Volterra Generative Models
Pith reviewed 2026-06-27 01:19 UTC · model grok-4.3
The pith
Volterra generative models inject path-dependent noise via fractional kernels into score-based diffusion while approximating the resulting non-Markovian dynamics with finite Markovian lifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Volterra generative models are a continuous-time score-based framework in which the forward process injects path-dependent noise through fractional kernels. Finite-dimensional Markovian lifts are constructed via Gaussian quadrature in both regimes and a hybrid finite-difference exponential approximation in the smooth regime to handle the non-Markovian and non-semimartingale dynamics. Squared error bounds are proved, an augmented linear-Gaussian forward process is derived, and learning remains data-dimensional through residual states and analytic auxiliary Gaussian scores. Covariance and reverse-time degeneracies from shared Brownian factors and signed weights are identified, motivating stabi
What carries the argument
Finite-dimensional Markovian lifts of the non-Markovian dynamics induced by fractional kernels, constructed using Gaussian quadrature or hybrid finite-difference exponential approximation.
If this is right
- The approximations achieve controlled squared error bounds.
- An augmented linear-Gaussian forward process is obtained for the lifted system.
- Learning can remain in the data dimension using residual states and analytic auxiliary Gaussian scores.
- Persistent fractional perturbations with small lifts improve score-based generation on MNIST and extend promisingly to natural images.
- Stabilized conditioning and Gaussian-bridge samplers address degeneracies in larger lifts.
Where Pith is reading between the lines
- If the path-dependent noise truly captures long-memory effects better than Markovian alternatives, similar lifts could apply to time-series forecasting or video generation tasks.
- The Gaussian quadrature approach might extend to other kernel-based non-Markovian processes beyond fractional ones.
- Testing on datasets with explicit long-range temporal dependencies would clarify when the fractional kernel provides gains over standard diffusion.
Load-bearing premise
The path-dependent noise from fractional kernels can be effectively captured by low-dimensional Markovian lifts without losing the generative benefits or requiring high-dimensional state spaces.
What would settle it
Running the models with increasing lift dimensions on MNIST and observing whether generation quality plateaus or degrades after a small number of dimensions would test if the approximation preserves the intended advantages.
Figures



read the original abstract
Score-based diffusion models typically use Brownian perturbations, which provide tractable reverse-time dynamics but impose memoryless noising. We introduce Volterra generative models, a continuous-time score-based framework whose forward process injects path-dependent noise through fractional kernels. To handle the non-Markovian and non-semimartingale dynamics, we construct finite-dimensional Markovian lifts using Gaussian quadrature in both regimes and a hybrid finite-difference exponential approximation in the smooth regime. We prove squared error bounds, derive an augmented linear-Gaussian forward process, and show that the learning can remain data-dimensional by considering residual states and analytic auxiliary Gaussian scores. We also identify covariance and reverse-time degeneracies caused by shared Brownian factors and signed smooth-regime weights. The degeneracy motivates stabilized conditioning and, for stiff larger lifts, a Gaussian-bridge reconstruction sampler. Experiments on MNIST and CIFAR-10 show that persistent fractional perturbations with small Markovian lifts can improve score-based generation on MNIST and provide a promising extension to natural images, while the bridge sampler provides a stability mechanism for larger lifts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Volterra generative models, a score-based diffusion framework that replaces standard Brownian forward processes with fractional-kernel Volterra processes to inject path-dependent noise. Non-Markovian dynamics are handled via finite-dimensional Markovian lifts (Gaussian quadrature in both regimes, hybrid finite-difference exponential in the smooth regime), with proved squared-error bounds, an augmented linear-Gaussian forward process, residual states to keep learning data-dimensional, and analytic auxiliary Gaussian scores. Covariance and reverse-time degeneracies from shared Brownian drivers and signed weights are identified and mitigated by conditioned scores and a Gaussian-bridge reconstruction sampler. Experiments on MNIST and CIFAR-10 report that small-lift persistent fractional perturbations improve generation quality over Brownian baselines on MNIST and show promise on natural images.
Significance. If the lift approximations preserve exploitable memory effects after substitution into the reverse SDE, the framework offers a concrete route to incorporate long-range temporal dependencies into continuous-time score-based models without inflating data dimensionality. The explicit squared-error bounds on the lifts, the linear-Gaussian augmentation, and the degeneracy-stabilization techniques constitute technical contributions that could be reused in other non-Markovian generative settings.
major comments (2)
- [Abstract / reverse-process derivation] Abstract and the section deriving the reverse process: squared-error bounds are stated for the forward-process lifts, yet no quantitative propagation of these bounds through the score-matching objective or the reverse SDE is supplied; without such propagation it remains unclear whether the controlled forward approximation error preserves the claimed path-dependent generation benefit once the score network is trained.
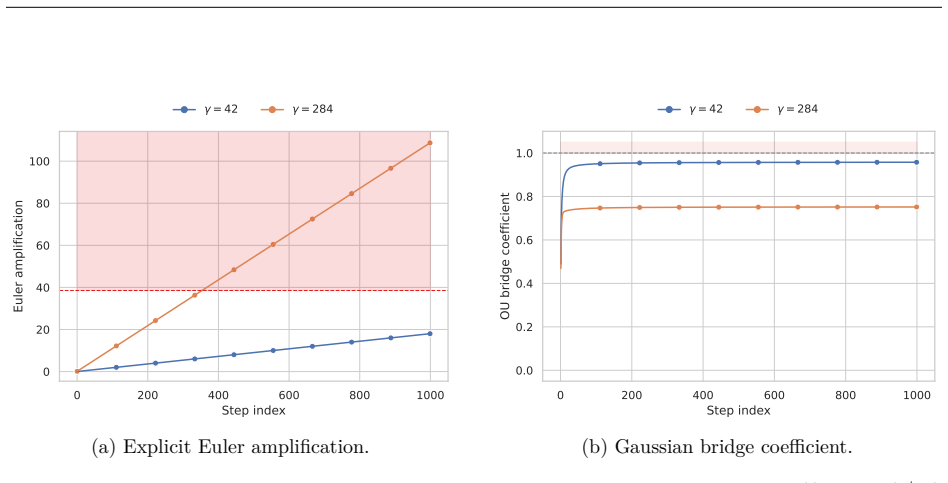
- [Degeneracy and stabilization section] The degeneracy analysis (shared Brownian factors and signed smooth-regime weights) correctly flags potential covariance collapse, but the proposed stabilizations (conditioned scores, Gaussian-bridge sampler) are presented without ablation that isolates their contribution to the reported MNIST/CIFAR-10 gains versus a plain Brownian baseline.
minor comments (2)
- [Lift construction] The description of the hybrid finite-difference exponential approximation would benefit from an explicit statement of the quadrature nodes and the truncation order used in the experiments.
- [Experiments] Table or figure reporting the lift dimension versus FID or inception score on MNIST would make the claim that 'small Markovian lifts' suffice more precise.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments below, agreeing where the manuscript is incomplete and outlining specific revisions.
read point-by-point responses
-
Referee: [Abstract / reverse-process derivation] Abstract and the section deriving the reverse process: squared-error bounds are stated for the forward-process lifts, yet no quantitative propagation of these bounds through the score-matching objective or the reverse SDE is supplied; without such propagation it remains unclear whether the controlled forward approximation error preserves the claimed path-dependent generation benefit once the score network is trained.
Authors: We agree that the manuscript currently supplies squared-error bounds only on the forward lifts and does not propagate these bounds through the score-matching loss or the reverse SDE. This omission leaves open the question of whether the path-dependent benefit survives the approximation once the score network is trained. In the revised manuscript we will add a dedicated subsection that (i) recalls the forward squared-error bound, (ii) invokes standard Lipschitz and growth assumptions on the score network, and (iii) derives an explicit upper bound on the KL divergence (or total-variation distance) between the law of the true Volterra reverse process and the law of the lifted reverse process. The new bound will be stated in terms of the lift error, the time horizon, and the score-network Lipschitz constant, thereby quantifying the preservation of the fractional memory effect. revision: yes
-
Referee: [Degeneracy and stabilization section] The degeneracy analysis (shared Brownian factors and signed smooth-regime weights) correctly flags potential covariance collapse, but the proposed stabilizations (conditioned scores, Gaussian-bridge sampler) are presented without ablation that isolates their contribution to the reported MNIST/CIFAR-10 gains versus a plain Brownian baseline.
Authors: The referee is correct that the current experiments do not isolate the contribution of the conditioned-score and Gaussian-bridge stabilizations via controlled ablations against the Brownian baseline. While the degeneracy analysis itself is self-contained, the performance claims would be stronger with such ablations. We will therefore add a new experimental subsection containing (a) a direct comparison of the full stabilized Volterra model against the same model run without conditioned scores and without the bridge sampler, and (b) the corresponding FID / IS numbers relative to the plain Brownian baseline on both MNIST and CIFAR-10. These tables will make the incremental benefit of each stabilization explicit. revision: yes
Circularity Check
No significant circularity detected
full rationale
The paper's core contributions consist of new constructions (finite-dimensional Markovian lifts via Gaussian quadrature or hybrid finite-difference exponential approximation), proved squared-error bounds on those lifts, an augmented linear-Gaussian forward process, and residual-state techniques that keep learning data-dimensional. None of these steps reduce by the paper's own equations or self-citations to previously fitted quantities or to the target generative claim itself. The abstract and described derivation chain are self-contained against external benchmarks; the cited degeneracies are identified and addressed with new stabilizations rather than assumed away. This is the normal case of an independent technical development.
Axiom & Free-Parameter Ledger
free parameters (1)
- Markovian lift dimension
axioms (1)
- standard math Gaussian quadrature yields controlled approximations to the fractional integrals defining the Volterra kernel
invented entities (2)
-
Volterra generative model
no independent evidence
-
Gaussian-bridge reconstruction sampler
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Ren, Zhiyao and Zhan, Yibing and Ding, Liang and Wang, Gaoang and Wang, Chaoyue and Fan, Zhongyi and Tao, Dacheng , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , doi =
2024
-
[2]
Proceedings of the AAAI Conference on Artificial Intelligence , volume =
Zhou, Shengzhe and Li, Zejian and Zhang, Shengyuan and Hou, Lefan and Yang, Changyuan and Yang, Guang and Yang, Zhiyuan and Sun, Lingyun , title =. Proceedings of the AAAI Conference on Artificial Intelligence , volume =. 2024 , doi =
2024
-
[3]
Proceedings of the 40th International Conference on Machine Learning , series =
Xu, Yilun and Liu, Ziming and Tian, Yonglong and Tong, Shangyuan and Tegmark, Max and Jaakkola, Tommi , title =. Proceedings of the 40th International Conference on Machine Learning , series =. 2023 , publisher =
2023
-
[4]
Bernstein Functions: Theory and Applications , edition =
Schilling, Ren. Bernstein Functions: Theory and Applications , edition =
-
[5]
Proceedings of the 37th International Conference on Machine Learning , series =
Zhang, Zhisheng and Xie, Yuting and Yang, Lin , title =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[6]
The Missing
Sergio Calvo Ordo. The Missing. Transactions on Machine Learning Research , issn=. 2024 , url=
2024
-
[7]
Neural Computing and Applications , volume=
Ganetic loss for generative adversarial networks with a focus on medical applications , author=. Neural Computing and Applications , volume=. 2025 , publisher=
2025
-
[8]
9th International Conference on Learning Representations,
Jiaming Song and Chenlin Meng and Stefano Ermon , title =. 9th International Conference on Learning Representations,
-
[9]
and Welsch, John H
Golub, Gene H. and Welsch, John H. , title =. Mathematics of Computation , volume =. 1969 , doi =
1969
-
[10]
Score-Based Generative Modeling through Stochastic Differential Equations
Score-based generative modeling through stochastic differential equations , author=. arXiv preprint arXiv:2011.13456 , year=
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[11]
Conditional
Stratonovich, Ruslan Leont’evich , booktitle=. Conditional. 1965 , publisher=
1965
-
[12]
Stochastic Processes and their Applications , volume=
Reverse-time diffusion equation models , author=. Stochastic Processes and their Applications , volume=. 1982 , publisher=
1982
-
[13]
Time reversal on
F. Time reversal on. Stochastic Processes—Mathematics and Physics: Proceedings of the 1st BiBoS-Symposium held in Bielefeld, West Germany, September 10--15, 1984 , pages=. 2006 , organization=
1984
-
[14]
Journal of Machine Learning Research , volume=
Estimation of non-normalized statistical models by score matching , author=. Journal of Machine Learning Research , volume=
-
[15]
Uncertainty in artificial intelligence , pages=
Sliced score matching: A scalable approach to density and score estimation , author=. Uncertainty in artificial intelligence , pages=. 2020 , organization=
2020
-
[16]
Fractional
Carmona, Philippe and Coutin, Laure , journal=. Fractional
-
[17]
Approximation of Stochastic
Alfonsi, Aur. Approximation of Stochastic. Mathematics of Computation , volume=
-
[18]
Markovian approximations of stochastic
Bayer, Christian and Breneis, Simon , journal=. Markovian approximations of stochastic. 2023 , publisher=
2023
-
[19]
2011 , publisher=
Quadrature Theory: The Theory of Numerical Integration on a Compact Interval , author=. 2011 , publisher=
2011
-
[20]
Stochastic Processes and their Applications , volume=
Affine representations of fractional processes with applications in mathematical finance , author=. Stochastic Processes and their Applications , volume=. 2019 , publisher=
2019
-
[21]
Advances in Neural Information Processing Systems , volume=
Generative fractional diffusion models , author=. Advances in Neural Information Processing Systems , volume=
-
[22]
Numerical integration
Brass, H and H. Numerical integration. 1993 , publisher=
1993
-
[23]
On the maxima and minima of
Lehmer, Derrick H , journal=. On the maxima and minima of. 1940 , publisher=
1940
-
[24]
Advances in neural information processing systems , volume=
Denoising diffusion probabilistic models , author=. Advances in neural information processing systems , volume=
-
[25]
Advances in Neural Information Processing Systems , volume=
Generative modeling by estimating gradients of the data distribution , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Fractional
Mandelbrot, Benoit B and Van Ness, John W , journal=. Fractional. 1968 , publisher=
1968
-
[27]
Quantitative Finance , volume=
Volatility is rough , author=. Quantitative Finance , volume=. 2018 , publisher=
2018
-
[28]
International Conference on Medical image computing and computer-assisted intervention , pages=
U-net: Convolutional networks for biomedical image segmentation , author=. International Conference on Medical image computing and computer-assisted intervention , pages=. 2015 , organization=
2015
-
[29]
Adam: A Method for Stochastic Optimization
Adam: A method for stochastic optimization , author=. arXiv preprint arXiv:1412.6980 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[30]
Artificial intelligence and machine learning for multi-domain operations applications , volume=
Super-convergence: Very fast training of neural networks using large learning rates , author=. Artificial intelligence and machine learning for multi-domain operations applications , volume=. 2019 , organization=
2019
-
[31]
Proceedings of the 32nd International Conference on Machine Learning , series=
Deep Unsupervised Learning using Nonequilibrium Thermodynamics , author=. Proceedings of the 32nd International Conference on Machine Learning , series=. 2015 , publisher=
2015
-
[32]
Neural Computation , volume=
A Connection Between Score Matching and Denoising Autoencoders , author=. Neural Computation , volume=. 2011 , publisher=
2011
-
[33]
Advances in Neural Information Processing Systems , volume=
Elucidating the Design Space of Diffusion-Based Generative Models , author=. Advances in Neural Information Processing Systems , volume=
-
[34]
and Park, Keehun and Kim, Sungwoong and Lim, Sungbin , booktitle=
Yoon, Eunbi B. and Park, Keehun and Kim, Sungwoong and Lim, Sungbin , booktitle=. Score-Based Generative Models with
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.