Rethinking Text-to-Image as Semantic-Aware Data Augmentation for Indoor Scene Recognition
Pith reviewed 2026-06-26 21:28 UTC · model grok-4.3
The pith
Stable Diffusion generates synthetic indoor scenes that augment scarce real data to train better scene recognition models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Text-to-image synthesis with Stable Diffusion supplies useful semantic augmentation for indoor scene recognition tasks, and the Diffusion Reconstruction Error metric allows reliable separation of synthetic from real images even with simple classifiers.
What carries the argument
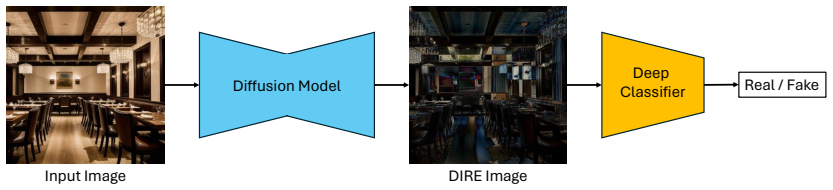
Stable Diffusion text-to-image generation as data augmentation, combined with Diffusion Reconstruction Error (DIRE) for synthetic-image detection.
If this is right
- Deep models trained with the SD-augmented data achieve higher accuracy on real indoor scene test images when authentic data is limited.
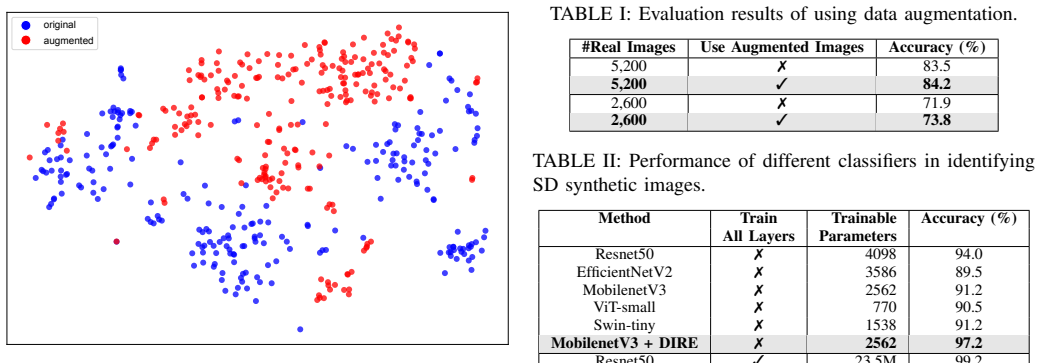
- DIRE enables training of robust detectors that reach 100 percent accuracy on SD-generated images using only lightweight models such as MobilenetV3.
- The augmentation pipeline directly addresses data scarcity caused by lighting, occlusions, and object arrangements in indoor environments.
Where Pith is reading between the lines
- The same generation-plus-detection loop could be tested on other data-scarce vision tasks such as fine-grained object classification.
- If DIRE remains effective across newer diffusion models, it might serve as a general tool for provenance verification of generated content.
- Pairing the augmentation with the detector could create an iterative training loop where models improve on both real and verified synthetic examples.
Load-bearing premise
The synthetic indoor scenes produced by Stable Diffusion are semantically accurate enough to improve real-data performance without introducing harmful distribution shifts or artifacts.
What would settle it
Training models on the MIT Indoor Scene dataset with and without the SD-augmented data and measuring no accuracy gain (or a loss) on the real test split would show the augmentation does not help.
Figures


read the original abstract
In the realm of computer vision, indoor image recognition presents challenges due to the intricate interplay of lighting conditions, occlusions, and diverse object arrangements within confined spaces. To address the lacks of training indoor images, we introduce a novel approach leveraging Stable Diffusion (SD) for the generation of synthetic images, which serve as a powerful data augmentation tool. The utilization of SD offers a principled framework for synthesizing diverse and realistic indoor scenes, thereby enriching the training data pool for robust indoor image recognition models. Experimental findings on the MIT Indoor Scene dataset reveal the potential of our proposed approach in enhancing the training of deep models when authentic data is limited. Furthermore, to prevent the misuse of SD synthetic images, we introduce a counter measure based on DIffusion Reconstruction Error (DIRE). The powerful DIRE presentation enables training robust classifiers only using lightweight deep models. Experiments show that our approach can perfectly recognize SD generated images with the accuracy of 100% using MobilenetV3.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes leveraging Stable Diffusion to generate synthetic indoor scene images as semantic-aware data augmentation for training deep models on the MIT Indoor Scene dataset when real data is scarce. It further introduces a DIRE-based detector to identify such synthetic images, claiming 100% accuracy using MobileNetV3.
Significance. If the augmentation results hold under controlled conditions, the work could offer a practical way to mitigate data scarcity in indoor scene recognition tasks. The dual focus on generation and detection is novel in this context, but the reported perfect detectability of the generated images raises questions about their distributional fidelity to real data, which would directly impact the augmentation premise.
major comments (3)
- [Abstract] Abstract: the central claim of accuracy gains from SD augmentation when real data is limited is presented without any description of experimental controls, baseline comparisons, number of synthetic images per class, or error bars, leaving the result unverified.
- [Abstract] Abstract: the 100% DIRE detection accuracy with MobileNetV3 is reported as an empirical outcome, yet this level of separability is consistent with the existence of detectable artifacts or shifts that would undermine the premise that the generated images are sufficiently realistic to improve real-data test performance.
- [Abstract] Abstract: no quantitative validation (e.g., feature-space distances, per-class realism metrics, or ablation against real held-out images) is provided to confirm that the synthetic images do not introduce distribution shifts or artifacts that degrade recognition on the real test set.
minor comments (1)
- [Abstract] Abstract: the sentence 'To address the lacks of training indoor images' contains a grammatical error and should read 'To address the lack of training indoor images'.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on our manuscript. We address each major comment below, clarifying the experimental details present in the full paper while proposing targeted revisions to the abstract for improved clarity and verifiability.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim of accuracy gains from SD augmentation when real data is limited is presented without any description of experimental controls, baseline comparisons, number of synthetic images per class, or error bars, leaving the result unverified.
Authors: The full manuscript (Sections 4 and 5) specifies the experimental protocol on the MIT Indoor Scenes dataset using limited real samples per class, direct comparisons against standard data augmentation baselines and other generation methods, the exact number of synthetic images generated per class via semantic text prompts, and accuracy results reported as means with standard deviations across multiple random seeds. We agree the abstract should be more self-contained and will revise it to concisely incorporate these controls and reporting details. revision: yes
-
Referee: [Abstract] Abstract: the 100% DIRE detection accuracy with MobileNetV3 is reported as an empirical outcome, yet this level of separability is consistent with the existence of detectable artifacts or shifts that would undermine the premise that the generated images are sufficiently realistic to improve real-data test performance.
Authors: The 100% detection result with the lightweight MobileNetV3 on DIRE features is presented as evidence of an effective countermeasure against misuse of synthetic images, leveraging diffusion-specific reconstruction errors rather than generic visual artifacts. This separability does not contradict the augmentation utility: the semantic text conditioning produces images that improve real-test recognition accuracy in our controlled experiments, showing that any detectable properties do not degrade task-relevant semantics. We will add a clarifying clause to the abstract distinguishing the detection goal from the augmentation premise. revision: partial
-
Referee: [Abstract] Abstract: no quantitative validation (e.g., feature-space distances, per-class realism metrics, or ablation against real held-out images) is provided to confirm that the synthetic images do not introduce distribution shifts or artifacts that degrade recognition on the real test set.
Authors: The manuscript reports that models trained on the SD-augmented sets outperform real-data-only baselines on the held-out real test set, providing empirical evidence against harmful shifts; additional ablations vary the synthetic-to-real ratio. To strengthen this, we will incorporate explicit quantitative validations such as feature-space distances (e.g., Fréchet Inception Distance per class) and direct comparisons against held-out real images in the revised manuscript and update the abstract to reference these metrics. revision: yes
Circularity Check
No significant circularity; claims are empirical outcomes
full rationale
The paper presents its core results (data-augmentation gains on MIT Indoor Scenes and 100% DIRE-based detection accuracy with MobileNetV3) as experimental findings rather than quantities derived from equations, fitted parameters, or self-referential definitions. No load-bearing self-citations, uniqueness theorems, ansatzes, or renamings of known results appear in the provided text. The augmentation premise is an unverified modeling assumption but does not reduce any claimed prediction to the inputs by construction, satisfying the criteria for a self-contained empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Perceptual @organization and recognition of indoor scenes from rgb-d images,
S. Gupta, P. Arbelaez, and J. Malik, “Perceptual @organization and recognition of indoor scenes from rgb-d images,” inCVPR, 2013, pp. 564–571
2013
-
[2]
Indoor scene recognition through object detection,
P. Espinace, T. Kollar, A. Soto, and N. Roy, “Indoor scene recognition through object detection,” inICRA, 2010, pp. 1406–1413
2010
-
[3]
Indoor image recognition and classification via deep convolutional neural network,
M. Afif, R. Ayachi, Y . Said, E. Pissaloux, and M. Atri, “Indoor image recognition and classification via deep convolutional neural network,” inInternational Conference on Sciences of Electronics, Technologies of Information and Telecommunications (SETIT’18), Vol. 1, 2020, pp. 364–371
2020
-
[4]
Deep learning based application for indoor scene recognition,
M. Afif, R. Ayachi, Y . Said, and M. Atri, “Deep learning based application for indoor scene recognition,”Neural Processing Letters, vol. 51, pp. 2827–2837, 2020
2020
-
[5]
Recognizing indoor scenes,
A. Quattoni and A. Torralba, “Recognizing indoor scenes,” inCVPR, 2009, pp. 413–420
2009
-
[6]
A survey on image data augmen- tation for deep learning,
C. Shorten and T. M. Khoshgoftaar, “A survey on image data augmen- tation for deep learning,”Journal of big data, vol. 6, no. 1, pp. 1–48, 2019
2019
-
[7]
Eda: Easy data augmentation techniques for boosting performance on text classification tasks,
J. Wei and K. Zou, “Eda: Easy data augmentation techniques for boosting performance on text classification tasks,”arXiv preprint arXiv:1901.11196, 2019
-
[8]
The Effectiveness of Data Augmentation in Image Classification using Deep Learning
L. Perez and J. Wang, “The effectiveness of data augmentation in image classification using deep learning,”arXiv preprint arXiv:1712.04621, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[9]
The art of data augmentation,
D. A. Van Dyk and X.-L. Meng, “The art of data augmentation,”Journal of Computational and Graphical Statistics, vol. 10, no. 1, pp. 1–50, 2001
2001
-
[10]
Data augmentation for improving deep learning in image classification problem,
A. Mikołajczyk and M. Grochowski, “Data augmentation for improving deep learning in image classification problem,” in2018 international interdisciplinary PhD workshop (IIPhDW), 2018, pp. 117–122
2018
-
[11]
Generative adversarial networks,
I. Goodfellow, J. Pouget-Abadie, M. Mirza, B. Xu, D. Warde-Farley, S. Ozair, A. Courville, and Y . Bengio, “Generative adversarial networks,” Communications of the ACM, vol. 63, no. 11, pp. 139–144, 2020
2020
-
[12]
High- resolution image synthesis with latent diffusion models,
R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High- resolution image synthesis with latent diffusion models,” inCVPR, 2022, pp. 10 684–10 695
2022
-
[13]
Hierarchical Text-Conditional Image Generation with CLIP Latents
A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical text-conditional image generation with clip latents,”arXiv preprint arXiv:2204.06125, vol. 1, no. 2, p. 3, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[15]
Scaling up gans for text-to-image synthesis,
M. Kang, J.-Y . Zhu, R. Zhang, J. Park, E. Shechtman, S. Paris, and T. Park, “Scaling up gans for text-to-image synthesis,” inCVPR, 2023, pp. 10 124–10 134
2023
-
[16]
Df-gan: A simple and effective baseline for text-to-image synthesis,
M. Tao, H. Tang, F. Wu, X.-Y . Jing, B.-K. Bao, and C. Xu, “Df-gan: A simple and effective baseline for text-to-image synthesis,” inCVPR, 2022, pp. 16 515–16 525
2022
-
[17]
Galip: Generative adversarial clips for text-to-image synthesis,
M. Tao, B.-K. Bao, H. Tang, and C. Xu, “Galip: Generative adversarial clips for text-to-image synthesis,” inCVPR, 2023, pp. 14 214–14 223
2023
-
[18]
Efficientnetv2: Smaller models and faster training,
M. Tan and Q. Le, “Efficientnetv2: Smaller models and faster training,” inICML, 2021, pp. 10 096–10 106
2021
-
[19]
A. Ovadya and J. Whittlestone, “Reducing malicious use of synthetic media research: Considerations and potential release practices for ma- chine learning,”arXiv preprint arXiv:1907.11274, 2019
work page internal anchor Pith review Pith/arXiv arXiv 1907
-
[20]
Evaluating the social impact of generative ai systems in systems and society,
I. Solaiman, Z. Talat, W. Agnew, L. Ahmad, D. Baker, S. L. Blodgett, H. Daum ´e III, J. Dodge, E. Evans, S. Hookeret al., “Evaluating the social impact of generative ai systems in systems and society,”arXiv preprint arXiv:2306.05949, 2023
-
[21]
Dire for diffusion-generated image detection,
Z. Wang, J. Bao, W. Zhou, W. Wang, H. Hu, H. Chen, and H. Li, “Dire for diffusion-generated image detection,” inICCV, 2023, pp. 22 445– 22 455
2023
-
[22]
Searching for mobilenetv3,
A. Howard, M. Sandler, G. Chu, L.-C. Chen, B. Chen, M. Tan, W. Wang, Y . Zhu, R. Pang, V . Vasudevanet al., “Searching for mobilenetv3,” in ICCV, 2019, pp. 1314–1324
2019
-
[23]
mixup: Beyond Empirical Risk Minimization
H. Zhang, M. Cisse, Y . N. Dauphin, and D. Lopez-Paz, “mixup: Beyond empirical risk minimization,”arXiv preprint arXiv:1710.09412, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[24]
Cutmix: Reg- ularization strategy to train strong classifiers with localizable features,
S. Yun, D. Han, S. J. Oh, S. Chun, J. Choe, and Y . Yoo, “Cutmix: Reg- ularization strategy to train strong classifiers with localizable features,” inICCV, 2019, pp. 6023–6032
2019
-
[25]
Laion- 5b: An open large-scale dataset for training next generation image-text models,
C. Schuhmann, R. Beaumont, R. Vencu, C. Gordon, R. Wightman, M. Cherti, T. Coombes, A. Katta, C. Mullis, M. Wortsmanet al., “Laion- 5b: An open large-scale dataset for training next generation image-text models,”NeurIPS, vol. 35, pp. 25 278–25 294, 2022
2022
-
[26]
Photorealistic text-to-image diffusion models with deep language understanding,
C. Saharia, W. Chan, S. Saxena, L. Li, J. Whang, E. L. Denton, K. Ghasemipour, R. Gontijo Lopes, B. Karagol Ayan, T. Salimans et al., “Photorealistic text-to-image diffusion models with deep language understanding,”NeurIPS, vol. 35, pp. 36 479–36 494, 2022
2022
-
[27]
Zero-shot text-to-image generation,
A. Ramesh, M. Pavlov, G. Goh, S. Gray, C. V oss, A. Radford, M. Chen, and I. Sutskever, “Zero-shot text-to-image generation,” inICML, 2021, pp. 8821–8831
2021
-
[28]
Stylegan-t: Un- locking the power of gans for fast large-scale text-to-image synthesis,
A. Sauer, T. Karras, S. Laine, A. Geiger, and T. Aila, “Stylegan-t: Un- locking the power of gans for fast large-scale text-to-image synthesis,” arXiv preprint arXiv:2301.09515, 2023
-
[29]
Text to image generation with semantic-spatial aware gan,
W. Liao, K. Hu, M. Y . Yang, and B. Rosenhahn, “Text to image generation with semantic-spatial aware gan,” inCVPR, 2022, pp. 18 187– 18 196
2022
-
[30]
eDiff-I: Text-to-Image Diffusion Models with an Ensemble of Expert Denoisers
Y . Balaji, S. Nah, X. Huang, A. Vahdat, J. Song, K. Kreis, M. Aittala, T. Aila, S. Laine, B. Catanzaroet al., “ediffi: Text-to-image diffu- sion models with an ensemble of expert denoisers,”arXiv preprint arXiv:2211.01324, 2022
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[31]
GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models
A. Nichol, P. Dhariwal, A. Ramesh, P. Shyam, P. Mishkin, B. McGrew, I. Sutskever, and M. Chen, “Glide: Towards photorealistic image gen- eration and editing with text-guided diffusion models,”arXiv preprint arXiv:2112.10741, 2021
work page internal anchor Pith review Pith/arXiv arXiv 2021
-
[32]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askellet al., “Learning transferable visual models from natural language supervision,” inICML, 2021, pp. 8748–8763
2021
-
[33]
xformers: A modular and hackable transformer modelling library,
B. Lefaudeux, F. Massa, D. Liskovich, W. Xiong, V . Caggiano, S. Naren, M. Xu, J. Hu, M. Tintore, S. Zhang, P. Labatut, and D. Haziza, “xformers: A modular and hackable transformer modelling library,” https://github.com/facebookresearch/xformers, 2022
2022
-
[34]
Null- text inversion for editing real images using guided diffusion models,
R. Mokady, A. Hertz, K. Aberman, Y . Pritch, and D. Cohen-Or, “Null- text inversion for editing real images using guided diffusion models,” in CVPR, 2023, pp. 6038–6047
2023
-
[35]
Deep residual learning for image recognition,
K. He, X. Zhang, S. Ren, and J. Sun, “Deep residual learning for image recognition,” inCVPR, 2016, pp. 770–778
2016
-
[36]
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gellyet al., “An image is worth 16x16 words: Transformers for image recognition at scale,”arXiv preprint arXiv:2010.11929, 2020
work page internal anchor Pith review Pith/arXiv arXiv 2010
-
[37]
Swin transformer: Hierarchical vision transformer using shifted windows,
Z. Liu, Y . Lin, Y . Cao, H. Hu, Y . Wei, Z. Zhang, S. Lin, and B. Guo, “Swin transformer: Hierarchical vision transformer using shifted windows,” inCVPR, 2021, pp. 10 012–10 022
2021
-
[38]
Imagenet: A large-scale hierarchical image database,
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei, “Imagenet: A large-scale hierarchical image database,” inCVPR, 2009, pp. 248–255
2009
-
[39]
Decoupled Weight Decay Regularization
I. Loshchilov and F. Hutter, “Decoupled weight decay regularization,” arXiv preprint arXiv:1711.05101, 2017
work page internal anchor Pith review Pith/arXiv arXiv 2017
-
[40]
Generalized cross entropy loss for training deep neural networks with noisy labels,
Z. Zhang and M. Sabuncu, “Generalized cross entropy loss for training deep neural networks with noisy labels,”NeurIPS, vol. 31, 2018
2018
-
[41]
Visualizing data using t-sne
L. Van der Maaten and G. Hinton, “Visualizing data using t-sne.”Journal of machine learning research, vol. 9, no. 11, 2008
2008
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.