Towards Scalable Customization and Deployment of Multi-Agent Systems for Enterprise Applications
Pith reviewed 2026-06-27 00:14 UTC · model grok-4.3
The pith
A two-stage framework adapts compact LLMs for enterprise multi-agent tasks and achieves 4.48 times higher throughput while preserving performance.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
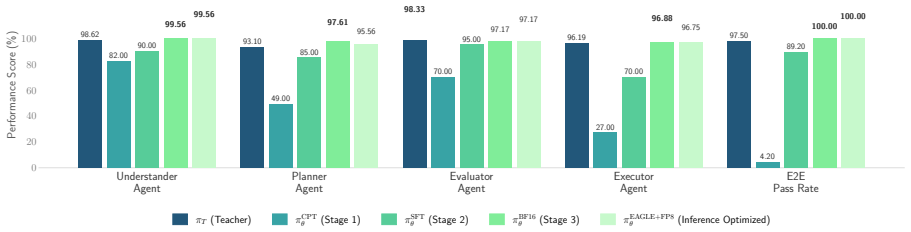
The authors state that their unified framework, built from an Agentic Model Customization stage followed by an Inference Optimization stage, supports rapid domain adaptation of multi-agent systems and produces a 4.48x speedup in throughput across enterprise workloads while maintaining overall performance and increasing robustness on long-tail scenarios.
What carries the argument
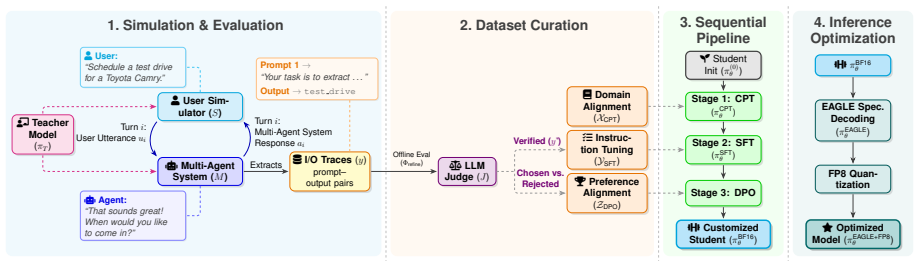
The two-stage pipeline of Agentic Model Customization (continual pretraining, supervised fine-tuning, preference optimization) paired with Inference Optimization (speculative decoding and FP8 quantization with calibration).
If this is right
- Multi-agent systems can be adapted to new enterprise domains more rapidly than before.
- Throughput rises by a factor of 4.48 with only minimal quality loss on standard tasks.
- Robustness improves specifically on long-tail scenarios common in real enterprise data.
- Serving costs drop because the optimizations enable higher throughput at comparable accuracy.
Where Pith is reading between the lines
- The same staged pipeline might be tested on multi-agent setups that involve more than two models or different communication patterns.
- Long-tail robustness gains could reduce the frequency of manual interventions in variable production environments.
- The framework's emphasis on compact models suggests it may scale more easily to resource-constrained enterprise hardware than larger base models would.
Load-bearing premise
The described combination of continual pretraining, supervised fine-tuning, preference optimization, speculative decoding, and FP8 quantization can be applied to multi-agent workflows without introducing compatibility issues or quality degradation that would offset the claimed throughput gains.
What would settle it
Running the full framework on a new enterprise multi-agent workload and measuring whether throughput reaches at least 4x the baseline while task success rates on long-tail cases stay the same or improve would confirm or refute the central performance claims.
Figures


read the original abstract
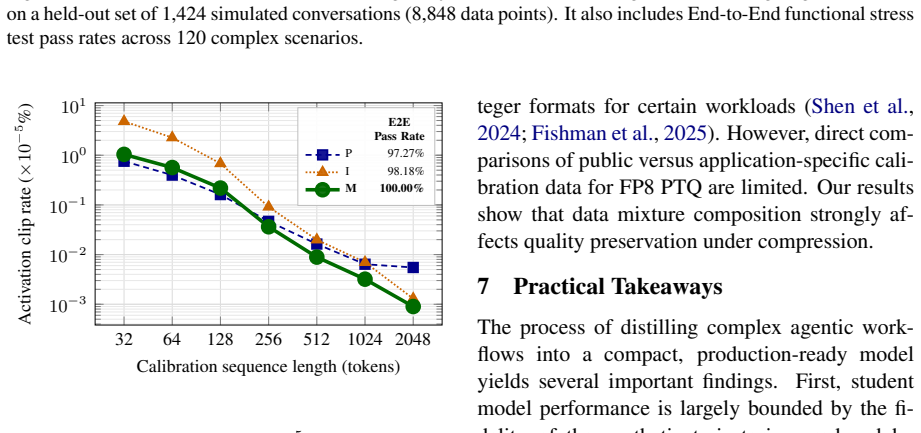
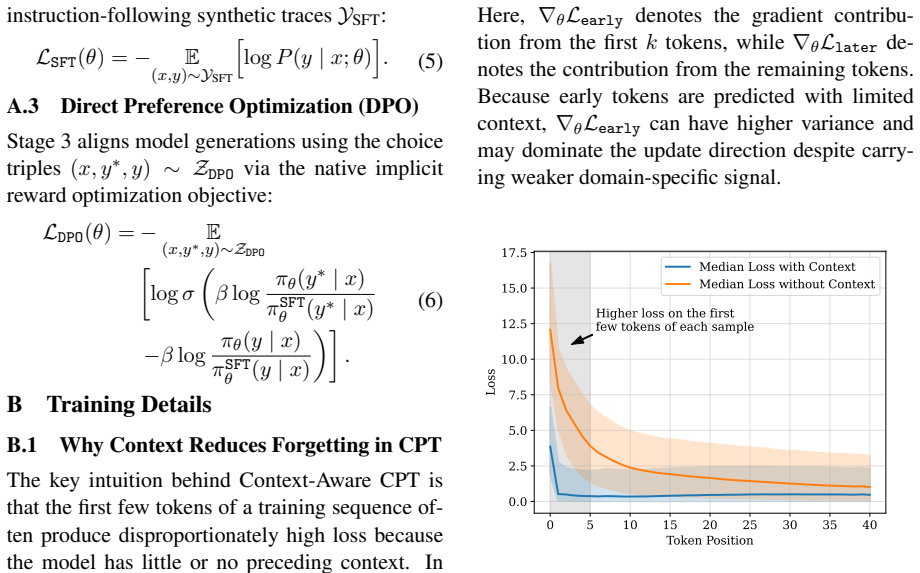
Large language model (LLM)-based multi-agent systems demonstrate strong performance on complex reasoning and task execution, enabling broad enterprise applications. However, production deployment remains challenging due to domain-specific customization requirements and high latency and inference costs in agentic workflows. We propose a unified framework for customization and efficient deployment of multi-agent systems in real-world settings. The first stage, Agentic Model Customization, combines continual pretraining, supervised fine-tuning, and preference optimization to adapt a compact model to specialized domains while retaining strong agentic capabilities. The second stage, Inference Optimization, integrates speculative decoding and FP8 quantization with targeted calibration to enable cost-efficient serving with minimal quality loss. Across enterprise workloads, our framework enables rapid domain adaptation and achieves a 4.48x speedup in throughput while maintaining performance and improving robustness on long-tail scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a unified two-stage framework for customizing and deploying LLM-based multi-agent systems in enterprise settings. Stage 1 (Agentic Model Customization) adapts compact models to specialized domains via continual pretraining, supervised fine-tuning, and preference optimization while retaining agentic capabilities. Stage 2 (Inference Optimization) combines speculative decoding with FP8 quantization and targeted calibration for efficient serving. The central claim is that the framework enables rapid domain adaptation and delivers a 4.48x throughput speedup across enterprise workloads while maintaining performance and improving robustness on long-tail scenarios.
Significance. If the performance claims are substantiated with rigorous experiments, the work would address a practically important gap in scaling multi-agent systems for production use by combining domain adaptation techniques with inference optimizations. The structured separation of customization and deployment stages is a reasonable engineering contribution, though the absence of supporting evidence for the key quantitative result limits immediate significance.
major comments (2)
- [Abstract] Abstract: The central claim of a 4.48x throughput improvement (with maintained performance) is presented without any reference to experimental setup, datasets, baselines, error bars, ablation studies, or end-to-end metrics on agentic traces. This directly undermines evaluation of the load-bearing performance assertion.
- [Inference Optimization] Inference Optimization stage: The integration of speculative decoding and FP8 quantization is asserted to work with multi-agent coordination (inter-agent messaging, state passing, conditional branching) but no compatibility analysis, interaction effects, or quality metrics on agentic workflows are supplied, leaving the compatibility assumption unverified.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and indicate where revisions will be made to improve clarity and completeness.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim of a 4.48x throughput improvement (with maintained performance) is presented without any reference to experimental setup, datasets, baselines, error bars, ablation studies, or end-to-end metrics on agentic traces. This directly undermines evaluation of the load-bearing performance assertion.
Authors: We agree that the abstract presents the central claim concisely without referencing the supporting experimental details. The full manuscript reports these elements in the Evaluation section, including the specific enterprise workloads, datasets for customization and testing, baselines (standard fine-tuned models without optimization), error bars from repeated runs, component ablations, and end-to-end metrics on agentic traces. To address the concern, we will revise the abstract to include a brief reference to the evaluation methodology while preserving its length constraints. revision: yes
-
Referee: [Inference Optimization] Inference Optimization stage: The integration of speculative decoding and FP8 quantization is asserted to work with multi-agent coordination (inter-agent messaging, state passing, conditional branching) but no compatibility analysis, interaction effects, or quality metrics on agentic workflows are supplied, leaving the compatibility assumption unverified.
Authors: The optimizations are applied at the per-model inference level and are designed to be orthogonal to higher-level agent coordination mechanisms. However, we acknowledge that the manuscript does not supply an explicit compatibility analysis, discussion of interaction effects, or dedicated quality metrics focused on agentic workflows. We will add this analysis in the revised version, including verification that token-level optimizations preserve inter-agent messaging integrity and additional workflow-level quality metrics. revision: yes
Circularity Check
No circularity: empirical framework description with no derivations or fitted predictions
full rationale
The paper presents an engineering framework combining standard techniques (continual pretraining, SFT, preference optimization, speculative decoding, FP8 quantization) for multi-agent LLM systems. No equations, uniqueness theorems, ansatzes, or self-citations appear as load-bearing steps in the provided text. The 4.48x throughput claim is stated as an empirical outcome across workloads rather than a derived prediction from fitted inputs or self-referential definitions. The central claims rest on described integration and reported results, not on any reduction to the paper's own inputs by construction. This is the expected non-finding for a systems paper without mathematical derivation chains.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems , volume=
T1: A tool-oriented conversational dataset for multi-turn agentic planning , author=. Advances in Neural Information Processing Systems , volume=
-
[2]
Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
Alignment for efficient tool calling of large language models , author=. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing , pages=
2025
-
[3]
Proceedings of the ACM on Web Conference 2025 , pages=
Tool learning in the wild: Empowering language models as automatic tool agents , author=. Proceedings of the ACM on Web Conference 2025 , pages=
2025
-
[4]
International Conference on Machine Learning , pages=
Skill Set Optimization: Reinforcing Language Model Behavior via Transferable Skills , author=. International Conference on Machine Learning , pages=. 2024 , organization=
2024
-
[5]
International Conference on Machine Learning , pages=
Fast inference from transformers via speculative decoding , author=. International Conference on Machine Learning , pages=. 2023 , organization=
2023
-
[6]
Findings of the Association for Computational Linguistics: ACL 2025 , pages=
Re-task: Revisiting llm tasks from capability, skill, and knowledge perspectives , author=. Findings of the Association for Computational Linguistics: ACL 2025 , pages=
2025
-
[7]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
Large language model based multi-agents: a survey of progress and challenges , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence , pages=
-
[8]
Advances in Neural Information Processing Systems , volume=
Are more llm calls all you need? towards the scaling properties of compound ai systems , author=. Advances in Neural Information Processing Systems , volume=
-
[9]
First Conference on Language Modeling , year=
Autogen: Enabling next-gen LLM applications via multi-agent conversations , author=. First Conference on Language Modeling , year=
-
[10]
International Conference on Learning Representations , volume=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. International Conference on Learning Representations , volume=
-
[11]
Proceedings of the 41st International Conference on Machine Learning , pages=
Improving factuality and reasoning in language models through multiagent debate , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[12]
Advances in neural information processing systems , volume=
Direct preference optimization: Your language model is secretly a reward model , author=. Advances in neural information processing systems , volume=
-
[13]
arXiv preprint arXiv:2506.02153 , year=
Small Language Models are the Future of Agentic AI , author=. arXiv preprint arXiv:2506.02153 , year=
-
[14]
arXiv preprint arXiv:2507.19635 , year=
Efficient and scalable agentic AI with heterogeneous systems , author=. arXiv preprint arXiv:2507.19635 , year=
-
[15]
arXiv preprint arXiv:2502.14815 , year=
Optimizing model selection for compound ai systems , author=. arXiv preprint arXiv:2502.14815 , year=
-
[16]
Proceedings of Machine Learning and Systems , volume=
Efficient post-training quantization with fp8 formats , author=. Proceedings of Machine Learning and Systems , volume=
-
[17]
arXiv e-prints , pages=
An investigation of fp8 across accelerators for llm inference , author=. arXiv e-prints , pages=
-
[18]
International Conference on Learning Representations , volume=
Scaling fp8 training to trillion-token llms , author=. International Conference on Learning Representations , volume=
-
[19]
2023 , url=
Elias Frantar and Saleh Ashkboos and Torsten Hoefler and Dan Alistarh , booktitle=. 2023 , url=
2023
-
[20]
International conference on machine learning , pages=
Smoothquant: Accurate and efficient post-training quantization for large language models , author=. International conference on machine learning , pages=. 2023 , organization=
2023
-
[21]
MLSys , year=
AWQ: Activation-aware Weight Quantization for LLM Compression and Acceleration , author=. MLSys , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Quarot: Outlier-free 4-bit inference in rotated llms , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
International Conference on Learning Representations , volume=
Omniquant: Omnidirectionally calibrated quantization for large language models , author=. International Conference on Learning Representations , volume=
-
[24]
Advances in Neural Information Processing Systems , volume=
Eagle-3: Scaling up inference acceleration of large language models via training-time test , author=. Advances in Neural Information Processing Systems , volume=
-
[25]
Proceedings of the 41st International Conference on Machine Learning , pages=
MEDUSA: Simple LLM inference acceleration framework with multiple decoding heads , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[26]
Proceedings of the 41st International Conference on Machine Learning , pages=
Break the sequential dependency of LLM inference using LOOKAHEAD DECODING , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[27]
arXiv preprint arXiv:2310.03714 , year=
Dspy: Compiling declarative language model calls into self-improving pipelines , author=. arXiv preprint arXiv:2310.03714 , year=
-
[28]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
Optimizing instructions and demonstrations for multi-stage language model programs , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages=
2024
-
[29]
Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Get to the point: Summarization with pointer-generator networks , author=. Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[30]
Proceedings of Machine Learning and Systems , volume=
Xgrammar: Flexible and efficient structured generation engine for large language models , author=. Proceedings of Machine Learning and Systems , volume=
-
[31]
arXiv preprint arXiv:2302.01318 , year=
Accelerating large language model decoding with speculative sampling , author=. arXiv preprint arXiv:2302.01318 , year=
-
[32]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Llama pro: Progressive llama with block expansion , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[33]
arXiv preprint arXiv:2407.21783 , year=
The llama 3 herd of models , author=. arXiv preprint arXiv:2407.21783 , year=
-
[34]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Overcoming catastrophic forgetting in massively multilingual continual learning , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[35]
Proceedings of the 41st International Conference on Machine Learning , pages=
EAGLE: speculative sampling requires rethinking feature uncertainty , author=. Proceedings of the 41st International Conference on Machine Learning , pages=
-
[36]
International Conference on Learning Representations , volume=
Flashattention-2: Faster attention with better parallelism and work partitioning , author=. International Conference on Learning Representations , volume=
-
[37]
Proceedings of the 29th symposium on operating systems principles , pages=
Efficient memory management for large language model serving with pagedattention , author=. Proceedings of the 29th symposium on operating systems principles , pages=
-
[38]
Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
Abstractive text summarization using sequence-to-sequence rnns and beyond , author=. Proceedings of the 20th SIGNLL conference on computational natural language learning , pages=
-
[39]
NeurIPS 2025 Workshop on Efficient Reasoning , year=
Optimizing Reasoning Efficiency through Prompt Difficulty Prediction , author=. NeurIPS 2025 Workshop on Efficient Reasoning , year=
2025
-
[40]
Proceedings of the 18th International Natural Language Generation Conference , pages=
Taming the titans: A survey of efficient llm inference serving , author=. Proceedings of the 18th International Natural Language Generation Conference , pages=
-
[41]
Advances in Neural Information Processing Systems , volume=
Fp8 quantization: The power of the exponent , author=. Advances in Neural Information Processing Systems , volume=
-
[42]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Eagle-2: Faster inference of language models with dynamic draft trees , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[43]
arXiv preprint arXiv:2606.11070 , year=
T1-Bench: Benchmarking Multi-Scenario Agents in Real-World Domains , author=. arXiv preprint arXiv:2606.11070 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.