Private Learning with Public Feature Conditioning
Pith reviewed 2026-06-26 21:17 UTC · model grok-4.3
The pith
Cond-DP constructs a conditioning matrix from public features to accelerate convergence of differentially private SGD in regression without extra privacy cost.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Cond-DP incorporates a data-driven conditioning matrix derived from public feature matrices to reshape the optimization landscape in differentially private stochastic gradient descent, enabling faster convergence in private regression tasks while recovering standard DPSGD when the matrix is the identity.
What carries the argument
The data-driven conditioning matrix constructed from public feature matrices with rapidly decaying spectra.
If this is right
- Private linear regression achieves provably faster convergence rates than DPSGD with no added privacy cost.
- Convergence guarantees apply across convex, strongly convex, and non-convex problem settings.
- Standard DPSGD is recovered exactly when the conditioning matrix is set to the identity.
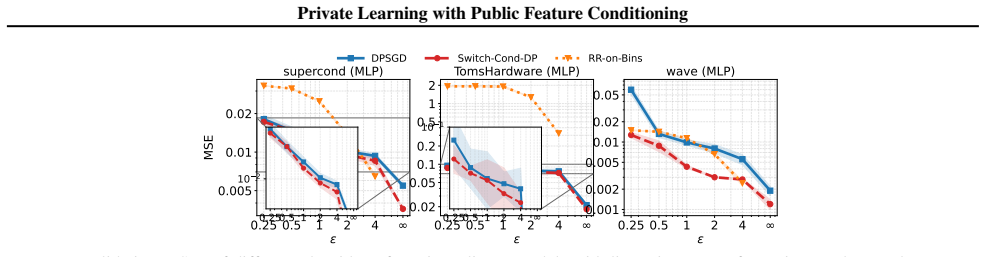
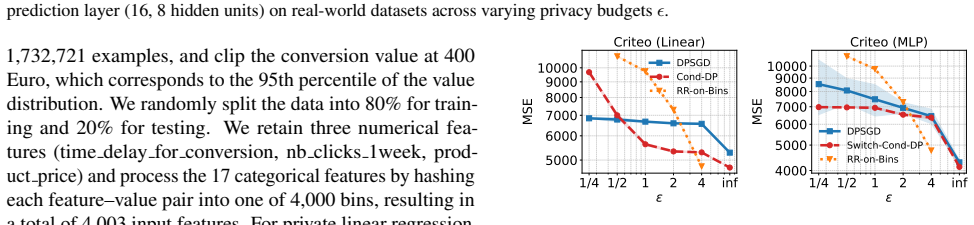
- Empirical performance improves over prior label-DP baselines on a range of datasets and model architectures.
Where Pith is reading between the lines
- The method could extend to other DP optimization tasks where public covariates are available and exhibit similar spectral decay.
- If public features in recommendation systems routinely satisfy the spectral condition, the privacy-utility gap for regression models could narrow in production settings.
- Testing whether the same conditioning improves performance when labels are fully private rather than label-DP would clarify the scope of the gains.
Load-bearing premise
Public feature matrices exhibit rapidly decaying spectra that allow a data-driven conditioning matrix to meaningfully reshape the optimization landscape.
What would settle it
A dataset in which the singular values of the public feature matrix decay slowly, such that Cond-DP shows no faster convergence or worse performance than plain DPSGD under the same privacy budget.
Figures





read the original abstract
We study differentially private (DP) regression in settings where each data sample includes public, non-sensitive features -- common in applications such as recommendation and advertising systems. While such label-DP or semi-sensitive-feature settings have been primarily explored in the context of classification, effective approaches for regression remain underexplored. We introduce Cond-DP, a conditioned variant of DPSGD that leverages the structure of public feature matrices to improve optimization under privacy constraints. Motivated by the observation that these public features often exhibit rapidly decaying spectra, Cond-DP incorporates a data-driven conditioning matrix to reshape the optimization landscape and accelerate convergence. We provide convergence guarantees for convex, strongly convex, and non-convex settings, and recover standard DPSGD as a special case when the conditioning matrix is the identity. We show how to construct an effective conditioning matrix for Cond-DP directly from public features, enabling provably faster convergence than DPSGD in private linear regression without incurring additional privacy cost. Empirically, Cond-DP with this conditioning matrix consistently outperforms state-of-the-art baselines across a wide range of datasets and model architectures under label DP, demonstrating strong and robust performance in practice.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Cond-DP, a conditioned variant of DPSGD for differentially private regression that constructs a data-driven conditioning matrix from public (non-sensitive) features. It claims this yields provably faster convergence than standard DPSGD for private linear regression with no additional privacy cost, provides convergence guarantees across convex/strongly convex/non-convex regimes, recovers DPSGD when the matrix is the identity, and shows consistent empirical outperformance over baselines under label DP.
Significance. If the central claims hold, the work provides a practical mechanism to exploit public feature structure for improved private optimization in regression without extra privacy expenditure, which is relevant for applications like recommendation systems. The explicit recovery of DPSGD as a special case when the conditioning matrix is the identity is a clear strength that anchors the contribution.
major comments (1)
- [Abstract] Abstract (motivation paragraph): The claim of 'provably faster convergence than DPSGD' is motivated by the observation that public feature matrices 'often exhibit rapidly decaying spectra,' but this spectral property is presented only as motivation rather than a derived condition or robustness result. Since the analysis recovers standard DPSGD for the identity matrix, any strict improvement is load-bearing on this unproven spectral assumption; without it the guarantee reduces to the baseline.
minor comments (1)
- The abstract states empirical outperformance 'across a wide range of datasets and model architectures' but provides no detail on error-bar handling, number of runs, or statistical testing; this should be clarified in the experimental section for reproducibility.
Simulated Author's Rebuttal
We thank the referee for the detailed reading and the constructive comment on the abstract. We address the point below and indicate the planned revision.
read point-by-point responses
-
Referee: [Abstract] Abstract (motivation paragraph): The claim of 'provably faster convergence than DPSGD' is motivated by the observation that public feature matrices 'often exhibit rapidly decaying spectra,' but this spectral property is presented only as motivation rather than a derived condition or robustness result. Since the analysis recovers standard DPSGD for the identity matrix, any strict improvement is load-bearing on this unproven spectral assumption; without it the guarantee reduces to the baseline.
Authors: We agree that the provable improvement over DPSGD is not unconditional and depends on the spectrum of the constructed conditioning matrix. The convergence analysis in Sections 3–4 derives explicit rates that improve upon standard DPSGD precisely when the conditioning matrix (built from public features) yields a more favorable effective condition number; the identity-matrix case recovers the baseline rates as a special case. The construction procedure in Section 5 is designed to produce such a matrix whenever the public feature covariance exhibits the decaying spectrum that is typical in the applications considered. We acknowledge that the abstract presents this spectral property only as motivation. In the revision we will update the abstract to state explicitly that the faster convergence guarantee holds under the condition that the public features admit a conditioning matrix with improved spectrum (as derived in the analysis), thereby framing the spectral decay as a derived condition rather than mere motivation. revision: yes
Circularity Check
No significant circularity; derivation self-contained
full rationale
The paper constructs the conditioning matrix explicitly from public features (external to the private optimization) and provides general convergence guarantees that recover DPSGD when the matrix is the identity. The claimed improvement is conditional on the matrix being effective due to public feature spectra, which is stated as motivation rather than a derived or fitted quantity. No equations reduce a prediction to a fitted input by construction, no self-citation is load-bearing for the central claim, and no ansatz or uniqueness result is smuggled in. The analysis is independent of the target faster-convergence result.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Public feature matrices exhibit rapidly decaying spectra
- standard math Standard assumptions for convex, strongly convex, and non-convex convergence analysis hold
Reference graph
Works this paper leans on
-
[1]
The algorithmic foundations of differential privacy.Found
Dwork, Cynthia and Roth, Aaron , title =. 2014 , issue_date =. doi:10.1561/0400000042 , journal =
-
[2]
Proceedings of Thirty Fourth Conference on Learning Theory , pages =
(Nearly) Dimension Independent Private ERM with AdaGrad Rates\\ via Publicly Estimated Subspaces , author =. Proceedings of Thirty Fourth Conference on Learning Theory , pages =. 2021 , editor =
2021
-
[3]
2024 , eprint=
Training Differentially Private Ad Prediction Models with Semi-Sensitive Features , author=. 2024 , eprint=
2024
-
[4]
2024 , URL=
Training Differentially Private Ad Prediction Models with Semi-Sensitive Features , author=. 2024 , URL=
2024
-
[5]
2023 , eprint=
Private Learning with Public Features , author=. 2023 , eprint=
2023
-
[6]
The Eleventh International Conference on Learning Representations , year=
Regression with Label Differential Privacy , author=. The Eleventh International Conference on Learning Representations , year=
-
[7]
Advances in Neural Information Processing Systems , editor=
Deep Learning with Label Differential Privacy , author=. Advances in Neural Information Processing Systems , editor=. 2021 , url=
2021
-
[8]
Badih Ghazi and Yangsibo Huang and Pritish Kamath and Ravi Kumar and Pasin Manurangsi and Chiyuan Zhang , booktitle=. Label. 2024 , url=
2024
-
[9]
Label differential privacy and private training data release , year =
Busa-Fekete, R\'. Label differential privacy and private training data release , year =. Proceedings of the 40th International Conference on Machine Learning , articleno =
-
[10]
2021 , eprint=
Label differential privacy via clustering , author=. 2021 , eprint=
2021
-
[11]
Antipodes of label differential privacy: PATE and ALIBI , year =
Malek, Mani and Mironov, Ilya and Prasad, Karthik and Shilov, Igor and Tram\`. Antipodes of label differential privacy: PATE and ALIBI , year =. Proceedings of the 35th International Conference on Neural Information Processing Systems , articleno =
-
[12]
2023 , eprint=
Label Differential Privacy via Aggregation , author=. 2023 , eprint=
2023
-
[13]
Factorization Machines , year=
Rendle, Steffen , booktitle=. Factorization Machines , year=
-
[14]
and Perescu-Popescu, Liliana and Mastorakis, Nikos , title =
Popescu, Marius-Constantin and Balas, Valentina E. and Perescu-Popescu, Liliana and Mastorakis, Nikos , title =. WSEAS Trans. Cir. and Sys. , month = jul, pages =. 2009 , issue_date =
2009
-
[15]
Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , title =
Abadi, Martin and Chu, Andy and Goodfellow, Ian and McMahan, H. Brendan and Mironov, Ilya and Talwar, Kunal and Zhang, Li , year=. Deep Learning with Differential Privacy , url=. doi:10.1145/2976749.2978318 , booktitle=
-
[16]
Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =
Evading the Curse of Dimensionality in Unconstrained Private GLMs , author =. Proceedings of The 24th International Conference on Artificial Intelligence and Statistics , pages =. 2021 , editor =
2021
-
[17]
The influence of a matrix condition number on iterative methods' convergence , year=
Pyzara, Anna and Bylina, Beata and Bylina, Jarosław , booktitle=. The influence of a matrix condition number on iterative methods' convergence , year=
-
[18]
Proceedings of the 24th Annual Conference on Learning Theory , pages =
Sample Complexity Bounds for Differentially Private Learning , author =. Proceedings of the 24th Annual Conference on Learning Theory , pages =. 2011 , editor =
2011
-
[19]
2017 , eprint=
Semi-supervised Knowledge Transfer for Deep Learning from Private Training Data , author=. 2017 , eprint=
2017
-
[20]
2018 , eprint=
Scalable Private Learning with PATE , author=. 2018 , eprint=
2018
-
[21]
Proceedings of the 36th International Conference on Machine Learning , pages =
On Sparse Linear Regression in the Local Differential Privacy Model , author =. Proceedings of the 36th International Conference on Machine Learning , pages =. 2019 , editor =
2019
-
[22]
Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds , year=
Bassily, Raef and Smith, Adam and Thakurta, Abhradeep , booktitle=. Private Empirical Risk Minimization: Efficient Algorithms and Tight Error Bounds , year=
-
[23]
3rd International Conference for Learning Representations, San Diego, 2015 , year=
Adam: A method for stochastic optimization , author=. 3rd International Conference for Learning Representations, San Diego, 2015 , year=
2015
-
[24]
Proceedings of the 29th International Coference on International Conference on Machine Learning , pages =
Rakhlin, Alexander and Shamir, Ohad and Sridharan, Karthik , title =. Proceedings of the 29th International Coference on International Conference on Machine Learning , pages =. 2012 , isbn =
2012
-
[25]
Ashkan Yousefpour and Igor Shilov and Alexandre Sablayrolles and Davide Testuggine and Karthik Prasad and Mani Malek and John Nguyen and Sayan Ghosh and Akash Bharadwaj and Jessica Zhao and Graham Cormode and Ilya Mironov , journal=. Opacus:
-
[26]
Trafficformer: An efficient pre-trained model for traffic data
Mahloujifar, Saeed and Guo, Chuan and Suh, G. Edward and Chaudhuri, Kamalika , booktitle =. 2025 , volume =. doi:10.1109/SP61157.2025.00179 , url =
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.