Covariance shrinkage for cosmological inference with Sellentin-Heavens-type likelihoods
Pith reviewed 2026-06-26 22:52 UTC · model grok-4.3
The pith
Covariance scaling corrections depend on the likelihood form, and shrinkage with marginalisation over its intensity improves conditioning without needing extra Hartlap scaling under Sellentin-Heavens inference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Scalar covariance corrections are likelihood-dependent and an additional Hartlap-type global scaling is not favoured once covariance uncertainty is marginalised through the Sellentin-Heavens likelihood. A shrinkage formulation in which the sample covariance is regularised towards a spherical target and the shrinkage intensity is treated as an auxiliary inferential quantity yields improved conditioning while propagating uncertainty about the amount of regularisation into posterior inference when the intensity is marginalised over.
What carries the argument
Shrinkage intensity treated as auxiliary inferential quantity with assigned prior whose posterior is induced by the likelihood, then marginalised to obtain the parameter posterior.
If this is right
- Hartlap-type global scaling is not needed when covariance uncertainty is already marginalised through the Sellentin-Heavens likelihood.
- Shrinkage substantially improves covariance conditioning.
- Marginalisation over shrinkage intensity propagates uncertainty about the regularisation amount into the parameter posterior.
- The approach combines covariance-marginalised likelihood inference with structural regularisation of noisy simulation-estimated covariance matrices.
Where Pith is reading between the lines
- The method could be applied to other inference problems that rely on simulation-estimated covariances, such as in particle physics or financial risk modelling.
- Alternative target matrices beyond the spherical choice could be substituted while retaining the marginalisation step.
- The framework might be extended to non-Gaussian likelihoods or to joint inference of multiple covariance-related hyperparameters.
Load-bearing premise
A spherical target matrix is a suitable regularisation anchor and the chosen prior on shrinkage intensity does not introduce bias.
What would settle it
Monte Carlo experiments that compare posterior calibration and parameter constraints obtained with and without the proposed shrinkage marginalisation, using known true covariances from simulations, would show whether the conditioning and uncertainty-propagation benefits hold.
Figures

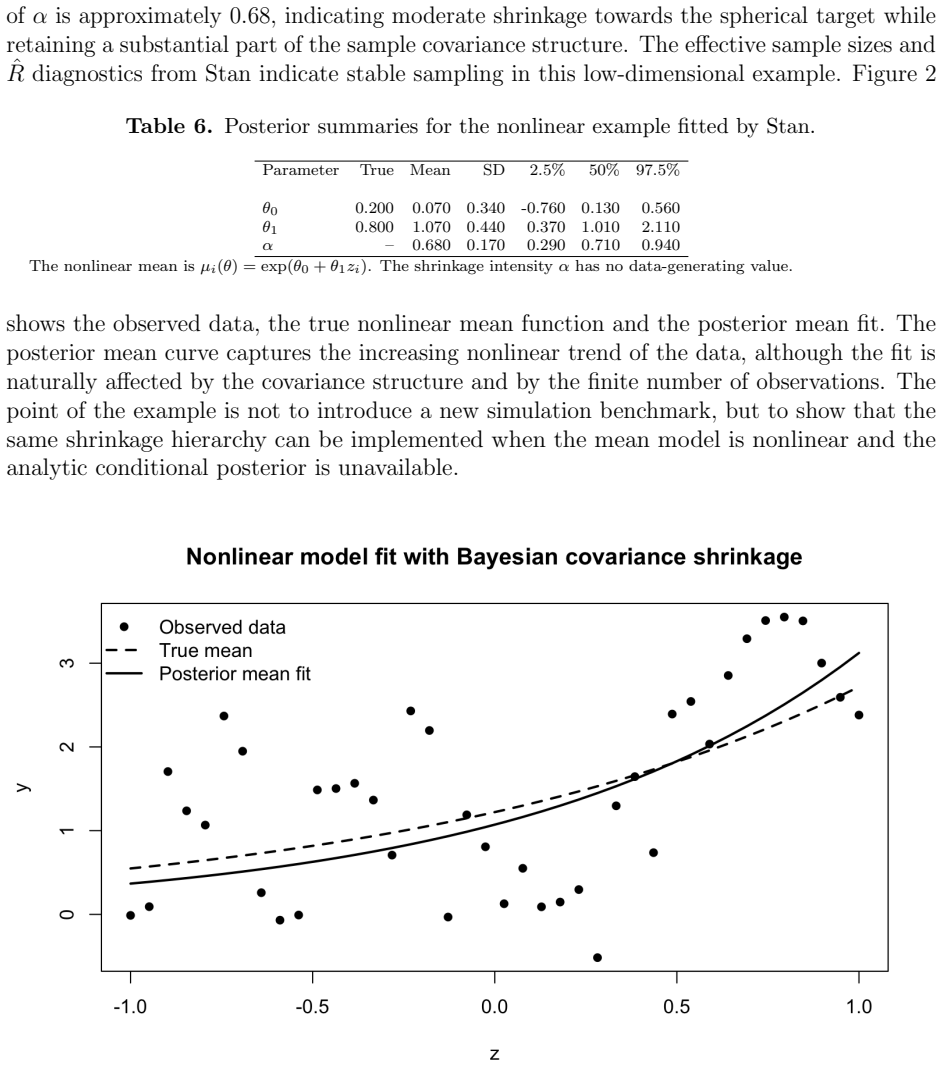
read the original abstract
Covariance matrices used in astronomical and cosmological parameter inference are often estimated from a finite number of simulations, so covariance uncertainty can affect posterior calibration and parameter constraints. We study covariance regularisation from the perspective of likelihood-based inference with simulation-estimated covariance matrices. First, we analyse scalar covariance scaling under the Gaussian plug-in likelihood and the covariance-marginalised Sellentin--Heavens likelihood. Using an expected negative log-likelihood loss, we show that Hartlap covariance-side scaling is recovered as the optimum under the Gaussian plug-in likelihood, whereas the unscaled sample covariance is optimal under the Sellentin--Heavens likelihood. This shows that scalar covariance corrections are likelihood-dependent and that an additional Hartlap-type global scaling is not favoured once covariance uncertainty is marginalised through the Sellentin--Heavens likelihood. We then introduce a shrinkage formulation in which the sample covariance is regularised towards a spherical target and the shrinkage intensity is treated as an auxiliary inferential quantity. A prior is assigned to the shrinkage intensity, the likelihood induces its posterior distribution, and the final parameter posterior is obtained by marginalising over it. Monte Carlo experiments show that shrinkage substantially improves covariance conditioning, while marginalisation over the shrinkage intensity propagates uncertainty about the amount of regularisation into posterior inference. The proposed approach provides a simple way to combine covariance-marginalised likelihood inference with structural regularisation of noisy simulation-estimated covariance matrices.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript claims that scalar covariance corrections are likelihood-dependent: Hartlap-type global scaling is optimal under the Gaussian plug-in likelihood but the unscaled sample covariance is optimal under the Sellentin-Heavens likelihood, as derived from an expected negative log-likelihood loss. It further proposes shrinking the sample covariance toward a spherical target while treating the shrinkage intensity as an auxiliary parameter with an assigned prior; the final posterior is obtained by marginalization over this intensity. Monte Carlo experiments are reported to show improved covariance conditioning and propagation of regularization uncertainty into the parameter posterior.
Significance. If the results hold, the work usefully demonstrates the likelihood dependence of simple covariance corrections and supplies a concrete procedure for combining Sellentin-Heavens marginalization with structural regularization. The Monte Carlo experiments constitute reproducible evidence for gains in conditioning and uncertainty propagation; these are concrete strengths that would be valuable for cosmological analyses limited by simulation-based covariance estimates.
major comments (2)
- [Shrinkage formulation] Shrinkage formulation: the adoption of a spherical target matrix together with a prior on the shrinkage intensity is introduced as a modeling choice whose mismatch with the strong off-diagonal structure of cosmological covariance matrices is not obviously corrected by marginalization; the manuscript does not provide a derivation or test showing that the marginal posterior on cosmological parameters remains unbiased under target misspecification.
- [Monte Carlo experiments] Monte Carlo experiments: while conditioning improvement is demonstrated, the experiments do not include a controlled test in which the spherical target is deliberately misspecified relative to the true covariance structure, leaving open whether the propagated uncertainty fully mitigates bias in the recovered parameter constraints.
minor comments (1)
- [scalar covariance scaling analysis] The expected-negative-log-likelihood derivation for optimality is summarized but the explicit loss function and its minimization steps are not shown; adding these would allow direct verification that the optimum is independent of the fitted parameters.
Simulated Author's Rebuttal
We thank the referee for the constructive report and for recognizing the manuscript's contributions on likelihood-dependent covariance corrections and the combination of Sellentin-Heavens marginalization with shrinkage. We address each major comment below.
read point-by-point responses
-
Referee: [Shrinkage formulation] Shrinkage formulation: the adoption of a spherical target matrix together with a prior on the shrinkage intensity is introduced as a modeling choice whose mismatch with the strong off-diagonal structure of cosmological covariance matrices is not obviously corrected by marginalization; the manuscript does not provide a derivation or test showing that the marginal posterior on cosmological parameters remains unbiased under target misspecification.
Authors: The spherical target is adopted for its analytical simplicity and precedent in the shrinkage literature. Marginalization over the shrinkage intensity is designed to let the data inform the effective amount of regularization rather than to guarantee unbiasedness under arbitrary target misspecification. The manuscript does not contain a derivation or dedicated test of unbiasedness for misspecified targets; we will add an explicit limitations paragraph discussing this assumption and its implications for cosmological covariances with strong off-diagonal structure. revision: partial
-
Referee: [Monte Carlo experiments] Monte Carlo experiments: while conditioning improvement is demonstrated, the experiments do not include a controlled test in which the spherical target is deliberately misspecified relative to the true covariance structure, leaving open whether the propagated uncertainty fully mitigates bias in the recovered parameter constraints.
Authors: The existing Monte Carlo suite demonstrates conditioning gains and uncertainty propagation when the target is a reasonable (if simplified) choice. We agree that a controlled misspecification test is absent and would strengthen the claims. In the revised version we will add such an experiment, deliberately using a mismatched spherical target and reporting the resulting shifts in the marginal posterior on cosmological parameters. revision: yes
Circularity Check
No circularity: optimality results derived from independent expected-loss functional; shrinkage is an explicit modeling proposal with assigned prior
full rationale
The paper derives that Hartlap scaling is optimal under the Gaussian plug-in likelihood but not under the Sellentin-Heavens likelihood by minimizing an expected negative log-likelihood loss that does not depend on any parameter fitted in the final result. The shrinkage construction treats intensity as an auxiliary variable with an explicit prior and performs marginalization; this is a modeling choice rather than a reduction of the target posterior to its own inputs by construction. No self-citation load-bearing steps, no fitted-input-called-prediction, and no self-definitional relations appear in the provided derivation chain. The spherical-target assumption is an unvalidated modeling premise but does not create circularity in the reported results.
Axiom & Free-Parameter Ledger
free parameters (1)
- prior on shrinkage intensity
axioms (2)
- domain assumption Covariance matrices are estimated from a finite number of simulations
- domain assumption Sellentin-Heavens likelihood correctly marginalises covariance uncertainty
Reference graph
Works this paper leans on
-
[1]
Unbiased estimation of the inverse covariance matrix , author=
Why your model parameter confidences might be too optimistic. Unbiased estimation of the inverse covariance matrix , author=. Astronomy & Astrophysics , volume=. 2007 , publisher=
2007
-
[2]
Monthly Notices of the Royal Astronomical Society: Letters , volume=
Parameter inference with estimated covariance matrices , author=. Monthly Notices of the Royal Astronomical Society: Letters , volume=. 2015 , publisher=
2015
-
[3]
1982 , publisher=
Aspects of multivariate statistical theory , author=. 1982 , publisher=
1982
-
[4]
Monthly Notices of the Royal Astronomical Society: Letters , volume=
Non-linear shrinkage estimation of large-scale structure covariance , author=. Monthly Notices of the Royal Astronomical Society: Letters , volume=. 2017 , publisher=
2017
-
[5]
Journal of Multivariate Analysis , volume=
A well-conditioned estimator for large-dimensional covariance matrices , author=. Journal of Multivariate Analysis , volume=. 2004 , publisher=
2004
-
[6]
The Annals of Statistics , volume=
Analytical nonlinear shrinkage of large-dimensional covariance matrices , author=. The Annals of Statistics , volume=. 2020 , publisher=
2020
-
[7]
Statistics , volume=
Improved precision matrix estimation for mean-variance portfolio selection , author=. Statistics , volume=. 2025 , publisher=
2025
-
[8]
Journal of Empirical Finance , volume=
Improved estimation of the covariance matrix of stock returns with an application to portfolio selection , author=. Journal of Empirical Finance , volume=. 2003 , publisher=
2003
-
[9]
Intelligent Systems with Applications , volume=
Shrinkage estimation with reinforcement learning of large variance matrices for portfolio selection , author=. Intelligent Systems with Applications , volume=. 2023 , publisher=
2023
-
[10]
Journal of Financial Econometrics , volume=
Learning the Shrinkage Intensity: A Data-Driven Approach for Risk-Optimized Portfolios , author=. Journal of Financial Econometrics , volume=. 2026 , publisher=
2026
-
[11]
Physical Review D , volume=
Dimensionality reduction techniques for statistical inference in cosmology , author=. Physical Review D , volume=. 2025 , publisher=
2025
-
[12]
Monthly Notices of the Royal Astronomical Society , volume=
Large covariance matrices: smooth models from the two-point correlation function , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2016 , publisher=
2016
-
[13]
Monthly Notices of the Royal Astronomical Society , volume=
Large covariance matrices: accurate models without mocks , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2019 , publisher=
2019
-
[14]
Monthly Notices of the Royal Astronomical Society , volume=
Putting the Precision in Precision Cosmology: How accurate should your data covariance matrix be? , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2013 , publisher=
2013
-
[15]
arXiv preprint arXiv:2604.19463 , year=
On combining estimated and analytic covariance matrices , author=. arXiv preprint arXiv:2604.19463 , year=
-
[16]
Physical Review D , volume=
Fewer mocks and less noise: Reducing the dimensionality of cosmological observables with subspace projections , author=. Physical Review D , volume=. 2021 , publisher=
2021
-
[17]
The Annals of Statistics , volume=
Empirical Bayes estimation of the multivariate normal covariance matrix , author=. The Annals of Statistics , volume=. 1980 , publisher=
1980
-
[18]
Journal of Multivariate Analysis , volume=
Minimax estimators for a multinormal precision matrix , author=. Journal of Multivariate Analysis , volume=. 1977 , publisher=
1977
-
[19]
Computational Statistics & Data Analysis , volume=
Improved Stein-type shrinkage estimators for the high-dimensional multivariate normal covariance matrix , author=. Computational Statistics & Data Analysis , volume=. 2011 , publisher=
2011
-
[20]
The Annals of Statistics , pages=
Estimation of a covariance matrix under Stein's loss , author=. The Annals of Statistics , pages=. 1985 , publisher=
1985
-
[21]
Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=
Large covariance estimation by thresholding principal orthogonal complements , author=. Journal of the Royal Statistical Society Series B: Statistical Methodology , volume=. 2013 , publisher=
2013
-
[22]
Physical Review D—Particles, Fields, Gravitation, and Cosmology , volume=
The effect of covariance estimator error on cosmological parameter constraints , author=. Physical Review D—Particles, Fields, Gravitation, and Cosmology , volume=. 2013 , publisher=
2013
-
[23]
Astronomy & Astrophysics , volume=
Simulation-based inference has its own Dodelson--Schneider effect (but it knows that it does) , author=. Astronomy & Astrophysics , volume=. 2025 , publisher=
2025
-
[24]
Monthly Notices of the Royal Astronomical Society , volume=
Precision matrix expansion--efficient use of numerical simulations in estimating errors on cosmological parameters , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2018 , publisher=
2018
-
[25]
Physical Review D , volume=
Data compression with noise suppression for inference under noisy covariance , author=. Physical Review D , volume=. 2025 , publisher=
2025
-
[26]
Monthly Notices of the Royal Astronomical Society , volume=
Dark Energy Survey year 3 results: covariance modelling and its impact on parameter estimation and quality of fit , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2021 , publisher=
2021
-
[27]
Monthly Notices of the Royal Astronomical Society , volume=
CARPool covariance: fast, unbiased covariance estimation for large-scale structure observables , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2022 , publisher=
2022
-
[28]
Monthly Notices of the Royal Astronomical Society , volume=
CARPool: fast, accurate computation of large-scale structure statistics by pairing costly and cheap cosmological simulations , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2021 , publisher=
2021
-
[29]
Monthly Notices of the Royal Astronomical Society , volume=
Bayesian control variates for optimal covariance estimation with pairs of simulations and surrogates , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2022 , publisher=
2022
-
[30]
Monthly Notices of the Royal Astronomical Society , volume=
Matching Bayesian and frequentist coverage probabilities when using an approximate data covariance matrix , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2022 , publisher=
2022
-
[31]
Monthly Notices of the Royal Astronomical Society , volume=
Dark energy survey year 3 results: likelihood-free, simulation-based w cdm inference with neural compression of weak-lensing map statistics , author=. Monthly Notices of the Royal Astronomical Society , volume=. 2025 , publisher=
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.