Semantic Robustness Certification for Vision-Language Models
Pith reviewed 2026-06-26 21:30 UTC · model grok-4.3
The pith
A framework certifies vision-language model robustness under semantic transformations by using text prompts as proxies and deriving closed-form decision boundaries.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Leveraging the open-vocabulary capability of VLMs, we use text prompts as semantic proxies to construct transformations parameterized by an extent that controls the degree of semantic variation. By characterizing the VLM decision boundary in closed form, our framework quantitatively certifies extent intervals for which the predicted class remains unchanged under the semantic transformation.
What carries the argument
Closed-form characterization of the VLM decision boundary under extent-parameterized semantic transformations proxied by text prompts.
If this is right
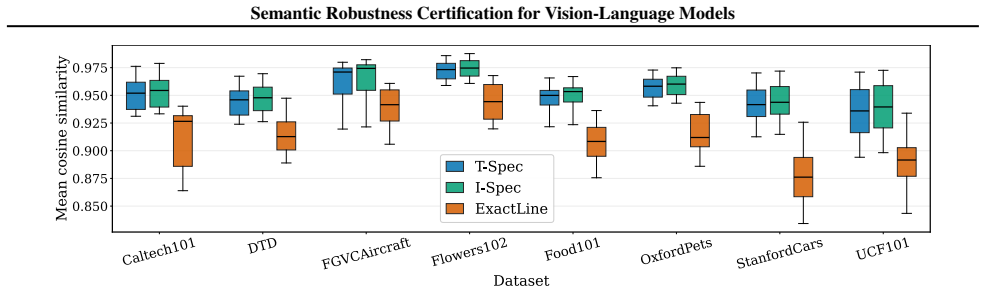
- The framework certifies robustness to semantic variations without collecting additional data for each variation type.
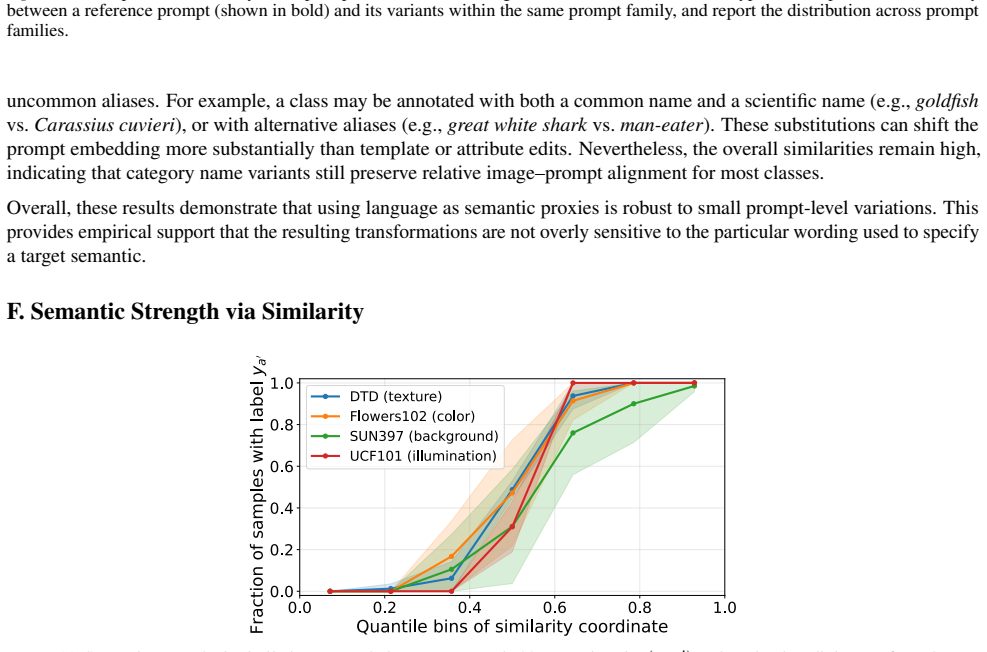
- Quantitative extent intervals are produced that guarantee the prediction remains stable.
- The approach works across both synthetic and real-world datasets for diverse semantic changes.
- Certification becomes practical for downstream tasks that encounter natural distribution shifts.
Where Pith is reading between the lines
- The certified intervals could be used to rank different prompts or models by how wide a semantic range they tolerate.
- Similar closed-form boundary techniques might apply to other multimodal models if their outputs can be expressed in comparable algebraic form.
- Deployed systems could track the extent parameter of incoming inputs and flag cases that fall outside certified intervals.
Load-bearing premise
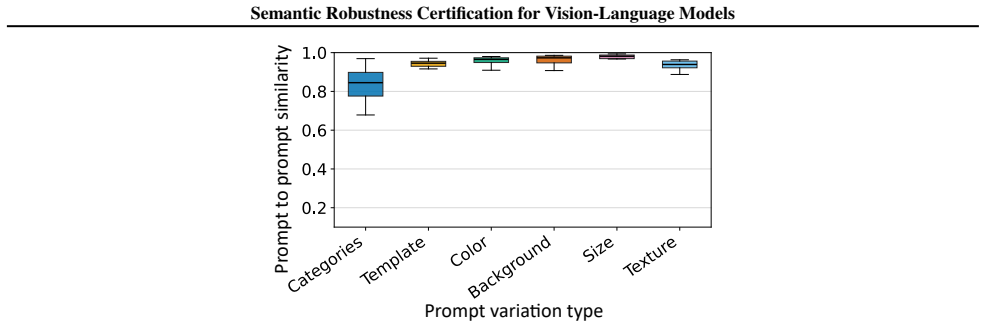
Text prompts serve as faithful semantic proxies for visual transformations and the VLM decision boundary admits a closed-form characterization allowing direct interval computation.
What would settle it
An experiment in which the model's actual class prediction changes inside a certified extent interval, or in which the computed closed-form boundary disagrees with the model's observed outputs on transformed inputs.
Figures






read the original abstract
Vision-language models (VLMs) are now widely used in downstream tasks. However, real-world applications often expose VLMs to distribution shifts induced by semantic variation (e.g., shape, size, and style). Robustness certification determines if a model's prediction changes when transformations are applied to its input. While most certification frameworks study geometric or pixel-level transformations over inputs, this work proposes a novel framework that enables certifying VLM robustness under semantic-level transformations. Leveraging the open-vocabulary capability of VLMs, we use text prompts as semantic proxies to construct transformations parameterized by an extent that controls the degree of semantic variation. By characterizing the VLM decision boundary in closed form, our framework quantitatively certifies extent intervals for which the predicted class remains unchanged under the semantic transformation. Our framework is the first to certify VLM robustness under semantic-level variations without requiring additional data for each variation, making it practical to apply. Experiments on both synthetic and real-world data show that our framework enables certifying robustness under diverse semantic variations across scenarios.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a framework for certifying robustness of vision-language models under semantic transformations (shape, size, style) by treating text prompts as parameterized semantic proxies controlled by an 'extent' variable. It claims to derive a closed-form characterization of the VLM decision boundary, enabling quantitative certification of intervals of the extent parameter over which the predicted class is invariant, without needing extra data per variation. Experiments on synthetic and real data are reported to support applicability across scenarios.
Significance. If the closed-form boundary characterization is valid, the work would be a notable advance: the first certification method targeting semantic-level shifts in VLMs that remains practical (no per-variation retraining or data). It directly addresses a gap left by geometric/pixel-level certification frameworks and could improve reliability of open-vocabulary VLMs in deployment.
major comments (1)
- [Abstract] Abstract (central claim): the assertion that the VLM decision boundary 'admits a closed-form characterization' permitting direct interval computation is load-bearing for the entire quantitative certification result. The abstract provides no functional form relating the extent parameter to image embeddings f(I(extent)) or effective text embeddings; without an explicit analytic mapping (e.g., linear interpolation or known parametric family) whose cosine-similarity roots can be solved in closed form, the argmax decision boundary cannot be inverted analytically for general VLMs, rendering the certification claim unsupported.
minor comments (1)
- The abstract would be clearer if it briefly indicated the assumed functional form of the extent-to-embedding map or gave the explicit boundary equation whose roots are claimed to be closed-form.
Simulated Author's Rebuttal
We thank the referee for the careful review and for identifying the need to substantiate the closed-form characterization more explicitly. We address the concern point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract (central claim): the assertion that the VLM decision boundary 'admits a closed-form characterization' permitting direct interval computation is load-bearing for the entire quantitative certification result. The abstract provides no functional form relating the extent parameter to image embeddings f(I(extent)) or effective text embeddings; without an explicit analytic mapping (e.g., linear interpolation or known parametric family) whose cosine-similarity roots can be solved in closed form, the argmax decision boundary cannot be inverted analytically for general VLMs, rendering the certification claim unsupported.
Authors: We agree the abstract is concise and omits the explicit mapping. Section 3 of the manuscript defines the extent-parameterized semantic proxy by linearly interpolating between text embeddings of base prompts that represent the semantic variation (e.g., low-to-high extent of shape or style). The resulting text embedding is therefore affine in the extent variable. The VLM decision is the argmax over cosine similarities between the (fixed) image embedding and these parameterized text embeddings. Substituting the affine form yields cosine-similarity scores that are quadratic in the extent; the decision-boundary crossings are therefore the real roots of quadratic equations, which are obtained in closed form via the quadratic formula. This supplies the quantitative interval certification without per-variation data or numerical search. We will revise the abstract to include a one-sentence statement of the affine embedding assumption and the resulting quadratic closed-form boundary. revision: yes
Circularity Check
No significant circularity; derivation relies on model similarity scores without self-referential reduction
full rationale
The paper's central claim is a closed-form characterization of the VLM decision boundary under text-prompt-parameterized semantic transformations, enabling direct interval certification for unchanged predictions. No equations or steps in the abstract or description reduce the certification output to a fitted parameter or self-citation by construction. The framework treats the VLM's open-vocabulary similarity scores as given inputs and derives extent intervals from them analytically, without evidence of the result being equivalent to its inputs via self-definition, renaming, or load-bearing self-citation. This is a standard non-circular outcome for a certification method that assumes an analytic boundary form.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Achiam, J., Adler, S., Agarwal, S., Ahmad, L., Akkaya, I., Aleman, F. L., Almeida, D., Altenschmidt, J., Altman, S., Anadkat, S., et al. Gpt-4 technical report.arXiv preprint arXiv:2303.08774,
work page internal anchor Pith review Pith/arXiv arXiv
-
[2]
Food-101– mining discriminative components with random forests
Bossard, L., Guillaumin, M., and Van Gool, L. Food-101– mining discriminative components with random forests. InComputer Vision–ECCV 2014: 13th European Con- ference, Zurich, Switzerland, September 6-12, 2014, Pro- ceedings, Part VI 13, pp. 446–461. Springer,
2014
-
[3]
Crabb´e, J., Rodr ´ıguez, P., Shankar, V ., Zappella, L., and Blaas, A. Interpreting clip: Insights on the robust- ness to imagenet distribution shifts.arXiv preprint arXiv:2310.13040,
-
[4]
N., Jovanovic, N., and Vechev, M
Ferrari, C., Muller, M. N., Jovanovic, N., and Vechev, M. Complete verification via multi-neuron relaxation guided branch-and-bound.arXiv preprint arXiv:2205.00263,
-
[5]
Guo, D., Wu, F., Zhu, F., Leng, F., Shi, G., Chen, H., Fan, H., Wang, J., Jiang, J., Wang, J., et al. Seed1. 5-vl technical report.arXiv preprint arXiv:2505.07062,
work page internal anchor Pith review Pith/arXiv arXiv
-
[6]
Li, Y ., Dong, J., Yang, C., Wen, S., Koniusz, P., Huang, T., Tian, Y ., and Ong, Y .-S. Mmt-ard: Multimodal multi- teacher adversarial distillation for robust vision-language models.arXiv preprint arXiv:2511.17448, 2025a. Li, Y ., Yang, C., Dong, J., Yao, Z., Xu, H., Dong, Z., Zeng, H., An, Z., and Tian, Y . Ammkd: Adaptive multimodal multi-teacher disti...
-
[7]
Fine-Grained Visual Classification of Aircraft
Maji, S., Rahtu, E., Kannala, J., Blaschko, M., and Vedaldi, A. Fine-grained visual classification of aircraft.arXiv preprint arXiv:1306.5151,
work page internal anchor Pith review Pith/arXiv arXiv
-
[8]
Schlarmann, C., Singh, N. D., Croce, F., and Hein, M. Robust clip: Unsupervised adversarial fine-tuning of vi- sion embeddings for robust large vision-language models. arXiv preprint arXiv:2402.12336,
-
[9]
UCF101: A Dataset of 101 Human Actions Classes From Videos in The Wild
11 Semantic Robustness Certification for Vision-Language Models Soomro, K., Zamir, A. R., and Shah, M. Ucf101: A dataset of 101 human actions classes from videos in the wild. arXiv preprint arXiv:1212.0402,
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
Local path inte- gration for attribution
Yang, P., Akhtar, N., Wen, Z., and Mian, A. Local path inte- gration for attribution. InProceedings of the AAAI Confer- ence on Artificial Intelligence, volume 37, pp. 3173–3180, 2023a. Yang, P., Akhtar, N., Wen, Z., Shah, M., and Mian, A. S. Re- calibrating feature attributions for model interpretation. InInternational Conference on Learning Representati...
-
[11]
Zhu, W., Zhang, Y ., Jin, X., Zeng, W., and Zhang, L. Ants: Adaptive negative textual space shaping for ood detection via test-time mllm understanding and reasoning.arXiv preprint arXiv:2509.03951,
-
[12]
Therefore,φ∈ U c,c′(δ). B. Experimental Setup In this work, we use the publicly available pretrained CLIP ViT-B/16 model released by OpenAI (Radford et al., 2021). All experiments are conducted using an NVIDIA 3090Ti GPU (24GB), a 16-core 3.9GHz Intel Core i9-12900K CPU, and 128GB RAM. To evaluate semantic robustness under controllable semantic extents, w...
2021
-
[13]
We therefore use multimodal large language models (MLLM) (e.g., GPT models (Achiam et al.,
and CycleGAN (Zhu et al., 2017)) often produced unrealistic outputs when asked to enforce semantic shifts on out-of-domain objects, and diffusion-based generators (e.g., InstructPix2Pix (Brooks et al., 2023)) frequently introduced visible artifacts or drifted from the input identity, which injects unintended semantic factors. We therefore use multimodal l...
2017
-
[14]
a photo of a [attribute] [class]
and Seedream (Guo et al., 2025)) to construct synthetic image sequences. Concretely, for each dataset we choose three representative classes and sample seed images per class. For each seed image, we generate at least one pair of ID and OOD semantic shifts for each semantic. Each shift is instantiated as an ordered image sequence with an explicit semantic ...
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.