VISUALSKILL: Multimodal Skills for Computer-Use Agents
Pith reviewed 2026-06-27 00:31 UTC · model grok-4.3
The pith
Retaining visual figures in skills for computer-use agents lifts average benchmark scores from 0.373 to 0.456 over text-only versions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
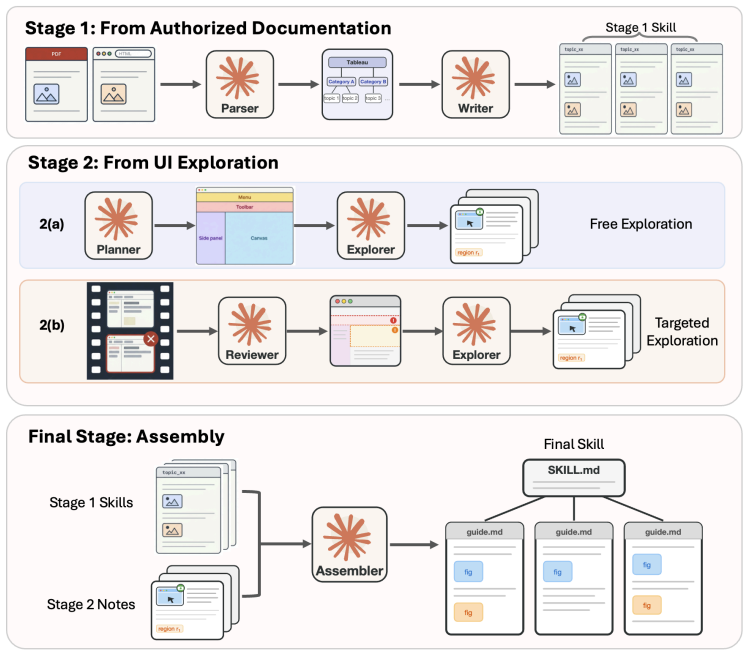
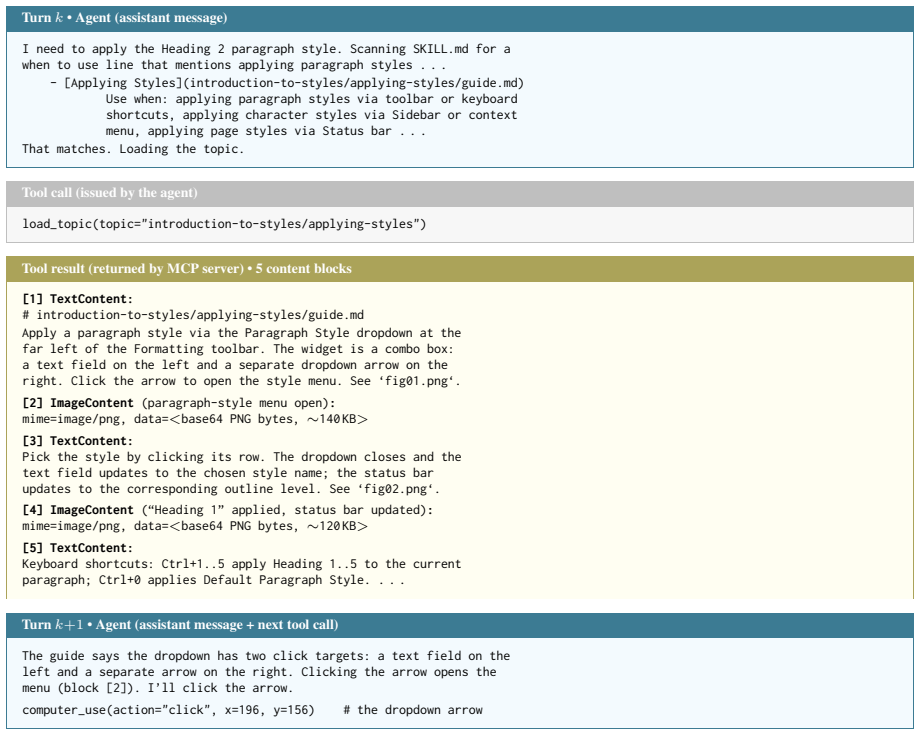
VISUALSKILL is a hierarchical multimodal skill tailored to each target application and organised as a central index over per-topic files. The agent consumes it through a load_topic MCP tool that fetches the relevant topic's text and figures on demand. Each skill is constructed with a two-stage pipeline that combines authored documentation with live-application UI exploration. On the two benchmarks this produces an average score of 0.456, an absolute gain of 8.3 points over a matched text-only skill that differs only in modality.
What carries the argument
VISUALSKILL, the hierarchical multimodal skill that retains visual figures from documentation and live UI exploration, accessed on demand via the load_topic tool.
If this is right
- Agents locate UI elements more reliably when figures remain in the skill artifact.
- Workflow state verification after each action becomes more accurate.
- The 15.3-point lift over the no-skill baseline holds on both CUA-World and OSExpert-Eval.
- Skills become application-specific through the combination of authored docs and live exploration.
- The modality difference alone accounts for the observed performance gap.
Where Pith is reading between the lines
- The same on-demand figure mechanism could be tested on web-browsing or mobile agents where visual state changes rapidly.
- Automatic refresh of figures when an application updates would be a natural next engineering step.
- Lower token consumption might result if agents query figures only when needed rather than receiving long verbal descriptions.
- The construction pipeline could be applied to non-GUI domains that still benefit from visual references, such as diagram-heavy technical manuals.
Load-bearing premise
The two-stage pipeline combining authored documentation with live-application UI exploration produces accurate, relevant figures without introducing noise or outdated visuals that could mislead the agent.
What would settle it
Replace the figures inside VISUALSKILL files with incorrect or outdated images and measure whether the 8.3-point advantage over the matched text-only skill disappears.
Figures













read the original abstract
Computer-use agents (CUAs) approach human-level performance on standardised benchmarks but still struggle on long-horizon tasks and unseen software. Existing skill libraries address this with reusable skills, but represent the skill artifact as text only, despite the visual nature of GUI interaction. We propose VISUALSKILL: a hierarchical multimodal skill, tailored to each target application and organised as a central index over per-topic files, which the agent consumes through a load_topic MCP tool that fetches the relevant topic's text and figures on demand. We construct each skill with a two-stage pipeline that combines authored documentation with live-application UI exploration. On two CUA benchmarks, CUA-World and OSExpert-Eval, a Claude Code CLI agent backed by Claude Opus 4.6 reaches an average score of 0.456 with VISUALSKILL, a +15.3 point absolute lift over the no-skill baseline (0.303). Against a matched text-only skill that is generated from the same source content and differs from VISUALSKILL only in modality, VISUALSKILL yields a further +8.3 point absolute gain over the matched text-only skill (0.373 vs. 0.456), providing direct evidence that retaining visual figures in the skill artifact, rather than verbalizing them away, helps the agent both identify UI elements and verify workflow state after each action. Our code is available at https://github.com/XMHZZ2018/VisualSkills.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces VISUALSKILL, a hierarchical multimodal skill library for computer-use agents (CUAs) that organizes per-topic files containing both text and figures, fetched on demand via a load_topic tool. Skills are built via a two-stage pipeline (authored documentation plus live-application UI exploration). On CUA-World and OSExpert-Eval, a Claude-based agent achieves 0.456 average score (+15.3 over no-skill baseline of 0.303; +8.3 over a matched text-only skill of 0.373), with the gain attributed to visual figures aiding UI element identification and post-action state verification. Code is released.
Significance. If the modality comparison is robust, the work supplies direct evidence that retaining visual artifacts in reusable skills improves long-horizon GUI agent performance beyond text-only representations, with implications for skill libraries in agentic systems. The matched text-only control and open code are strengths that facilitate verification.
major comments (2)
- [Construction pipeline (abstract and methods describing skill construction)] The two-stage pipeline (authored documentation combined with live-application UI exploration) is presented as the source of the skill artifacts, yet the manuscript reports no validation step, human review, or automated check confirming that captured UI screenshots match current application state, are task-relevant, or add non-redundant information beyond what can be verbalized. This assumption is load-bearing for the central claim that the +8.3 point gain (0.456 vs 0.373) can be attributed to modality rather than figure quality or noise.
- [Evaluation section (benchmarks and results)] The empirical comparison lacks reported details on prompt variation, figure quality controls, or error analysis that would establish robustness of the 0.456 vs 0.373 difference; the abstract notes a matched text-only control but full methods, dataset details, and per-task breakdowns are not provided to verify the result.
minor comments (2)
- [VISUALSKILL representation] The hierarchical index and load_topic MCP tool are described at a high level; a concrete example of a per-topic file (text + figures) would clarify consumption by the agent.
- [Construction pipeline] No discussion of potential staleness in live-exploration figures or how the pipeline handles application updates.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below with clarifications and commit to revisions that strengthen the presentation of the construction pipeline and evaluation details without altering the core claims.
read point-by-point responses
-
Referee: [Construction pipeline (abstract and methods describing skill construction)] The two-stage pipeline (authored documentation combined with live-application UI exploration) is presented as the source of the skill artifacts, yet the manuscript reports no validation step, human review, or automated check confirming that captured UI screenshots match current application state, are task-relevant, or add non-redundant information beyond what can be verbalized. This assumption is load-bearing for the central claim that the +8.3 point gain (0.456 vs 0.373) can be attributed to modality rather than figure quality or noise.
Authors: We agree that the absence of an explicit validation description leaves the attribution open to the concern raised. The live UI exploration stage captures current application states by design, and the authored documentation stage ensures topical relevance, but these steps were not formally documented as quality controls. In the revision we will add a dedicated subsection describing the quality assurance process, including human review of a random sample of skills for state fidelity, task relevance, and non-redundancy relative to text, plus simple automated checks for image-text alignment. This addition will make the load-bearing assumption explicit and verifiable. revision: yes
-
Referee: [Evaluation section (benchmarks and results)] The empirical comparison lacks reported details on prompt variation, figure quality controls, or error analysis that would establish robustness of the 0.456 vs 0.373 difference; the abstract notes a matched text-only control but full methods, dataset details, and per-task breakdowns are not provided to verify the result.
Authors: The matched text-only control is constructed from identical source content and differs only in modality, as stated in the methods; this design isolates the visual contribution. We nevertheless concur that additional robustness information is warranted. The revision will expand the evaluation section with (i) results across multiple prompt templates, (ii) figure quality controls applied during skill construction, (iii) a concise error analysis categorizing failure modes, and (iv) per-task score breakdowns for both benchmarks. Dataset construction details and the full per-topic skill inventory will be moved to an appendix. revision: yes
Circularity Check
No circularity: empirical comparison on fixed benchmarks with matched control
full rationale
The paper reports an empirical evaluation of VISUALSKILL on CUA-World and OSExpert-Eval benchmarks. The central claim is a measured performance lift (0.456 vs 0.373) when retaining visual figures versus a matched text-only condition generated from identical source content. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text. The two-stage pipeline is a construction method whose output quality is an external assumption, not a self-referential quantity that forces the reported delta. The result is therefore independent of any definitional or fitted reduction.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard benchmark evaluation protocols for computer-use agents are sufficient to measure skill utility.
invented entities (1)
-
VISUALSKILL hierarchical multimodal skill
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Saaket Agashe, Kyle Wong, Vincent Tu, Jiachen Yang, Ang Li, and Xin Eric Wang. 2025. Agent s2: A compositional generalist-specialist framework for computer use agents. arXiv preprint arXiv:2504.00906
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[2]
Pranjal Aggarwal, Graham Neubig, and Sean Welleck. 2026. Gym-anything: Turn any software into an agent environment. arXiv preprint arXiv:2604.06126
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[3]
Anthropic . 2026. Introducing claude sonnet 4.6. https://www.anthropic.com/news/claude-sonnet-4-6. Accessed: 2026-05-20
2026
- [4]
-
[5]
Guanyu Jiang, Zhaochen Su, Xiaoye Qu, and Yi R Fung. 2026. Xskill: Continual learning from experience and skills in multimodal agents. arXiv preprint arXiv:2603.12056
work page internal anchor Pith review arXiv 2026
- [6]
-
[7]
Simular AI . 2026. Agent s3. https://www.simular.ai/articles/agent-s3. Accessed: 2026-05-20
2026
-
[8]
Xinyuan Wang, Bowen Wang, Dunjie Lu, Junlin Yang, Tianbao Xie, Junli Wang, Jiaqi Deng, Xiaole Guo, Yiheng Xu, Chen Wu, and 1 others. 2026. Opencua: Open foundations for computer-use agents. Advances in Neural Information Processing Systems, 38:139756--139806
2026
- [9]
-
[10]
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh J Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, and 1 others. 2024. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer environments. Advances in Neural Information Processing Systems, 37:52040--52094
2024
-
[11]
Kangning Zhang, Shuai Shao, Qingyao Li, Jianghao Lin, Lingyue Fu, Shijian Wang, Wenxiang Jiao, Yuan Lu, Weiwen Liu, Weinan Zhang, and 1 others. 2026. Mmskills: Towards multimodal skills for general visual agents. arXiv preprint arXiv:2605.13527
work page internal anchor Pith review Pith/arXiv arXiv 2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.