Signature filtering: a lightweight enhancement for statistical watermark detection in large language models
Pith reviewed 2026-06-27 01:02 UTC · model grok-4.3
The pith
Signature filtering raises LLM watermark detection from 8-31% to 78-99% by removing unreliable tokens before testing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
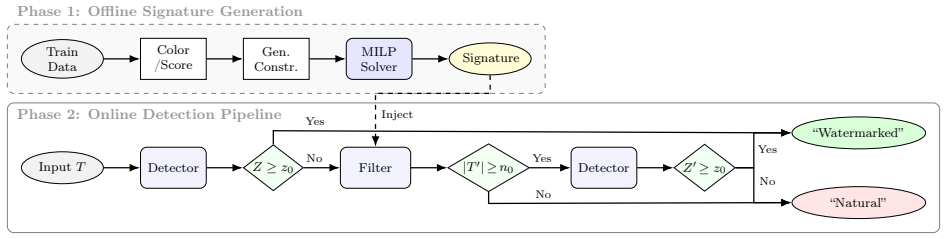
Signature filtering learns signature tokens via a mixed-integer linear program on a small training set that maximizes true positive rate, then removes them before applying the watermark test. Across Kgw, Sweet, Unigram, and Exp watermarks and six LLMs, 2- and 3-gram filters lift detection rates in weak-signal and low-entropy settings from 8-31 percent to 78-99 percent with controllable false positives. Finite-sample and asymptotic bounds are given under color-blind, color-adaptive, and distributionally correlated attacker models, and 2-gram filters for Kgw-style watermarks preserve most gains when text is scrambled or 25-50 percent of tokens are perturbed.
What carries the argument
The mixed-integer linear program solved on a small training set to select signature tokens that maximize true positive rate under the chosen constraints.
If this is right
- Detection becomes reliable for repetitive or low-entropy LLM outputs that previously yielded weak signals.
- The filter works as an add-on to any existing statistical watermark without retraining the generator or changing the embedding rule.
- Finite-sample and asymptotic bounds hold under three attacker models including color-adaptive and distributionally correlated cases.
- 2-gram filters for Kgw-style watermarks often match or exceed the advanced WinMax detector after sentence scrambling and token edits.
Where Pith is reading between the lines
- Watermark designers may need to consider how their token patterns interact with signature removal at detection time.
- The same MILP approach could be tested on non-watermark statistical detectors that also rely on token-level signals.
- Larger or more diverse training sets might reduce any overfitting risk when signatures are applied to new domains.
- Combining signature filtering with other post-processing steps could further harden provenance checks against coordinated edits.
Load-bearing premise
The signature tokens found on a small training set will make watermark tests unreliable on unseen texts, different generation settings, and attacker edits without losing the reported detection gains.
What would settle it
Run the learned 2-gram or 3-gram filter on a new corpus and LLM never seen in training and measure whether detection rates fall back near the 8-31 percent range without the filter.
Figures




read the original abstract
Statistical watermarks help organizations attribute large language model (LLM) outputs, yet existing detectors often struggle when watermark signals are weak, texts are repetitive, or watermarks are edited. We propose signature filtering, a detection-time module that enhances watermark detection without modifying watermark embedding and text generation. It learns a small set of ``signature'' tokens whose presence makes watermark tests unreliable, and removes these tokens before detection. The signatures are obtained by solving a mixed-integer linear program on a small training set, with constraints that maximize the true positive rate. We additionally derive finite-sample and asymptotic bounds under several attacker models (color-blind, color-adaptive, and distributionally correlated). On four well-known watermark families (Kgw, Sweet, Unigram, Exp), four benchmark corpora (C4, MBPP, HumanEval, Code-Search-Net), and six LLMs (Opt-1.3b, Opt-6.7b, Llama2-13b, Llama3.1-8b, Qwen2.5-14b, Phi-3-medium-14b), 2- and 3-gram signatures raise detection rates in weak-signal and low-entropy settings from 8~31% without filtering to 78~99% with filtering, while keeping false positives controllable and often negligible. In stress tests where we scramble sentences and perturb 25~50% of tokens by dilution, deletions, and substitutions, 2-gram filters for Kgw-style watermarks preserve most of the clean-text detection gains, often matching or outperforming the advanced WinMax watermark detector. Signature filtering thus provides a simple, scalable, and model-agnostic add-on to strengthen watermark-based provenance checks for LLM text in information processing workflows.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes signature filtering, a detection-time enhancement for statistical LLM watermarks that identifies a small set of 'signature' n-grams via mixed-integer linear programming (MILP) on a training split; these tokens are removed before applying the watermark test. The method is evaluated on four watermark families (Kgw, Sweet, Unigram, Exp), four corpora (C4, MBPP, HumanEval, Code-Search-Net), and six LLMs, reporting TPR lifts from 8-31% to 78-99% in weak-signal/low-entropy regimes while controlling FPR. Finite-sample and asymptotic bounds are derived under color-blind, color-adaptive, and distributionally correlated attacker models, with additional stress tests on sentence scrambling and 25-50% token perturbations.
Significance. If the generalization of the MILP-derived signatures holds, the approach offers a lightweight, model-agnostic add-on that substantially improves detection reliability for existing watermarks without altering embedding or generation. The work is strengthened by its broad empirical scope across multiple watermarks, datasets, and models plus explicit attacker-model bounds; these elements provide concrete, falsifiable performance claims that could be directly useful for provenance verification pipelines.
major comments (2)
- [§3, §5] §3 (MILP formulation) and §5 (experimental setup): the central TPR gains (8-31% → 78-99%) rest on signatures learned from a small training split generalizing to held-out test texts, different LLMs, and attacker perturbations. No ablation of training-set size, no cross-corpus transfer results for the MILP step itself, and no explicit check that selected n-grams are watermark-inherent rather than corpus-specific (e.g., low-entropy patterns in C4/MBPP) are reported; this directly undermines the load-bearing claim that the reported gains and bounds transfer.
- [§4] §4 (attacker-model bounds): the finite-sample and asymptotic bounds are stated under the assumption that the signature set is fixed and independent of the test distribution. If the MILP signatures overfit training statistics, the color-adaptive and distributionally correlated bounds no longer apply to the actual deployed detector; the paper does not quantify sensitivity of the bounds to signature selection.
minor comments (2)
- [§3.1] Notation for n-gram signatures (2-gram vs. 3-gram) is introduced without an explicit definition of the token alphabet or how duplicates are handled in the MILP objective.
- [Figures 2-4] Table captions and axis labels in the main result figures should explicitly state the training-set size used for MILP and the exact false-positive target.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and detailed review. We provide point-by-point responses to the major comments below, and we will incorporate revisions to address the concerns raised.
read point-by-point responses
-
Referee: [§3, §5] §3 (MILP formulation) and §5 (experimental setup): the central TPR gains (8-31% → 78-99%) rest on signatures learned from a small training split generalizing to held-out test texts, different LLMs, and attacker perturbations. No ablation of training-set size, no cross-corpus transfer results for the MILP step itself, and no explicit check that selected n-grams are watermark-inherent rather than corpus-specific (e.g., low-entropy patterns in C4/MBPP) are reported; this directly undermines the load-bearing claim that the reported gains and bounds transfer.
Authors: We agree that additional ablations would provide stronger support for the generalization claims. Although the reported results already span multiple corpora and LLMs, demonstrating practical transfer, we will add ablations on training-set size and cross-corpus MILP transfer experiments in the revision. We will also include an analysis of the selected n-grams to distinguish watermark-inherent patterns from corpus-specific ones, for instance by examining overlap and entropy characteristics across different datasets. These additions will bolster the evidence that the TPR gains and bounds are transferable. revision: yes
-
Referee: [§4] §4 (attacker-model bounds): the finite-sample and asymptotic bounds are stated under the assumption that the signature set is fixed and independent of the test distribution. If the MILP signatures overfit training statistics, the color-adaptive and distributionally correlated bounds no longer apply to the actual deployed detector; the paper does not quantify sensitivity of the bounds to signature selection.
Authors: The bounds are formulated for a fixed signature set at test time, consistent with our methodology of learning signatures on a training split and applying them to held-out test data. To directly address the potential impact of overfitting, we will include in the revised version a sensitivity analysis that evaluates how the bounds vary under different signature selections, such as those obtained from varied training splits or with added regularization in the MILP. This will quantify the robustness of the theoretical guarantees. revision: yes
Circularity Check
No significant circularity; derivation is self-contained
full rationale
The paper trains signatures via MILP on a small training split and evaluates detection-rate gains on held-out test corpora under explicit attacker models (color-blind, color-adaptive, distributionally correlated). Finite-sample and asymptotic bounds are derived from those models rather than from quantities fitted on the evaluation data. No self-definitional loop, no fitted parameter renamed as a prediction, and no load-bearing self-citation chain appears in the reported derivation. Standard train/test separation plus model-based bounds keep the central empirical claims independent of the inputs by construction.
Axiom & Free-Parameter Ledger
free parameters (1)
- signature token set
axioms (1)
- standard math The mixed-integer linear program can be solved to produce effective signatures on the given training set.
invented entities (1)
-
signature tokens
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Theoretical Computer Science 147, 181–210
The complexity and approximability of finding maximum feasible subsystems of linear relations. Theoretical Computer Science 147, 181–210. doi:10.1016/0304-3975(94)00254-G. Austin, J., Odena, A., Nye, M., Bosma, M., Michalewski, H., Dohan, D., Jiang, E., Cai, C., Terry, M., Le, Q., et al.,
-
[2]
Program Synthesis with Large Language Models
Program synthesis with large language models. arXiv preprint arXiv:2108.07732 doi:10.48550/arXiv.2108.07732. Bentkus, V.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2108.07732
-
[3]
A lyapunov-type bound inRd. Theory of Probability & Its Applications 49, 311–323. doi:10.1137/S0040585X97981123. Bifet, A., Gavaldà, R.,
-
[4]
Learning from time-changing data with adaptive windowing, in: SIAM Inter- national Conference on Data Mining, SIAM. pp. 443–448. doi:10.1137/1.9781611972771.42. 23 Chandra, B., Dunietz, J., Roberts, K.,
-
[5]
Technical Report NIST AI 100-4
Reducing risks posed by synthetic content: An overview of technical approaches to digital content transparency. Technical Report NIST AI 100-4. National Institute of Standards and Technology. doi:10.6028/NIST.AI.100-4. Chen, M., Tworek, J., Jun, H., Yuan, Q., Ponde de Oliveira Pinto, H., Kaplan, J., Edwards, H., Burda, Y., Joseph, N., Brockman, G., et al.,
-
[6]
Evaluating Large Language Models Trained on Code
Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374 doi:10.48550/arXiv.2107.03374. Christ, M., Gunn, S., Zamir, O.,
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2107.03374
-
[7]
Undetectable watermarks for language models, in: Annual Conference on Learning Theory, PMLR. pp. 1125–1139. doi:10.48550/arXiv.2306.09194. Dathathri, S., See, A., Ghaisas, S., Huang, P.S., McAdam, R., Welbl, J., Bachani, V., Kaskasoli, A., Stanforth, R., Matejovicova, T., Hayes, J., Vyas, N., Al Merey, M., Brown-Cohen, J., Bunel, R., Balle, B., Cemgil, T....
-
[8]
Scalable watermarking for identifying large language model outputs. Nature 634, 818–823. doi:10.1038/s41586-024-08025-4. Fang, X., Wu, H., Jing, J., Meng, Y., Yu, B., Yu, H., Zhang, H.,
-
[9]
NSEP: Early fake news detection via news semantic environment perception. Information Processing & Management 61, 103594. doi:10. 1016/j.ipm.2023.103594. Fernandez, P., Chaffin, A., Tit, K., Chappelier, V., Furon, T., 2023a. Three bricks to consolidate watermarks for large language models, in: IEEE International Workshop on Information Forensics and Secur...
-
[10]
Computers & Operations Research 139, 105633
Faster maximum feasible subsystem solutions for dense constraint matrices. Computers & Operations Research 139, 105633. doi:10.1016/j.cor.2021.105633. Fu, J., Zhao, X., Yang, R., Zhang, Y., Chen, J., Xiao, Y.,
-
[11]
arXiv preprint arXiv:2402.12948 doi:10.48550/arXiv.2402
Gumbelsoft: Diversified language model watermarking via the Gumbelmax-trick. arXiv preprint arXiv:2402.12948 doi:10.48550/arXiv.2402. 12948. Gama, J., Žliobait˙ e, I., Bifet, A., Pechenizkiy, M., Bouchachia, A.,
-
[12]
García-Teodoro, P., Díaz-Verdejo, J., Maciá-Fernández, G., & Vázquez, E
A survey on concept drift adapta- tion. ACM Computing Surveys 46, 1–37. doi:10.1145/2523813. Gretton, A., Borgwardt, K.M., Rasch, M.J., Schölkopf, B., Smola, A.,
-
[13]
Journal of Machine Learning Research 13, 723–773
A kernel two-sample test. Journal of Machine Learning Research 13, 723–773. doi:10.5555/2188385.2188410. Gurobi Optimization, LLC,
-
[14]
arXiv preprint arXiv:2402.14007 doi:10.48550/arXiv.2402.14007
Can watermarks survive translation? on the cross-lingual consistency of text watermark for large language models. arXiv preprint arXiv:2402.14007 doi:10.48550/arXiv.2402.14007. Hogg, R.V., Tanis, E., Zimmerman, D.,
-
[15]
CodeSearchNet Challenge: Evaluating the State of Semantic Code Search
CodeSearchNetchallenge: Evaluat- ing the state of semantic code search. arXiv preprint arXiv:1909.09436 doi:10.48550/arXiv.1909.09436. Kirchenbauer, J., Geiping, J., Wen, Y., Katz, J., Miers, I., Goldstein, T., 2024a. A watermark for large language models. arXiv preprint arXiv:2301.10226 doi:10.48550/arXiv.2301.10226. 24 Kirchenbauer, J., Geiping, J., Wen...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.1909.09436 1909
-
[16]
Transactions on Machine Learning Research doi:10.48550/arXiv.2307.15593
Robust distortion-free watermarks for language models. Transactions on Machine Learning Research doi:10.48550/arXiv.2307.15593. Lee, T., Hong, S., Ahn, J., Hong, I., Lee, H., Yun, S., Shin, J., Kim, G.,
-
[17]
arXiv preprint arXiv:2305.15060 doi:10.48550/arXiv.2305.15060
Who wrote this code? watermarking for code generation. arXiv preprint arXiv:2305.15060 doi:10.48550/arXiv.2305.15060. Li, X., Ruan, F., Wang, H., Long, Q., Su, W.J., 2025a. Robust detection of watermarks for large language models under human edits. Journal of the Royal Statistical Society: Series B (Statistical Methodology) doi:10.1093/jrsssb/qkaf056. Li,...
-
[18]
Learning under concept drift: A review. IEEE Transactions on Knowledge and Data Engineering 31, 2346–2363. doi:10.1109/TKDE.2018.2876857. Lu, Y., Pan, L., Han, J., Zou, L., Yu, P.S., Wen, L., Song, X., He, X.,
-
[19]
arXiv preprint arXiv:2404.17571 doi:10.48550/arXiv.2404.17571
Entropy-based text watermarking detection. arXiv preprint arXiv:2404.17571 doi:10.48550/arXiv.2404.17571. Luvembe, A.M., Li, W., Li, S., Liu, F., Wu, X.,
-
[20]
InformationProcessing&Management 61, 103653
Caf-ODNN: Complementary attention fusion with optimizeddeepneuralnetworkformultimodalfakenewsdetection. InformationProcessing&Management 61, 103653. doi:10.1016/j.ipm.2023.103653. Pan, L., Liu, A., Han, J., Lu, Y., Yu, P.S., Wen, L., 2024a. Markllm: An open-source toolkit for LLM watermarking. arXiv preprint arXiv:2405.10051 doi:10.48550/arXiv.2405.10051....
-
[21]
Information Processing & Manage- ment 61, 103564
Not all fake news is semantically similar: Contextual semantic representation learning for multimodal fake news detection. Information Processing & Manage- ment 61, 103564. doi:10.1016/j.ipm.2023.103564. Pfetsch, M.E.,
-
[22]
SIAM Journal on Optimization 19, 21–38
Branch-and-cut for the maximum feasible subsystem problem. SIAM Journal on Optimization 19, 21–38. doi:10.1137/050645828. Polikar, R.,
-
[23]
Journal of Machine Learning Research 21, 1–67
Exploring the limits of transfer learning with a unified text-to-text transformer. Journal of Machine Learning Research 21, 1–67. doi:10.5555/3455716.3455856. 25 Reynolds, S., Obitayo, S., Dalmasso, N., Ngo, D.D.T., Potluru, V.K., Veloso, M.,
-
[24]
arXiv preprint arXiv:2502.18608 doi:10.48550/ arXiv.2502.18608
Toward breaking watermarks in distortion-free large language models. arXiv preprint arXiv:2502.18608 doi:10.48550/ arXiv.2502.18608. Tsur, D., Long, C.X., Verdun, C.M., Vithana, S., Hsu, H., Chen, C.F., Permuter, H.H., Calmon, F.P.,
-
[25]
Heavywater and simplexwater: Distortion-free LLM watermarks for low-entropy distributions, in: Advances in Neural Information Processing Systems, Curran Associates, Inc. doi:10.48550/arXiv.2506. 06409. Wang, Z., Gu, T., Wu, B., Yang, Y., 2025a. MorphMark: Flexible adaptive watermarking for large language models, in: Annual Meeting of the Association for C...
-
[26]
arXiv preprint arXiv:2312.17295 doi:10.48550/arXiv.2312.17295
Optimizing watermarks for large language models. arXiv preprint arXiv:2312.17295 doi:10.48550/arXiv.2312.17295. Wu, J., Yang, S., Zhan, R., Yuan, Y., Chao, L.S., Wong, D.F.,
-
[27]
Information Processing & Management 62, 104241
Delphiagent: A trustworthy multi-agent verification framework for automated fact verification. Information Processing & Management 62, 104241. doi:10. 1016/j.ipm.2025.104241. Xylogiannopoulos, K.F., Xanthopoulos, P., Karampelas, P., Bakamitsos, G.A.,
arXiv 2025
-
[28]
Can you tell the difference? Information Processing & Management 61, 103842
ChatGPT paraphrased product reviews can confuse consumers and undermine their trust in genuine reviews. Can you tell the difference? Information Processing & Management 61, 103842. doi:10.1016/j.ipm.2024.103842. Zhang, Z., Zhang, X., Zhang, Y., Zhang, L.Y., Chen, C., Hu, S., Gill, A., Pan, S.,
-
[29]
arXiv preprint arXiv:2405.19677 doi:10
Large language model watermark stealing with mixed integer programming. arXiv preprint arXiv:2405.19677 doi:10. 48550/arXiv.2405.19677. Zhao, X., Ananth, P.V., Li, L., Wang, Y.X.,
-
[30]
arXiv preprint arXiv:2306.17439 doi:10.48550/arXiv.2306.17439
Provable robust watermarking for AI-generated text. arXiv preprint arXiv:2306.17439 doi:10.48550/arXiv.2306.17439. 26
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.