Data-Forcing Distillation: Restoring Diversity and Fidelity in Few-Step Video Generation
Pith reviewed 2026-06-27 00:53 UTC · model grok-4.3
The pith
Data-Forcing Distillation restores diversity and fidelity in few-step video diffusion models via teacher score discrepancy guidance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
DFD adds the teacher score discrepancy term to the reverse KL objective of distribution matching distillation, directing the student toward the real-data distribution to recover missing modes and suppress artifacts absent from real videos.
What carries the argument
Teacher score discrepancy term that measures the gap between teacher and student predictions to enforce real-data alignment.
If this is right
- Few-step video generators regain sample diversity comparable to multi-step teachers.
- Over-saturation artifacts are eliminated, yielding more natural video appearance and dynamics.
- The method applies uniformly to text-to-video, image-to-video, and autoregressive video tasks.
- Only 100-300 finetuning steps suffice to surpass the teacher model on tested architectures.
- The change integrates into existing DMD-style pipelines with one line of code.
Where Pith is reading between the lines
- The approach may extend to distilling other generative modalities where reverse KL causes mode dropping.
- Real-time video applications could benefit from the reduced step count while preserving fidelity.
- Further analysis could test whether the discrepancy term scales to larger teacher-student gaps.
Load-bearing premise
The teacher score discrepancy term consistently guides the student to real data modes without introducing new artifacts or requiring architecture-specific adjustments.
What would settle it
Train a few-step student with DFD on a held-out video dataset and check whether mode collapse or over-saturation reappears in generated samples.
Figures

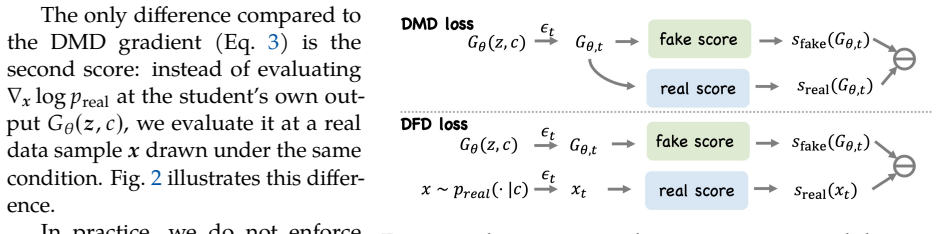








read the original abstract
Recent progress has shown promise in distilling multi-step video diffusion models into efficient few-step students. Among them, Distribution Matching Distillation (DMD) and its successor DMD2 achieved strong generation quality and fast convergence. However, due to the nature of the reverse Kullback--Leibler (KL) objective, these methods exhibit two persistent failure modes: a substantial drop in sample diversity, and visibly over-saturated outputs that deviate from real-video appearance. In this work, we propose Data-Forcing Distillation (DFD), a simple post-training framework that restores diversity and fidelity in DMD with only a single-line of code change. At its core is the teacher score discrepancy to guide the student toward the real-data distribution, pulling it to missing modes (mitigating mode collapse) and away from problematic modes absent in real data (avoiding over-saturation). We provide an in-depth theoretical analysis of our framework and validate our approach on text-to-video, image-to-video, and autoregressive video generation. With only 100--300 steps of finetuning, DFD effectively restores diversity and fidelity on both Wan2.1-1.3B and Cosmos-Predict2.5-2B model, resolving the over-saturation artifacts with significantly better video dynamics and appearance, and even outperforms the teacher model.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Data-Forcing Distillation (DFD), a minimal post-training modification to Distribution Matching Distillation (DMD) for few-step video diffusion models. The core addition is a teacher score discrepancy term intended to restore sample diversity and correct over-saturation by guiding the student toward the real-data distribution. The manuscript provides theoretical analysis of the framework and reports empirical results on text-to-video, image-to-video, and autoregressive settings using Wan2.1-1.3B and Cosmos-Predict2.5-2B, claiming that 100-300 finetuning steps suffice to resolve the failure modes and that the resulting student can outperform the original multi-step teacher.
Significance. If the central claims hold under controlled evaluation, the work would be significant for practical few-step video generation: it targets a documented weakness of reverse-KL distillation methods with a lightweight fix and reports strong gains on two production-scale models. The emphasis on minimal additional training steps is a practical strength.
major comments (2)
- [Abstract, §5] Abstract and §5 (Experiments): The claim that DFD 'even outperforms the teacher model' is load-bearing for the central contribution. The reported comparisons must include a few-step teacher baseline evaluated at the same inference budget (4-8 steps) as the DFD student; without it, any apparent superiority is expected from the baseline multi-step vs. few-step mismatch and does not demonstrate that the score-discrepancy term itself yields a superior distribution.
- [§4] §4 (Theoretical analysis): The derivation that the teacher score discrepancy term 'pulls it to missing modes (mitigating mode collapse) and away from problematic modes' requires an explicit fixed-point or gradient analysis showing that the added term does not reduce to a reparameterization of the existing DMD objective or introduce new modes of collapse. The current description leaves open whether the guidance is parameter-free or requires model-specific scaling.
minor comments (2)
- [§5] Figure captions and §5 tables should explicitly state the number of denoising steps used for every baseline and proposed method to allow direct comparison of inference cost.
- [§3] The abstract states 'a single-line of code change'; the precise modified loss expression should appear in the main text (not only appendix) for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below and indicate the revisions we will incorporate.
read point-by-point responses
-
Referee: [Abstract, §5] Abstract and §5 (Experiments): The claim that DFD 'even outperforms the teacher model' is load-bearing for the central contribution. The reported comparisons must include a few-step teacher baseline evaluated at the same inference budget (4-8 steps) as the DFD student; without it, any apparent superiority is expected from the baseline multi-step vs. few-step mismatch and does not demonstrate that the score-discrepancy term itself yields a superior distribution.
Authors: We agree that including a few-step teacher baseline at the same inference budget (4-8 steps) would strengthen the empirical validation and isolate the contribution of the score-discrepancy term. Our current comparisons focus on the original multi-step teacher to highlight recovery of its performance with few steps, but we acknowledge the referee's point regarding potential mismatch. In the revised version, we will add these controlled baselines for both Wan2.1-1.3B and Cosmos-Predict2.5-2B. revision: yes
-
Referee: [§4] §4 (Theoretical analysis): The derivation that the teacher score discrepancy term 'pulls it to missing modes (mitigating mode collapse) and away from problematic modes' requires an explicit fixed-point or gradient analysis showing that the added term does not reduce to a reparameterization of the existing DMD objective or introduce new modes of collapse. The current description leaves open whether the guidance is parameter-free or requires model-specific scaling.
Authors: We will expand §4 with an explicit fixed-point and gradient analysis of the combined DMD + teacher score discrepancy objective. This will show that the added term provides a distinct directional force toward the real-data distribution that is not equivalent to a reparameterization of the reverse-KL term alone. The core formulation is parameter-free, relying only on the difference in teacher scores; we will clarify this and any practical scaling factors used in experiments. revision: yes
Circularity Check
No circularity: new discrepancy term presented as independent addition with no reduction to fitted inputs or self-citations
full rationale
The paper introduces DFD as a post-training framework using a teacher score discrepancy term to restore diversity and fidelity in DMD-based distillation. The abstract and description frame this as a simple, independent modification (single-line code change) supported by in-depth theoretical analysis, without any equations or claims that reduce the new term to a fitted parameter from prior work, a self-citation chain, or a self-definitional loop. No load-bearing uniqueness theorems or ansatzes imported via citation are referenced in the provided text. The central claim of outperformance and restoration stands on the proposed term itself rather than re-labeling existing quantities. This is the common case of a self-contained method addition.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Score-Based Generative Modeling through Stochastic Differential Equations
Yang Song, Jascha Sohl-Dickstein, Diederik P Kingma, Abhishek Kumar, Stefano Ermon, and Ben Poole. Score-based generative modeling through stochastic differential equations.arXiv preprint arXiv:2011.13456, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[2]
Flow Matching for Generative Modeling
Yaron Lipman, Ricky TQ Chen, Heli Ben-Hamu, Maximilian Nickel, and Matt Le. Flow matching for generative modeling.arXiv preprint arXiv:2210.02747, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[3]
High- resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. High- resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022. 15
2022
-
[4]
Wan: Open and Advanced Large-Scale Video Generative Models
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[5]
World Simulation with Video Foundation Models for Physical AI
Arslan Ali, Junjie Bai, Maciej Bala, Yogesh Balaji, Aaron Blakeman, Tiffany Cai, Jiaxin Cao, Tianshi Cao, Elizabeth Cha, Yu-Wei Chao, and other. World simulation with video foundation models for physical AI.arXiv preprint arXiv:2511.00062, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
HunyuanVideo: A Systematic Framework For Large Video Generative Models
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[7]
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Zhuoyi Yang, Jiayan Teng, Wendi Zheng, Ming Ding, Shiyu Huang, Jiazheng Xu, Yuanming Yang, Wenyi Hong, Xiaohan Zhang, Guanyu Feng, et al. Cogvideox: Text-to-video diffusion models with an expert transformer.arXiv preprint arXiv:2408.06072, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[8]
Video generation models as world simulators
Tim Brooks, Bill Peebles, Connor Holmes, Will DePue, Yufei Guo, Leo Jing, David Schnurr, Joe Taylor, Troy Luhman, Eric Luhman, et al. Video generation models as world simulators. OpenAI Blog, 1(8):1, 2024
2024
-
[9]
Progressive Distillation for Fast Sampling of Diffusion Models
Tim Salimans and Jonathan Ho. Progressive distillation for fast sampling of diffusion models. arXiv preprint arXiv:2202.00512, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[10]
On distillation of guided diffusion models
Chenlin Meng, Robin Rombach, Ruiqi Gao, Diederik Kingma, Stefano Ermon, Jonathan Ho, and Tim Salimans. On distillation of guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 14297–14306, 2023
2023
-
[11]
Consistency models
Yang Song, Prafulla Dhariwal, Mark Chen, and Ilya Sutskever. Consistency models. 2023
2023
-
[12]
Improved Techniques for Training Consistency Models
YangSongandPrafullaDhariwal. Improvedtechniquesfortrainingconsistencymodels.arXiv preprint arXiv:2310.14189, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[13]
Simplifying, Stabilizing and Scaling Continuous-Time Consistency Models
Cheng Lu and Yang Song. Simplifying, stabilizing and scaling continuous-time consistency models.arXiv preprint arXiv:2410.11081, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[14]
Mean Flows for One-step Generative Modeling
Zhengyang Geng, Mingyang Deng, Xingjian Bai, J Zico Kolter, and Kaiming He. Mean flows for one-step generative modeling.arXiv preprint arXiv:2505.13447, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
- [15]
-
[16]
One-step diffusion with distribution matching distillation
Tianwei Yin, Michaël Gharbi, Richard Zhang, Eli Shechtman, Fredo Durand, William T Free- man, and Taesung Park. One-step diffusion with distribution matching distillation. InPro- ceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6613–6623, 2024
2024
-
[17]
Improved distribution matching distillation for fast image synthesis
Tianwei Yin, Michaël Gharbi, Taesung Park, Richard Zhang, Eli Shechtman, Fredo Durand, and William T Freeman. Improved distribution matching distillation for fast image synthesis. Advances in neural information processing systems, 37:47455–47487, 2024
2024
-
[18]
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.Advances in Neural Information Processing Systems, 36:76525–76546, 2023
Weijian Luo, Tianyang Hu, Shifeng Zhang, Jiacheng Sun, Zhenguo Li, and Zhihua Zhang. Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.Advances in Neural Information Processing Systems, 36:76525–76546, 2023. 16
2023
-
[19]
Yifei Wang, Weimin Bai, Colin Zhang, Debing Zhang, Weijian Luo, and He Sun. Uni-instruct: One-step diffusion model through unified diffusion divergence instruction.arXiv preprint arXiv:2505.20755, 2025
-
[20]
DreamFusion: Text-to-3D using 2D Diffusion
Ben Poole, Ajay Jain, Jonathan T Barron, and Ben Mildenhall. Dreamfusion: Text-to-3d using 2d diffusion.arXiv preprint arXiv:2209.14988, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[21]
Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation
Zhengyi Wang, Cheng Lu, Yikai Wang, Fan Bao, Chongxuan Li, Hang Su, and Jun Zhu. Pro- lificdreamer: High-fidelity and diverse text-to-3d generation with variational score distillation. Advances in neural information processing systems, 36:8406–8441, 2023
2023
-
[22]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[23]
Latent Consistency Models: Synthesizing High-Resolution Images with Few-Step Inference
Simian Luo, Yiqin Tan, Longbo Huang, Jian Li, and Hang Zhao. Latent consistency models: Synthesizing high-resolution images with few-step inference.arXiv preprint arXiv:2310.04378, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[24]
T2v-turbo: Breaking the quality bottleneck of video consistency model with mixed reward feedback.Advances in neural information processing systems, 37:75692–75726, 2024
Jiachen Li, Weixi Feng, Tsu-Jui Fu, Xinyi Wang, Sugato Basu, Wenhu Chen, and William Y Wang. T2v-turbo: Breaking the quality bottleneck of video consistency model with mixed reward feedback.Advances in neural information processing systems, 37:75692–75726, 2024
2024
-
[25]
Consistency models made easy
Zhengyang Geng, Ashwini Pokle, Weijian Luo, Justin Lin, and J Zico Kolter. Consistency models made easy. InThe Thirteenth International Conference on Learning Representations, 2024
2024
-
[26]
Dongjun Kim, Chieh-Hsin Lai, Wei-Hsiang Liao, Naoki Murata, Yuhta Takida, Toshimitsu Uesaka, Yutong He, Yuki Mitsufuji, and Stefano Ermon. Consistency trajectory models: Learning probability flow ode trajectory of diffusion.arXiv preprint arXiv:2310.02279, 2023
-
[27]
Large Scale Diffusion Distillation via Score-Regularized Continuous-Time Consistency
Kaiwen Zheng, Yuji Wang, Qianli Ma, Huayu Chen, Jintao Zhang, Yogesh Balaji, Jianfei Chen, Ming-Yu Liu, Jun Zhu, and Qinsheng Zhang. Large scale diffusion distillation via score-regularized continuous-time consistency.arXiv preprint arXiv:2510.08431, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[28]
Phased consistency models.Advances in neural information processing systems, 37:83951–84009, 2024
Fu-Yun Wang, Zhaoyang Huang, Alexander W Bergman, Dazhong Shen, Peng Gao, Michael Lingelbach, Keqiang Sun, Weikang Bian, Guanglu Song, Yu Liu, et al. Phased consistency models.Advances in neural information processing systems, 37:83951–84009, 2024
2024
-
[29]
arXiv preprint arXiv:2502.15681 , year=
Yilun Xu, Weili Nie, and Arash Vahdat. One-step diffusion models with𝑓-divergence distri- bution matching.arXiv preprint arXiv:2502.15681, 2025
-
[30]
One-step diffusiondistillationthroughscoreimplicitmatching.AdvancesinNeuralInformationProcessing Systems, 37:115377–115408, 2024
Weijian Luo, Zemin Huang, Zhengyang Geng, J Zico Kolter, and Guo-jun Qi. One-step diffusiondistillationthroughscoreimplicitmatching.AdvancesinNeuralInformationProcessing Systems, 37:115377–115408, 2024
2024
-
[31]
Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation
Mingyuan Zhou, Huangjie Zheng, Zhendong Wang, Mingzhang Yin, and Hai Huang. Score identity distillation: Exponentially fast distillation of pretrained diffusion models for one-step generation. InForty-first International Conference on Machine Learning, 2024
2024
-
[32]
Diversity-Preserved Distribution Matching Distillation for Fast Visual Synthesis
Tianhe Wu, Ruibin Li, Lei Zhang, and Kede Ma. Diversity-preserved distribution matching distillation for fast visual synthesis.arXiv preprint arXiv:2602.03139, 2026. 17
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[33]
Transition matching distillation for fast video generation.ArXiv, abs/2601.09881, 2026
Weili Nie, Julius Berner, Nanye Ma, Chao Liu, Saining Xie, and Arash Vahdat. Transition matching distillation for fast video generation.ArXiv, abs/2601.09881, 2026
-
[34]
Training neural samplers with reverse diffusive kl divergence.arXiv preprint arXiv:2410.12456, 2024
Jiajun He, Wenlin Chen, Mingtian Zhang, David Barber, and José Miguel Hernández-Lobato. Training neural samplers with reverse diffusive kl divergence.arXiv preprint arXiv:2410.12456, 2024
-
[35]
Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis
Yanzuo Lu, Yuxi Ren, Xin Xia, Shanchuan Lin, Xing Wang, Xuefeng Xiao, Andy J Ma, Xiaohua Xie, and Jian-Huang Lai. Adversarial distribution matching for diffusion distillation towards efficient image and video synthesis. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16818–16829, 2025
2025
-
[36]
ViPE: Video Pose Engine for 3D Geometric Perception
Jiahui Huang, Qunjie Zhou, Hesam Rabeti, Aleksandr Korovko, Huan Ling, Xuanchi Ren, Tianchang Shen, Jun Gao, Dmitry Slepichev, Chen-Hsuan Lin, Jiawei Ren, Kevin Xie, Joydeep Biswas,LauraLeal-Taixe,andSanjaFidler.Vipe: Videoposeenginefor3dgeometricperception. InNVIDIA Research Whitepapers arXiv:2508.10934, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[37]
Vbench: Comprehensive benchmark suiteforvideogenerativemodels
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, et al. Vbench: Comprehensive benchmark suiteforvideogenerativemodels. InProceedingsoftheIEEE/CVFConferenceonComputerVision and Pattern Recognition, pages 21807–21818, 2024
2024
-
[38]
Self Forcing: Bridging the Train-Test Gap in Autoregressive Video Diffusion
Xun Huang, Zhengqi Li, Guande He, Mingyuan Zhou, and Eli Shechtman. Self forcing: Bridging the train-test gap in autoregressive video diffusion.arXiv preprint arXiv:2506.08009, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[39]
Oriane Siméoni, Huy V Vo, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[40]
AlecRadford,JongWookKim,ChrisHallacy,AdityaRamesh,GabrielGoh,SandhiniAgarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, et al. Learning transferable visual modelsfromnaturallanguagesupervision. InInternationalconferenceonmachinelearning,pages 8748–8763. PmLR, 2021. 18 A Additional Theory A.1 teacher score discrepancy A good regularizer mus...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.