Protein-Based Fish Species Identification: Dataset, Models, and Insights from Native Bangladeshi Fish
Pith reviewed 2026-06-26 21:57 UTC · model grok-4.3
The pith
New dataset and efficient hybrid model enable practical protein-based identification of nine native Bangladeshi fish species
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
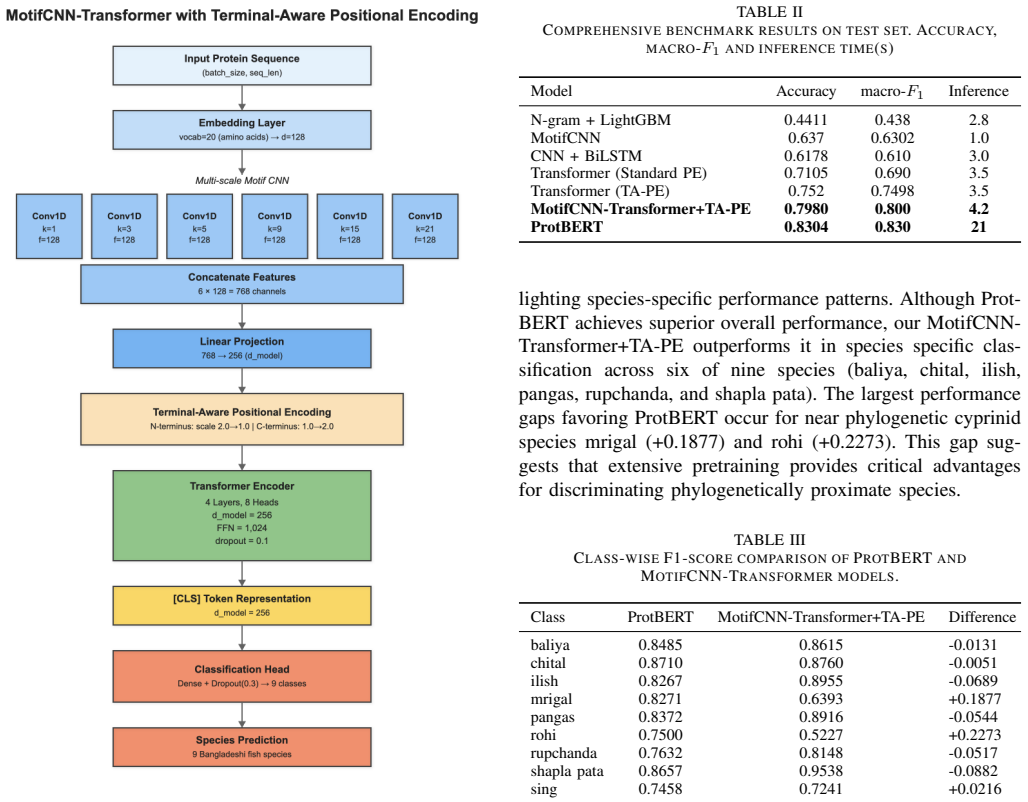
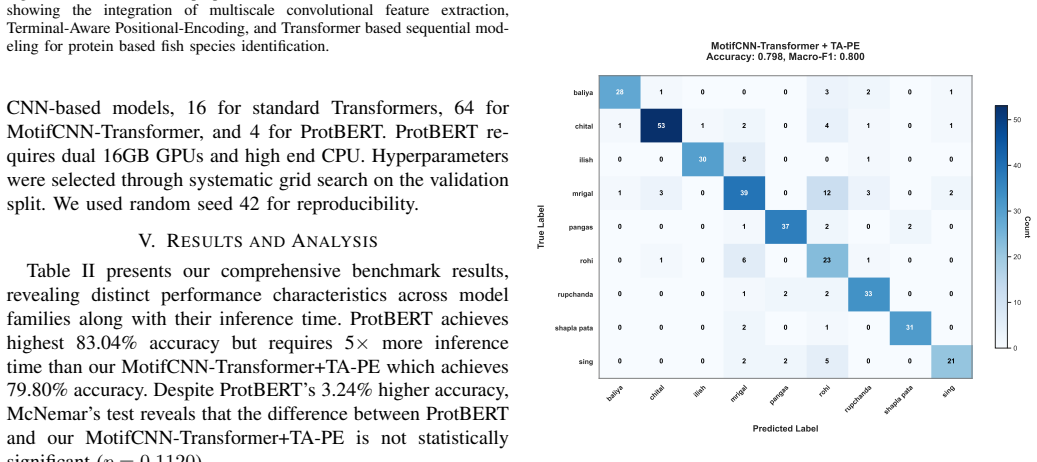
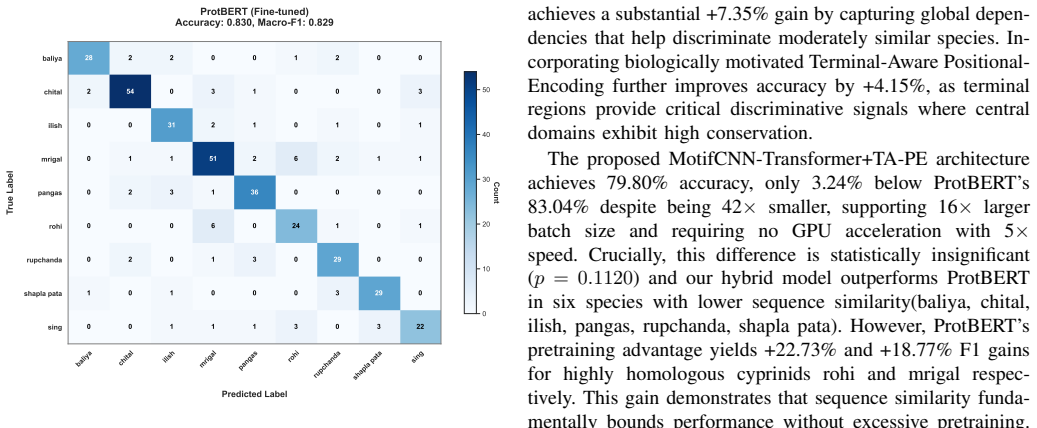
The authors curate 2845 protein sequences across nine Bangladeshi fish species and demonstrate that a proposed MotifCNN-Transformer+TA-PE architecture achieves 79.80% accuracy and 0.80 macro-F1, statistically indistinguishable from the 83.04% of fine-tuned ProtBERT while being 5 times faster, 42 times smaller, and runnable without GPUs.
What carries the argument
MotifCNN-Transformer+TA-PE, a hybrid of convolutional motif detection and transformer layers augmented with terminal-aware positional encoding that processes variable-length protein sequences for species classification
If this is right
- Species authentication becomes feasible in areas without high-end computing hardware
- Pathways open for fisheries management and food authentication in South Asia
- Phylogenetic relationships can guide sequence similarity analysis for biodiversity monitoring
- GPU-free inference supports deployment in rural Bangladesh
Where Pith is reading between the lines
- The approach might generalize to other protein-dependent regions or additional fish species if similar datasets are built
- Combining with other data types like images could improve real-world accuracy beyond sequence-only limits
- The efficiency gains suggest similar hybrids could replace large models in other biological classification tasks
Load-bearing premise
The 2845 sequences form a representative and unbiased sample of the nine species without systematic curation artifacts that inflate classification performance
What would settle it
Collecting new protein sequences from the same nine species but from different individuals or locations and finding that accuracy drops below 70 percent would challenge the model's reliability
Figures

read the original abstract
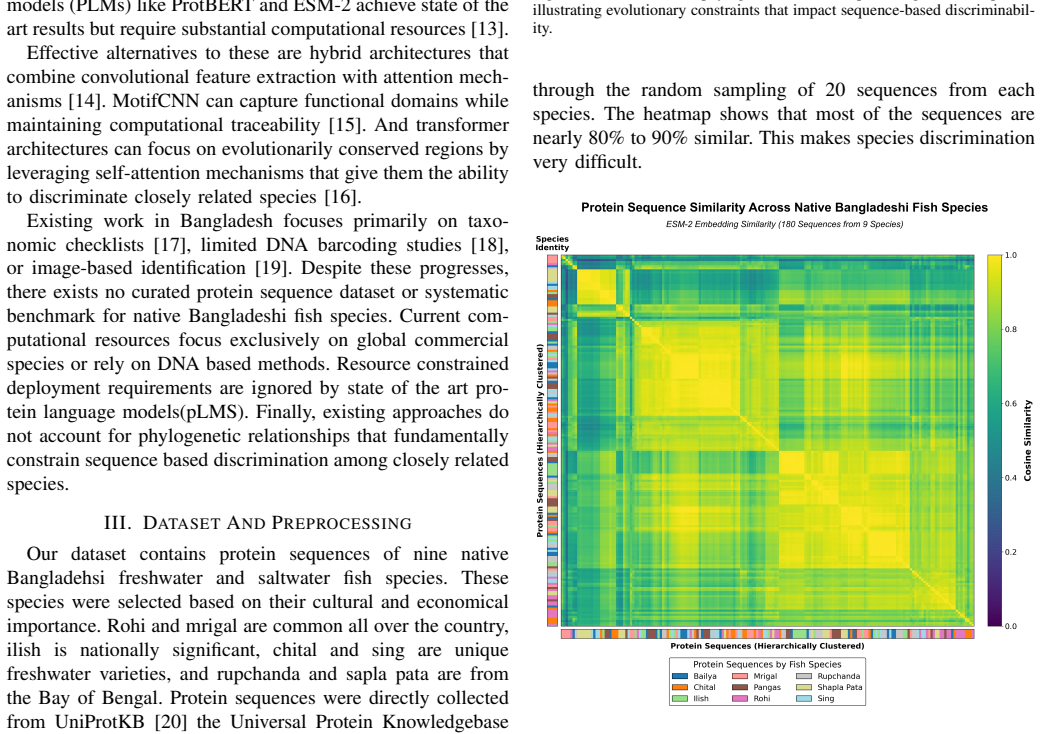
Correct identification of fish species is highly significant for food security, economic development, and climate resilience in Bangladesh. Protein sequences directly reflect functional and evolutionary constraints which are important for species authentication and biodiversity monitoring. Yet there exists no benchmark for native Bangladeshi fish species identification from protein sequence. In this study, we addressed this gap by introducing the first curated dataset for nine native Bangladeshi fish species of 2845 high quality protein sequences. We also established the first protein sequence classification baseline for this domain through a systematic benchmarking of seven architectural paradigms. Moreover, we propose a realistic deployable novel hybrid architecture of MotifCNN and Transformer with Terminal-Aware Positional-Encoding (MotifCNN-Transformer+TA-PE). Our novel architecture achieves 79.80% accuracy with macro-F1 of 0.80. The highest 83.04% accuracy is achieved by finetuned protein language model ProtBERT that has 420M parameters and requires dual 16GB GPUs for inference. According to McNemar's test, ProtBERT's 3.24% accuracy gain over our MotifCNN-Transformer+TA-PE is statistically insignificant (p = 0.1120). Our novel architecture beats it among six of the nine classes in per class identification. Also our MotifCNN-Transformer+TA-PE is approximately 5x faster, 42x smaller, and supports 16x larger batch size than ProtBERT and has GPU free inference, making it more practical for deployment in resources constrained areas such as rural Bangladesh. Beyond this, our foundational work shows effects of phylogenetic relationships on sequence similarity and establishes pathways for fisheries management, food authentication and biodiversity conservation in South Asia's protein dependent economy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the first curated dataset of 2845 protein sequences from nine native Bangladeshi fish species and establishes the first classification baselines by benchmarking seven architectural paradigms. It proposes a novel hybrid MotifCNN-Transformer+TA-PE model that achieves 79.80% accuracy and 0.80 macro-F1, statistically indistinguishable from ProtBERT's 83.04% accuracy per McNemar's test (p=0.1120), while claiming superior efficiency (5x faster, 42x smaller, GPU-free inference) for deployment in resource-constrained settings.
Significance. If the dataset is shown to be representative without curation artifacts, the work supplies a valuable benchmark for protein-based species identification relevant to food security and biodiversity monitoring in South Asia; the inclusion of McNemar's tests and per-class results strengthens the empirical comparison, and the efficiency claims (if substantiated) address practical deployment needs.
major comments (2)
- [Dataset construction] Dataset construction section: the representativeness of the 2845 sequences is a load-bearing assumption for all reported accuracies, per-class wins, and McNemar's test results, yet the manuscript provides no details on selection criteria, gene sources, geographic sampling, or curation filters that could introduce intra-species similarity biases hinted at by the phylogenetic analysis.
- [Benchmarking and experimental setup] Benchmarking and experimental setup (abstract and results): the central performance claims (79.80% vs 83.04%) and efficiency comparisons rest on unreported train/test splits, sequence preprocessing, and leakage-prevention steps; without these, the statistical insignificance conclusion and deployment practicality assertions cannot be evaluated.
minor comments (2)
- [Abstract] Abstract: the phrase 'high quality protein sequences' is used without defining the quality thresholds or filtering criteria applied during curation.
- [Results] The efficiency claims (5x faster, 42x smaller, 16x larger batch size) are presented without accompanying implementation details or hardware specifications that would allow independent verification.
Simulated Author's Rebuttal
We thank the referee for their detailed and constructive review. The comments identify areas where additional methodological transparency is needed to support the claims. We address each major comment below and will revise the manuscript accordingly to improve reproducibility and clarity.
read point-by-point responses
-
Referee: [Dataset construction] Dataset construction section: the representativeness of the 2845 sequences is a load-bearing assumption for all reported accuracies, per-class wins, and McNemar's test results, yet the manuscript provides no details on selection criteria, gene sources, geographic sampling, or curation filters that could introduce intra-species similarity biases hinted at by the phylogenetic analysis.
Authors: We acknowledge that the original Dataset construction section lacks explicit details on selection criteria, gene sources, geographic sampling, and curation filters. In the revised manuscript we will expand this section to document: sequence sources (e.g., NCBI/UniProt accessions), quality and length filters applied, any available geographic metadata for Bangladeshi specimens, and further discussion of how phylogenetic structure was considered when assessing potential intra-species similarity biases. These additions will directly address the representativeness concern. revision: yes
-
Referee: [Benchmarking and experimental setup] Benchmarking and experimental setup (abstract and results): the central performance claims (79.80% vs 83.04%) and efficiency comparisons rest on unreported train/test splits, sequence preprocessing, and leakage-prevention steps; without these, the statistical insignificance conclusion and deployment practicality assertions cannot be evaluated.
Authors: We agree that the experimental protocol details were insufficient. The revised manuscript will add a dedicated Experimental Setup subsection specifying: the train/test split ratios and stratification method, sequence preprocessing (length handling, tokenization, padding), and explicit leakage-prevention steps (e.g., ensuring no identical or highly similar sequences cross the split). These clarifications will allow independent evaluation of the accuracy figures, McNemar's test, and efficiency comparisons. revision: yes
Circularity Check
No circularity detected; empirical benchmarking is self-contained
full rationale
The paper constructs a new dataset of 2845 protein sequences for nine fish species and reports classification accuracies (e.g., 79.80% for the proposed MotifCNN-Transformer+TA-PE and 83.04% for ProtBERT) obtained via standard training and evaluation on that dataset. No equations, derivations, or load-bearing claims reduce these metrics to fitted parameters defined by the authors themselves, nor do they rely on self-citations for uniqueness theorems or ansatzes. The performance numbers and McNemar tests follow directly from applying external model architectures to the curated sequences, with no self-definitional loops or renaming of known results as novel derivations. The central claims remain independent of the paper's own inputs.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Protein sequences contain sufficient phylogenetic and functional signal to discriminate among the nine fish species
Reference graph
Works this paper leans on
-
[1]
Fisheries in the context of attaining sustainable development goals (sdgs) in bangladesh: Covid-19 impacts and future prospects,
A. R. Sunny, M. H. Mithun, S. H. Prodhan, M. Ashrafuzzaman, S. M. A. Rahman, M. M. Billah, M. Hussain, K. J. Ahmed, S. A. Sazzad, M. T. Alam, A. Rashid, and M. M. Hossain, “Fisheries in the context of attaining sustainable development goals (sdgs) in bangladesh: Covid-19 impacts and future prospects,”Sustainability, vol. 13, no. 17, 2021. [Online]. Availa...
2021
-
[2]
Integrated dna barcoding methods to identify species in the processed fish products from chinese market,
S. Zhao, H. Zhang, Z. Zhao, Y . Zhang, J. Yu, Y . Tang, and C. Zhou, “Integrated dna barcoding methods to identify species in the processed fish products from chinese market,”Food Research International, vol. 182, p. 114140, 2024. [Online]. Available: https://www.sciencedirect.com/science/article/pii/S0963996924002102
2024
-
[3]
A. Meledina, D. Straka, F. Soucek, T. A. Smirnova, and S. Kuckova, “Rapid determination of fish species of raw and heat-treated fish meat using proteomic species-specific markers,”Food Technology and Biotechnology, vol. 63, no. 3, pp. 287–297, Jul–Sep 2025, epub 2025 Aug 31. PMID: 41000212; PMCID: PMC12413489. [Online]. Available: https://pubmed.ncbi.nlm....
arXiv 2025
-
[4]
Proteomics for species authentication of cod and corresponding fishery products,
H.-J. Chien, Y .-H. Huang, Y .-F. Zheng, W.-C. Wang, C.-Y . Kuo, G.-J. Wei, and C.-C. Lai, “Proteomics for species authentication of cod and corresponding fishery products,”Food Chemistry, vol. 374, p. 131631, 2022. [Online]. Available: https://www.sciencedirect.com/ science/article/pii/S0308814621026376
2022
-
[5]
A comparative morphological analysis of body and fin shape for eight shark species,
D. J. Irschick, A. Fu, G. Lauder, C. Wilga, C.-Y . Kuo, and N. Hammerschlag, “A comparative morphological analysis of body and fin shape for eight shark species,”Biological Journal of the Linnean Society, vol. 122, no. 3, pp. 589–604, 08 2017. [Online]. Available: https://doi.org/10.1093/biolinnean/blx088
-
[6]
S. Adhikary, S. Banerjee, R. Singh, and A. D. Dwivedi, “Fish species identification on low resolution—a study with enhanced super- resolution generative adversarial network (esrgan), yolo and vgg-16,” PeerJ Computer Science, vol. 11, p. e2860, 2025. [Online]. Available: https://pubmed.ncbi.nlm.nih.gov/40567807/
arXiv 2025
-
[7]
Dna barcoding for identification of fish species in the taiwan strait,
X. Bingpeng, L. Heshan, Z. Zhilan, W. Chunguang, W. Yanguo, and W. Jianjun, “Dna barcoding for identification of fish species in the taiwan strait,”PLOS ONE, vol. 13, no. 6, pp. 1–13, 06 2018. [Online]. Available: https://doi.org/10.1371/journal.pone.0198109
-
[8]
Dna barcodes are ineffective for species identification of acropora corals from the aquarium trade,
Z. B. R. Quek, Z. T. Yip, S. S. Jain, H. X. V . Wong, Z. Tan, A. R. Joseph, and D. Huang, “Dna barcodes are ineffective for species identification of acropora corals from the aquarium trade,” Biodiversity Data Journal, vol. 12, p. e125914, 2024. [Online]. Available: https://doi.org/10.3897/BDJ.12.e125914
-
[9]
Xai-driven deep learning for protein sequence functional group classification,
P. Chakraborty and A. Bhargava, “Xai-driven deep learning for protein sequence functional group classification,” 2025. [Online]. Available: https://arxiv.org/abs/2511.13791
arXiv 2025
-
[10]
An efficient deep learning approach for dna-binding proteins classification from primary sequences,
N. Y . Ahmed, W. A. Alsanousi, E. M. Hamid, M. K. Elbashir, K. M. Al-Aidarous, M. Mohammed, and M. E. M. Musa, “An efficient deep learning approach for dna-binding proteins classification from primary sequences,”International Journal of Computational Intelligence Sys- tems, vol. 17, no. 1, p. 88, Apr. 2024
2024
-
[11]
Ai and machine learning in biology: From genes to proteins,
Z. M. Hein, D. Guruparan, B. Okunsai, C. M. N. Che Mohd Nassir, M. D. C. Ramli, and S. Kumar, “Ai and machine learning in biology: From genes to proteins,”Biology, vol. 14, no. 10, 2025. [Online]. Available: https://www.mdpi.com/2079-7737/14/10/1453
2025
-
[12]
Why transformers outperform lstms: A comparative study on sarcasm detection,
P. Bari, G. Bedi, K. Joshi, and A. Jawale, “Why transformers outperform lstms: A comparative study on sarcasm detection,”Journal on Artificial Intelligence, vol. 7, no. 1, pp. 499–508, 2025. [Online]. Available: http://www.techscience.com/jai/v7n1/64530
2025
-
[13]
Evolutionary-scale prediction of atomic-level protein structure with a language model , volume =
Z. Lin, H. Akin, R. Rao, B. Hie, Z. Zhu, W. Lu, N. Smetanin, R. Verkuil, O. Kabeli, Y . Shmueli, A. dos Santos Costa, M. Fazel- Zarandi, T. Sercu, S. Candido, and A. Rives, “Evolutionary-scale prediction of atomic-level protein structure with a language model,” Science, vol. 379, no. 6637, pp. 1123–1130, 2023. [Online]. Available: https://www.science.org/...
-
[14]
A fast (cnn + mcws-transformer) based architecture for protein function prediction,
A. Mahala, A. Ranjan, R. Priyadarshini, R. Vikram, and P. Dansena, “A fast (cnn + mcws-transformer) based architecture for protein function prediction,”Statistical Applications in Genetics and Molecular Biology, vol. 24, no. 1, Jul. 2025, pMID: 40586353. [Online]. Available: https://pubmed.ncbi.nlm.nih.gov/40586353/
arXiv 2025
-
[15]
Motif-based convolutional neural network on graphs,
A. Sankar, X. Zhang, and K. C.-C. Chang, “Motif-based convolutional neural network on graphs,” 2019. [Online]. Available: https://arxiv.org/ abs/1711.05697
Pith/arXiv arXiv 2019
-
[16]
Transformer architecture and attention mechanisms in genome data analysis: A comprehensive review,
S. R. Choi and M. Lee, “Transformer architecture and attention mechanisms in genome data analysis: A comprehensive review,” Biology, vol. 12, no. 7, 2023. [Online]. Available: https://www.mdpi. com/2079-7737/12/7/1033
2023
-
[17]
An updated checklist of marine fishes of bangladesh,
K. Habib and M. ISLAM, “An updated checklist of marine fishes of bangladesh,”Bangladesh Journal of Fisheries, vol. 32, pp. 357–367, 01 2021
2021
-
[18]
Molecular characteriza- tion of small indigenous fish species (sis) of bangladesh through dna barcodes,
M. S. Ahmed, M. Chowdhury, and L. Nahar, “Molecular characteriza- tion of small indigenous fish species (sis) of bangladesh through dna barcodes,”Gene, vol. 684, 10 2018
2018
-
[19]
Bd-freshwater-fish: An image dataset from bangladesh for ai- powered automatic fish species classification and detection toward smart aquaculture,
P. Das, M. Kawsar, P. Biswas Paul, A. A. Hridoy, M. Hossain, and S. Niloy, “Bd-freshwater-fish: An image dataset from bangladesh for ai- powered automatic fish species classification and detection toward smart aquaculture,”Data in Brief, vol. 57, p. 111132, 11 2024
2024
-
[20]
Uniprot: the universal protein knowledgebase in 2025,
T. U. Consortium, “Uniprot: the universal protein knowledgebase in 2025,”Nucleic Acids Research, vol. 53, no. D1, pp. D609–D617, 11
2025
-
[21]
[Online]. Available: https://doi.org/10.1093/nar/gkae1010
-
[22]
Database resources of the national center for biotechnology information in 2025,
E. W. Sayerset al., “Database resources of the national center for biotechnology information in 2025,”Nucleic Acids Research, vol. 53, no. D1, pp. D20–D29, 2025. [Online]. Available: https: //pubmed.ncbi.nlm.nih.gov/39526373/
arXiv 2025
-
[23]
Different low-complexity regions of sfpq play distinct roles in the formation of biomolecular condensates,
A. C. Marshall, J. Cummins, S. Kobelke, T. Zhu, J. Widagdo, V . Anggono, A. Hyman, A. H. Fox, C. S. Bond, and M. Lee, “Different low-complexity regions of sfpq play distinct roles in the formation of biomolecular condensates,”Journal of Molecular Biology, vol. 435, no. 24, p. 168364, 2023. [Online]. Available: https://www.sciencedirect.com/science/article...
2023
-
[24]
Quality control of purified proteins to improve data quality and reproducibility: results from a large-scale survey,
N. Berrow, A. de Marco, M. Lebendiker, M. Garcia-Alai, S. H. Knauer, B. Lopez-Mendez, A. Matagne, A. Parret, K. Remans, S. Uebel, and B. Raynal, “Quality control of purified proteins to improve data quality and reproducibility: results from a large-scale survey,”European Bio- physics Journal, vol. 50, no. 3, pp. 453–460, May 2021
2021
-
[25]
Molecular signature of hypersaline adaptation: insights from genome and proteome composition of halophilic prokaryotes,
S. Paul, S. K. Bag, S. Das, E. T. Harvill, and C. Dutta, “Molecular signature of hypersaline adaptation: insights from genome and proteome composition of halophilic prokaryotes,”Genome Biology, vol. 9, no. 4, p. R70, Apr. 2008
2008
-
[26]
Life at high salt concentrations, intracellular kcl concentrations, and acidic proteomes,
A. Oren, “Life at high salt concentrations, intracellular kcl concentrations, and acidic proteomes,”Frontiers in Microbiology, vol. V olume 4 - 2013, 2013. [Online]. Available: https://www. frontiersin.org/journals/microbiology/articles/10.3389/fmicb.2013.00315
-
[27]
Deeploc: prediction of protein subcellular localization using deep learning,
J. Armenteros, C. Sønderby, S. Sønderby, H. Nielsen, and O. Winther, “Deeploc: prediction of protein subcellular localization using deep learning,”Bioinformatics (Oxford, England), vol. 33, 07 2017
2017
-
[28]
Proteinbert: a universal deep-learning model of protein sequence and function,
N. Brandes, D. Ofer, Y . Peleg, N. Rappoport, and M. Linial, “Proteinbert: a universal deep-learning model of protein sequence and function,”Bioinformatics, vol. 38, no. 8, pp. 2102–2110, 02 2022. [Online]. Available: https://doi.org/10.1093/bioinformatics/btac020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.