A Link between Shock-wave Theory and Symmetry-reduced Stochastic Gradient Descent for Artificial Neural Networks
Pith reviewed 2026-06-27 02:16 UTC · model grok-4.3
The pith
Symmetry-quotiented SGD dynamics in neural networks reduce to a viscous Hamilton-Jacobi equation whose gradient obeys a Burgers-type equation with possible shock formation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
After quotienting parameter symmetries and applying local-entropy coarse-graining, the effective dynamics satisfy a viscous Hamilton--Jacobi equation on the quotient manifold. Under the assumption that the raw parameter dynamics can be summarized by a gradient field on the quotiented space, the gradient of the coarse-grained loss function obeys a Burgers-type equation, and shock formation can be established rigorously. The same equations hold for multilayer perceptrons, convolutional neural networks, Transformers, and mean-field networks.
What carries the argument
Symmetry quotienting of parameter space via Lie groups, followed by local-entropy coarse-graining, which produces a viscous Hamilton-Jacobi equation on the quotient manifold whose gradient satisfies a Burgers-type equation.
If this is right
- Multilayer perceptrons, convolutional networks, Transformers, and mean-field networks all obey the derived Hamilton-Jacobi or Burgers-type equations after symmetry reduction.
- Shock formation can be established rigorously once the gradient-field assumption holds on the quotient manifold.
- Symmetry-corrected quotient observables supply a principled basis for monitoring, forecasting, and controlling training-phase transitions.
- Raw parameter norms in architectures such as Transformers are often distorted by symmetry redundancy and therefore misleading.
Where Pith is reading between the lines
- The Burgers-shock picture may suggest new regularization strategies that explicitly damp or steer shock locations during training.
- The same quotient construction could be applied to other first-order optimizers to test whether their reduced dynamics also admit fluid-mechanical descriptions.
- Symmetry-corrected observables might serve as early-warning signals for generalization transitions that are invisible in the original parameter space.
Load-bearing premise
The raw parameter dynamics can be summarized by a gradient field on the quotiented space.
What would settle it
A direct numerical check showing that the gradient of the coarse-grained loss in a symmetry-quotiented multilayer perceptron fails to satisfy the Burgers-type equation would falsify the claimed reduction.
Figures

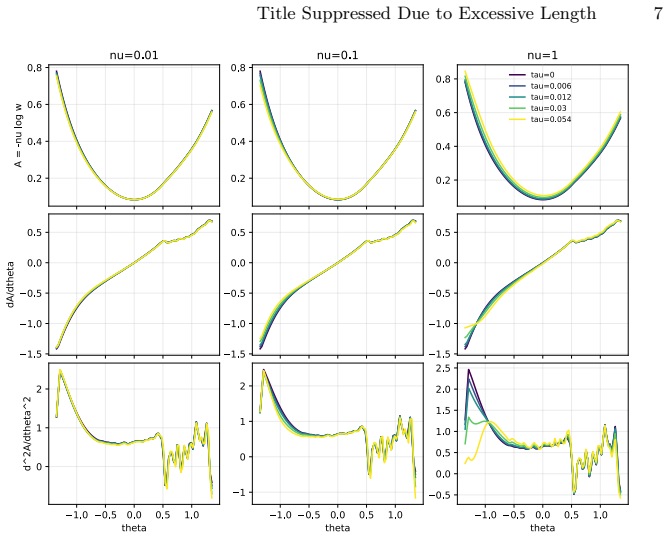
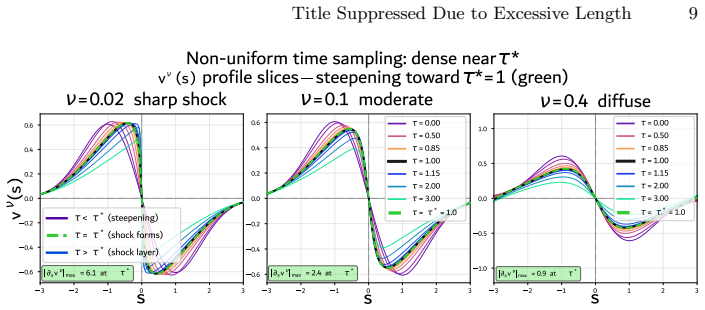
read the original abstract
We develop a mathematically explicit link between shock-wave theory and the symmetry-quotiented learning dynamics of stochastic gradient descent, drawing on differential geometry, Lie group theory, and fluid mechanics. Specifically, after quotienting parameter symmetries and applying local-entropy coarse-graining, the effective dynamics satisfy a viscous Hamilton--Jacobi equation on the quotient manifold. Moreover, under the assumption that the raw parameter dynamics can be summarized by a gradient field on the quotiented space, the gradient of the coarse-grained loss function obeys a Burgers-type equation, and shock formation can be established rigorously. We apply our theory to multilayer perceptrons, convolutional neural networks, Transformers, and mean-field networks, and show that they obey the Hamilton--Jacobi or Burgers-type equations. We conjecture that this framework also yields practical diagnostics for deep learning. In architectures such as Transformers, raw parameter norms are often distorted by symmetry redundancy and may therefore be misleading, whereas symmetry-corrected quotient observables provide a principled basis for monitoring, forecasting, and controlling training-phase transitions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims to establish a rigorous connection between shock-wave theory and the symmetry-quotiented dynamics of stochastic gradient descent in artificial neural networks. By quotienting out parameter symmetries and applying local-entropy coarse-graining, the effective dynamics are shown to satisfy a viscous Hamilton--Jacobi equation on the quotient manifold. Under the additional assumption that the raw parameter dynamics can be summarized by a gradient field on this quotient space, the gradient of the coarse-grained loss function is shown to obey a Burgers-type equation, allowing for rigorous establishment of shock formation. The framework is then applied to multilayer perceptrons, convolutional neural networks, Transformers, and mean-field networks, asserting that they obey these equations, with conjectures on practical diagnostics for training.
Significance. If the central assumption regarding the gradient-field summarization holds and the derivations are correct, the work offers a potentially significant interdisciplinary link between differential geometry, fluid mechanics, and machine learning theory. It could provide new analytical tools for understanding symmetry effects and phase transitions in deep learning training, particularly for architectures like Transformers where symmetry redundancy affects parameter norms. The explicit mathematical framework and conjectured diagnostics represent a strength if substantiated.
major comments (1)
- [Applications to architectures (abstract and corresponding section)] The assertion that MLPs, CNNs, Transformers, and mean-field networks obey the Hamilton--Jacobi or Burgers-type equations (as stated in the abstract and the applications section) rests on the unexamined assumption that their raw parameter dynamics can be summarized by a gradient field on the quotiented space. No explicit check or justification is provided that SGD trajectories for these architectures satisfy this condition (e.g., absence of non-gradient components from mini-batch noise or residual symmetries). This assumption is load-bearing for the Burgers equation and shock-formation results, so the applicability claims require verification or qualification.
minor comments (1)
- [Abstract] The abstract introduces 'local-entropy coarse-graining' without a brief inline definition or forward reference to its definition in the main text.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback. We address the single major comment below.
read point-by-point responses
-
Referee: [Applications to architectures (abstract and corresponding section)] The assertion that MLPs, CNNs, Transformers, and mean-field networks obey the Hamilton--Jacobi or Burgers-type equations (as stated in the abstract and the applications section) rests on the unexamined assumption that their raw parameter dynamics can be summarized by a gradient field on the quotiented space. No explicit check or justification is provided that SGD trajectories for these architectures satisfy this condition (e.g., absence of non-gradient components from mini-batch noise or residual symmetries). This assumption is load-bearing for the Burgers equation and shock-formation results, so the applicability claims require verification or qualification.
Authors: We agree that the gradient-field assumption is essential for the Burgers-type equation and the rigorous shock-formation result. The viscous Hamilton--Jacobi equation on the quotient manifold follows directly from symmetry quotienting and local-entropy coarse-graining without this assumption. The manuscript applies the general framework to MLPs, CNNs, Transformers, and mean-field networks to obtain the Hamilton--Jacobi dynamics; the Burgers equation is invoked only under the additional gradient-field hypothesis. We will revise the abstract and applications section to make this distinction explicit, qualify the Burgers and shock claims as conditional on the assumption, and note that empirical verification of the assumption for these architectures remains an open question for future work. revision: yes
Circularity Check
No circularity; derivation conditional on explicit assumption with no self-referential reduction
full rationale
The provided abstract and context show a derivation that first obtains a viscous Hamilton-Jacobi equation via symmetry quotienting and local-entropy coarse-graining. It then states an explicit assumption ('under the assumption that the raw parameter dynamics can be summarized by a gradient field on the quotiented space') before deriving the Burgers-type equation and rigorous shock formation. Application to MLPs, CNNs, Transformers and mean-field networks is presented as obeying the equations, but this is framed under the same stated assumption rather than by redefining inputs to match outputs. No self-definitional loop, fitted parameter renamed as prediction, or load-bearing self-citation chain appears. The assumption is load-bearing for the strongest claim yet is openly declared and not constructed from the target result itself. This satisfies the default expectation of non-circularity for a mathematically conditional derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The raw parameter dynamics can be summarized by a gradient field on the quotiented space
Reference graph
Works this paper leans on
-
[1]
Path-sgd: Path- normalized optimization in deep neural networks
Neyshabur, Behnam, Russ R. Salakhutdinov, and Nati Srebro. "Path-sgd: Path- normalized optimization in deep neural networks."Advances in neural information processing systems28 (2015)
2015
-
[2]
A scale invariant flatness measure for deep network minima
Rangamani, Akshay, et al. "A scale invariant flatness measure for deep network minima."arXiv preprintarXiv:1902.02434 (2019)
Pith/arXiv arXiv 1902
-
[3]
Deep relaxation: partial differential equations for opti- mizing deep neural networks
Chaudhari, Pratik, et al. "Deep relaxation: partial differential equations for opti- mizing deep neural networks."Research in the Mathematical Sciences5.3 (2018): 30
2018
-
[4]
Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations
Li, Qianxiao, and Cheng Tai. "Stochastic modified equations and dynamics of stochastic gradient algorithms i: Mathematical foundations."Journal of Machine Learning Research20.40 (2019): 1-47
2019
-
[5]
Stochastic modified flows, mean-field limits and dynamics of stochastic gradient descent
Gess, Benjamin, Sebastian Kassing, and Vitalii Konarovskyi. "Stochastic modified flows, mean-field limits and dynamics of stochastic gradient descent."Journal of Machine Learning Research25.30 (2024): 1-27
2024
-
[6]
Theoretical analysis of auto rate- tuning by batch normalization
Arora, Sanjeev, Zhiyuan Li, and Kaifeng Lyu. "Theoretical analysis of auto rate- tuning by batch normalization."arXiv preprintarXiv:1812.03981 (2018)
Pith/arXiv arXiv 2018
-
[7]
A mean field view of the landscape of two-layer neural networks
Mei, Song, Andrea Montanari, and Phan-Minh Nguyen. "A mean field view of the landscape of two-layer neural networks."Proceedings of the National Academy of Sciences115.33 (2018): E7665-E7671. Title Suppressed Due to Excessive Length 15
2018
-
[8]
Mean field analysis of deep neural networks
Sirignano, Justin, and Konstantinos Spiliopoulos. "Mean field analysis of deep neural networks."Mathematics of Operations Research47.1 (2022): 120-152
2022
-
[9]
Hide & seek: Transformer symmetries obscure sharpness & Riemannian geometry finds it
Da Silva, Marvin F., Felix Dangel, and Sageev Oore. "Hide & seek: Transformer symmetries obscure sharpness & Riemannian geometry finds it."arXiv preprint arXiv:2505.05409 (2025)
arXiv 2025
-
[10]
Evans, Lawrence C.Partial differential equations.Vol. 19. American mathematical society, 2022
2022
-
[11]
Leveque.Numerical methods for conservation laws
LeVeque, Randall J., and Randall J. Leveque.Numerical methods for conservation laws. Vol. 132. Basel: Birkhäuser, 1992
1992
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.