HyDRA: Lossless Hypergraph Summarization via Co-Clustering
Pith reviewed 2026-06-27 20:13 UTC · model grok-4.3
The pith
HyDRA offers the first formal framework for lossless summarization of weighted hypergraphs by co-clustering nodes and hyperedges.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
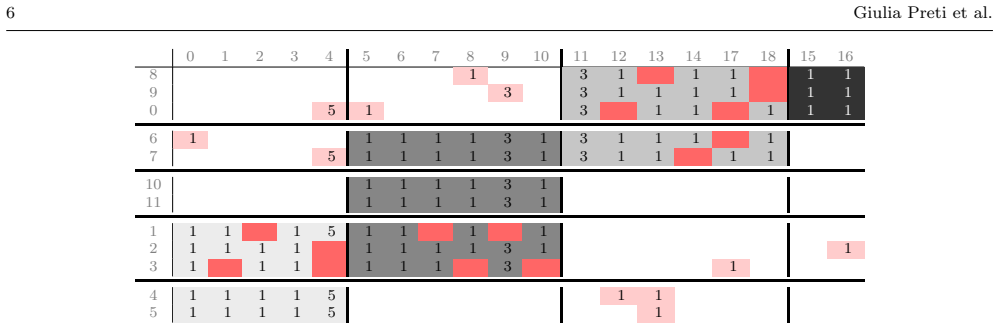
HyDRA establishes a formal framework where a summary hypergraph of supernodes and superhyperedges, together with a correction table, permits exact reconstruction of any weighted hypergraph. Linking the task to co-clustering produces a parameter-free greedy algorithm that iteratively merges node and hyperedge clusters while using incremental updates to minimize a storage-aware cost function at every step.
What carries the argument
The storage-aware cost function that the greedy co-clustering process minimizes by merging node clusters and hyperedge clusters, with incremental updates to the correction table.
If this is right
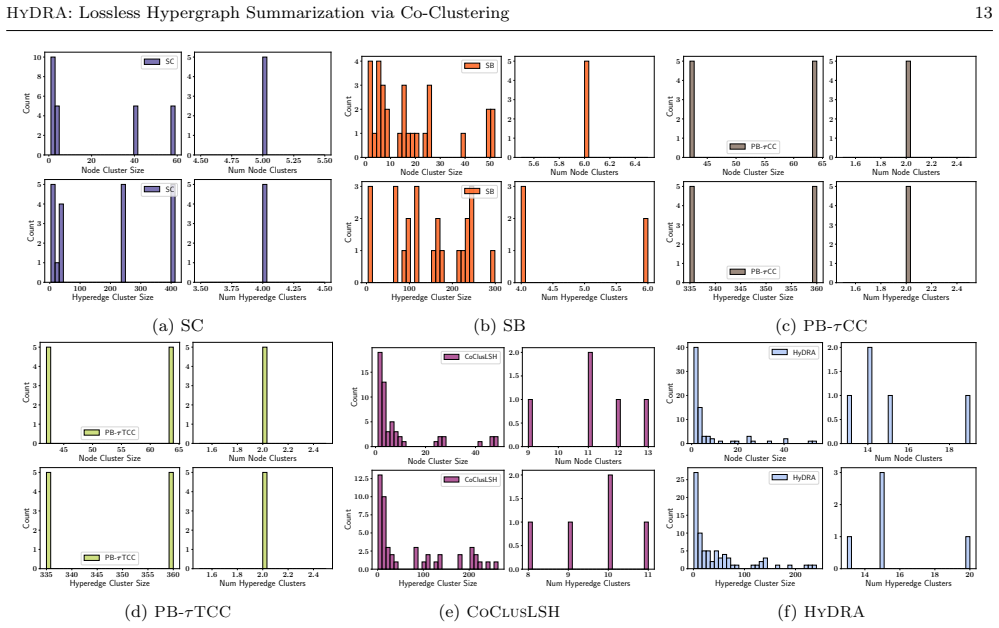
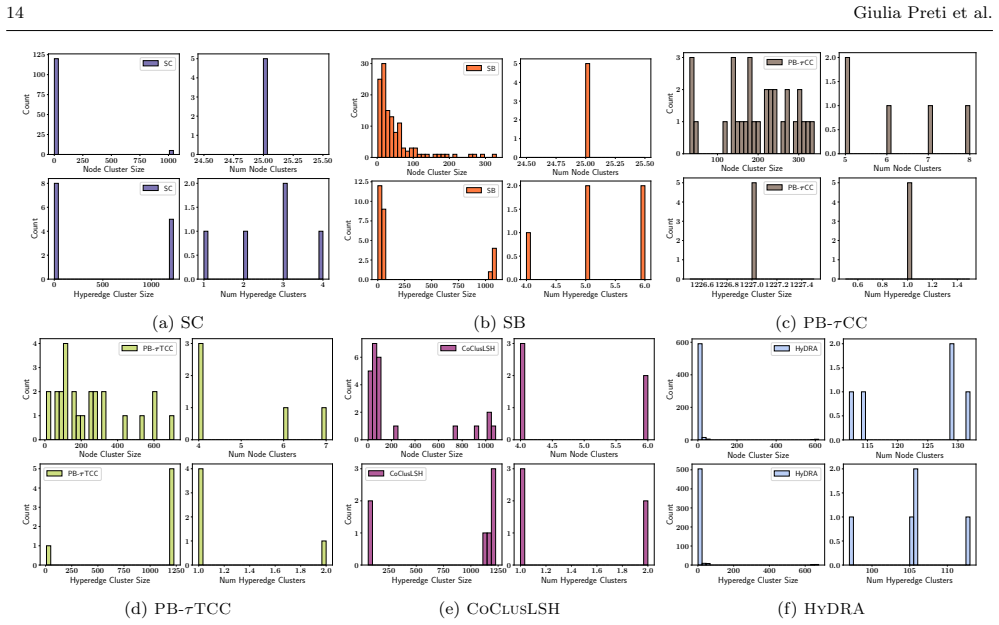
- The summaries achieve storage reductions of 80 to 93 percent depending on the input hypergraph.
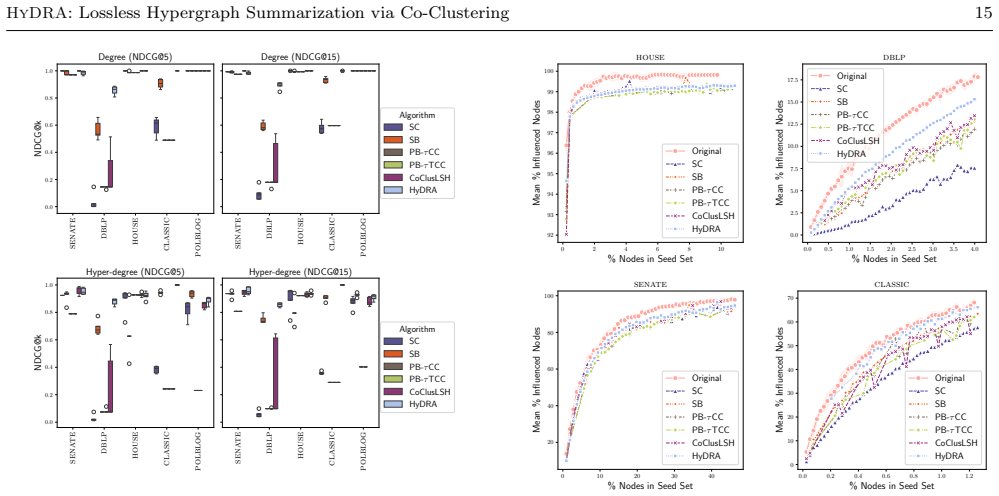
- The summaries remain hypergraphs and therefore support direct approximate answers to connectivity and centrality queries.
- Downstream tasks such as influence maximization run faster on the summaries.
- The algorithm requires no parameters because incremental updates avoid repeated full recomputation of the correction table.
Where Pith is reading between the lines
- The same merging logic could be tested on hypergraphs that grow over time if the incremental updates are extended to handle new nodes and edges.
- The correction-table approach might be adapted to other higher-order data structures where exact reconstruction is required.
- Because the output is itself a hypergraph, the method could be applied recursively to produce multi-level summaries.
Load-bearing premise
That the link to co-clustering produces a greedy merging process whose incremental updates correctly minimize the storage cost at every step without full recomputation.
What would settle it
A run on a small known weighted hypergraph in which the produced summary plus correction table fails to reconstruct the exact original weights, or in which a different sequence of merges yields lower total storage.
Figures




read the original abstract
Hypergraphs are a powerful representation for higher-order interactions but their scale and complexity pose significant data management and analysis challenges. While summarization techniques are widely used to distill simple graphs, lossless summarization for hypergraphs remains unexplored. We introduce HyDRA, the first formal framework for lossless summarization of weighted hypergraphs. In our framework, a summary is a new weighted hypergraph composed of supernodes (groups of nodes) and superhyperedges (groups of hyperedges), paired with a correction table for exact reconstruction. By establishing a conceptual link to co-clustering, we design an efficient, parameter-free greedy algorithm that iteratively merges node and hyperedge clusters to minimize a novel storage-aware cost function. HyDRA employs an incremental update strategy to prevent the costly recomputation of the correction table at each step. Extensive experiments demonstrate that \our achieves a substantial reduction in storage cost (80-93% in some settings, depending on the hypergraph characteristics). Because the resulting summaries are themselves hypergraphs, they can be queried directly, providing fast and accurate approximate answers for various connectivity and centrality queries, and accelerating downstream tasks such as influence maximization.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces HyDRA as the first formal framework for lossless summarization of weighted hypergraphs via co-clustering. A summary consists of supernodes (node groups) and superhyperedges (hyperedge groups) together with a correction table that enables exact reconstruction of the original hypergraph. The authors map the storage-aware cost to a co-clustering objective and present a parameter-free greedy algorithm that iteratively merges clusters; an incremental update strategy is claimed to avoid full recomputation of the correction table after each merge. Experiments report 80-93% storage reductions (depending on hypergraph characteristics) and show that the resulting summaries support fast approximate answers to connectivity and centrality queries.
Significance. If the algorithmic claims hold, the work supplies the first explicit lossless summarization framework for weighted hypergraphs, a domain where prior techniques have been limited to simple graphs. The conceptual reduction to co-clustering, the parameter-free greedy procedure, and the reported storage savings constitute concrete contributions. The ability to query the summary hypergraph directly is a practical strength that could accelerate downstream tasks such as influence maximization.
major comments (2)
- [§4.3] §4.3 (Incremental update strategy): the central claim that the delta computed by the incremental correction-table update exactly equals the change in the global storage-aware cost function is not supported by explicit closed-form equations or a proof that all interaction terms between supernodes and superhyperedges are accounted for. Because the greedy choice at each merge step relies on this delta being exact, any omitted term would make the selected merges suboptimal and could invalidate both the reported storage reductions and the lossless-reconstruction guarantee.
- [§5] §5 (Experimental evaluation): the 80-93% storage reductions are reported without a clear statement of the baseline summarization methods against which they are measured, nor is there a direct verification (e.g., via reconstruction error or checksum) that the correction table produced by the incremental procedure reconstructs the input hypergraph exactly on the tested instances.
minor comments (2)
- [§3] Notation for the storage-aware cost function is introduced without an explicit equation number; adding an equation label would improve traceability when the cost is later referenced in the merge analysis.
- [§5] The abstract states that summaries 'support fast and accurate approximate answers,' yet the experimental section does not quantify the approximation error or running-time improvement relative to querying the original hypergraph; a small table of query-error statistics would strengthen the claim.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive comments. We address each major comment below.
read point-by-point responses
-
Referee: [§4.3] §4.3 (Incremental update strategy): the central claim that the delta computed by the incremental correction-table update exactly equals the change in the global storage-aware cost function is not supported by explicit closed-form equations or a proof that all interaction terms between supernodes and superhyperedges are accounted for. Because the greedy choice at each merge step relies on this delta being exact, any omitted term would make the selected merges suboptimal and could invalidate both the reported storage reductions and the lossless-reconstruction guarantee.
Authors: We agree that the manuscript would benefit from an explicit derivation. In the revision we will insert closed-form equations for the incremental correction-table update together with a short proof that the computed delta equals the exact change in the storage-aware cost, accounting for every interaction term between supernodes and superhyperedges. This will confirm that the greedy selections remain optimal and that the lossless property is preserved. revision: yes
-
Referee: [§5] §5 (Experimental evaluation): the 80-93% storage reductions are reported without a clear statement of the baseline summarization methods against which they are measured, nor is there a direct verification (e.g., via reconstruction error or checksum) that the correction table produced by the incremental procedure reconstructs the input hypergraph exactly on the tested instances.
Authors: We will revise §5 to name the baseline methods explicitly (including any adaptations of prior graph summarization techniques) and to report direct reconstruction checks—checksums and zero-error metrics—on every tested instance, confirming that the correction table yields exact reconstruction. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper introduces a new formal framework for lossless hypergraph summarization by establishing a conceptual link to co-clustering and designing a parameter-free greedy algorithm with incremental updates to minimize a storage-aware cost function. No equations, fitted parameters, or self-citations are visible in the provided text that would reduce any claimed prediction or result to its inputs by construction. The central claims rest on the novelty of the framework and the efficiency of the algorithm rather than any self-definitional mapping or renamed known result. The derivation is self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Data mining and knowledge discovery 29:626–688
Akoglu L, Tong H, Koutra D (2015) Graph based anomaly detection and description: a survey. Data mining and knowledge discovery 29:626–688
2015
-
[2]
ACM Transactions on Knowledge Discovery from Data 18(6):1–22
Ali S, Ahmad M, Beg MA, Khan IU, Faizullah S, Khan MA (2024) Ssag: Summarization and spar- sification of attributed graphs. ACM Transactions on Knowledge Discovery from Data 18(6):1–22
2024
-
[3]
Theory of Computing 8(1):597–622
Anagnostopoulos A, Dasgupta A, Kumar R (2012) A constant-factor approximation algorithm for co- clustering. Theory of Computing 8(1):597–622
2012
-
[4]
In: 2019 IEEE 60th Annual Symposium on Foundations of Computer Science, IEEE, IEEE, New York, NY, USA, pp 910–928
Bansal N, Svensson O, Trevisan L (2019) New no- tions and constructions of sparsification for graphs and hypergraphs. In: 2019 IEEE 60th Annual Symposium on Foundations of Computer Science, IEEE, IEEE, New York, NY, USA, pp 910–928
2019
-
[5]
ACM Comput Surv 57(2), DOI 10.1145/3698875
Battaglia E, Peiretti F, Pensa RG (2024) Co- clustering: A survey of the main methods, recent trends, and open problems. ACM Comput Surv 57(2), DOI 10.1145/3698875
-
[6]
Machine Learning 113(4):2153–2181
Battaglia E, Peiretti F, Pensa RG (2024) Fast pa- rameterless prototype-based co-clustering. Machine Learning 113(4):2153–2181
2024
-
[7]
SIAM Journal on Mathematics of Data Science 1(2):293–312
Benson AR (2019) Three hypergraph eigenvector centralities. SIAM Journal on Mathematics of Data Science 1(2):293–312
2019
-
[8]
Benson and Rediet Abebe and Michael T
Benson AR, Abebe R, Schaub MT, Jadbabaie A, Kleinberg J (2018) Simplicial closure and higher-order link prediction. Proceedings of the National Academy of Sciences 115(48):E11,221– E11,230, DOI 10.1073/pnas.1800683115
-
[9]
arXiv preprint arXiv:190609068 18 Giulia Preti et al
Billings JCW, Hu M, Lerda G, Medvedev AN, Mottes F, Onicas A, Santoro A, Petri G (2019) Simplex2vec embeddings for community detec- tion in simplicial complexes. arXiv preprint arXiv:190609068 18 Giulia Preti et al
2019
-
[10]
In: Proceedings of the 20th international conference on World Wide Web, Association for Computing Machinery, New York, NY, USA, pp 587–596
Boldi P, Rosa M, Santini M, Vigna S (2011) Layered label propagation: A multiresolution coordinate-free ordering for compressing social net- works. In: Proceedings of the 20th international conference on World Wide Web, Association for Computing Machinery, New York, NY, USA, pp 587–596
2011
-
[11]
Advances in neural infor- mation processing systems 22
Bul` o S, Pelillo M (2009) A game-theoretic approach to hypergraph clustering. Advances in neural infor- mation processing systems 22
2009
-
[12]
In: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, New York, NY, USA, pp 219–228
Chierichetti F, Kumar R, Lattanzi S, Mitzen- macher M, Panconesi A, Raghavan P (2009) On compressing social networks. In: Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, New York, NY, USA, pp 219–228
2009
-
[13]
Proceedings of the ACM on Management of Data 2(3):1–26
Chu D, Zhang F, Zhang W, Zhang Y, Lin X (2024) Graph summarization: Compactness meets efficiency. Proceedings of the ACM on Management of Data 2(3):1–26
2024
-
[14]
Information Sciences 301:13–26
Del Buono N, Pio G (2015) Non-negative matrix tri-factorization for co-clustering: an analysis of the block matrix. Information Sciences 301:13–26
2015
-
[15]
In: Proceedings of the seventh ACM SIGKDD in- ternational conference on Knowledge discovery and data mining, Association for Computing Machin- ery, New York, NY, USA, pp 269–274
Dhillon IS (2001) Co-clustering documents and words using bipartite spectral graph partitioning. In: Proceedings of the seventh ACM SIGKDD in- ternational conference on Knowledge discovery and data mining, Association for Computing Machin- ery, New York, NY, USA, pp 269–274
2001
-
[16]
In: Pro- ceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, New York, NY, USA, pp 89–98
Dhillon IS, Mallela S, Modha DS (2003) Information-theoretic co-clustering. In: Pro- ceedings of the ninth ACM SIGKDD international conference on Knowledge discovery and data mining, Association for Computing Machinery, New York, NY, USA, pp 89–98
2003
-
[17]
In: Proceedings of the 18th ACM SIGKDD inter- national conference on Knowledge discovery and data mining, Association for Computing Machin- ery, New York, NY, USA, pp 1249–1257
Feng J, He X, Konte B, B¨ ohm C, Plant C (2012) Summarization-based mining bipartite graphs. In: Proceedings of the 18th ACM SIGKDD inter- national conference on Knowledge discovery and data mining, Association for Computing Machin- ery, New York, NY, USA, pp 1249–1257
2012
-
[18]
BMC bioinformatics 22(1):287
Feng S, Heath E, Jefferson B, Joslyn C, Kvinge H, Mitchell HD, Praggastis B, Eisfeld AJ, Sims AC, Thackray LB, et al (2021) Hypergraph mod- els of biological networks to identify genes critical to pathogenic viral response. BMC bioinformatics 22(1):287
2021
-
[19]
In: Proceedings of the AAAI conference on artificial intelligence, AAAI Press, Palo Alto, California USA, vol 33, pp 3558– 3565
Feng Y, You H, Zhang Z, Ji R, Gao Y (2019) Hy- pergraph neural networks. In: Proceedings of the AAAI conference on artificial intelligence, AAAI Press, Palo Alto, California USA, vol 33, pp 3558– 3565
2019
-
[20]
In: Aus- tralasian Database Conference, Springer, Springer, pp 147–159
Gao T, Akoglu L (2014) Fast information- theoretic agglomerative co-clustering. In: Aus- tralasian Database Conference, Springer, Springer, pp 147–159
2014
-
[21]
In: International Conference on Parallel Problem Solv- ing from Nature, Springer, pp 217–235
Genetti S, Ribaga E, Cunegatti E, Lotito QF, Iacca G (2024) Influence maximization in hypergraphs using multi-objective evolutionary algorithms. In: International Conference on Parallel Problem Solv- ing from Nature, Springer, pp 217–235
2024
-
[22]
In: Euro- pean Conference on Principles of Data Mining and Knowledge Discovery, Springer, pp 173–184
Gionis A, Mannila H, Sepp¨ anen JK (2004) Geomet- ric and combinatorial tiles in 0–1 data. In: Euro- pean Conference on Principles of Data Mining and Knowledge Discovery, Springer, pp 173–184
2004
-
[23]
Journal of the american statistical association 67(337):123–129
Hartigan JA (1972) Direct clustering of a data ma- trix. Journal of the american statistical association 67(337):123–129
1972
-
[24]
Data Mining and Knowledge Discovery 35(6):2542– 2576
Hess S, Pio G, Hochstenbach M, Ceci M (2021) Broccoli: overlapping and outlier-robust bicluster- ing through proximal stochastic gradient descent. Data Mining and Knowledge Discovery 35(6):2542– 2576
2021
-
[25]
Data Mining and Knowledge Discovery 26(2):217–254
Ienco D, Robardet C, Pensa RG, Meo R (2013) Parameter-less co-clustering for star-structured heterogeneous data. Data Mining and Knowledge Discovery 26(2):217–254
2013
-
[26]
In: Proceedings of the 26th ACM SIGKDD interna- tional conference on knowledge discovery & data mining, pp 2020–2029
Ji S, Feng Y, Ji R, Zhao X, Tang W, Gao Y (2020) Dual channel hypergraph collaborative filtering. In: Proceedings of the 26th ACM SIGKDD interna- tional conference on knowledge discovery & data mining, pp 2020–2029
2020
-
[27]
ACM Transactions on Knowledge Discovery from Data (TKDD) 16(5):1– 30
Ke X, Khan A, Bonchi F (2022) Multi-relation graph summarization. ACM Transactions on Knowledge Discovery from Data (TKDD) 16(5):1– 30
2022
-
[28]
In: Proceedings of the Ninth ACM SIGKDD Inter- national Conference on Knowledge Discovery and Data Mining, KDD ’03, p 137–146
Kempe D, Kleinberg J, Tardos E (2003) Maximiz- ing the spread of influence through a social network. In: Proceedings of the Ninth ACM SIGKDD Inter- national Conference on Knowledge Discovery and Data Mining, KDD ’03, p 137–146
2003
-
[29]
Proc VLDB Endow 10(12):1981–1984
Khan A, Bhowmick SS, Bonchi F (2017) Summa- rizing static and dynamic big graphs. Proc VLDB Endow 10(12):1981–1984
2017
-
[30]
Genome research 13(4):703–716
Kluger Y, Basri R, Chang JT, Gerstein M (2003) Spectral biclustering of microarray data: coclus- tering genes and conditions. Genome research 13(4):703–716
2003
-
[31]
In: 2018 IEEE International Conference on Data Min- ing (ICDM), IEEE, pp 1097–1097
Koutra D, Vreeken J, Bonchi F (2018) Summa- rizing graphs at multiple scales: new trends. In: 2018 IEEE International Conference on Data Min- ing (ICDM), IEEE, pp 1097–1097
2018
-
[32]
ACM Computing Surveys 57(8):1–36 HyDRA: Lossless Hypergraph Summarization via Co-Clustering 19
Lee G, Bu F, Eliassi-Rad T, Shin K (2025) A survey on hypergraph mining: Patterns, tools, and gener- ators. ACM Computing Surveys 57(8):1–36 HyDRA: Lossless Hypergraph Summarization via Co-Clustering 19
2025
-
[33]
In: 2022 IEEE 38th International Conference on Data Engi- neering (ICDE), IEEE, pp 472–484
Lee K, Ko J, Shin K (2022) Slugger: Lossless hier- archical summarization of massive graphs. In: 2022 IEEE 38th International Conference on Data Engi- neering (ICDE), IEEE, pp 472–484
2022
-
[34]
In: Proceedings of the 2010 SIAM International Conference on Data Mining, SIAM, pp 454–465
LeFevre K, Terzi E (2010) Grass: Graph structure summarization. In: Proceedings of the 2010 SIAM International Conference on Data Mining, SIAM, pp 454–465
2010
-
[35]
Proceedings of the ACM on Management of Data 1(2):1–23
Li Y, Yang R, Shi J (2023) Efficient and effec- tive attributed hypergraph clustering via k-nearest neighbor augmentation. Proceedings of the ACM on Management of Data 1(2):1–23
2023
-
[36]
ACM computing surveys (CSUR) 51(3):1–34
Liu Y, Safavi T, Dighe A, Koutra D (2018) Graph summarization methods and applications: A sur- vey. ACM computing surveys (CSUR) 51(3):1–34
2018
-
[37]
Communications Physics 5(1):79
Lotito QF, Musciotto F, Montresor A, Battiston F (2022) Higher-order motif analysis in hypergraphs. Communications Physics 5(1):79
2022
-
[38]
Mampaey M, Vreeken J (2010) Summarising data by clustering items. In: Machine Learning and Knowledge Discovery in Databases: European Con- ference, ECML PKDD 2010, Barcelona, Spain, September 20-24, 2010, Proceedings, Part II 21, Springer, pp 321–336
2010
-
[39]
In: Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, pp 573–581
Mampaey M, Tatti N, Vreeken J (2011) Tell me what i need to know: succinctly summarizing data with itemsets. In: Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining, pp 573–581
2011
-
[40]
ACM Transactions on Knowledge Discovery from Data (TKDD) 6(4):1–42
Mampaey M, Vreeken J, Tatti N (2012) Summariz- ing data succinctly with the most informative item- sets. ACM Transactions on Knowledge Discovery from Data (TKDD) 6(4):1–42
2012
-
[41]
Merchant A, Mathioudakis M, Wang Y (2023) Graph summarization via node grouping: A spec- tral algorithm. In: Proceedings of the Sixteenth ACM International Conference on Web Search and Data Mining, pp 742–750, DOI 10.1145/3539597. 3570441
-
[42]
In: Proceedings of the 2008 ACM SIGMOD international confer- ence on Management of data, pp 419–432
Navlakha S, Rastogi R, Shrivastava N (2008) Graph summarization with bounded error. In: Proceedings of the 2008 ACM SIGMOD international confer- ence on Management of data, pp 419–432
2008
-
[43]
EPJ Data Science 6:1–16
Patania A, Petri G, Vaccarino F (2017) The shape of collaborations. EPJ Data Science 6:1–16
2017
-
[44]
Journal of The Royal Society Interface 11(101):20140,873
Petri G, Expert P, Turkheimer F, Carhart-Harris R, Nutt D, Hellyer PJ, Vaccarino F (2014) Homological scaffolds of brain functional net- works. Journal of The Royal Society Interface 11(101):20140,873
2014
-
[45]
In: Proceedings of the Web Conference 2021, pp 3408–3418
Preti G, De Francisci Morales G, Bonchi F (2021) Strud: Truss decomposition of simplicial complexes. In: Proceedings of the Web Conference 2021, pp 3408–3418
2021
-
[46]
In: Proceedings of the ACM Web Confer- ence 2022, pp 1444–1454
Preti G, De Francisci Morales G, Bonchi F (2022) Fresco: mining frequent patterns in simplicial com- plexes. In: Proceedings of the ACM Web Confer- ence 2022, pp 1444–1454
2022
-
[47]
The VLDB Journal pp 1–24
Preti G, De Francisci Morales G, Bonchi F (2024) Hyper-distance oracles in hypergraphs. The VLDB Journal pp 1–24
2024
-
[48]
Physical Review X 14(3):031,032
Preti G, Fazzone A, Petri G, De Francisci Morales G (2024) Higher-order null models as a lens for so- cial systems. Physical Review X 14(3):031,032
2024
-
[49]
Information Processing Letters 108(2):45–49
Puolam¨ aki K, Hanhij¨ arvi S, Garriga GC (2008) An approximation ratio for biclustering. Information Processing Letters 108(2):45–49
2008
-
[50]
IEEE transactions on pattern analysis and machine intelligence 39(9):1697–1711
Purkait P, Chin TJ, Sadri A, Suter D (2016) Clus- tering with hypergraphs: the case for large hyper- edges. IEEE transactions on pattern analysis and machine intelligence 39(9):1697–1711
2016
-
[51]
Ram´ ırez I, Tepper M (2013) Bi-clustering via mdl- based matrix factorization. In: Progress in Pattern Recognition, Image Analysis, Computer Vision, and Applications: 18th Iberoamerican Congress, CIARP 2013, Havana, Cuba, November 20-23, 2013, Proceedings, Part I 18, Springer, pp 230–237
2013
-
[52]
Data mining and knowledge discovery 31:314–349
Riondato M, Garc´ ıa-Soriano D, Bonchi F (2017) Graph summarization with quality guarantees. Data mining and knowledge discovery 31:314–349
2017
-
[53]
In: Proceedings of the 5th ACM Conference on Bioinformatics, Computa- tional Biology, and Health Informatics, pp 249–258
Ritz A, Murali T (2014) Pathway analysis with signaling hypergraphs. In: Proceedings of the 5th ACM Conference on Bioinformatics, Computa- tional Biology, and Health Informatics, pp 249–258
2014
-
[54]
ACM Transactions on Knowledge Discovery from Data (TKDD) 14(4):1–21
Sun B, Chan THH, Sozio M (2020) Fully dynamic approximate k-core decomposition in hypergraphs. ACM Transactions on Knowledge Discovery from Data (TKDD) 14(4):1–21
2020
-
[55]
In: Proceedings of the 2008 ACM SIGMOD international confer- ence on Management of data, pp 567–580
Tian Y, Hankins RA, Patel JM (2008) Efficient ag- gregation for graph summarization. In: Proceedings of the 2008 ACM SIGMOD international confer- ence on Management of data, pp 567–580
2008
-
[56]
ACM Trans Knowl Dis- cov Data 18(9), DOI 10.1145/3681793
Wang H, Song Y, Chen W, Luo Z, Li C, Li T (2024) A survey of co-clustering. ACM Trans Knowl Dis- cov Data 18(9), DOI 10.1145/3681793
-
[57]
Data Mining and Knowledge Dis- covery 23:215–251
Xiang Y, Jin R, Fuhry D, Dragan FF (2011) Sum- marizing transactional databases with overlapped hyperrectangles. Data Mining and Knowledge Dis- covery 23:215–251
2011
-
[58]
arXiv preprint arXiv:220601394
Xie M, Zhan XX, Liu C, Zhang ZK (2022) Influ- ence maximization in hypergraphs. arXiv preprint arXiv:220601394
2022
-
[59]
In: The World Wide Web Conference, Association for Com- 20 Giulia Preti et al
Yang D, Qu B, Yang J, Cudre-Mauroux P (2019) Revisiting user mobility and social relationships in lbsns: a hypergraph embedding approach. In: The World Wide Web Conference, Association for Com- 20 Giulia Preti et al. puting Machinery, New York, NY, USA, pp 2147– 2157
2019
-
[60]
In: Proceedings of the AAAI Conference on Artificial Intelligence, AAAI Press, Palo Alto, Cal- ifornia USA, vol 32
Zhang M, Cui Z, Jiang S, Chen Y (2018) Beyond link prediction: Predicting hyperlinks in adjacency space. In: Proceedings of the AAAI Conference on Artificial Intelligence, AAAI Press, Palo Alto, Cal- ifornia USA, vol 32
2018
-
[61]
World Wide Web 21:985–1013
Zheng X, Luo Y, Sun L, Ding X, Zhang J (2018) A novel social network hybrid recommender system based on hypergraph topologic structure. World Wide Web 21:985–1013
2018
-
[62]
Advances in neural information pro- cessing systems 19
Zhou D, Huang J, Sch¨ olkopf B (2006) Learning with hypergraphs: Clustering, classification, and embedding. Advances in neural information pro- cessing systems 19
2006
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.