PersonalPlan: Planning Multi-Agent Systems for Personalized Programming Learning
Pith reviewed 2026-06-26 18:58 UTC · model grok-4.3
The pith
PersonalPlan uses two-stage training on a new dataset to let 8B and 32B models generate superior personalized programming learning plans for multi-agent systems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
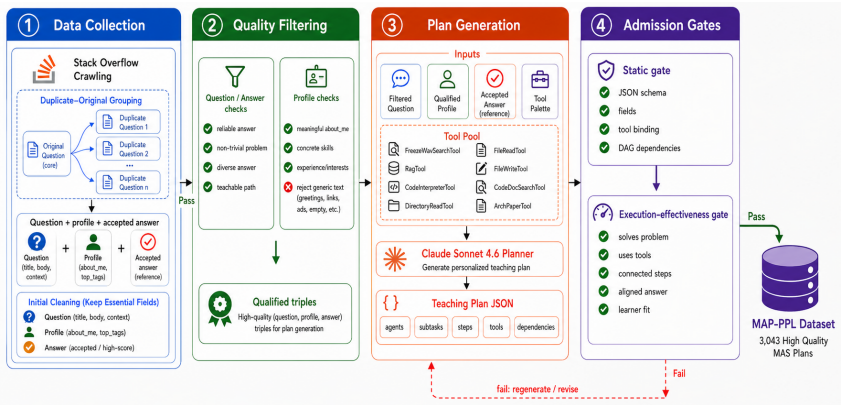
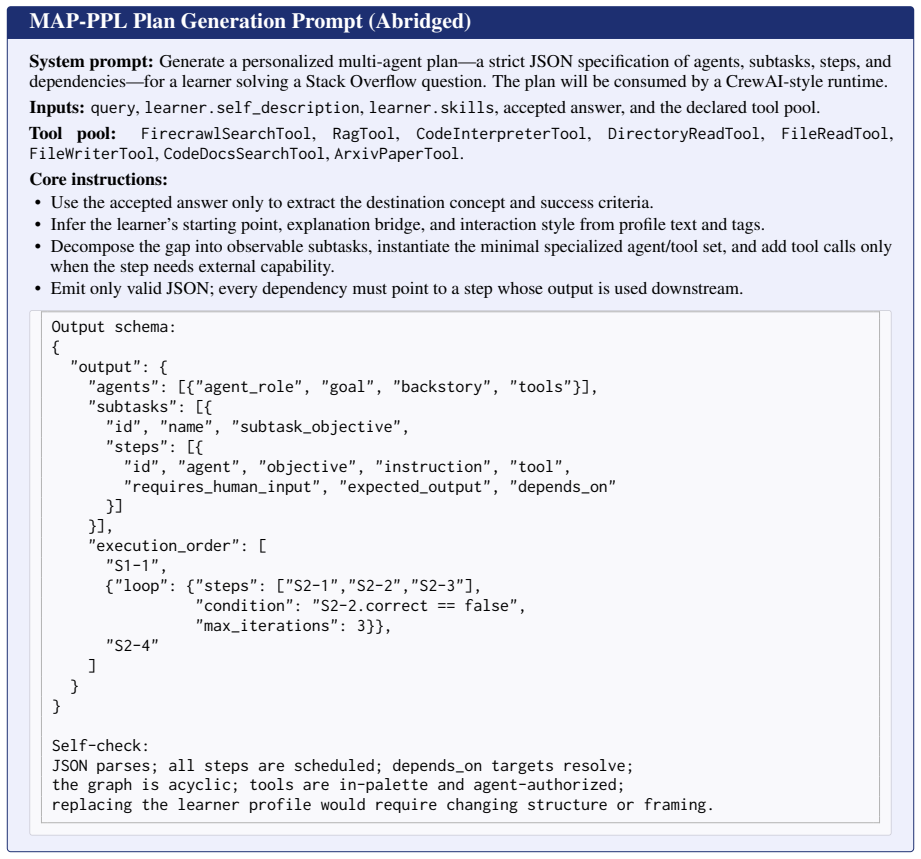
PersonalPlan is a two-stage MAS planner that first performs hierarchical SFT with separate LoRA adapters for profile-aware task decomposition and step dependency planning, then applies Reward-Adaptive GRPO to encourage generation of executable, personalized, and pedagogically scaffolded plans; on the MAP-PPL dataset these 8B and 32B variants achieve state-of-the-art results in plan executability, personalization, and pedagogical quality compared with frontier LLMs, generic MAS frameworks, and other agentic planners.
What carries the argument
The two-stage training process that combines hierarchical supervised fine-tuning with Reward-Adaptive GRPO to produce profile-conditioned plans specifying agents, subtasks, executable steps, and prerequisite dependencies.
If this is right
- Multi-agent systems can be orchestrated to deliver instruction that adapts to individual learner profiles rather than using generic plans.
- Smaller-parameter models become viable for high-quality planning tasks that previously required larger frontier systems.
- Explicit modeling of prerequisite dependencies supports more structured and scaffolded learning paths.
- The separation of profile-aware decomposition and dependency planning allows targeted optimization for different aspects of plan quality.
Where Pith is reading between the lines
- Similar dataset construction and two-stage training could be applied to personalized planning in other skill domains such as mathematics or language learning.
- The method may lower the compute barrier for deploying adaptive educational agents by relying on 8B-scale models.
- Success here suggests that reward-adaptive reinforcement learning can be tuned to balance multiple objectives like executability and pedagogical fit without hand-crafted heuristics.
- If the plans transfer to live tutoring sessions, they could reduce the need for constant human oversight in multi-agent learning environments.
Load-bearing premise
The MAP-PPL dataset built from Stack Overflow question groups and learner profiles supplies a representative basis for training plans that will work in actual personalized programming learning.
What would settle it
A real-world trial in which students follow PersonalPlan-generated sequences versus baseline plans and show no measurable gains in task completion rates or learning progress.
Figures






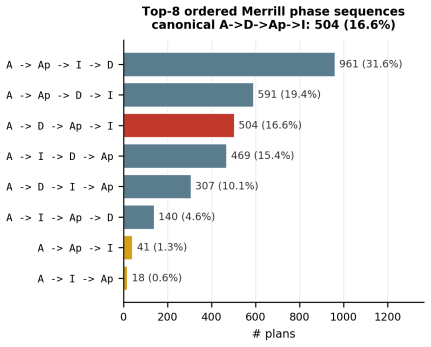
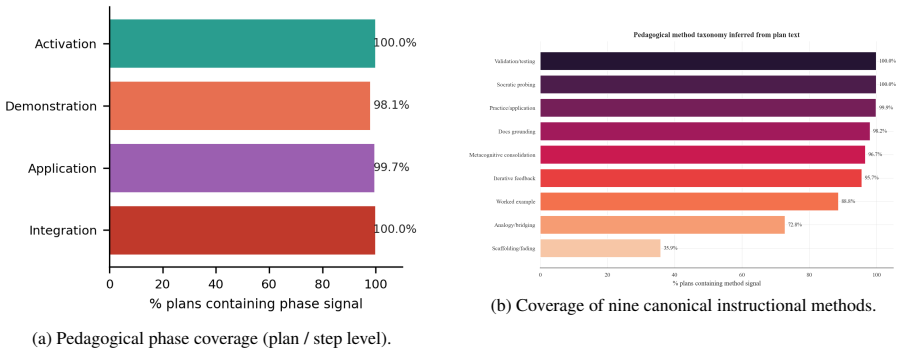







read the original abstract
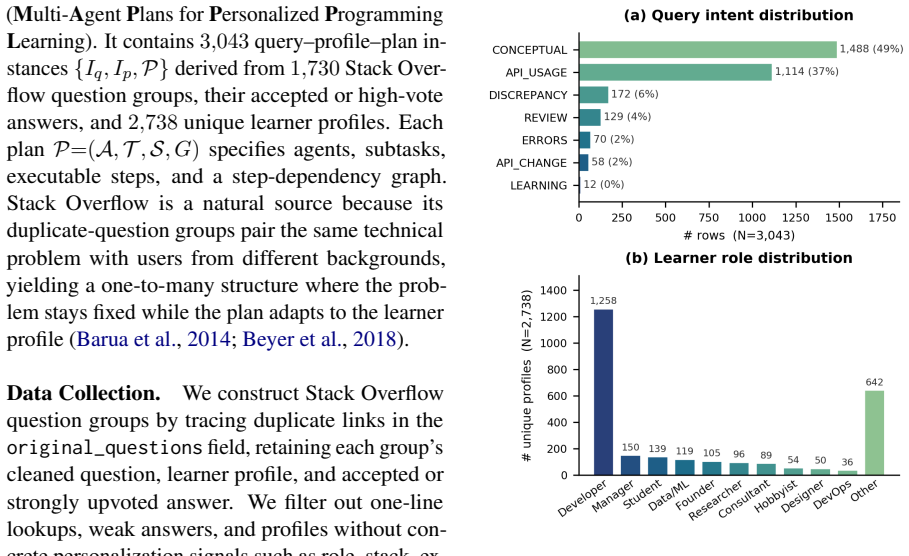
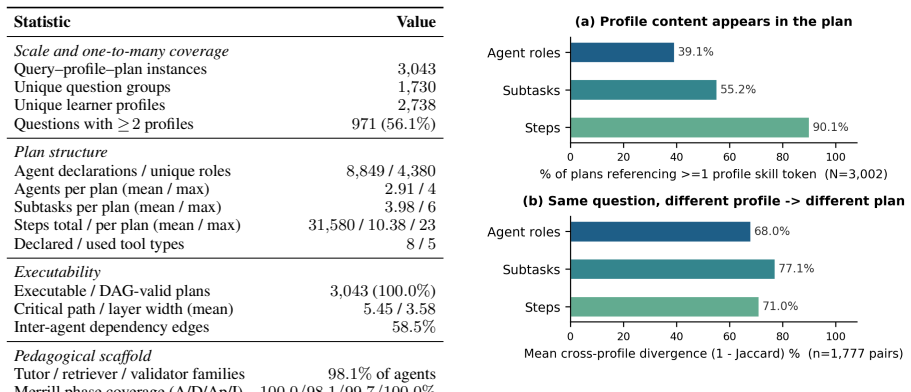
Effective programming education requires personalized instruction adapted to diverse learner backgrounds. However, while LLM-based multi-agent systems (MAS) excel at complex planning, existing planners often lack profile-grounding and pedagogical scaffolding, thereby undermining personalized programming learning. To fill in the gap, we first introduce \textbf{MAP-PPL} (\textbf{M}ulti-\textbf{A}gent \textbf{P}lans for \textbf{P}ersonalized \textbf{P}rogramming \textbf{L}earning), a profile-conditioned multi-agent planning dataset with 3{,}043 query--profile--plan instances from 1{,}730 Stack Overflow question groups and 2{,}738 learner profiles. Each plan specifies agents, subtasks, executable steps, and prerequisite dependencies. Then, we propose \textbf{PersonalPlan}, a two-stage MAS planner that first performs hierarchical SFT with separate LoRA adapters for profile-aware task decomposition and step dependency planning, then applies a Reward-Adaptive GRPO to encourage the model to generate executable, personalized, and pedagogically scaffolded plans. Extensive experiments on MAP-PPL comparing PersonalPlan against frontier LLMs, generic MAS frameworks, and agentic planners demonstrate its superiority. With only 8B and 32B variants, PersonalPlan achieves state-of-the-art plan executability, personalization, and pedagogical quality, effectively orchestrating MAS for agent-student interactions.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the MAP-PPL dataset containing 3,043 query-profile-plan instances derived from 1,730 Stack Overflow question groups and 2,738 learner profiles. It proposes PersonalPlan, a two-stage MAS planner that performs hierarchical SFT with separate LoRA adapters for profile-aware task decomposition and step dependency planning, followed by Reward-Adaptive GRPO. Experiments on MAP-PPL report state-of-the-art results in plan executability, personalization, and pedagogical quality for the 8B and 32B variants relative to frontier LLMs, generic MAS frameworks, and other agentic planners.
Significance. If the internal benchmark results prove robust and the automated metrics are shown to correlate with real learner outcomes, the work could advance profile-conditioned planning methods for educational multi-agent systems. The creation of a dedicated dataset and the two-stage training approach constitute concrete contributions to LLM-based planners.
major comments (2)
- [Abstract and Experiments] Abstract and Experiments section: All reported gains in executability, personalization, and pedagogical quality are measured exclusively inside the MAP-PPL dataset; no external learner-outcome validation, human tutoring studies, pre/post learning gains, or correlation between the paper's metrics and actual student performance is provided. This is load-bearing for the headline claim that PersonalPlan effectively orchestrates MAS for agent-student interactions.
- [Dataset] Dataset construction: The assumption that the 3,043 instances from 1,730 SO question groups and 2,738 learner profiles provide a representative and high-quality basis for training and evaluating plans that generalize to real personalized programming learning scenarios is not supported by details on how learner profiles were generated, validated for realism, or checked for coverage of diverse backgrounds.
minor comments (1)
- [Abstract] Abstract: The summary of experimental results mentions superiority but does not list the concrete metrics, exact baselines, or number of runs, which reduces clarity for readers.
Simulated Author's Rebuttal
We thank the referee for the constructive comments on our manuscript. We address each major comment point by point below, indicating where revisions will be incorporated.
read point-by-point responses
-
Referee: [Abstract and Experiments] Abstract and Experiments section: All reported gains in executability, personalization, and pedagogical quality are measured exclusively inside the MAP-PPL dataset; no external learner-outcome validation, human tutoring studies, pre/post learning gains, or correlation between the paper's metrics and actual student performance is provided. This is load-bearing for the headline claim that PersonalPlan effectively orchestrates MAS for agent-student interactions.
Authors: We acknowledge that all quantitative results are obtained on the newly introduced MAP-PPL benchmark using automated metrics for executability (verified via execution traces), personalization (profile-feature alignment), and pedagogical quality (scaffolding rubric scores). These metrics were chosen because they directly operationalize the planning objectives, yet we agree that external validation against real learner outcomes is absent. In the revised version we will (i) qualify the abstract and conclusion claims to state that superiority is demonstrated on MAP-PPL, and (ii) add an explicit limitations paragraph noting the lack of human studies and the desirability of future correlation analyses. This is a partial revision; the internal benchmark results and training methodology remain unchanged. revision: partial
-
Referee: [Dataset] Dataset construction: The assumption that the 3,043 instances from 1,730 SO question groups and 2,738 learner profiles provide a representative and high-quality basis for training and evaluating plans that generalize to real personalized programming learning scenarios is not supported by details on how learner profiles were generated, validated for realism, or checked for coverage of diverse backgrounds.
Authors: The current dataset section outlines the provenance from Stack Overflow question groups and the creation of 2,738 learner profiles, but we accept that additional procedural details are warranted. In the revision we will expand the dataset construction subsection to include: (a) the exact procedure used to synthesize profiles from common learner archetypes, (b) the diversity criteria applied (experience level, target language, prior knowledge indicators), and (c) any internal consistency checks performed. These additions will be factual expansions rather than new experiments. revision: yes
Circularity Check
No significant circularity; standard training and evaluation on author-constructed benchmark
full rationale
The paper constructs the MAP-PPL dataset from external sources (1,730 Stack Overflow question groups and 2,738 learner profiles) and applies standard hierarchical SFT with LoRA adapters plus a Reward-Adaptive GRPO variant to train PersonalPlan. All reported results are empirical comparisons of executability, personalization, and pedagogical quality on this benchmark against frontier LLMs and other planners. No derivation step reduces by construction to its inputs, no fitted parameters are relabeled as predictions, and no load-bearing claims rely on self-citations or imported uniqueness theorems. The approach is self-contained as a new dataset plus supervised training pipeline without self-referential definitions.
Axiom & Free-Parameter Ledger
free parameters (2)
- Separate LoRA adapters
- Reward function in GRPO
axioms (1)
- domain assumption Constructed dataset instances accurately reflect real learner needs and valid plans
Reference graph
Works this paper leans on
-
[1]
Communications of the ACM , volume=
Computing Education in the Era of Generative AI , author=. Communications of the ACM , volume=. 2024 , doi=
2024
-
[2]
arXiv preprint arXiv:2505.10922 , year=
Vaiage: A Multi-Agent Solution to Personalized Travel Planning , author=. arXiv preprint arXiv:2505.10922 , year=
-
[3]
IEEE Transactions on Learning Technologies , year=
Eduplanner: Llm-based multi-agent systems for customized and intelligent instructional design , author=. IEEE Transactions on Learning Technologies , year=
-
[4]
arXiv preprint arXiv:2504.04220 , year=
AdaCoder: An Adaptive Planning and Multi-Agent Framework for Function-Level Code Generation , author=. arXiv preprint arXiv:2504.04220 , year=
-
[5]
NeurIPS , year=
Deep Knowledge Tracing , author=. NeurIPS , year=
-
[6]
GPT-4 Technical Report , author=. arXiv preprint arXiv:2303.08774 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[7]
Tree of Thoughts: Deliberate Problem Solving with Large Language Models
Tree of Thoughts: Deliberate Problem Solving with Large Language Models , author=. arXiv preprint arXiv:2305.10601 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Reflexion: Language Agents with Verbal Reinforcement Learning
Reflexion: Language Agents with Verbal Reinforcement Learning , author=. arXiv preprint arXiv:2303.11366 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[9]
Behavior Research Methods, Instruments, & Computers , volume=
AutoTutor: A tutor with dialogue in natural language , author=. Behavior Research Methods, Instruments, & Computers , volume=. 2004 , publisher=
2004
-
[10]
Sparks of Artificial General Intelligence: Early experiments with GPT-4
CAMEL: Communicative Agents for "Mind" Exploration of Large Language Model Society , author=. arXiv preprint arXiv:2303.12712 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[11]
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversation Framework , author=. arXiv preprint arXiv:2308.08155 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[12]
2013 35th International Conference on Software Engineering (ICSE) , pages=
Seahawk: Stack overflow in the ide , author=. 2013 35th International Conference on Software Engineering (ICSE) , pages=. 2013 , organization=
2013
-
[13]
Empirical software engineering , volume=
What are developers talking about? an analysis of topics and trends in stack overflow , author=. Empirical software engineering , volume=. 2014 , publisher=
2014
-
[14]
, author=
Lora: Low-rank adaptation of large language models. , author=. ICLR , volume=
-
[15]
The Twelfth International Conference on Learning Representations (ICLR) , year=
MetaGPT: Meta Programming for A Multi-Agent Collaborative Framework , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[16]
Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
ChatDev: Communicative Agents for Software Development , author=. Proceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (ACL) , year=
-
[17]
The Twelfth International Conference on Learning Representations (ICLR) , year=
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors , author=. The Twelfth International Conference on Learning Representations (ICLR) , year=
-
[18]
Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI) , year=
AutoAgents: A Framework for Automatic Agent Generation , author=. Proceedings of the Thirty-Third International Joint Conference on Artificial Intelligence (IJCAI) , year=
-
[19]
Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI) , year=
CodeAid: Evaluating a Classroom Deployment of an LLM-based Programming Assistant that Balances Student and Educator Needs , author=. Proceedings of the CHI Conference on Human Factors in Computing Systems (CHI) , year=
-
[20]
Proceedings of the 23rd Koli Calling International Conference on Computing Education Research , year=
CodeHelp: Using Large Language Models with Guardrails for Scalable Support in Programming Classes , author=. Proceedings of the 23rd Koli Calling International Conference on Computing Education Research , year=
-
[21]
Advances in Neural Information Processing Systems (NeurIPS) , year=
PersonaAgent: When Large Language Model Agents Meet Personalization at Test Time , author=. Advances in Neural Information Processing Systems (NeurIPS) , year=
-
[22]
2025 , howpublished=
2025
-
[23]
2026 , howpublished=
2026
-
[24]
Yang, An and others , journal=
-
[25]
Shao, Zhihong and Wang, Peiyi and Zhu, Qihao and Xu, Runxin and Song, Junxiao and Zhang, Mingchuan and Li, Y. K. and Wu, Yu and Guo, Daya , journal=
-
[26]
and Gonzalez, Joseph E
Zheng, Lianmin and Chiang, Wei-Lin and Sheng, Ying and Zhuang, Siyuan and Wu, Zhanghao and Zhuang, Yonghao and Lin, Zi and Li, Zhuohan and Xing, Eric P. and Gonzalez, Joseph E. and Stoica, Ion and Zhang, Hao , booktitle=. Judging
-
[27]
Scaling Laws for Reward Model Overoptimization
Scaling Laws for Reward Model Overoptimization , author=. arXiv preprint arXiv:2210.10760 , year=
work page internal anchor Pith review Pith/arXiv arXiv
-
[28]
and Hajishirzi, Hannaneh , journal=
Lambert, Nathan and Pyatkin, Valentina and Morrison, Jacob and Miranda, LJ and Lin, Bill Yuchen and Chandu, Khyathi and Dziri, Nouha and Kumar, Sachin and Zick, Tom and Choi, Yejin and Smith, Noah A. and Hajishirzi, Hannaneh , journal=
-
[29]
Huang, Anonymous and others , journal=
-
[30]
and Keutzer, Kurt and Gholami, Amir , journal=
Kim, Sehoon and Moon, Suhong and Tabrizi, Ryan and Lee, Nicholas and Mahoney, Michael W. and Keutzer, Kurt and Gholami, Amir , journal=. An
-
[31]
Wei, Anonymous , journal=. Beyond
-
[32]
Expert Systems with Applications , volume=
Learning Path Personalization and Recommendation Methods: A Survey of the State-of-the-Art , author=. Expert Systems with Applications , volume=
-
[33]
Computers & Education , volume=
Intelligent Web-Based Learning System with Personalized Learning Path Guidance , author=. Computers & Education , volume=
-
[34]
Data-Driven Personalized Learning Path Planning Based on Cognitive Diagnostic Assessments in
Jiang, Bing and Li, Xinyi and Yang, Shengyingjie and Kong, Yiyao and Cheng, Wenlong and Hao, Chenchen and Lin, Qiyun , booktitle=. Data-Driven Personalized Learning Path Planning Based on Cognitive Diagnostic Assessments in
-
[35]
Automatically Classifying Posts into Question Categories on
Beyer, Stefanie and Macho, Christian and Pinzger, Martin and Di Penta, Massimiliano , booktitle=. Automatically Classifying Posts into Question Categories on
-
[36]
2025 , note=
Zhu, Anonymous and others , booktitle=. 2025 , note=
2025
-
[37]
Yin, Da and Brahman, Faeze and Ravichander, Abhilasha and Chandu, Khyathi and Chang, Kai-Wei and Choi, Yejin and Lin, Bill Yuchen , booktitle=. Agent. 2024 , note=
2024
-
[38]
and Keutzer, Kurt and Gholami, Amir , booktitle=
Erdogan, Lutfi Eren and Lee, Nicholas and Kim, Sehoon and Moon, Suhong and Furuta, Hiroki and Kwon, Gopala and Wawrzynski, Pawel and Mahoney, Michael W. and Keutzer, Kurt and Gholami, Amir , booktitle=. 2025 , note=
2025
-
[39]
International Conference on Learning Representations (ICLR) , year=
On-Policy Distillation of Language Models: Learning from Self-Generated Mistakes , author=. International Conference on Learning Representations (ICLR) , year=
-
[40]
Shen, Weizhou and Li, Chenliang and Chen, Hongzhan and Yan, Ming and Quan, Xiaojun and Chen, Hehong and Zhang, Ji and Huang, Fei , booktitle=. Small
-
[41]
Tian, Chunhao and Wang, Yutong and Liu, Xuebo and Wang, Zhexuan and Ding, Liang and Zhang, Miao and Zhang, Min , booktitle=
-
[42]
and Dehlan, Om and Mausam and Gupta, Manish , booktitle=
Karthikeyan, T. and Dehlan, Om and Mausam and Gupta, Manish , booktitle=
-
[43]
Zhao, Qi and Fu, Haotian and Sun, Chen and Konidaris, George , booktitle=
-
[44]
Song, Yifan and Xiong, Weimin and Zhao, Xiutian and Zhu, Dawei and Wu, Wenhao and Wang, Ke and Li, Cheng and Peng, Wei and Li, Sujian , booktitle=
-
[45]
Xiong, Weimin and Song, Yifan and Dong, Qingxiu and Zhao, Bingchan and Song, Feifan and Wang, Xun and Li, Sujian , booktitle=
-
[46]
Xi, Zhiheng and Ding, Yiwen and Chen, Wenxiang and Hong, Boyang and Guo, Honglin and Wang, Junzhe and Guo, Xin and Yang, Dingwen and Liao, Chenyang and He, Wei and Gao, Songyang and Chen, Lu and Zheng, Rui and Zou, Yicheng and Gui, Tao and Zhang, Qi and Qiu, Xipeng and Huang, Xuanjing and Wu, Zuxuan and Jiang, Yu-Gang , booktitle=
-
[47]
Wei, Zhepei and Yao, Wenlin and Liu, Yao and Zhang, Weizhi and Lu, Qin and Qiu, Liang and Yu, Changlong and Xu, Puyang and Zhang, Chao and Yin, Bing and Yun, Hyokun and Li, Lihong , booktitle=
-
[48]
Parmar, Mihir and Goyal, Palash and Liu, Xin and Song, Yiwen and Ling, Mingyang and Baral, Chitta and Palangi, Hamid and Pfister, Tomas , booktitle=
-
[49]
Instruct, Not Assist:
Kargupta, Priyanka and Agarwal, Ishika and Hakkani-Tur, Dilek and Han, Jiawei , booktitle=. Instruct, Not Assist:
-
[50]
, booktitle=
Sonkar, Shashank and Liu, Naiming and Baraniuk, Richard G. , booktitle=. Student Data Paradox and Curious Case of Single Student-Tutor Model: Regressive Side Effects of Training
-
[51]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
Personality-aware Student Simulation for Conversational Intelligent Tutoring Systems , author=. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing (EMNLP) , year=
2024
-
[52]
Peng, Xian and Yuan, Pan and Li, Dong and Cheng, Junlong and Fang, Qin and Liu, Zhi , booktitle=
-
[53]
From Problem-Solving to Teaching Problem-Solving: Aligning
Dinucu-Jianu, David and Macina, Jakub and Daheim, Nico and Hakimi, Ido and Gurevych, Iryna and Sachan, Mrinmaya , booktitle=. From Problem-Solving to Teaching Problem-Solving: Aligning
-
[54]
Liu, Yang and Iter, Dan and Xu, Yichong and Wang, Shuohang and Xu, Ruochen and Zhu, Chenguang , booktitle=
-
[55]
Li, Zheng and Tian, Bowen and Yang, Junnan and Lu, Yating and Zhou, Pengfei and Chen, Yi , journal=
-
[56]
Wang, Yifei and Ji, Cha and Wang, Mengmeng and Liu, Yiding and Wang, Yuhong , booktitle=
-
[57]
Kim, Hannah and Mitra, Kushan and Shen, Chen and Zhang, Dan and Hruschka, Estevam , booktitle=
-
[58]
Zhang, Jiayi and Xiang, Jinyu and Yu, Zhaoyang and Teng, Fengwei and Chen, Xionghui and Chen, Jiaqi and Zhuge, Mingchen and Cheng, Xin and Hong, Sirui and Wang, Jinlin and others , booktitle=
-
[59]
Proceedings of the International Conference on Learning Representations (ICLR) , year=
Benchmarking Agentic Workflow Generation , author=. Proceedings of the International Conference on Learning Representations (ICLR) , year=
-
[60]
2025 , doi=
Zhao, Jianing and Gao, Peng and Cao, Jiannong and Wen, Zhiyuan and Chen, Chen and Yin, Jianing and Yang, Ruosong and Yuan, Bo , journal=. 2025 , doi=
2025
-
[61]
David, Jones and Ghosh, Shreya , booktitle=. 2026 , publisher=. doi:10.18653/v1/2026.eacl-demo.10 , url=
-
[62]
TechTrends , volume=
From Programming to Prompting: Developing Computational Thinking through Large Language Model-Based Generative Artificial Intelligence , author=. TechTrends , volume=. 2025 , publisher=
2025
-
[63]
and Duncan, Ravit Golan and Chinn, Clark A
Hmelo-Silver, Cindy E. and Duncan, Ravit Golan and Chinn, Clark A. , journal=. Scaffolding and Achievement in Problem-Based and Inquiry Learning: A Response to. 2007 , publisher=
2007
-
[64]
Educational Technology Research and Development , volume=
First principles of instruction , author=. Educational Technology Research and Development , volume=. 2002 , publisher=
2002
-
[65]
Teaching computer programming with
Sentance, Sue and Waite, Jane and Kallia, Maria , journal=. Teaching computer programming with. 2019 , publisher=
2019
-
[66]
Advances in Neural Information Processing Systems , volume=
Scheduled Sampling for Sequence Prediction with Recurrent Neural Networks , author=. Advances in Neural Information Processing Systems , volume=
-
[67]
International Conference on Learning Representations , year=
Sequence Level Training with Recurrent Neural Networks , author=. International Conference on Learning Representations , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.