EgoCS-400K: An Egocentric Gameplay Dataset for World Models
Pith reviewed 2026-06-27 01:36 UTC · model grok-4.3
The pith
EgoCS-400K supplies over 400,000 first-person videos with aligned human actions, states, and events from Counter-Strike matches to support world model training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
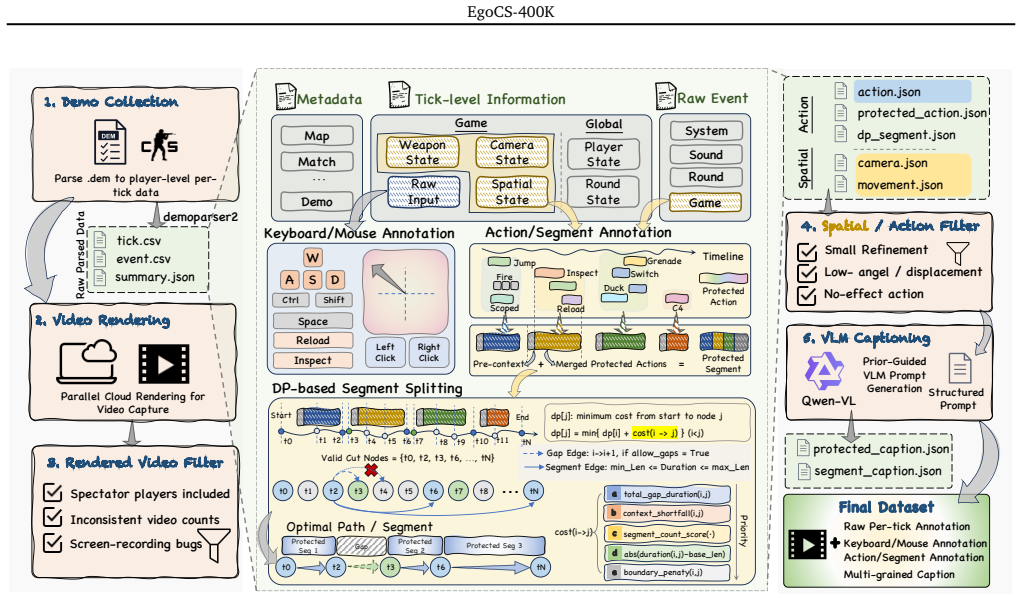
By extracting player states, view directions, movements, inputs, weapon usage, game events, and round context from public CS and CS2 match demos and rendering clean first-person videos from the same trajectories, EgoCS-400K creates a dataset of over 400,000 videos and 10,000 hours that connects visual observations directly to human actions, camera motion, states, and events for interactive world modeling.
What carries the argument
The replay-grounded construction pipeline that parses professional match demos, extracts rich annotations, and renders temporally aligned first-person videos.
If this is right
- Action-conditioned future prediction becomes feasible at large scale.
- State- and event-aware scene rollout can be trained on real human trajectories.
- Replay-grounded captioning links language to game events and actions.
- Agent egocentric action understanding improves with aligned viewpoint and input data.
Where Pith is reading between the lines
- Models trained on this data could transfer to real-world navigation or robotics if the game dynamics capture similar physics.
- Future work might extend the dataset to other games or add multi-agent interactions for more complex world models.
- The scale allows testing whether world models can handle long-horizon predictions in dynamic environments.
Load-bearing premise
Public professional match demos can be parsed, replayed, rendered, and aligned to produce first-person videos that faithfully represent human gameplay without major artifacts or loss of information.
What would settle it
A side-by-side comparison showing that models trained on the rendered EgoCS-400K videos achieve lower accuracy on future scene prediction than the same models trained on directly captured first-person footage from the same matches.
Figures


read the original abstract
The shift from video generation to interactive world modeling places new demands on data: beyond captioned videos, world models require temporally aligned video-action-language trajectories grounded in the actions, camera motion, states, and events that drive future scene changes. However, such data is difficult to obtain at scale. Web video datasets offer broad visual coverage but lack executable actions and reliable states; robotic datasets provide action and state supervision but are costly and limited in scene diversity; and existing simulators often lack large-scale human-driven interaction trajectories. In this paper, we introduce EgoCS-400K, a large-scale replay-grounded egocentric Counter-Strike dataset for world models, built from public professional CS and CS2 match demos that preserve human gameplay trajectories and enable parsing, replaying, rendering, and temporal alignment. We extract player states, view directions, movements, keyboard/button inputs, view-angle changes, weapon usage, game events, and round-level context, and render clean first-person videos from the same trajectories. EgoCS-400K contains over 400,000 first-person videos and 10,000 hours of gameplay from more than 1,000 matches and 40,000 rounds, covering 13 maps and 10 player viewpoints per round. It supports a range of interactive visual modeling tasks, including action-conditioned future prediction, state- and event-aware scene rollout, replay-grounded captioning, and agent egocentric action understanding. By connecting visual observations with human actions, camera motion, game states, and events at scale, EgoCS-400K serves as a practical bridge between passive web videos, controllable game simulation, and costly real-world embodied data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EgoCS-400K, a large-scale egocentric dataset derived from public professional Counter-Strike and CS2 match demos. It claims to contain over 400,000 first-person videos and 10,000 hours of gameplay from more than 1,000 matches and 40,000 rounds across 13 maps, with extracted player states, view directions, movements, inputs, events, and rendered videos, enabling tasks such as action-conditioned future prediction, state- and event-aware scene rollout, replay-grounded captioning, and agent egocentric action understanding.
Significance. If the data fidelity holds, EgoCS-400K would provide a significant resource for world model research by supplying temporally aligned video-action-state trajectories at a scale far exceeding existing robotic or simulator datasets, while incorporating human gameplay diversity. The curation from public demos is a practical approach to achieving this scale.
major comments (1)
- abstract, data-construction paragraph: The central claim that the dataset supplies reliable trajectories for interactive modeling rests on the unverified assumption that public demos enable parsing, replaying, rendering, and temporal alignment without significant fidelity loss or artifacts. No quantitative validation, error rates, or ground-truth comparisons (e.g., action parsing accuracy or rendered vs. original frame fidelity) are provided, which is load-bearing for claims of utility in action-conditioned prediction and state-aware rollout.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the manuscript. We address the single major comment below.
read point-by-point responses
-
Referee: abstract, data-construction paragraph: The central claim that the dataset supplies reliable trajectories for interactive modeling rests on the unverified assumption that public demos enable parsing, replaying, rendering, and temporal alignment without significant fidelity loss or artifacts. No quantitative validation, error rates, or ground-truth comparisons (e.g., action parsing accuracy or rendered vs. original frame fidelity) are provided, which is load-bearing for claims of utility in action-conditioned prediction and state-aware rollout.
Authors: We agree that the manuscript does not currently include quantitative validation of parsing accuracy or rendered-frame fidelity, and that this is a substantive point for claims about reliable trajectories. The construction uses standard, publicly documented demo parsers for CS:GO/CS2 that are designed to produce bit-exact replays of the recorded inputs and states; however, we did not report error rates or direct comparisons in the submitted version. In the revision we will add a dedicated validation subsection that reports (1) action-parsing accuracy measured against manually annotated ground-truth on a held-out sample of rounds, (2) frame-level visual fidelity metrics between rendered videos and the original demo playback, and (3) a summary of any observed artifacts or alignment offsets. These additions will directly support the utility claims for action-conditioned prediction and state-aware rollout. revision: yes
Circularity Check
No circularity: dataset curation paper with no derivation or fitted quantities
full rationale
The paper introduces a dataset (EgoCS-400K) assembled from public CS/CS2 match demos. No equations, predictions, parameters, or derivation chain exist in the provided text. The central contribution is descriptive curation and task support statements; the data-construction pipeline is presented as an empirical process without self-referential reduction or load-bearing self-citation. This matches the default case of a self-contained dataset paper (score 0).
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, Szymon Jakubczak, Tim Jones, Liyiming Ke, Sergey Levine, Adrian Li-Bell, Mohith Mothukuri, Suraj Nair, Karl Pertsch, Lucy Xiaoyang Shi, James Tanner, Quan Vuong, Anna Walling, Haohuan Wang, and Ury Zhilinsky.π0: A visio...
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Junliang Guo, Yang Ye, Tianyu He, Haoyu Wu, Yushu Jiang, Tim Pearce, and Jiang Bian. Mineworld: A real-time and open-source interactive world model on minecraft.arXiv preprint arXiv:2504.08388,
-
[3]
Yingchen He, Christian D. Weilbach, Martyna E. Wojciechowska, Yiyuan Sun, Yuxuan Zhang, and Frank Wood. Plaicraft: Large-scale time-aligned vision-speech-action dataset for embodied ai.arXiv preprint arXiv:2505.12707,
-
[4]
Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040,
Yicong Hong, Yiqun Mei, Chongjian Ge, Yiran Xu, Yang Zhou, Sai Bi, Yannick Hold-Geoffroy, Mike Roberts, Matthew Fisher, Eli Shechtman, Kalyan Sunkavalli, Feng Liu, Zhengqi Li, and Hao Tan. Relic: Interactive video world model with long-horizon memory.arXiv preprint arXiv:2512.04040,
-
[5]
HunyuanWorld Team, Zhenwei Wang, Yuhao Liu, Junta Wu, Zixiao Gu, Haoyuan Wang, Xuhui Zuo, Tianyu Huang, Wenhuan Li, Sheng Zhang, et al. HunyuanWorld 1.0: Generating immersive, explorable, and interactive 3D worlds from words or pixels.arXiv preprint arXiv:2507.21809,
-
[6]
The Kinetics Human Action Video Dataset
Will Kay, Joao Carreira, Karen Simonyan, Brian Zhang, Chloe Hillier, Sudheendra Vijayanarasimhan, Fabio Viola, Tim Green, Trevor Back, Paul Natsev, Mustafa Suleyman, and Andrew Zisserman. The kinetics human action video dataset. InarXiv preprint arXiv:1705.06950,
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Alexander Khazatsky, Karl Pertsch, Suraj Nair, Ashwin Balakrishna, Sudeep Dasari, Siddharth Karamcheti, Soroush Nasiriany, Mohan Kumar Srirama, Lawrence Yunliang Chen, Kirsty Ellis, et al. Droid: A large-scale in-the-wild robot manipulation dataset.arXiv preprint arXiv:2403.12945,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Jiaqi Li, Junshu Tang, Zhiyong Xu, Longhuang Wu, Yuan Zhou, Shuai Shao, Tianbao Yu, Zhiguo Cao, and Qinglin Lu. Hunyuan-gamecraft: High-dynamic interactive game video generation with hybrid history condition.arXiv preprint arXiv:2506.17201,
-
[9]
Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744,
Xiaofeng Mao, Shaoheng Lin, Zhen Li, Chuanhao Li, Wenshuo Peng, Tong He, Jiangmiao Pang, Ming- min Chi, Yu Qiao, and Kaipeng Zhang. Yume: An interactive world generation model.arXiv preprint arXiv:2507.17744,
-
[10]
JisuNam,YicongHong,Chun-HaoPaulHuang,FengLiu,JoungBinLee,JiyoungKim,SiyoonJin,YunsungLee, Jaeyoon Jung, Suhwan Choi, Seungryong Kim, and Yang Zhou. Worldcam: Interactive autoregressive 3d gaming worlds with camera pose as a unifying geometric representation.arXiv preprint arXiv:2603.16871,
-
[11]
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Abhishek Padalkar, Alex Pooley, Ajay Jain, Alex Bewley, Alexander Herzog, Alex Irpan, Alexander Khazatsky, Anant Rai, Anikait Singh, Anthony Brohan, et al. Open x-embodiment: Robotic learning datasets and rt-x models.arXiv preprint arXiv:2310.08864,
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
Movie Gen: A Cast of Media Foundation Models
Adam Polyak, Amit Zohar, Andrew Brown, Andros Tjandra, Animesh Sinha, Ann Lee, Apoorv Vyas, Bowen Shi, Chih-Yao Ma, Ching-Yao Chuang, et al. Movie gen: A cast of media foundation models.arXiv preprint arXiv:2410.13720,
work page internal anchor Pith review Pith/arXiv arXiv
-
[13]
arXiv preprint arXiv:2509.21790 (2025)
YuShang, LeiJin, YidingMa, XinZhang, ChenGao, WeiWu, andYongLi. Longscape: Advancinglong-horizon embodied world models with context-aware moe.arXiv preprint arXiv:2509.21790,
-
[14]
Hunyuan-gamecraft-2: Instruction-following interactive game world model
Junshu Tang, Jiacheng Liu, Jiaqi Li, Longhuang Wu, Haoyu Yang, Penghao Zhao, Siruis Gong, Xiang Yuan, Shuai Shao, and Qinglin Lu. Hunyuan-gamecraft-2: Instruction-following interactive game world model. arXiv preprint arXiv:2511.23429,
-
[15]
Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter
URLhttps://arxiv.org/ abs/2512.04797. Dani Valevski, Yaniv Leviathan, Moab Arar, and Shlomi Fruchter. Diffusion models are real-time game engines.arXiv preprint arXiv:2408.14837,
-
[16]
Matrix-Game 3.0: Real-Time and Streaming Interactive World Model with Long-Horizon Memory
Zile Wang, Zexiang Liu, Jaixing Li, Kaichen Huang, Baixin Xu, Fei Kang, Mengyin An, Peiyu Wang, Biao Jiang, Yichen Wei, Yidan Xietian, Jiangbo Pei, Liang Hu, Boyi Jiang, Hua Xue, Zidong Wang, Haofeng Sun, Wei Li, Wanli Ouyang, Xianglong He, Yang Liu, Yangguang Li, and Yahui Zhou. Matrix-game 3.0: Real-time and streaming interactive world model with long-h...
work page internal anchor Pith review Pith/arXiv arXiv
-
[17]
Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701, 2025
Yifan Zhang, Chunli Peng, Boyang Wang, Puyi Wang, Qingcheng Zhu, Fei Kang, Biao Jiang, Zedong Gao, Eric Li, Yang Liu, and Yahui Zhou. Matrix-game: Interactive world foundation model.arXiv preprint arXiv:2506.18701,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.