Moving Beyond Diversity: Visual Token Pruning as Subspace Reconstruction for Efficient VLMs
Pith reviewed 2026-06-26 21:39 UTC · model grok-4.3
The pith
SPARE prunes up to 94% of visual tokens in VLMs by minimizing subspace reconstruction error instead of maximizing cosine diversity, retaining 95% performance without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
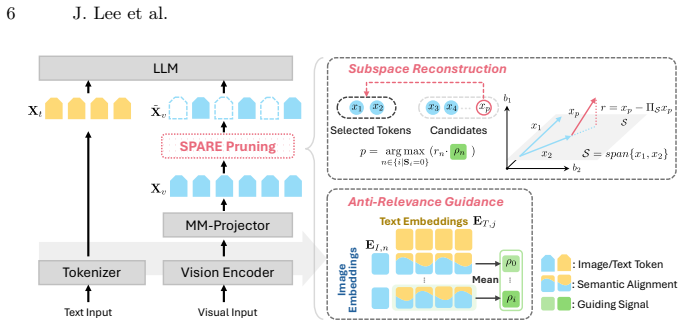
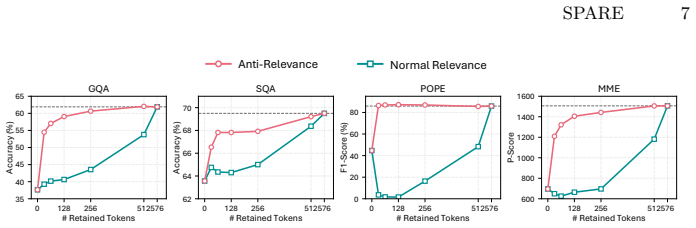
SPARE reformulates visual token pruning as a column subset selection problem that explicitly minimizes reconstruction error by iteratively selecting tokens with the largest projection residuals in the feature subspace; it further shows that tokens with lower image-text relevance scores improve context preservation when added as a selection criterion.
What carries the argument
Column subset selection solved by greedy iterative residual projection, augmented by an anti-relevance score that down-weights tokens strongly aligned with the text prompt.
If this is right
- SPARE achieves state-of-the-art token-reduction results on multiple VLMs and benchmarks with particular gains on compositional tasks.
- It removes up to 94% of visual tokens while keeping 95% of baseline performance on LLaVA.
- The entire procedure runs without any additional training or fine-tuning.
- The anti-relevance criterion improves context-aware selection beyond pure reconstruction.
Where Pith is reading between the lines
- The residual-based selection rule could be tested on other feature-reduction problems such as audio token pruning or long-context language models.
- The finding that low-relevance tokens aid context might motivate re-examination of relevance filtering in retrieval-augmented generation.
- Direct measurement of reconstruction error on held-out visual features could serve as a cheap proxy for expected downstream accuracy.
Load-bearing premise
That minimizing the reconstruction error of the visual feature matrix from the selected tokens will preserve the information required for downstream VLM task performance better than cosine-based diversity selection.
What would settle it
A controlled experiment in which cosine-similarity diversity pruning retains equal or higher accuracy than SPARE on the same compositional multi-skill reasoning benchmarks, or in which the measured reconstruction error after pruning fails to predict the observed task scores.
Figures




read the original abstract
Despite their remarkable performance, Vision Language Models (VLMs) incur substantial computational overhead due to the large number of visual tokens. While diversity maximization has become a dominant strategy for token reduction, existing methods rely on cosine-based normalized similarity that discards magnitude information, failing to faithfully approximate the original feature representation and leading to suboptimal performance, particularly on compositional multi-skill reasoning tasks. In this paper, we introduce SPARE, a subspace reconstruction method that reformulates token pruning as a column subset selection problem and explicitly minimizes reconstruction error. By iteratively selecting tokens with large projection residuals, SPARE performs reconstruction-driven pruning beyond angular diversity. Moreover, we reveal a counterintuitive anti-relevance phenomenon: tokens with lower image-text relevance score can better preserve contextual information. Based on this finding, we incorporate anti-relevance into SPARE as an additional selection criterion to promote context-aware token selection. Extensive experiments across multiple VLMs and benchmarks demonstrate that SPARE consistently achieves state-of-the-art performance, with strong gains on compositional tasks. When applied to LLaVA, SPARE removes up to 94% of visual tokens while retaining 95% of the baseline performance, all in a fully training-free manner.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SPARE, a training-free visual token pruning method for VLMs that reformulates the task as a column subset selection problem in feature subspace reconstruction. It argues that cosine-based diversity maximization discards magnitude information and is suboptimal for compositional tasks; instead, SPARE iteratively selects tokens with large projection residuals to minimize reconstruction error. The paper also reports a counterintuitive anti-relevance phenomenon (lower image-text relevance tokens better preserve context) and incorporates it as an additional selection criterion. Experiments claim SOTA results, including up to 94% token removal on LLaVA while retaining 95% baseline performance with gains on compositional multi-skill reasoning tasks.
Significance. If the empirical claims and the superiority of residual-driven reconstruction over cosine diversity hold under full scrutiny, the work would offer a practical, training-free advance for efficient VLM inference with potential impact on resource-limited deployment. The anti-relevance observation, if robust, challenges prevailing relevance-based heuristics and could seed new selection criteria. The reported retention of performance at extreme pruning ratios (94%) is noteworthy for the field.
minor comments (2)
- [Abstract] Abstract: the claim of 'strong gains on compositional multi-skill reasoning tasks' should be supported by explicit per-task deltas or a dedicated table reference in the main text to allow readers to assess effect sizes.
- [Method] The manuscript should include a clear algorithmic description or pseudocode for the iterative residual selection procedure (including how anti-relevance is combined) to ensure reproducibility, as the high-level description leaves implementation details ambiguous.
Simulated Author's Rebuttal
We thank the referee for the detailed summary of our work and the positive assessment of SPARE's contributions to training-free visual token pruning. The recommendation for minor revision is noted. No major comments were provided in the report, so we have no specific points to address point-by-point at this stage. We will incorporate any minor suggestions during revision to strengthen the manuscript.
Circularity Check
No significant circularity detected
full rationale
The paper's central contribution is the SPARE algorithm, which reformulates visual token pruning as a column subset selection problem solved by iterative selection of tokens with large projection residuals to minimize reconstruction error, plus an additional anti-relevance criterion derived from an observed phenomenon. No equations, self-citations, or prior-work invocations are present in the provided material that reduce the claimed method, performance claims, or anti-relevance finding back to fitted inputs or self-referential definitions by construction. The derivation chain consists of a direct algorithmic reformulation and an empirical observation, both presented as independent of the target results, making the paper self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Iterative selection of tokens with large projection residuals minimizes reconstruction error for the original feature matrix.
Reference graph
Works this paper leans on
-
[1]
In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR (2025)
Alvar, S.R., Singh, G., Akbari, M., Zhang, Y.: DivPrune: Diversity-based Visual Token Pruning for Large Multimodal Models. In: IEEE/CVF Conference on Com- puter Vision and Pattern Recognition, CVPR (2025)
2025
-
[2]
CoRR (2025)
Bai, S., Chen, K., Liu, X., Wang, J., Ge, W., Song, S., Dang, K., Wang, P., Wang, S., Tang, J., Zhong, H., Zhu, Y., Yang, M., Li, Z., Wan, J., Wang, P., Ding, W., Fu, Z., Xu, Y., Ye, J., Zhang, X., Xie, T., Cheng, Z., Zhang, H., Yang, Z., Xu, H., Lin, J.: Qwen2.5-VL Technical Report. CoRR (2025)
2025
-
[3]
Linear Algebra and its Applications (1994)
Bjorck, A.: Numerics of gram-schmidt orthogonalization. Linear Algebra and its Applications (1994)
1994
-
[4]
In: Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA (2009)
Boutsidis, C., Mahoney, M.W., Drineas, P.: An Improved Approximation Algo- rithm for the Column Subset Selection Problem. In: Proceedings of the Twentieth Annual ACM-SIAM Symposium on Discrete Algorithms, SODA (2009)
2009
-
[5]
Linear algebra and its applications (1987)
Chan, T.F.: Rank Revealing QR Factorizations. Linear algebra and its applications (1987)
1987
-
[6]
In: 18th European Conference on Computer Vision, ECCV (2024)
Chen,L.,Zhao,H.,Liu,T.,Bai,S.,Lin,J.,Zhou,C.,Chang,B.:AnImageisWorth 1/2 Tokens After Layer 2: Plug-and-Play Inference Acceleration for Large Vision- Language Models. In: 18th European Conference on Computer Vision, ECCV (2024)
2024
-
[7]
Chiang, W.L., Li, Z., Lin, Z., Sheng, Y., Wu, Z., Zhang, H., Zheng, L., Zhuang, S., Zhuang, Y., Gonzalez, J.E., Stoica, I., Xing, E.P.: Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality (2023),https://lmsys.org/blog/ 2023-03-30-vicuna/
2023
-
[8]
In: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys- tems, NeurIPS (2022)
Dao,T.,Fu,D.Y.,Ermon,S.,Rudra,A.,Ré,C.:FlashAttention:FastandMemory- Efficient Exact Attention with IO-Awareness. In: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Sys- tems, NeurIPS (2022)
2022
-
[9]
Theory Comput
Deshpande, A., Rademacher, L., Vempala, S.S., Wang, G.: Matrix Approximation and Projective Clustering via Volume Sampling. Theory Comput. (2006)
2006
-
[10]
Drineas, P., Mahoney, M.W., Muthukrishnan, S.: Relative-Error CUR Matrix De- compositions. SIAM J. Matrix Anal. Appl. (2008)
2008
-
[11]
Farahat, A.K., Elgohary, A., Ghodsi, A., Kamel, M.S.: Greedy Column Subset Selection for Large-Scale Data Sets. Knowl. Inf. Syst. (2015)
2015
-
[12]
In: Annual Conference on Neural Information Processing Systems, NeurIPS
Fazlyab, M., Robey, A., Hassani, H., Morari, M., Pappas, G.J.: Efficient and Ac- curate Estimation of Lipschitz Constants for Deep Neural Networks. In: Annual Conference on Neural Information Processing Systems, NeurIPS. pp. 11423–11434 (2019)
2019
-
[13]
In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025)
Fu, C., Chen, P., Shen, Y., Qin, Y., Zhang, M., Lin, X., Yang, J., Zheng, X., Li, K., Sun, X., Wu, Y., Ji, R., Shan, C., He, R.: MME: A comprehensive evaluation benchmark for multimodal large language models. In: The Thirty-ninth Annual Conference on Neural Information Processing Systems Datasets and Benchmarks Track (2025)
2025
-
[14]
In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017 (2017)
Goyal, Y., Khot, T., Summers-Stay, D., Batra, D., Parikh, D.: Making the V in VQA matter: Elevating the role of image understanding in visual question an- swering. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017 (2017)
2017
-
[15]
Gu, M., Eisenstat, S.C.: Efficient Algorithms for Computing a Strong Rank- Revealing QR Factorization. SIAM J. Sci. Comput. (1996) 16 J. Lee et al
1996
-
[16]
In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 (2019)
Hudson, D.A., Manning, C.D.: GQA: A new dataset for real-world visual reasoning and compositional question answering. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 (2019)
2019
-
[17]
CoRR (2023)
Jiang, A.Q., Sablayrolles, A., Mensch, A., Bamford, C., Chaplot, D.S., de Las Casas, D., Bressand, F., Lengyel, G., Lample, G., Saulnier, L., Lavaud, L.R., Lachaux, M., Stock, P., Scao, T.L., Lavril, T., Wang, T., Lacroix, T., Sayed, W.E.: Mistral 7b. CoRR (2023)
2023
-
[18]
CoRR (2025)
Kim, Y., Zhang, Y., Liu, H., Jung, A., Lee, S., Hong, S.: Training-Free Token Pruning via Zeroth-Order Gradient Estimation in Vision-Language Models. CoRR (2025)
2025
-
[19]
Li, B., Zhang, Y., Guo, D., Zhang, R., Li, F., Zhang, H., Zhang, K., Zhang, P., Li, Y., Liu, Z., Li, C.: LLaVA-OneVision: Easy Visual Task Transfer. Trans. Mach. Learn. Res. (2025)
2025
-
[20]
CoRR (2024)
Li, F., Zhang, R., Zhang, H., Zhang, Y., Li, B., Li, W., Ma, Z., Li, C.: Llava-next- interleave: Tackling multi-image, video, and 3d in large multimodal models. CoRR (2024)
2024
-
[21]
In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP (2023)
Li, Y., Du, Y., Zhou, K., Wang, J., Zhao, W.X., Wen, J.: Evaluating Object Hallu- cination in Large Vision-Language Models. In: Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP (2023)
2023
-
[22]
In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 (2024)
Liu, H., Li, C., Li, Y., Lee, Y.J.: Improved baselines with visual instruction tuning. In: IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2024, Seattle, WA, USA, June 16-22, 2024 (2024)
2024
-
[23]
Liu, H., Li, C., Li, Y., Li, B., Zhang, Y., Shen, S., Lee, Y.J.: Llava-next: Improved reasoning, ocr, and world knowledge (2024),https://llava-vl.github.io/blog/ 2024-01-30-llava-next/
2024
-
[24]
Liu,H.,Li,C.,Wu,Q.,Lee,Y.J.:VisualInstructionTuning.In:AdvancesinNeural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems, NeurIPS (2023)
2023
-
[25]
Liu, Y., Duan, H., Zhang, Y., Li, B., Zhang, S., Zhao, W., Yuan, Y., Wang, J., He, C., Liu, Z., Chen, K., Lin, D.: Mmbench: Is your multi-modal model an all-around player? In: Computer Vision - ECCV 2024 - 18th European Conference, Milan, Italy, September 29-October 4, 2024, Proceedings, Part VI (2024)
2024
-
[26]
Lu, P., Mishra, S., Xia, T., Qiu, L., Chang, K., Zhu, S., Tafjord, O., Clark, P., Kalyan, A.: Learn to explain: Multimodal reasoning via thought chains for science question answering. In: Advances in Neural Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, November 28 - ...
2022
-
[27]
In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (2021)
Radford, A., Kim, J.W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., Sastry, G., Askell, A., Mishkin, P., Clark, J., Krueger, G., Sutskever, I.: Learning transferable visual models from natural language supervision. In: Proceedings of the 38th In- ternational Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (2021)
2021
-
[28]
Linear Algebra and its Appli- cations610, 52–58 (2021)
Shitov, Y.: Column subset selection is NP-complete. Linear Algebra and its Appli- cations610, 52–58 (2021)
2021
-
[29]
In: IEEE Conference on Com- puter Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 (2019) SPARE 17
Singh, A., Natarajan, V., Shah, M., Jiang, Y., Chen, X., Batra, D., Parikh, D., Rohrbach, M.: Towards VQA models that can read. In: IEEE Conference on Com- puter Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16-20, 2019 (2019) SPARE 17
2019
-
[30]
In: Proceedings of the 31st International Conference on Computational Linguistics, COLING (2025)
Song, D., Wang, W., Chen, S., Wang, X., Guan, M.X., Wang, B.: Less is More: A Simple yet Effective Token Reduction Method for Efficient Multi-modal LLMs. In: Proceedings of the 31st International Conference on Computational Linguistics, COLING (2025)
2025
-
[31]
LLaMA: Open and Efficient Foundation Language Models
Touvron, H., Lavril, T., Izacard, G., Martinet, X., Lachaux, M., Lacroix, T., Roz- ière, B., Goyal, N., Hambro, E., Azhar, F., Rodriguez, A., Joulin, A., Grave, E., Lample, G.: Llama: Open and efficient foundation language models. CoRR (2023), https://doi.org/10.48550/arXiv.2302.13971
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2302.13971 2023
-
[32]
Wen, Z., Gao, Y., Li, W., He, C., Zhang, L.: Token Pruning in Multimodal Large Language Models: Are We Solving the Right Problem? In: Findings of the Associ- ation for Computational Linguistics, ACL (2025)
2025
-
[33]
Important Tokens
Wen, Z., Gao, Y., Wang, S., Zhang, J., Zhang, Q., Li, W., He, C., Zhang, L.: Stop Looking for "Important Tokens" in Multimodal Language Models: Duplication Matters More. In: Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing, EMNLP (2025)
2025
-
[34]
CoRR (2024)
Xing, L., Huang, Q., Dong, X., Lu, J., Zhang, P., Zang, Y., Cao, Y., He, C., Wang,J.,Wu,F.,Lin,D.:PyramidDrop:AcceleratingYourLargeVision-Language Models via Pyramid Visual Redundancy Reduction. CoRR (2024)
2024
-
[35]
In: Forty-first International Conference on Machine Learning, ICML (2024)
Yu, W., Yang, Z., Li, L., Wang, J., Lin, K., Liu, Z., Wang, X., Wang, L.: MM-Vet: Evaluating Large Multimodal Models for Integrated Capabilities. In: Forty-first International Conference on Machine Learning, ICML (2024)
2024
-
[36]
In: The Thirty-ninth Annual Conference on Neural Information Process- ing Systems, NeurIPS (2025)
Zhang, Q., Liu, M., Li, L., Lu, M., Zhang, Y., Pan, J., She, Q., Zhang, S.: Beyond Attention or Similarity: Maximizing Conditional Diversity for Token Pruning in MLLMs. In: The Thirty-ninth Annual Conference on Neural Information Process- ing Systems, NeurIPS (2025)
2025
-
[37]
In: Forty-second Interna- tional Conference on Machine Learning, ICML (2025)
Zhang, Y., Fan, C., Ma, J., Zheng, W., Huang, T., Cheng, K., Gudovskiy, D.A., Okuno, T., Nakata, Y., Keutzer, K., Zhang, S.: SparseVLM: Visual Token Spar- sification for Efficient Vision-Language Model Inference. In: Forty-second Interna- tional Conference on Machine Learning, ICML (2025)
2025
-
[38]
Is the spoon made of the same material as the chopsticks?
Zhu, J., Wang, W., Chen, Z., Liu, Z., Ye, S., Gu, L., Tian, H., Duan, Y., Su, W., Shao, J., Gao, Z., Cui, E., Wang, X., Cao, Y., Liu, Y., Wei, X., Zhang, H., Wang, H., Xu, W., Li, H., Wang, J., Deng, N., Li, S., He, Y., Jiang, T., Luo, J., Wang, Y., He, C., Shi, B., Zhang, X., Shao, W., He, J., Xiong, Y., Qu, W., Sun, P., Jiao, P., Lv, H., Wu, L., Zhang, ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.