Low-resource Language Discrimination Towards Chinese Dialects with Transfer learning and Data Augmentation
Pith reviewed 2026-06-26 21:16 UTC · model grok-4.3
The pith
Transfer learning from larger dialect corpora plus targeted data augmentation enables accurate discrimination of low-resource Chinese dialects.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By first training a source-side ASR model on a relatively larger Chinese dialects corpus, augmenting the target-side low-resource data via speed pitch and noise disturbance, fine-tuning a target ASR model on the augmented data with a self-attention mechanism to capture common semantic features, and finally extracting hidden representations from the target model, the CDDTLDA framework achieves significantly higher accuracy on Chinese dialects discrimination than existing approaches.
What carries the argument
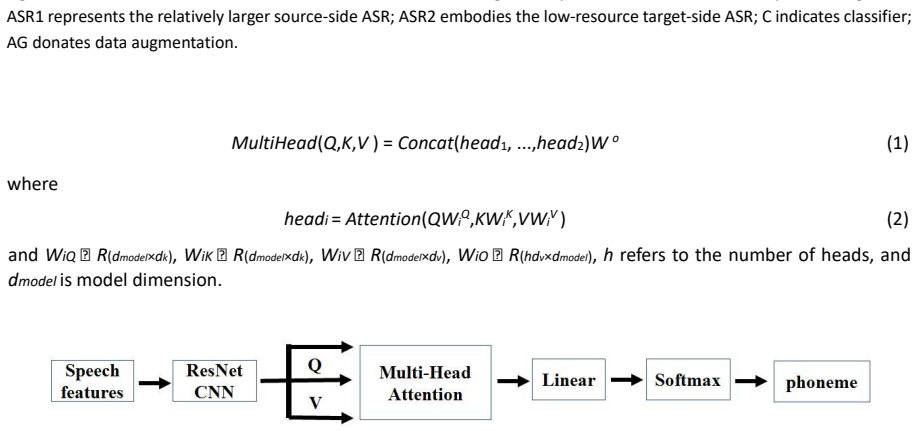
Self-attention mechanism inside the fine-tuned target ASR model that captures common semantic features between source and target models for downstream discrimination.
If this is right
- Dialect discrimination tasks can proceed without large amounts of labeled target data by leveraging a related larger corpus.
- ASR models pretrained on one set of dialects can supply useful representations for discrimination on related low-resource dialects.
- Simple acoustic augmentations (speed, pitch, noise) suffice to make limited target data usable for fine-tuning.
- Hidden-layer representations from the fine-tuned ASR model serve as effective input features for the discrimination classifier.
Where Pith is reading between the lines
- The same transfer-plus-augmentation pattern could be tested on other groups of closely related low-resource languages or dialects.
- If the self-attention step is removed, performance should drop; an ablation study would isolate its contribution.
- The approach may scale to joint modeling of multiple dialect discrimination and recognition tasks within one network.
- Success here suggests that semantic overlap across dialects is large enough to support parameter-efficient adaptation rather than training from scratch.
Load-bearing premise
Common semantic features between the source and target ASR models can be captured by the self-attention mechanism.
What would settle it
Running the same experiments on the two benchmark Chinese dialects corpora and finding that the full CDDTLDA pipeline does not outperform the strongest prior methods would falsify the central claim.
Figures






read the original abstract
Chinese dialects discrimination is a challenging natural language processing task due to scarce annotation resource. In this article, we develop a novel Chinese dialects discrimination framework with transfer learning and data augmentation (CDDTLDA) in order to overcome the shortage of resources. To be more specific, we first use a relatively larger Chinese dialects corpus to train a source-side automatic speech recognition (ASR) model. Then, we adopt a simple but effective data augmentation method (i.e., speed, pitch, and noise disturbance) to augment the target-side low-resource Chinese dialects, and fine-tune another target ASR model based on the previous source-side ASR model. Meanwhile, the potential common semantic features between source-side and target-side ASR models can be captured by using self-attention mechanism. Finally, we extract the hidden semantic representation in the target ASR model to conduct Chinese dialects discrimination. Our extensive experimental results demonstrate that our model significantly outperforms state-of-the-art methods on two benchmark Chinese dialects corpora.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes CDDTLDA, a framework for low-resource Chinese dialects discrimination. It trains a source ASR model on a larger corpus, applies data augmentation (speed, pitch, noise perturbations) to the target low-resource data, fine-tunes a target ASR model, employs self-attention to capture common semantic features between source and target models, and extracts hidden representations from the target model for discrimination. The central empirical claim is that this approach significantly outperforms state-of-the-art methods on two benchmark Chinese dialects corpora.
Significance. If the reported outperformance is substantiated with detailed metrics, baselines, and controls, the work would offer a practical transfer-learning pipeline for dialect discrimination and similar low-resource speech/NLP tasks. The combination of ASR pretraining, targeted augmentation, and attention-based feature sharing aligns with established techniques but applies them to an under-resourced domain.
minor comments (3)
- [Abstract] Abstract: The summary asserts significant outperformance without quoting any concrete metrics, dataset sizes, or baseline names. Adding one or two key numbers (e.g., accuracy deltas and corpus names) would make the abstract self-contained and easier for readers to assess at a glance.
- [Method] The description of the self-attention module and the precise layer from which hidden representations are extracted remains high-level. A short diagram or explicit layer reference would improve reproducibility.
- [Experiments] Ensure the experimental section reports all augmentation parameters (e.g., speed factors, SNR levels), the exact architecture of the ASR models, and statistical significance tests for the claimed improvements.
Simulated Author's Rebuttal
We thank the referee for their constructive review and recommendation of minor revision. The report provides a clear summary of our work and notes its potential value if the empirical claims are well-supported. Since no specific major comments were listed, we have no point-by-point responses to provide at this time.
Circularity Check
No significant circularity; purely empirical framework
full rationale
The paper presents a transfer-learning pipeline for low-resource Chinese dialect discrimination: train source ASR on larger corpus, augment target data via speed/pitch/noise, fine-tune target ASR, apply self-attention to capture shared features, then extract hidden representations for classification. No equations, derivations, uniqueness theorems, or first-principles predictions appear anywhere in the manuscript. The central claim is strictly empirical outperformance on two benchmark corpora and is externally falsifiable via replication on those same corpora. No self-citations are load-bearing, no fitted parameters are renamed as predictions, and no ansatz is smuggled via prior work. The method is a standard supervised transfer setup whose validity does not reduce to its own inputs by construction.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Zhang Biao, Xiong Deyi, Su Jinsong, and Luo Jiebo. 2019. Future-aware knowledge distillation for neural machine translation. IEEE/ACM Transactions on Audio, Speech and Language Processing 27, 12 (2019), 2278–2287
2019
-
[2]
Aggelina Chatziagapi, Georgios Paraskevopoulos, Dimitris Sgouropoulos, Georgios Pantazopoulos, and Shrikanth Narayanan. 2019. Data augmentation using GANs for speech emotion recognition. In Proceedings of the Conference of the International Speech Communication Association (Interspeech), Graz, Austria, September 15-19, 2019
2019
-
[3]
Çağrı Çöltekin and Taraka Rama. 2016. Discriminating similar languages with linear SVMs and neural networks. In Proceedings of the Third Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial), Osaka, Japan, December 12, 2016. 15–24
2016
-
[4]
Wenyuan Dai, Qiang Yang, Gui -Rong Xue, and Yong Yu. 2007. Boosting for transfer learning. In Proceedings of the International Conference on Machine Learning (ICML), Corvallis, Oregon, USA, June 20-24, 2007. 193–200
2007
-
[5]
Davis and Paul Mermelstein
Stan W. Davis and Paul Mermelstein. 1980. Comparison of parametric representations for monosyllabic word recognition in continuously spoken sentences. IEEE Transactions on Acoustics Speech and Signal Processing 28, 4 (1980), 357–366
1980
-
[6]
Torres -Carrasquillo, Douglas A
Najim Dehak, Pedro A. Torres -Carrasquillo, Douglas A. Reynolds, and RÃľda Dehak. 2011. Language recognition via i -vectors and dimensionality reduction. In Proceedings of the Conference of the International Speech Communication Association (Interspeech), Florence, Italy, August 28-31, 2011
2011
-
[7]
Heba Elfardy and Mona Diab. 2013. Sentence level dialect identification in arabic. In Proceedings of the 51st Annual Mee ting of the Association for Computational Linguistics (ACL), Sofia, Bulgaria, August 4-9, 2013. 456–461
2013
-
[8]
Caroline Etienne, Guillaume Fidanza, Andrei Petrovskii, Laurence Devillers, and Benoit Schmauch. 2018. CNN+LSTM architecture for speech emotion recognition with data augmentation. In Proceedings of the Workshop on Speech, Music and Mind 2018
2018
-
[9]
Xu Fan, Wang Mingwen, and Li Maoxi. 2018. Building parallel monolingual Gan chinese dialects corpus. In Proceedings of the Eleventh International Conference on Lang uage Resources and Evaluation (LREC), Miyazaki, Japan, May 7 -12, 2018 . European Language Resources Association ( ELRA )
2018
-
[10]
Helena GÃşmez-Adorno, Ilia Markov, Jorge Baptista, Grigori Sidorov, and David Pinto. 2017. Discriminating between similar languages using a combination of typed and untyped character n -grams and words. In Proceedings of the 4th Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial), Valencia, Spain, April 3, 2017. 137–145
2017
-
[11]
Cyril Goutte, Serge LÃľger, and Marine Carpuat. 2014. The NRC system for discriminating similar languages. In Proceedings of the First Workshop on Applying NLP Tools to Similar Languages, Varieties and Dialects, Dublin, Ireland, August 23, 2014. 139–145
2014
-
[12]
Greg Grefenstette. 1995. Comparing two language id entification schemes. In Proceedings of the 3rd International Conference on Statistical Analysis of Textual Data, Rome, December 11-13, 1995
1995
-
[13]
IFLYTEK. 2018. IFLYTEK world-wide contest for dialect discrimination: a baseline system. http://challenge.xfyun.cn/2018/aicompetition/ tech#tr_3.. (2018)
2018
-
[14]
IFLYTEK. 2018. Ranking list of IFLYTEK world-wide contest for dialect discrimination. http://challenge.xfyun.cn/2018/aicompetition/tech.. (2018)
2018
-
[15]
Tommi Jauhiainen, Marco Lui, Marcos Zampieri, Timothy Baldwin, and Krister LindÃľn. 2018. Automatic language identification in texts: a Survey. Journal of Artificial Intelligence Research 65 (2018)
2018
-
[16]
Ye Jia, Yu Zhang, Ron Weiss, Quan Wang, Jonathan Shen, Fei Ren, Zhifeng Chen, Patrick Nguyen, Ruoming Pang, Ignacio Moreno, a nd Yonghui Wu. 2018. Transfer learning from speaker verification to multispeaker text -to-speech synthesis. In Proceedings of the 32 nd International Conference on Neural Information Processing Systems (NIPS), Montreal, Canada, Dec...
2018
-
[17]
Zeng Jiali, Su Jinsong, Wen Huating, Liu Yang, Xie Jun, Yin Yongjing, and Zhao Jianqiang. 2018. Multi-domain neural machine translation with word-level domain context discrimination. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP) 2018, Brussels, Belgium, October 31âĂŞNovember 4, 2018. 447–457
2018
-
[18]
Zeng Jiali, Liu Yang, Su Jinsong, Ge Yubing, Lu Yaojie, Yin Yongjing, and Luo Jiebo. 2019. Iterative dual domain adaptation f or neural machine translation. In Proceedings of the 2019 Conferen ce on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Brussels, Belgium, ...
2019
-
[19]
Su Jinsong, Zeng Jiali, Xie Jun, Wen Huating, Yin Yongjing, and Liu Yang. 2019. Exploring discriminative word-level domain contexts for multi-domain neural machine translation. IEEE Transactions on Pattern Analysis and Machine Intelligence 43, 5 (2019), 1530–1545
2019
-
[20]
Dietrich Klakow and Jochen Peters. 2002. Testing the correlation of word error rate and perplexity. Speech Communication 38, 1/2 (2002) , 19–28
2002
-
[21]
Shervin Malmasi and Mark Dras. 2015. Automatic language identification for persian and dari texts. In Proceedings of the Pacific Association for Computational Linguistics. 53–58
2015
-
[22]
Bharadwaja Kumar
Kavi Narayana Murthy and G. Bharadwaja Kumar . 2006. Language identification from small text samples. Journal of Quantitative Linguistics 13, 1 (2006), 57–80
2006
-
[23]
Nikola, Ljubesic, Denis, and Kranjcic. 2015. Discriminating between closely related languages on twitter . Informatica: An International Journal of Computing and Informatics (2015), 1 – 8
2015
-
[24]
Pan, Sinno, and Jialin. 2010. A survey on transfer learning. IEEE Transactions on Knowledge and Data Engineering 22 (2010), 1345–1359
2010
-
[25]
Sinno Jialin Pan, Ivor W Tsang, James Kwok, and Qiang Yang. 2011. Domain Adaptation via Transfer Component Analysis. 22, 2 (2011) , 199–210
2011
-
[26]
Park, William Chan, Yu Zhang, Chung Cheng Chiu, Barret Zoph , Ekin D
Daniel S. Park, William Chan, Yu Zhang, Chung Cheng Chiu, Barret Zoph , Ekin D. Cubuk, and Quoc V. Le. 2019. SpecAugment: a simple data augmentation method for automatic speech recognition. (2019), 2613–2617
2019
-
[27]
Yi Ren, Xu Tan, Tao Qin, Sheng Zhao, and Tie Yan Liu. 2019. Almost unsupervised text to speech and automatic speech recognition. (2019)
2019
-
[28]
Khoshgoftaar
Connor Shorten and Taghi M. Khoshgoftaar . 2019. A survey on image data augmentation for deep learning. Journal of Big Data 6, 1 (2019)
2019
-
[29]
Alberto SimÃţes, JosÃľ Almeida, and S.D. Byers. 2014. Language identification: a neural network approach. 38 (01 2014), 251–265. https://doi.org/10.4230/OASIcs.SLATE.2014.251
-
[30]
David Snyder, Daniel Garcia-Romero, Alan Mccree, Gregory Sell, and Sanjeev Khudanpur . 2018. Spoken language recognition using x- vectors. In Odyssey 2018 The Speaker and Language Recognition Workshop
2018
-
[31]
JÃűrg Tiedemann and Nikola Ljubevsi ’C. 2012. Efficient discrimination be tween closely related languages. In Proceedings of the International Conference on Computational Linguistics (COLING), Mumbai, India, December 8-15, 2012
2012
-
[32]
Yuxuan Wang, Daisy Stanton, Yu Zhang, Rj Skerry-Ryan, Eric Battenberg, Joel Shor, Ying Xiao, Fei Ren, Ye Jia, and Rif A Saurous. 2018. Style tokens: unsupervised style modeling, control and transfer in end-to-end speech synthesis. In Proceedings of the 35 th International Conference on Machine Learning (ICML), Stockholm, Sweden, PMLR 80, 2018
2018
-
[33]
Nianheng Wu, Eric Demattos, Kwok Him So, Pin Zhen Chen, and Ar Ltekin. 2019. Language discrimination and transfer learning for similar languages: experiments with feature combinations and adaptation. In Proceedings of the Sixth Workshop on NLP for Similar Languages, Varieties and Dialects (VarDial), Minneapolis, MN, June 7, 2019. 54–63
2019
-
[34]
Fan Xu, Jian Luo, Mingwen Wang, and Guodong Zhou. 2020. Speech-driven end-to-end language discrimination toward chinese dialects. ACM Transactions on Asian and Low-Resource Language Information Processing 19, 5 (2020), 1–24
2020
-
[35]
Fan Xu, Xiongfei Xu, Mingwen Wang, and Maoxi Li. 2015. Building monolingual word alignment corpus for the greater china region. In Proceedings of the Joint Workshop on Language Technology for Closely Related Languag es, Varieties and Dialects . Association for Computational Linguistics, Hissar, Bulgaria, 85–94
2015
-
[36]
Marcos Zampieri, Shervin Malmasi, Nikola Ljubei Ljubeic, Preslav Nakov, and Nomi Aepli. 2017. Findings of the vardial evaluat ion campaign 2017. In Proceedings of the Fourth Workshop on NLP for Similar Languages, Varieties and Dialects, Valencia, Spain, April 3,
2017
-
[37]
Marcos Zampieri, Shervin Malmasi, Yves Scherrer, Tanja Samardžić, Francis Tyers, Miikka Silfverberg, Natalia Klyueva, Tung-Le Pan, Chu- Ren Huang, Radu Tudor Ionescu, Andrei M. Butnaru, and Tommi Jauhiainen. 2019. A report on the third vardial evaluation campaign. In Proceedings of the Sixth Workshop on NLP for Similar Languages, Varieties and Dialects. A...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.