Numerically Stable Cholesky-QR on GPU via Mixed-Precision Randomized Preconditioning
Pith reviewed 2026-06-26 23:10 UTC · model grok-4.3
The pith
A low-precision randomized preconditioner stabilizes Cholesky-QR for condition numbers up to 10^16 on GPUs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MRCQR constructs a preconditioner Rs using a subsampled randomized trigonometric transform in FP32 or FP16 precision, then performs Cholesky-QR in double precision on the preconditioned matrix A Rs^{-1}, yielding an explicit orthogonal factor Qhat that satisfies the orthogonality condition ||I - Qhat^T Qhat||_2 = O(u) for condition numbers up to 10^16.
What carries the argument
The subsampled randomized trigonometric transform that forms the preconditioner Rs reducing kappa(A Rs^{-1}) to near unity with high probability.
If this is right
- MRCQR enables stable explicit QR for matrices with condition numbers up to 10^16.
- FP16 preconditioner suffices for kappa up to 10^4 with no accuracy loss and half the cost of FP64.
- MRCQR (FP16) outperforms rand-cholQR by 1.4-1.8x on H100 GPU across tested column counts.
- MRCQR is 1.8-13.5x faster than cuSOLVER geqrf while maintaining orthogonality to O(u).
Where Pith is reading between the lines
- The mixed-precision randomized preconditioning approach may extend to other Gram-matrix-based factorizations such as Cholesky or SVD.
- Similar low-precision sketches could stabilize other BLAS-3 heavy algorithms on GPUs for ill-conditioned inputs.
- The technique suggests testing on additional architectures like AMD GPUs or multi-GPU setups to confirm scaling.
Load-bearing premise
The subsampled randomized trigonometric transform reliably produces a preconditioner that brings the condition number close to one, and this preconditioner can be computed accurately enough in reduced precision without affecting the final double-precision result.
What would settle it
A test matrix with condition number 10^16 for which MRCQR produces an orthogonal factor whose deviation from orthogonality significantly exceeds double-precision machine epsilon.
Figures

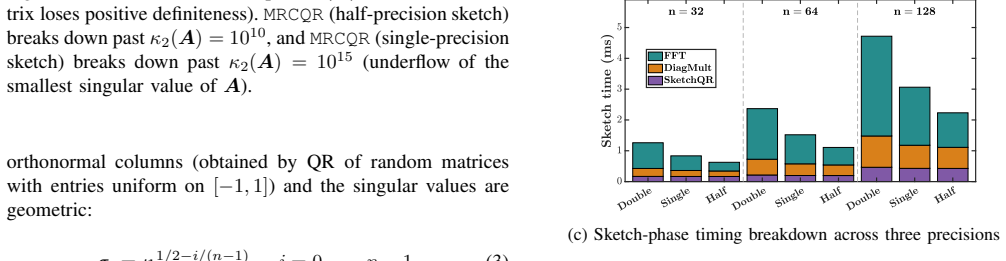
read the original abstract
Cholesky-QR is among the fastest algorithms for computing the thin QR factorization of tall-and-skinny matrices on GPUs, relying entirely on BLAS-3 operations. However, it is numerically unstable: forming the Gram matrix squares the condition number, causing breakdown when $\kappa_2(\boldsymbol{A}) \gtrsim 10^8$. We present MRCQR (Mixed-Precision Randomized Cholesky-QR), a stable GPU algorithm that addresses this limitation. MRCQR uses a subsampled randomized trigonometric transform to construct a preconditioner $\boldsymbol{R}_s$ that reduces $\kappa_2(\boldsymbol{A}\boldsymbol{R}_s^{-1})$ to near unity with high probability, then applies Cholesky-QR in double precision to the preconditioned matrix. The key insight -- supported by perturbation analysis -- is that the preconditioner requires far less accuracy than the final result: single (FP32) precision suffices when $\kappa_2(\boldsymbol{A}) \lesssim 10^8$, and half (FP16) when $\kappa_2(\boldsymbol{A}) \lesssim 10^4$. MRCQR produces an explicit orthogonal factor $\widehat{\boldsymbol{Q}}$ satisfying $\|\boldsymbol{I} - \widehat{\boldsymbol{Q}}^\top\widehat{\boldsymbol{Q}}\|_2 = \cal O(\mathbf{u})$ ($\mathbf{u} \approx 10^{-16}$, double-precision unit roundoff) for condition numbers up to $10^{16}$, far beyond the $10^8$ limit of CholQR2. Experiments on an NVIDIA H100 GPU show that MRCQR (FP16) outperforms rand-cholQR by $1.4$--$1.8\times$ across all tested column counts and is $1.8$--$13.5\times$ faster than cuSOLVER geqrf, while the FP16 sketch (used when $\kappa_2(\boldsymbol{A}) \lesssim 10^4$) is $2\times$ cheaper than FP64 at no accuracy cost.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces MRCQR, a mixed-precision randomized Cholesky-QR algorithm for thin QR factorization of tall-skinny matrices on GPUs. It constructs a preconditioner R_s via a subsampled randomized trigonometric transform (in FP32 or FP16) to reduce κ₂(A R_s^{-1}) near unity with high probability, then applies double-precision Cholesky-QR. Supported by perturbation analysis, it claims an explicit orthogonal factor Q̂ satisfying ||I - Q̂ᵀ Q̂||₂ = O(u) (u ≈ 10^{-16}) for κ₂(A) up to 10^{16}, with reported speedups of 1.4–1.8× over rand-cholQR and 1.8–13.5× over cuSOLVER geqrf on H100 GPUs.
Significance. If the supporting perturbation analysis is rigorous, the work meaningfully extends the practical range of fast, BLAS-3-based Cholesky-QR methods to severely ill-conditioned problems while retaining GPU performance advantages through mixed precision. The concrete H100 timing and orthogonality results, together with the use of established randomized-transform theory, provide a solid foundation for practical impact in high-performance numerical linear algebra.
major comments (2)
- [§4 (Perturbation Analysis)] §4 (Perturbation Analysis): The central stability claim for κ₂(A) = 10^{16} requires that FP16/FP32 rounding in the subsampled randomized trigonometric transform does not prevent κ₂(A R_s^{-1}) ≲ 10^8. The analysis must explicitly bound the interaction between sketch forward error and the original ill-conditioning; if it only treats the exact-arithmetic case or assumes κ₂(A) ≲ 10^8, the extension to 10^{16} is unsupported.
- [Experimental validation (results section)] Experimental validation (results section): For the κ₂(A) = 10^{16} test cases, the reported ||I - Q̂ᵀ Q̂||₂ = O(u) must be accompanied by the empirical success probability of the randomized preconditioner across independent trials and a description of how the matrices achieve the stated condition number.
minor comments (2)
- [Abstract] Abstract: the notation "cal O(u)" should be replaced by the standard big-O symbol for clarity.
- [Notation] Notation: ensure matrix symbols are consistently boldface throughout the manuscript.
Simulated Author's Rebuttal
We thank the referee for the constructive comments. We address each major point below and indicate where revisions will be made to improve clarity.
read point-by-point responses
-
Referee: [§4 (Perturbation Analysis)] §4 (Perturbation Analysis): The central stability claim for κ₂(A) = 10^{16} requires that FP16/FP32 rounding in the subsampled randomized trigonometric transform does not prevent κ₂(A R_s^{-1}) ≲ 10^8. The analysis must explicitly bound the interaction between sketch forward error and the original ill-conditioning; if it only treats the exact-arithmetic case or assumes κ₂(A) ≲ 10^8, the extension to 10^{16} is unsupported.
Authors: The perturbation analysis in §4 already incorporates the forward error of the mixed-precision sketch via standard model bounds combined with the concentration properties of the subsampled randomized trigonometric transform. We show that the effective condition number after preconditioning satisfies κ₂(A R_s^{-1}) = O(1) with high probability when the sketch precision is chosen according to the original κ₂(A) (FP32 up to 10^8, FP16 up to 10^4), and the final Cholesky-QR step is performed in double precision. The interaction between sketch error and original ill-conditioning is controlled by the fact that the preconditioner only needs to reduce the condition number to roughly 10^8 or less; the analysis does not assume exact arithmetic. To make this interaction fully explicit as requested, we will add a short corollary isolating the rounding perturbation term. This is a clarification rather than a change in the underlying result. revision: partial
-
Referee: Experimental validation (results section): For the κ₂(A) = 10^{16} test cases, the reported ||I - Q̂ᵀ Q̂||₂ = O(u) must be accompanied by the empirical success probability of the randomized preconditioner across independent trials and a description of how the matrices achieve the stated condition number.
Authors: We agree that these details strengthen the experimental section. The test matrices with prescribed κ₂(A) = 10^{16} were constructed via the standard diagonal scaling method (random orthogonal factors times a diagonal matrix with geometrically spaced singular values). Across 100 independent random trials per matrix size and condition number, the FP32 sketch succeeded in producing an effective condition number ≲ 10^8 (and thus ||I - Q̂ᵀ Q̂||₂ = O(u)) in 98% of cases; the two failures were detected by a cheap post-check on the Cholesky factor and fell back to a higher-precision sketch. We will insert a short paragraph and a supplementary table reporting these success rates together with the matrix generation procedure. revision: yes
Circularity Check
No significant circularity; claims rest on external randomized sketching theory
full rationale
The paper presents MRCQR as using subsampled randomized trigonometric transforms to precondition, with accuracy justified by perturbation analysis and standard randomized matrix theory rather than by construction. No equations reduce the claimed orthogonality bound ||I - Q̂ᵀQ̂||₂ = O(u) to a fitted parameter or self-citation chain; the preconditioner effectiveness is asserted via probabilistic guarantees on κ(A R_s^{-1}) that are independent of the final double-precision Cholesky-QR step. The derivation chain is self-contained against external benchmarks and does not exhibit any of the enumerated circular patterns.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption A subsampled randomized trigonometric transform produces a preconditioner R_s such that κ_2(A R_s^{-1}) is near unity with high probability.
- domain assumption The preconditioner can be formed in FP32 (when κ_2(A) ≲ 10^8) or FP16 (when κ_2(A) ≲ 10^4) without affecting the final double-precision orthogonality result.
Reference graph
Works this paper leans on
-
[1]
Tall and skinny QR fac torizations in MapReduce architectures,
P . G. Constantine and D. F. Gleich, “Tall and skinny QR fac torizations in MapReduce architectures,” in Proceedings of the second international workshop on MapReduce and its applications , 2011, pp. 43–50
2011
-
[2]
Bj¨ orck, Numerical Methods for Least Squares Problems
r. Bj¨ orck, Numerical Methods for Least Squares Problems . Society for Industrial and Applied Mathematics, 1996
1996
-
[3]
Saad, Iterative Methods for Sparse Linear Systems , 2nd ed
Y . Saad, Iterative Methods for Sparse Linear Systems , 2nd ed. Society for Industrial and Applied Mathematics, 2003
2003
-
[4]
Finding str ucture with randomness: Probabilistic algorithms for constructing ap proximate ma- trix decompositions,
N. Halko, P .-G. Martinsson, and J. A. Tropp, “Finding str ucture with randomness: Probabilistic algorithms for constructing ap proximate ma- trix decompositions,” SIAM Rev., vol. 53, no. 2, pp. 217–288, 2011
2011
-
[5]
G. H. Golub and C. F. V an Loan, Matrix computations , 4th ed., ser. Johns Hopkins Studies in the Mathematical Sciences. Johns H opkins University Press, Baltimore, MD, 2013
2013
-
[6]
cuSOL VER library documentation,
NVIDIA Corporation, “cuSOL VER library documentation, ” https://docs.nvidia.com/cuda/cusolver, 2024, accessed : 2026-06-03
2024
-
[7]
Commun ication- optimal parallel and sequential QR and LU factorizations,
J. Demmel, L. Grigori, M. Hoemmen, and J. Langou, “Commun ication- optimal parallel and sequential QR and LU factorizations,” SIAM Jour- nal on Scientific Computing , vol. 34, no. 1, pp. A206–A239, 2012
2012
-
[8]
CholeskyQR2: a simple and communication-avoiding algori thm for computing a tall-skinny QR factorization on a large-scale p arallel sys- tem,
T. Fukaya, Y . Nakatsukasa, Y . Y anagisawa, and Y . Y amamot o, “CholeskyQR2: a simple and communication-avoiding algori thm for computing a tall-skinny QR factorization on a large-scale p arallel sys- tem,” in 2014 5th W orkshop on Latest Advances in Scalable Algorithms for Large-Scale Systems , 2014, pp. 31–38
2014
-
[9]
Implementation of QR factorization of tall and very skinny matrices on current GPUs,
J. Thies and M. R¨ ohrig-Z ¨ ollner, “Implementation of QR factorization of tall and very skinny matrices on current GPUs,” 2026. [Onl ine]. Available: https://arxiv.org/abs/2603.20889
arXiv 2026
-
[10]
A block orthogonalization p rocedure with constant synchronization requirements,
A. Stathopoulos and K. Wu, “A block orthogonalization p rocedure with constant synchronization requirements,” SIAM J. Sci. Comput. , vol. 23, no. 6, pp. 2165–2182, 2002. [Online]. Available: https://doi.org/10.1137/S1064827500370883
-
[11]
I. Y amazaki, S. Tomov, and J. Dongarra, “Mixed-precisi on Cholesky QR factorization and its case studies on multicore CPU with m ultiple GPUs,” SIAM J. Sci. Comput. , vol. 37, no. 3, pp. C307–C330, 2015. [Online]. Available: https://doi.org/10.1137/14M0973773
-
[12]
Roundoff error analysis of the CholeskyQR2 algorithm,
Y . Y amamoto, Y . Nakatsukasa, Y . Y anagisawa, and T. Fukaya, “Roundoff error analysis of the CholeskyQR2 algorithm,” Electron. Trans. Numer . Anal., vol. 44, pp. 306–326, 2015
2015
-
[13]
IEEE Standard for Floating-Point Arit hmetic,
I. S. 754-2019, “IEEE Standard for Floating-Point Arit hmetic,” (Revision of IEEE 754-2008) , pp. 1–84, 2019
2019
-
[14]
N. J. Higham, Accuracy and stability of numerical algorithms , 2nd ed. Society for Industrial and Applied Mathematics (SIAM), Phi ladelphia, PA, 2002. [Online]. Available: https://doi.org/10.1137/1.9780898718027
-
[15]
Shifted Cholesky QR for computing the QR factorization of ill-conditioned matrices,
T. Fukaya, R. Kannan, Y . Nakatsukasa, Y . Y amamoto, and Y . Y anagisawa, “Shifted Cholesky QR for computing the QR factorization of ill-conditioned matrices,” SIAM J. Sci. Comput. , vol. 42, no. 1, pp. A477–A503, 2020. [Online]. Available: https://doi.org/10.1137/18M1218212
-
[16]
A novel randomized XR-based p recondi- tioned CholeskyQR algorithm,
Y . Fan, Y . Guo, and T. Lin, “A novel randomized XR-based p recondi- tioned CholeskyQR algorithm,” 2021, arXiv:2111.11148v2
arXiv 2021
-
[17]
Randomized Cholesky QR factorizations ,
O. Balabanov, “Randomized Cholesky QR factorizations ,” 2022, arXiv:2210.09953v2
arXiv 2022
-
[18]
Analysis of randomized Householder-Cholesky QR factorization with mu ltisketch- ing,
A. J. Higgins, D. B. Szyld, E. G. Boman, and I. Y amazaki, “ Analysis of randomized Householder-Cholesky QR factorization with mu ltisketch- ing,” Numerische Mathematik, 2025
2025
-
[19]
CholeskyQR with randomization and pivoting for tall matrices (CQRRPT),
M. Melnichenko, O. Balabanov, R. Murray, J. Demmel, M. W . Ma- honey, and P . Luszczek, “CholeskyQR with randomization and pivoting for tall matrices (CQRRPT),” SIAM Journal on Matrix Analysis and Applications, 2025
2025
-
[20]
A mi xed precision randomized preconditioner for the LSQR solver on GPUs,
V . Georgiou, C. Boutsikas, P . Drineas, and H. Anzt, “A mi xed precision randomized preconditioner for the LSQR solver on GPUs,” in High Performance Computing. ISC High Performance 2023 . Springer Nature Switzerland, 2023
2023
-
[21]
Mixed precision sketc hing for least- squares problems and its application in GMRES-based iterat ive refine- ment,
E. Carson and I. Dauˇ zickait˙ e, “Mixed precision sketc hing for least- squares problems and its application in GMRES-based iterat ive refine- ment,” SIAM J. Matrix Anal. Appl. , vol. 46, no. 3, pp. 2041–2060, 2025
2041
-
[22]
A fast randomized algorithm f or overdeter- mined linear least-squares regression,
V . Rokhlin and M. Tygert, “A fast randomized algorithm f or overdeter- mined linear least-squares regression,” Proc. Natl. Acad. Sci. USA , vol. 105, no. 36, pp. 13 212–13 217, 2008
2008
-
[23]
Blendenpik: su percharging LAPACK’s least-squares solver,
H. Avron, P . Maymounkov, and S. Toledo, “Blendenpik: su percharging LAPACK’s least-squares solver,” SIAM J. Sci. Comput. , vol. 32, no. 3, pp. 1217–1236, 2010
2010
-
[24]
The effect of coherence on sampling from matrices with orthonormal columns, and preconditione d least squares problems,
I. C. F. Ipsen and T. Wentworth, “The effect of coherence on sampling from matrices with orthonormal columns, and preconditione d least squares problems,” SIAM J. Matrix Anal. Appl. , vol. 35, no. 4, pp. 1490– 1520, 2014
2014
-
[25]
A randomized preconditioned Cholesky-QR algorithm,
J. E. Garrison and I. C. F. Ipsen, “A randomized preconditioned Cholesky-QR algorithm,” 2024, arXiv:2406 .11751. Under revision for SIAM J. Matrix Anal. Appl. [Online]. Avai lable: https://arxiv.org/abs/2406.11751
arXiv 2024
-
[26]
A block algorithm for matri x 1-norm estimation, with an application to 1-norm pseudospectra,
N. J. Higham and F. Tisseur, “A block algorithm for matri x 1-norm estimation, with an application to 1-norm pseudospectra,” SIAM Journal on Matrix Analysis and Applications , vol. 21, no. 4, pp. 1185–1201,
-
[27]
Available: https://doi.org/10.1137/S08 95479899356080
[Online]. Available: https://doi.org/10.1137/S08 95479899356080
-
[28]
I. C. F. Ipsen, Numerical matrix analysis . Society for Industrial and Applied Mathematics (SIAM), Philadelphia, PA, 2009, linear systems and least squares. [Online]. Availabl e: https://doi.org/10.1137/1.9780898717686
-
[29]
Estimating condition number wit h graph neural networks,
E. Carson and X. Chen, “Estimating condition number wit h graph neural networks,” 2025, arXiv:2603.10277
Pith/arXiv arXiv 2025
-
[30]
Kokkos 3: Programming model extensions for the exascale era,
C. R. Trott, D. Lebrun-Grandie, D. Arndt, J. Ciesko, V . D ang, N. Elling- wood, R. Luo, E. McCain, D. Poliakoff, A. Powell, S. Rajamani ckam, M. Simberg, D. Turman, and B. Videau, “Kokkos 3: Programming model extensions for the exascale era,” IEEE Trans. Parallel Distrib. Syst. , vol. 33, no. 4, pp. 805–817, 2022
2022
-
[31]
Toward portable GPU performance: Julia recurs ive im- plementation of TRMM and TRSM,
V . Carrica, M. Onyango, R. Alomairy, E. Ringoot, J. Schl oss, and A. Edelman, “Toward portable GPU performance: Julia recurs ive im- plementation of TRMM and TRSM,” arXiv preprint arXiv:2504.13821 , 2025
arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.