprehensive Benchmark for Tool-Augmented LLMs , author=. Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing , year=
2023
-
[25]
arXiv preprint arXiv:2310.03128 , year=
MetaTool Benchmark for Large Language Models: Deciding Whether to Use Tools and Which to Use , author=. arXiv preprint arXiv:2310.03128 , year=
-
[26]
Proceedings of the International Conference on Learning Representations , year=
CRAFT: Customizing LLMs by Creating and Retrieving from Specialized Toolsets , author=. Proceedings of the International Conference on Learning Representations , year=
-
[27]
Advances in Neural Information Processing Systems , volume=
ToolQA: A Dataset for LLM Question Answering with External Tools , author=. Advances in Neural Information Processing Systems , volume=
-
[28]
Proceedings of the International Conference on Learning Representations , year=
Decomposed Prompting: A Modular Approach for Solving Complex Tasks , author=. Proceedings of the International Conference on Learning Representations , year=
-
[29]
Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
Measuring and Narrowing the Compositionality Gap in Language Models , author=. Findings of the Association for Computational Linguistics: EMNLP 2023 , year=
2023
-
[30]
arXiv preprint arXiv:2403.12881 , year=
AgentFlan: Designing Data and Methods of Effective Agent Tuning for Large Language Models , author=. arXiv preprint arXiv:2403.12881 , year=
-
[31]
arXiv preprint arXiv:2308.03427 , year=
TPTU: Task Planning and Tool Usage of Large Language Model-based AI Agents , author=. arXiv preprint arXiv:2308.03427 , year=
-
[35]
Advances in Neural Information Processing Systems , volume=
HuggingGPT: Solving AI Tasks with ChatGPT and its Friends in Hugging Face , author=. Advances in Neural Information Processing Systems , volume=
-
[36]
Asai, Akari and Wu, Zeqiu and Wang, Yizhong and Sil, Avirup and Hajishirzi, Hannaneh , booktitle=. Self-
-
[37]
2023 , howpublished=
Plan-and-Execute Agents , author=. 2023 , howpublished=
2023
-
[38]
Anthropic . 2024. Model context protocol. Https://modelcontextprotocol.io/
2024
-
[39]
Anthropic . 2025. Agent skills specification. Https://docs.anthropic.com/en/docs/agents-and-tools/agent-skills
2025
-
[40]
Akari Asai, Zeqiu Wu, Yizhong Wang, Avirup Sil, and Hannaneh Hajishirzi. 2024. Self- RAG : Learning to retrieve, generate, and critique through self-reflection. In Proceedings of the International Conference on Learning Representations
2024
- [41]
-
[42]
Shibo Hao, Tianyang Liu, Zhen Wang, and Zhiting Hu. 2024. Toolkengpt: Augmenting frozen language models with massive tools via tool embeddings. Advances in Neural Information Processing Systems, 36
2024
-
[43]
Wenlong Huang, Pieter Abbeel, Deepak Pathak, and Igor Mordatch. 2022. Language models as zero-shot planners: Extracting actionable knowledge for embodied agents. In Proceedings of the 39th International Conference on Machine Learning
2022
-
[44]
Jeff Johnson, Matthijs Douze, and Herv \'e J \'e gou. 2019. Billion-scale similarity search with gpus. IEEE Transactions on Big Data, 7(3):535--547
2019
-
[45]
Vladimir Karpukhin, Barlas Oguz, Sewon Min, Patrick Lewis, Ledell Wu, Sergey Edunov, Danqi Chen, and Wen-tau Yih. 2020. Dense passage retrieval for open-domain question answering. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing
2020
-
[46]
Tushar Khot, Harsh Trivedi, Matthew Finlayson, Yao Fu, Kyle Richardson, Peter Clark, and Ashish Sabharwal. 2023. Decomposed prompting: A modular approach for solving complex tasks. In Proceedings of the International Conference on Learning Representations
2023
-
[47]
LangChain . 2023. Plan-and-execute agents. https://blog.langchain.dev/planning-agents/. Multi-step planning agents that decouple high-level planning from per-step execution
2023
-
[48]
Minghao Li, Feifan Song, Bowen Yu, Haiyang Yu, and 1 others. 2023. Api-bank: A comprehensive benchmark for tool-augmented llms. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing
2023
- [49]
-
[50]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2024. Gorilla: Large language model connected with massive apis. In Proceedings of the 41st International Conference on Machine Learning
2024
- [51]
-
[52]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others. 2023. Toolllm: Facilitating large language models to master 16000+ real-world apis. arXiv preprint arXiv:2307.16789
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[53]
Qwen Team . 2024. Qwen2.5 technical report. arXiv preprint arXiv:2412.15115
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[54]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in Neural Information Processing Systems, 36
2023
-
[55]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023 a . Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36
2023
- [56]
-
[57]
Noah Shinn, Federico Cassano, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. 2023. Reflexion: Language agents with verbal reinforcement learning. Advances in Neural Information Processing Systems, 36
2023
-
[58]
Lei Wang, Wanyu Xu, Yihuai Lan, Zhiqiang Hu, Yunshi Lan, Roy Ka-Wei Lee, and Ee-Peng Lim. 2023. Plan-and-solve prompting: Improving zero-shot chain-of-thought reasoning by large language models. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics
2023
- [59]
-
[60]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed Chi, Quoc V Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in Neural Information Processing Systems, 35
2022
-
[61]
Shitao Xiao, Zheng Liu, Peitian Zhang, and Niklas Muennighoff. 2024. C-pack: Packaged resources to advance general chinese embedding. arXiv preprint arXiv:2309.07597
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[62]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2023. React: Synergizing reasoning and acting in language models. In Proceedings of the International Conference on Learning Representations
2023
-
[63]
Lifan Yuan, Yangyi Chen, Xingyao Wang, and 1 others. 2025. Craft: Customizing llms by creating and retrieving from specialized toolsets. In Proceedings of the International Conference on Learning Representations
2025
- [64]
-
[65]
Denny Zhou, Nathanael Sch \"a rli, Le Hou, Jason Wei, Nathan Scales, Xuezhi Wang, Dale Schuurmans, Claire Cui, Olivier Bousquet, Quoc Le, and Ed Chi. 2022. Least-to-most prompting enables complex reasoning in large language models. arXiv preprint arXiv:2205.10625
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[66]
Yuchen Zhuang, Yue Yu, Kuan Wang, Haotian Sun, and Chao Zhang. 2024. Toolqa: A dataset for llm question answering with external tools. Advances in Neural Information Processing Systems, 36
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.