HALOMI: Learning Humanoid Loco-Manipulation with Active Perception from Human Demonstrations
Pith reviewed 2026-06-26 20:44 UTC · model grok-4.3
The pith
HALOMI transfers human demonstrations to humanoid robots for loco-manipulation by aligning ego-views and using a manifold-constrained controller for head-hand tracking.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
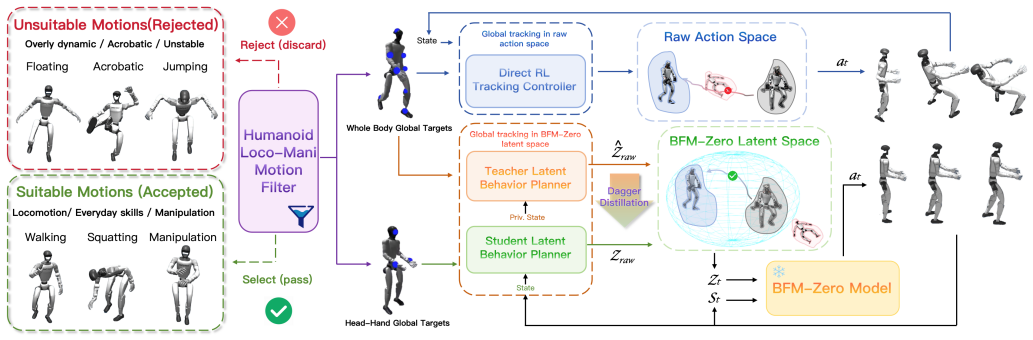
HALOMI extends Universal Manipulation Interface with egocentric sensing to gather ego-view and wrist-view observations plus head-hand trajectories, introduces a manifold-constrained controller that plans in a learned latent behavior manifold for precise world-frame head-hand tracking, and applies ego-view alignment together with controller-aware reference trajectory adaptation to close human-to-humanoid mismatches, yielding an 85 percent average success rate across three quantitatively evaluated real-world tasks on a Unitree G1 robot with actuated neck.
What carries the argument
The manifold-constrained controller, which plans inside a learned latent behavior manifold to produce precise and robust head-hand tracking under out-of-distribution targets.
If this is right
- The framework supports five real-world tasks including navigation, grasping, bimanual manipulation, whole-body coordination, and dynamic behaviors on a physical humanoid.
- Additional qualitative results demonstrate dynamic tossing and deep-squat grasping without retraining.
- The approach achieves 85 percent average success across the three tasks measured quantitatively.
Where Pith is reading between the lines
- Active neck actuation may be necessary for maintaining hand-eye coordination during loco-manipulation at human-like speeds.
- The latent manifold could serve as a reusable prior for transferring demonstrations across different humanoid morphologies.
- Scaling the human demonstration collection pipeline might extend the method to longer-horizon tasks that combine locomotion with multi-step manipulation.
Load-bearing premise
Ego-view alignment and controller-aware reference trajectory adaptation sufficiently reduce observation and action mismatches between human demonstrations and humanoid execution, while the manifold-constrained controller remains precise and robust under out-of-distribution targets.
What would settle it
A large drop in success rate when the manifold constraint is removed or when testing on targets that lie outside the distribution covered by the learned latent behavior manifold.
Figures






read the original abstract
Human demonstrations, which can be collected at scale and naturally capture active hand-eye coordination, are a promising data source for learning humanoid loco-manipulation. However, directly transferring human demonstrations to humanoids requires a precise world-frame tracking controller, which is often brittle under Out-of-Distribution(OOD) targets, while human-to-humanoid gaps persist in both egocentric observation and action execution. To address these challenges, we present HALOMI, a scalable framework for learning humanoid loco-manipulation with active perception from human demonstrations. HALOMI extends Universal Manipulation Interface (UMI) with egocentric sensing to collect ego-view and wrist-view observations along with head-hand trajectories at scale. We further propose a manifold-constrained controller that plans in a learned latent behavior manifold to enable precise and robust head-hand tracking in the world frame. To bridge the human-to-humanoid gap, we perform ego-view alignment and introduce a controller-aware reference trajectory adaptation to reduce mismatch in both observation and action execution. We validate HALOMI on a Unitree G1 humanoid robot with an actuated neck across five real-world tasks involving navigation, grasping, bimanual manipulation, whole-body coordination, and dynamic behaviors. Across the three quantitatively evaluated tasks, HALOMI achieves an average success rate of 85\%, while additional qualitative demonstrations show its ability to support dynamic tossing and deep-squat grasping.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces HALOMI, a framework extending the Universal Manipulation Interface (UMI) for learning humanoid loco-manipulation from human demonstrations. It incorporates egocentric sensing for ego-view and wrist-view observations plus head-hand trajectories, proposes a manifold-constrained controller that plans in a learned latent behavior manifold for robust world-frame head-hand tracking, and applies ego-view alignment together with controller-aware reference trajectory adaptation to reduce human-to-humanoid mismatches in observation and action spaces. Validation is performed on a Unitree G1 humanoid with actuated neck across five real-world tasks (navigation, grasping, bimanual manipulation, whole-body coordination, dynamic behaviors), reporting an average 85% success rate on the three quantitatively evaluated tasks.
Significance. If the empirical results hold after verification, the framework could meaningfully advance scalable imitation learning for humanoid robots by leveraging natural human active perception data while addressing observation and execution gaps. The real-world deployment on a physical Unitree G1 across diverse tasks including dynamic behaviors constitutes a concrete strength; the absence of machine-checked proofs or parameter-free derivations is expected for this empirical robotics contribution.
major comments (3)
- [§5] §5 (Experiments): The headline 85% average success rate on three tasks is presented without baseline comparisons, error bars, or failure-mode analysis, so it is impossible to determine whether the reported performance is attributable to the ego-view alignment, controller-aware adaptation, or manifold-constrained controller rather than task selection or favorable conditions.
- [§4.2] §4.2 (Manifold-constrained controller): The claim that the controller enables 'precise and robust head-hand tracking under OOD targets' is load-bearing for the central transfer argument, yet the section supplies no quantitative tracking-error metrics (e.g., position/orientation RMSE) or ablation against a non-manifold baseline controller.
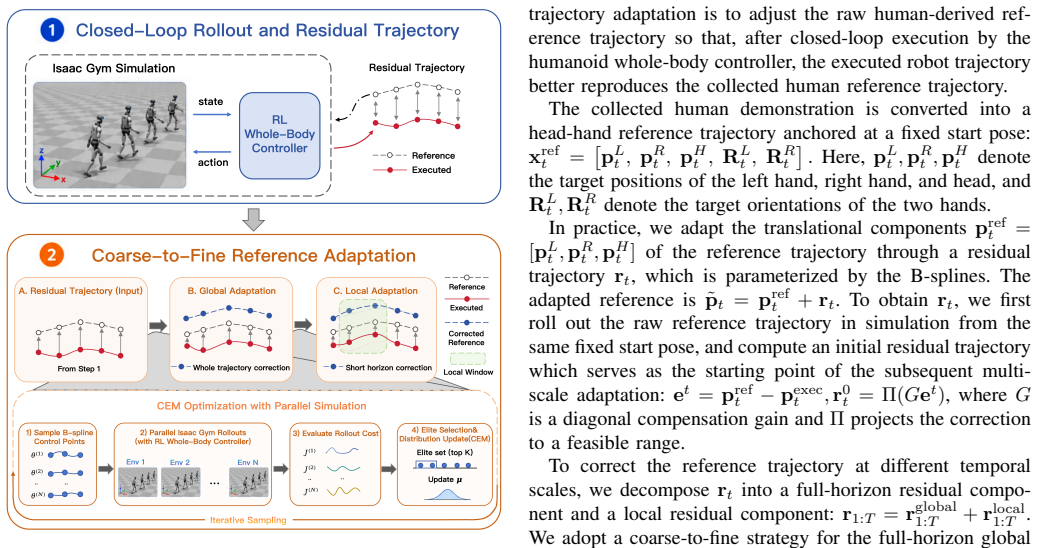
- [§4.3] §4.3 (Ego-view alignment and trajectory adaptation): These components are asserted to close the human-to-humanoid gap in both observation and action spaces, but no quantitative before/after mismatch metrics or controlled ablations isolating their contribution appear in the evaluation.
minor comments (2)
- [Abstract and §5] The abstract and §5 refer to 'five real-world tasks' but only three receive quantitative evaluation; a brief table clarifying which tasks are quantitative versus qualitative would improve clarity.
- [§4.2] Notation for the latent behavior manifold and the manifold constraint is introduced without an explicit equation reference in the main text; adding a numbered equation would aid reproducibility.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed comments. We agree that the major points identify areas where additional quantitative evidence and comparisons would strengthen the manuscript, and we outline specific revisions below to address them.
read point-by-point responses
-
Referee: [§5] §5 (Experiments): The headline 85% average success rate on three tasks is presented without baseline comparisons, error bars, or failure-mode analysis, so it is impossible to determine whether the reported performance is attributable to the ego-view alignment, controller-aware adaptation, or manifold-constrained controller rather than task selection or favorable conditions.
Authors: We agree that the experimental section would benefit from these elements to better isolate the contributions of each component. In the revised manuscript, we will add baseline comparisons (including variants without ego-view alignment, without controller-aware adaptation, and without the manifold constraint), report error bars from repeated trials, and include a failure-mode analysis for the three quantitative tasks. revision: yes
-
Referee: [§4.2] §4.2 (Manifold-constrained controller): The claim that the controller enables 'precise and robust head-hand tracking under OOD targets' is load-bearing for the central transfer argument, yet the section supplies no quantitative tracking-error metrics (e.g., position/orientation RMSE) or ablation against a non-manifold baseline controller.
Authors: We acknowledge that §4.2 currently lacks the requested quantitative support. We will revise this section to include position and orientation RMSE metrics for head-hand tracking under OOD targets, with direct comparisons to a non-manifold baseline controller to substantiate the robustness claims. revision: yes
-
Referee: [§4.3] §4.3 (Ego-view alignment and trajectory adaptation): These components are asserted to close the human-to-humanoid gap in both observation and action spaces, but no quantitative before/after mismatch metrics or controlled ablations isolating their contribution appear in the evaluation.
Authors: We agree that quantitative mismatch metrics and isolating ablations would clarify the impact of these components. In the revision, we will add before/after metrics quantifying the reduction in observation mismatch (e.g., via visual feature distances) and action mismatch, together with controlled ablations that isolate the contributions of ego-view alignment and controller-aware reference trajectory adaptation. revision: yes
Circularity Check
No circularity: empirical validation pipeline with no derivations or self-referential reductions
full rationale
The manuscript presents HALOMI as an empirical framework extending UMI with ego-view alignment, controller-aware adaptation, and a manifold-constrained controller, then reports real-robot success rates (85% average on three tasks). No equations, predictions, or first-principles results are claimed that reduce by construction to author-fitted quantities, self-citations, or ansatzes. The load-bearing elements are experimental outcomes on Unitree G1 hardware, which remain externally falsifiable and do not collapse into definitional equivalence with the inputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Vision in action: Learning active perception from human demonstrations,
H. Xiong, X. Xu, J. Wu, Y . Hou, J. Bohg, and S. Song, “Vision in action: Learning active perception from human demonstrations,” inConference on Robot Learning. PMLR, 2025, pp. 5450–5463
2025
-
[2]
Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,
C. Chi, Z. Xu, C. Pan, E. Cousineau, B. Burchfiel, S. Feng, R. Tedrake, and S. Song, “Universal manipulation interface: In-the-wild robot teach- ing without in-the-wild robots,” inProceedings of Robotics: Science and Systems (RSS), 2024
2024
-
[3]
Activeumi: Robotic manipulation with active perception from robot-free human demonstrations,
Q. Zeng, C. Li, J. S. John, Z. Zhou, J. Wen, G. Feng, Y . Zhu, and Y . Xu, “Activeumi: Robotic manipulation with active perception from robot-free human demonstrations,”arXiv preprint arXiv:2510.01607, 2025
arXiv 2025
-
[4]
Hommi: Learning whole-body mobile manipulation from human demonstrations,
X. Xu, J. Park, H. Zhang, E. Cousineau, A. Bhat, J. Barreiros, D. Wang, and S. Song, “Hommi: Learning whole-body mobile manipulation from human demonstrations,”arXiv preprint arXiv:2603.03243, 2026
Pith/arXiv arXiv 2026
-
[5]
Egomi: Learning active vision and whole-body manipulation from egocentric human demonstrations,
J. Yu, Y . Shentu, D. Wu, P. Abbeel, K. Goldberg, and P. Wu, “Egomi: Learning active vision and whole-body manipulation from egocentric human demonstrations,”arXiv preprint arXiv:2511.00153, 2025
arXiv 2025
-
[6]
Humanoid manipulation interface: Humanoid whole-body manipulation from robot-free demonstrations,
R. Nai, B. Zheng, J. Zhao, H. Zhu, S. Dai, Z. Chen, Y . Hu, Y . Hu, T. Zhang, C. Wenet al., “Humanoid manipulation interface: Humanoid whole-body manipulation from robot-free demonstrations,” arXiv preprint arXiv:2602.06643, 2026
arXiv 2026
-
[7]
Bifrostumi: Bridg- ing robot-free demonstrations and humanoid whole-body manipulation,
C. Yu, H. Wang, Y . Hu, J. Zhang, Y . Li, and S. Luo, “Bifrostumi: Bridg- ing robot-free demonstrations and humanoid whole-body manipulation,” arXiv preprint arXiv:2605.03452, 2026
Pith/arXiv arXiv 2026
-
[8]
In-the-wild compliant manipulation with umi-ft,
H. Choi, Y . Hou, C. Pan, S. Hong, A. Patel, X. Xu, M. R. Cutkosky, and S. Song, “In-the-wild compliant manipulation with umi-ft,”arXiv preprint arXiv:2601.09988, 2026
arXiv 2026
-
[9]
Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation,
M. Xu, H. Zhang, Y . Hou, Z. Xu, L. Fan, M. Veloso, and S. Song, “Dexumi: Using human hand as the universal manipulation interface for dexterous manipulation,” inConference on Robot Learning. PMLR, 2025, pp. 437–459
2025
-
[10]
UMI on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,
H. Ha, Y . Gao, Z. Fu, J. Tan, and S. Song, “UMI on legs: Making manipulation policies mobile with manipulation-centric whole-body controllers,” inProceedings of the 2024 Conference on Robot Learning, 2024
2024
-
[11]
Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit,
Q. Ben, F. Jia, J. Zeng, J. Dong, D. Lin, and J. Pang, “Homie: Humanoid loco-manipulation with isomorphic exoskeleton cockpit,”arXiv preprint arXiv:2502.13013, 2025
arXiv 2025
-
[12]
AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole- Body Control,
J. Li, X. Cheng, T. Huang, S. Yang, R.-Z. Qiu, and X. Wang, “AMO: Adaptive Motion Optimization for Hyper-Dexterous Humanoid Whole- Body Control,” inProceedings of Robotics: Science and Systems, LosAngeles, CA, USA, June 2025
2025
-
[13]
Twist: Teleoperated whole-body imitation system,
Y . Ze, Z. Chen, J. P. Ara ´ujo, Z. ang Cao, X. B. Peng, J. Wu, and C. K. Liu, “Twist: Teleoperated whole-body imitation system,”arXiv preprint arXiv:2505.02833, 2025
arXiv 2025
-
[14]
Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,
T. He, Z. Luo, X. He, W. Xiao, C. Zhang, W. Zhang, K. Kitani, C. Liu, and G. Shi, “Omnih2o: Universal and dexterous human- to-humanoid whole-body teleoperation and learning,”arXiv preprint arXiv:2406.08858, 2024
arXiv 2024
-
[15]
Clone: Closed-loop whole-body humanoid teleoperation for long- horizon tasks,
Y . Li, Y . Lin, J. Cui, T. Liu, W. Liang, Y . Zhu, and S. Huang, “Clone: Closed-loop whole-body humanoid teleoperation for long- horizon tasks,” in9th Annual Conference on Robot Learning, 2025
2025
-
[16]
Clot: Closed-loop global motion tracking for whole-body humanoid teleoperation,
T. Zhu, G. Cai, Y . Zhaohui, G. Ren, H. Xie, Z. Wang, J. Wu, J. Wang, X. Yang, Y . Muet al., “Clot: Closed-loop global motion tracking for whole-body humanoid teleoperation,”arXiv preprint arXiv:2602.15060, 2026
arXiv 2026
-
[17]
Universal humanoid motion representations for physics-based control,
Z. Luo, J. Cao, J. Merel, A. Winkler, J. Huang, K. Kitani, and W. Xu, “Universal humanoid motion representations for physics-based control,” inInternational Conference on Learning Representations, vol. 2024, 2024, pp. 56 766–56 782
2024
-
[18]
Y . Li, Z. Luo, T. Zhang, C. Dai, A. Kanervisto, A. Tirinzoni, H. Weng, K. Kitani, M. Guzek, A. Touatiet al., “Bfm-zero: A promptable behavioral foundation model for humanoid control using unsupervised reinforcement learning,”arXiv preprint arXiv:2511.04131, 2025
arXiv 2025
-
[19]
Learning physics- based full-body human reaching and grasping from brief walking references,
Y . Li, M. Lin, Z. Lin, Y . Deng, Y . Cao, and L. Yi, “Learning physics- based full-body human reaching and grasping from brief walking references,” inProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), June 2025, pp. 27 673–27 682
2025
-
[20]
Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,
M. Shi, S. Peng, J. Chen, H. Jiang, Y . Li, D. Huang, P. Luo, H. Li, and L. Chen, “Egohumanoid: Unlocking in-the-wild loco-manipulation with robot-free egocentric demonstration,”arXiv preprint arXiv:2602.10106, 2026
Pith/arXiv arXiv 2026
-
[21]
Sample-efficient cross-entropy method for real-time planning,
C. Pinneri, S. Sawant, S. Blaes, J. Achterhold, J. Stueckler, M. Rolinek, and G. Martius, “Sample-efficient cross-entropy method for real-time planning,” inConference on Robot Learning. PMLR, 2021, pp. 1049– 1065
2021
-
[22]
π 0.5: a vision-language-action model with open-world generalization,
K. Blacket al., “π 0.5: a vision-language-action model with open-world generalization,” in9th Annual Conference on Robot Learning, 2025
2025
-
[23]
Fastumi: A scalable and hardware- independent universal manipulation interface with dataset,
K. Liu, C. Guan, Z. Jia, Z. Wu, X. Liu, T. Wang, S. Liang, P. Chen, P. Zhang, H. Songet al., “Fastumi: A scalable and hardware- independent universal manipulation interface with dataset,”arXiv preprint arXiv:2409.19499, 2024
arXiv 2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.