EBench: Elemental Diagnosis of Generalist Mobile Manipulation Policies
Pith reviewed 2026-06-27 00:18 UTC · model grok-4.3
The pith
A benchmark with 26 tasks shows that mobile manipulation policies with similar success rates have markedly different capability profiles.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
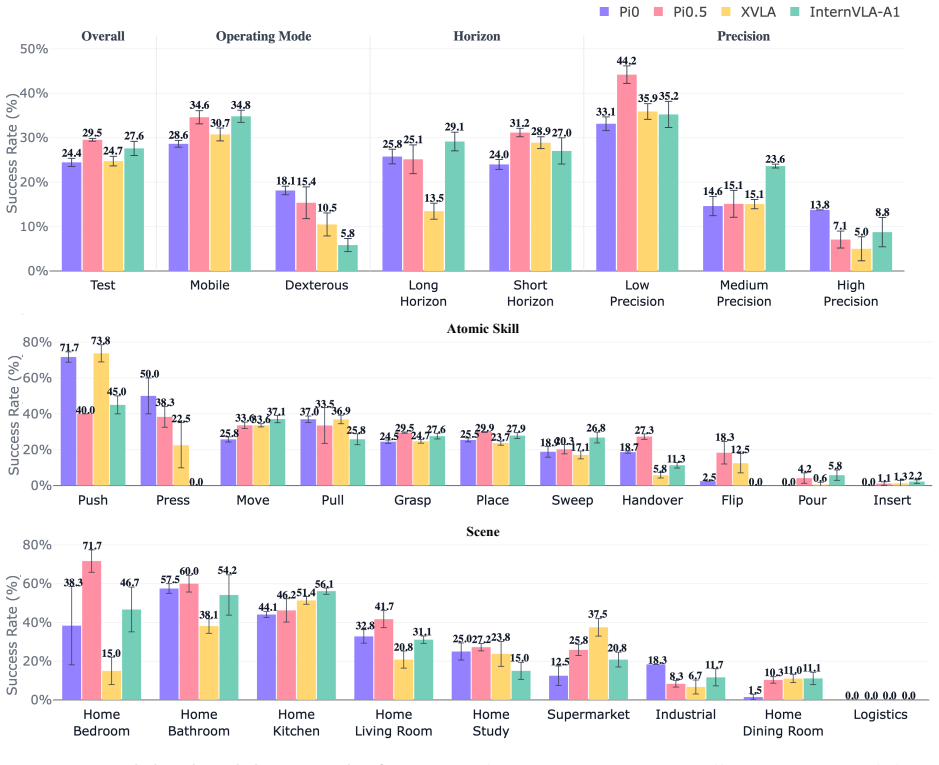
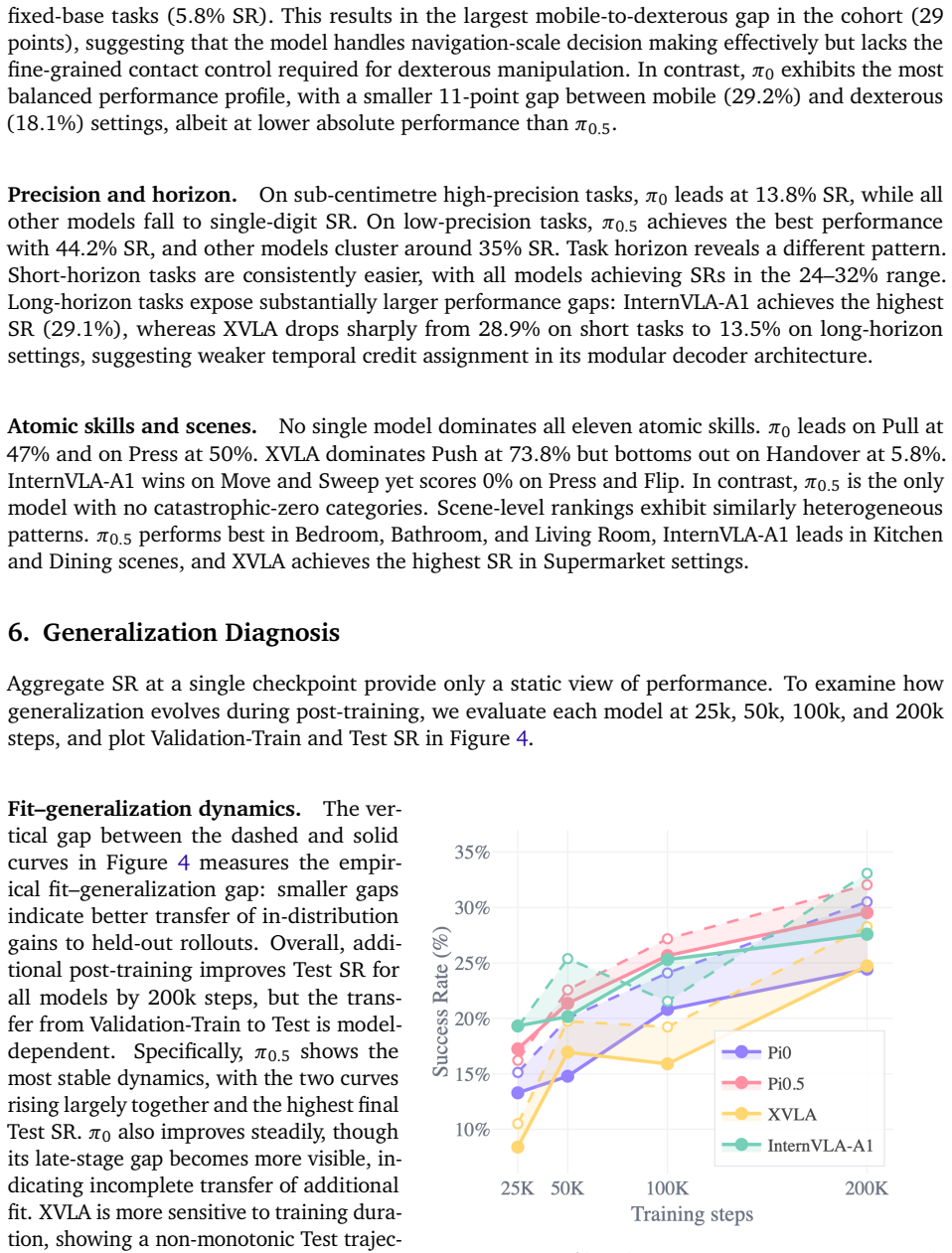
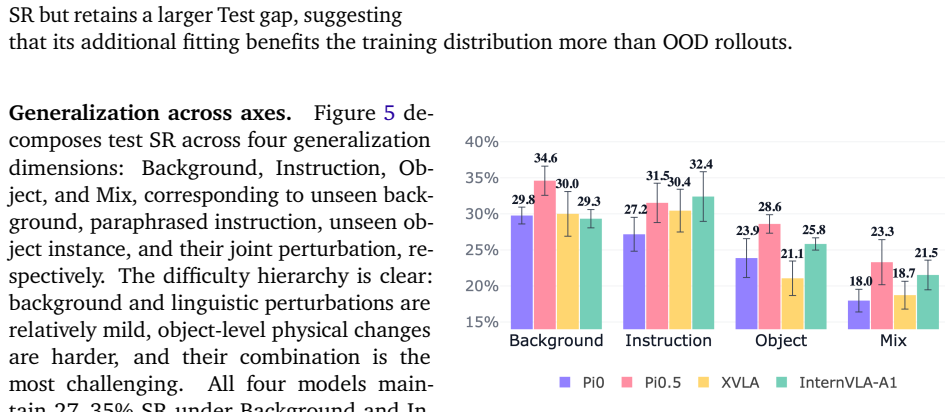
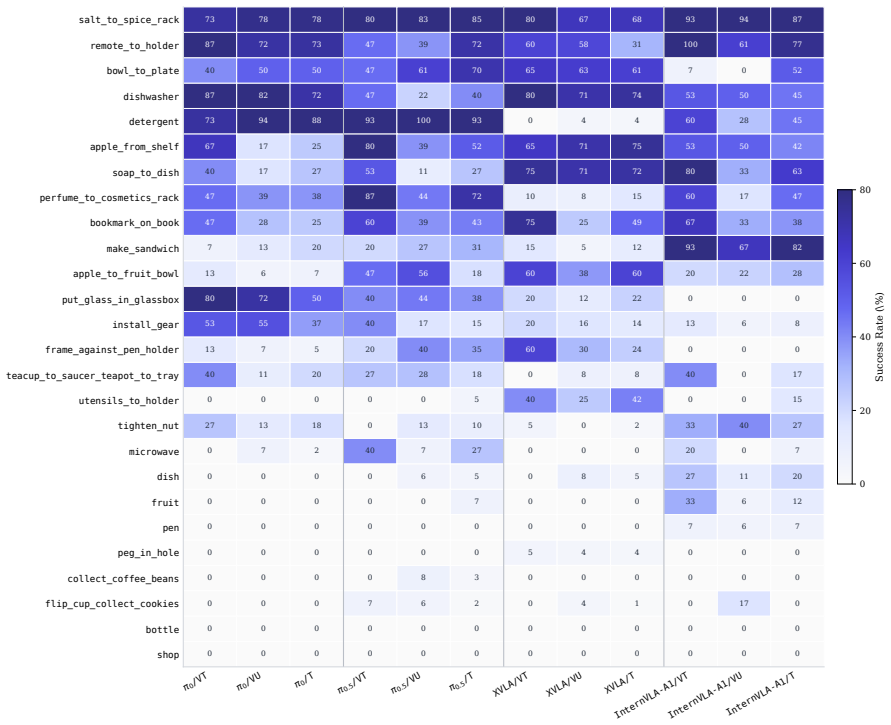
Models with near success rates exhibit strikingly different capability profiles: π0.5 achieves the highest test success rate and the best train-test retention, whereas InternVLA-A1 dominates mobile manipulation but collapses on dexterous tasks, and XVLA exhibits strengths on a disjoint set of atomic skills compared to other policies. Beyond capability profiling, EBench analyzes the generalization ability from four representative perspectives, identifying the impact of different distribution shift factors.
What carries the argument
EBench benchmark of 26 tasks annotated along five capability dimensions and four generalization dimensions.
If this is right
- Policy development should target specific capability weaknesses rather than optimizing a single success rate.
- Generalization analysis across distribution shifts can directly inform which factors to address in model training.
- Evaluation protocols for generalist manipulation should routinely include multi-dimensional profiling instead of aggregate scores alone.
Where Pith is reading between the lines
- The differing profiles suggest that combining elements from multiple policies could cover a wider range of skills than any single model.
- Extending the benchmark to physical robots would test whether simulation-based diagnoses predict real-world performance gaps.
- The framework could be applied to measure progress as new generalist models are released by tracking changes across the same dimensions.
Load-bearing premise
The 26 tasks together with the five capability dimensions and four generalization dimensions are sufficient and representative for diagnosing the full range of generalist mobile manipulation capabilities.
What would settle it
Running the same set of models on a new collection of tasks or dimensions that produces identical capability profiles for all models despite their similar success rates would falsify the claim that the benchmark reveals distinct profiles.
Figures


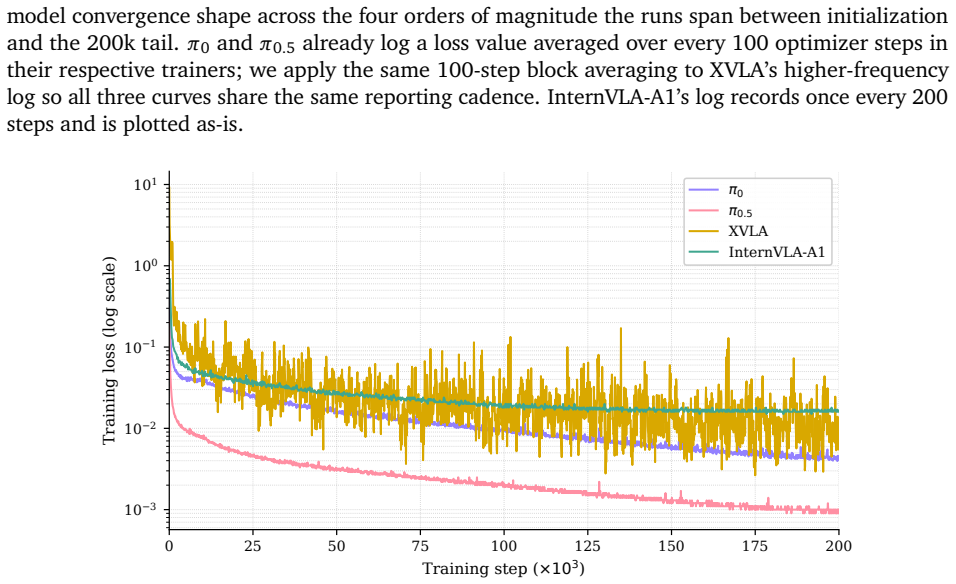
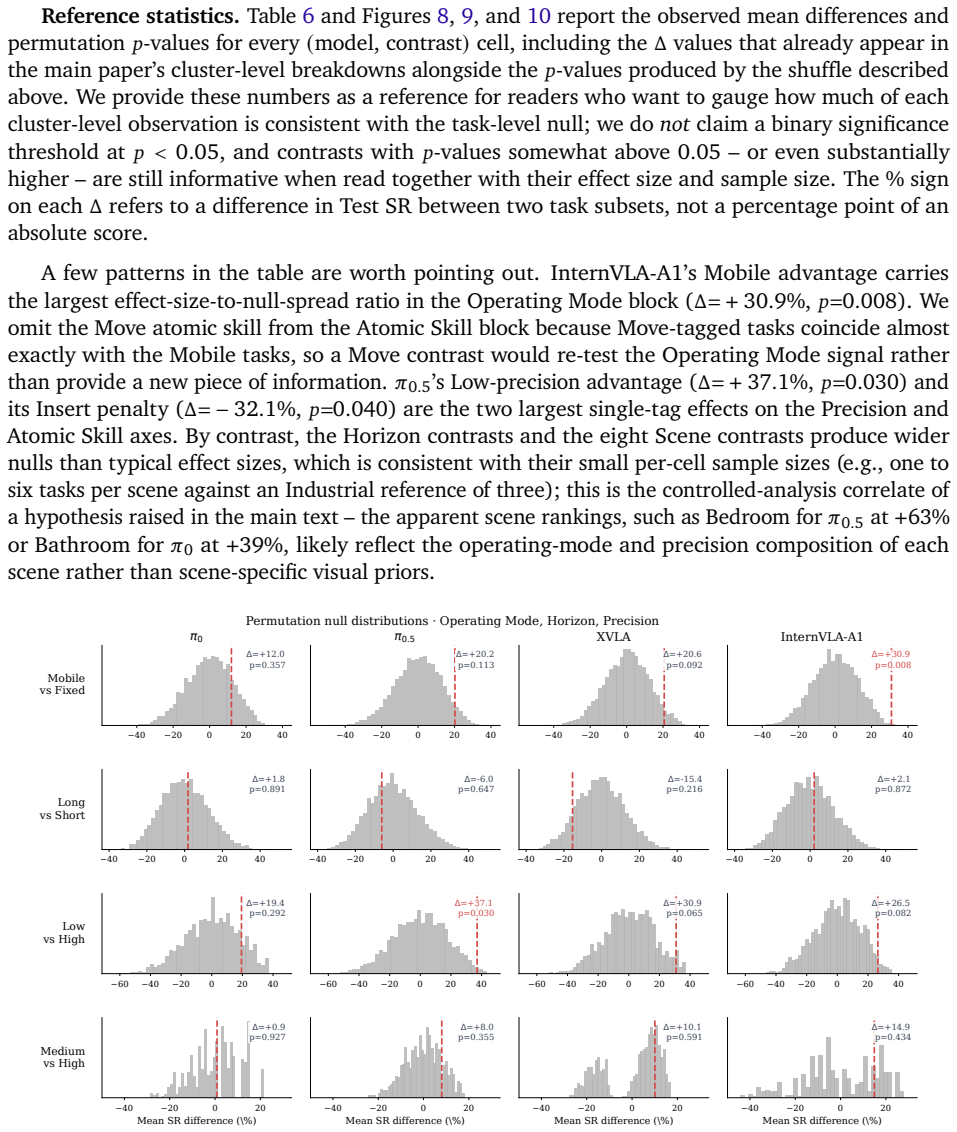
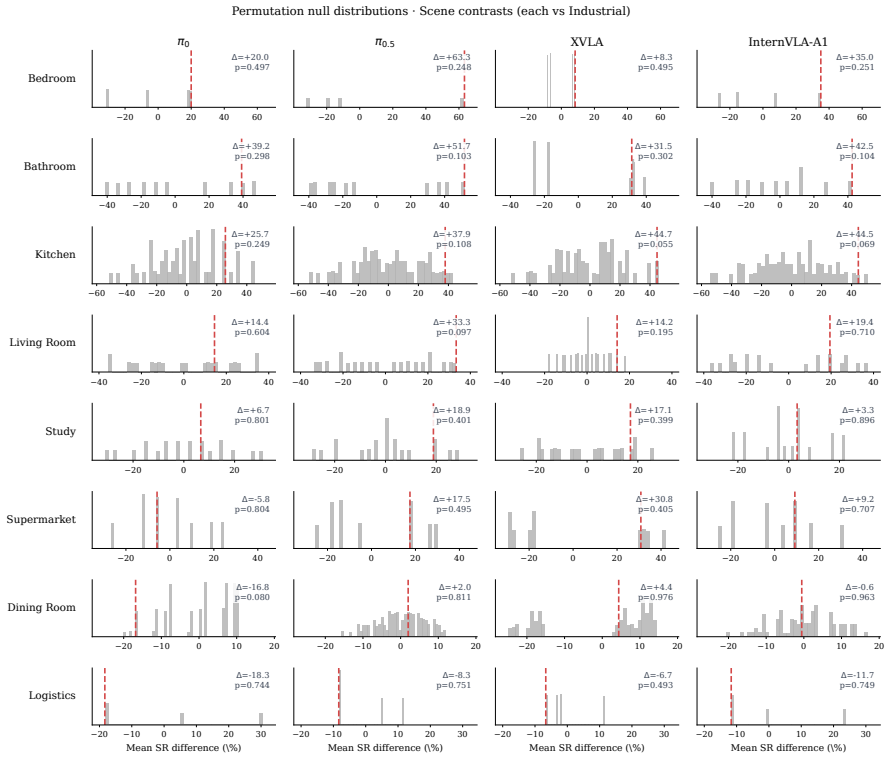
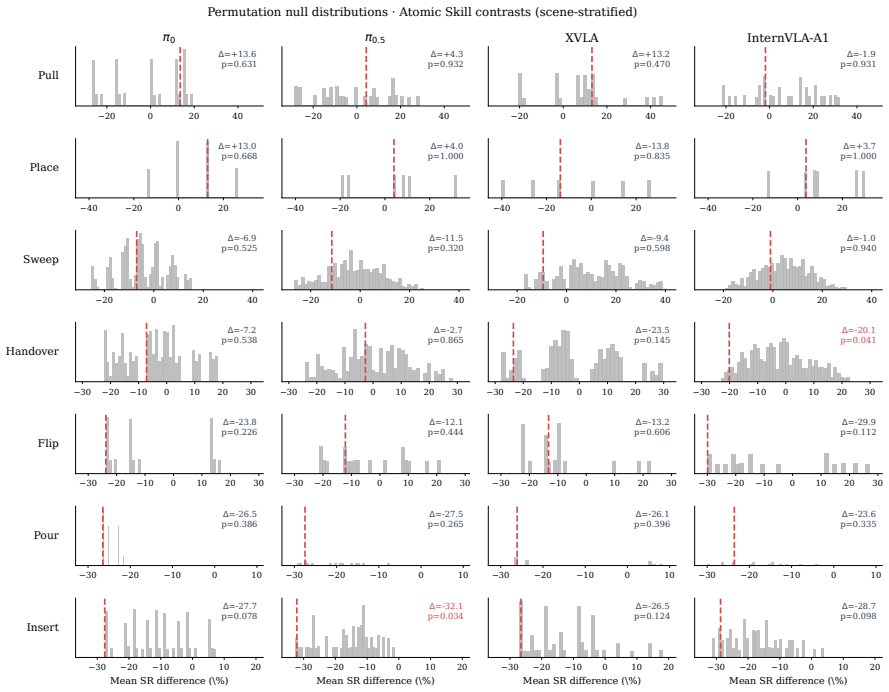
read the original abstract
We present EBench, a simulation benchmark that diagnoses generalist mobile manipulation policies beyond a single success-rate scalar. EBench comprises 26 diverse and challenging manipulation tasks annotated along 5 capability dimensions and 4 generalization dimensions. We evaluate state-of-the-art generalist manipulation models including $\pi_0$, $\pi_{0.5}$, XVLA, and InternVLA-A1, and reveal that models with near success rates exhibit strikingly different capability profiles: $\pi_{0.5}$ achieves the highest test success rate and the best train--test retention, whereas InternVLA-A1 dominates mobile manipulation but collapses on dexterous tasks, and XVLA exhibits strengths on a disjoint set of atomic skills compared to other policies. Beyond capability profiling, EBench analyzes the generalization ability from 4 representative perspectives, identifying the impact of different distribution shift factors. The results reveal strengths and weaknesses of models behind an overall score. We hope this benchmark offers a broad set of diagnostic signals to guide iteration on generalist manipulation models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces EBench, a simulation benchmark for diagnosing generalist mobile manipulation policies. It consists of 26 tasks annotated along 5 capability dimensions and 4 generalization dimensions. Evaluations of models including π0, π0.5, XVLA, and InternVLA-A1 show that policies with near-identical overall success rates exhibit qualitatively different profiles (e.g., π0.5 with highest test success and retention; InternVLA-A1 strong on mobile but weak on dexterous tasks; XVLA with disjoint atomic skill strengths), plus analysis of generalization under distribution shifts.
Significance. If the task set and annotations prove representative, the work supplies useful multi-dimensional diagnostics that go beyond scalar success rates, enabling more targeted iteration on generalist policies. The explicit profiling of complementary strengths across models and the four-perspective generalization analysis are concrete contributions that could be adopted by the community.
major comments (2)
- [Task construction and annotation section] Task construction and annotation section: the central claim that observed profile differences (e.g., InternVLA-A1 mobile vs. dexterous collapse) reflect intrinsic model distinctions rather than benchmark artifacts rests on the untested premise that the 26 tasks plus 5/4 dimensions are sufficient and representative; no quantitative coverage argument, inter-annotator reliability, or validation against real-world mobile manipulation regimes (long-horizon sequencing, contact-rich dynamics, sensor noise) is provided.
- [Results and statistical analysis section] Results and statistical analysis section: the reported distinctions in capability profiles lack any mention of statistical testing (e.g., significance of differences across dimensions or confidence intervals on success rates), which is required to substantiate that the profiles are reliably different rather than noise.
minor comments (1)
- [Abstract] Abstract: model names (π0, π0.5, XVLA, InternVLA-A1) should include citations to the original papers on first use for clarity.
Simulated Author's Rebuttal
Thank you for the constructive feedback. We address each major comment below and describe the changes planned for the revised manuscript.
read point-by-point responses
-
Referee: [Task construction and annotation section] Task construction and annotation section: the central claim that observed profile differences (e.g., InternVLA-A1 mobile vs. dexterous collapse) reflect intrinsic model distinctions rather than benchmark artifacts rests on the untested premise that the 26 tasks plus 5/4 dimensions are sufficient and representative; no quantitative coverage argument, inter-annotator reliability, or validation against real-world mobile manipulation regimes (long-horizon sequencing, contact-rich dynamics, sensor noise) is provided.
Authors: We acknowledge the absence of quantitative coverage metrics, inter-annotator reliability scores, and direct real-world validation. Task selection was performed by experts to span the stated capability and generalization dimensions, as described in the manuscript. In the revision we will add an explicit subsection on task curation rationale together with a limitations paragraph that discusses coverage gaps and the inherent constraints of simulation versus real-world regimes. This addition will allow readers to better evaluate the observed profiles without claiming unproven representativeness. revision: partial
-
Referee: [Results and statistical analysis section] Results and statistical analysis section: the reported distinctions in capability profiles lack any mention of statistical testing (e.g., significance of differences across dimensions or confidence intervals on success rates), which is required to substantiate that the profiles are reliably different rather than noise.
Authors: We agree that statistical support is required. The revised results section will report bootstrap confidence intervals on per-dimension success rates and include pairwise statistical comparisons (e.g., McNemar tests for binary outcomes) between models to establish that the reported profile differences are statistically distinguishable from sampling noise. revision: yes
Circularity Check
No circularity: empirical benchmark with direct observations only
full rationale
This is a pure empirical benchmark paper presenting task evaluations and capability annotations on 26 tasks. It contains no derivations, equations, fitted parameters, predictions from models, or self-citation chains that reduce claims to inputs by construction. Central claims are direct measurements of success rates and dimension scores across policies; the task set and dimensions are presented as chosen design choices rather than derived results. No load-bearing step matches any of the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Bjorck, F. Castañeda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y. Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[2]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. 𝜋0: A Vision-Language-Action Flow Model for General Robot Control.arXiv preprint arXiv:2410.24164,
-
[3]
J. Cai, Z. Cai, J. Cao, Y. Chen, Z. He, L. Jiang, H. Li, H. Li, Y. Li, Y. Liu, et al. Internvla-a1: Unifying understanding, generation and action for robotic manipulation.arXiv preprint arXiv:2601.02456,
-
[4]
T. Chen, Z. Chen, B. Chen, Z. Cai, Y. Liu, Z. Li, Q. Liang, X. Lin, Y. Ge, Z. Gu, et al. Robotwin 2.0: A scalable data generator and benchmark with strong domain randomization for robust bimanual robotic manipulation.arXiv preprint arXiv:2506.18088,
-
[5]
T. Chen, Y. Wang, M. Li, Y. Qin, H. Shi, Z. Li, Y. Hu, Y. Zhang, K. Wang, Y. Chen, et al. Rmbench: Memory-dependent robotic manipulation benchmark with insights into policy design.arXiv preprint arXiv:2603.01229,
-
[6]
S. Community. Starvla: A lego-like codebase for vision-language-action model developing.arXiv preprint arXiv:2604.05014,
-
[7]
S. Fei, S. Wang, J. Shi, Z. Dai, J. Cai, P. Qian, L. Ji, X. He, S. Zhang, Z. Fei, et al. Libero-plus: In-depth robustness analysis of vision-language-action models.arXiv preprint arXiv:2510.13626,
-
[8]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. 𝜋0.5: A Vision-Language-Action Model with Open-World Generalization.arXiv preprint arXiv:2504.16054,
-
[9]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
-
[10]
L. Li, Q. Zhang, Y. Luo, S. Yang, R. Wang, F. Han, M. Yu, Z. Gao, N. Xue, X. Zhu, et al. Causal world modeling for robot control.arXiv preprint arXiv:2601.21998,
-
[11]
X. Li, K. Hsu, J. Gu, K. Pertsch, O. Mees, H. R. Walke, C. Fu, I. Lunawat, I. Sieh, S. Kirmani, et al. Evaluating real-world robot manipulation policies in simulation.arXiv preprint arXiv:2405.05941,
-
[12]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation. InInternational Conference on Learning Representations, volume 2025, pages 29982–30009,
2025
-
[13]
T. Mu, Z. Ling, F. Xiang, D. Yang, X. Li, S. Tao, Z. Huang, Z. Jia, and H. Su. Maniskill: Generalizable manipulation skill benchmark with large-scale demonstrations.arXiv preprint arXiv:2107.14483,
-
[14]
S. Nasiriany, A. Maddukuri, L. Zhang, A. Parikh, A. Lo, A. Joshi, A. Mandlekar, and Y. Zhu. Robocasa: Large-scale simulation of everyday tasks for generalist robots.arXiv preprint arXiv:2406.02523,
-
[15]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
-
[16]
H. Wang, J. Chen, W. Huang, Q. Ben, T. Wang, B. Mi, T. Huang, S. Zhao, Y. Chen, S. Yang, et al. Grutopia: Dream general robots in a city at scale.arXiv preprint arXiv:2407.10943,
-
[17]
J. Ye, N. Gao, S. Yang, J. Zheng, Z. Wang, Y. Chen, P. Chen, Y. Chen, S. Liu, and J. Jia. StarVLA-𝛼: Reducing Complexity in Vision-Language-Action Systems.arXiv preprint arXiv:2604.11757,
-
[18]
T. Yuan, Z. Dong, Y. Liu, and H. Zhao. Fast-wam: Do world action models need test-time future imagination?arXiv preprint arXiv:2603.16666,
-
[19]
J. Zheng, J. Li, Z. Wang, D. Liu, X. Kang, Y. Feng, Y. Zheng, J. Zou, Y. Chen, J. Zeng, et al. X-vla: Soft-prompted transformer as scalable cross-embodiment vision-language-action model.arXiv preprint arXiv:2510.10274,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.