Learning Robust Pair Confidence for Multimodal Emotion-Cause Pair Extraction
Pith reviewed 2026-06-26 20:53 UTC · model grok-4.3
The pith
A training framework adds margin and alignment constraints to make pair confidence more robust for multimodal emotion-cause extraction.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
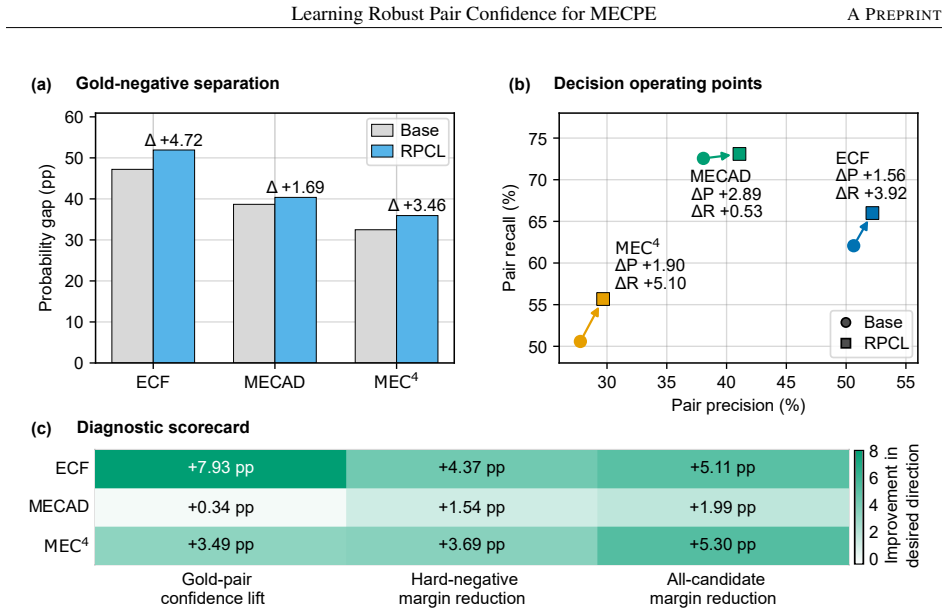
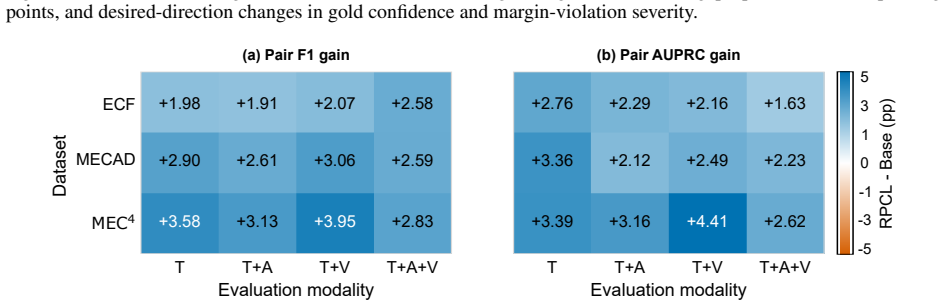
RPCL encourages pair confidence to be both discriminative and stable by separating gold pairs from row-wise hard negatives through a confidence-difference margin constraint and by aligning clean pair predictions with predictions from a corrupted view where non-gold contextual utterance representations are partially corrupted. The original clean pair scorer and decoding pipeline remain unchanged at inference. On ECF, MECAD, and MEC4 the method improves three-seed mean Pair F1 by 2.58 to 2.83 percentage points in the full text-audio-video setting and raises mean Pair AUPRC on all three datasets, with diagnostic checks showing larger gold-negative confidence gaps and lower margin-violation seve
What carries the argument
RPCL (Robust Pair Confidence Learning), a training framework that imposes a margin constraint on confidence differences and an alignment constraint between clean and corrupted views to shape relative pair confidence.
If this is right
- Gold pairs receive measurably higher separation from their row-wise hard negatives.
- Mean Pair AUPRC rises on every tested dataset in the full multimodal setting.
- Diagnostic metrics record both larger gold-negative gaps and lower margin-violation severity.
- The same inference-time scorer and decoder can be retained without modification.
- The gains appear across three distinct MECPE benchmarks when text, audio, and video are all used.
Where Pith is reading between the lines
- The same margin-plus-alignment pattern could be tested on other pair or link extraction tasks where relative ranking among candidates matters.
- The corruption-alignment idea might reduce dependence on incidental non-gold context in any multimodal ranking setting.
- If the constraints prove stable, they could be combined with larger pre-trained multimodal backbones to check whether the F1 lift scales.
- The approach suggests that explicit control over confidence geometry may be more effective than simply scaling model capacity for this class of extraction problems.
Load-bearing premise
The reported gains in Pair F1 and AUPRC arise from the two proposed constraints rather than from differences in hyperparameter search, random seeds, or base-model implementation details.
What would settle it
A re-run of the experiments that matches all hyperparameters, seeds, and base-model code exactly, removes the two RPCL constraints, and finds no remaining difference in Pair F1 would falsify that the constraints drive the gains.
Figures

read the original abstract
Multimodal emotion-cause pair extraction (MECPE) requires reliable pair confidence over candidate pairs. Existing pair scorers commonly use pair-level cross entropy over valid candidates, which treats links mostly independently. This leaves the relative confidence geometry among competing causes under-constrained, allowing gold pairs to stay close to hard negatives or rely on incidental non-gold context. We study this vulnerability as pair-confidence brittleness and propose RPCL (Robust Pair Confidence Learning), a training-only framework for pair-confidence learning. RPCL encourages pair confidence to be both discriminative and stable: gold pairs are separated from row-wise hard negatives through a confidence-difference margin constraint, and clean pair predictions are aligned with predictions from a corrupted view where non-gold contextual utterance representations are partially corrupted. The original clean pair scorer and decoding pipeline are used unchanged at inference time. On ECF, MECAD, and MEC4, RPCL improves the three-seed mean Pair F1 over a matched base model by 2.58 to 2.83 percentage points in the full text-audio-video setting, and improves mean Pair AUPRC on all three datasets. Diagnostic analysis further shows larger gold-negative confidence gaps and lower margin-violation severity. These results suggest that explicitly shaping pair confidence is an effective training strategy for MECPE.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes RPCL, a training-only framework for multimodal emotion-cause pair extraction (MECPE) consisting of a confidence-difference margin constraint separating gold pairs from row-wise hard negatives and an alignment loss between clean pair predictions and those from a corrupted view of non-gold context. It claims that RPCL yields 2.58–2.83 pp gains in three-seed mean Pair F1 (and consistent Pair AUPRC gains) over a matched base model on the ECF, MECAD, and MEC4 datasets in the full text-audio-video setting, supported by diagnostic checks showing larger gold-negative gaps and lower margin violations. The original scorer and decoder remain unchanged at inference.
Significance. If the gains are verifiably attributable to the two constraints, RPCL would constitute a lightweight, inference-neutral training procedure that directly addresses pair-confidence brittleness in MECPE. The diagnostic analysis of confidence gaps provides mechanistic support, but the lack of a documented matching protocol, error bars, ablations, or statistical tests leaves the central empirical claim under-supported.
major comments (3)
- [Abstract / experimental claims paragraph] Abstract and experimental claims paragraph: the assertion of improvement 'over a matched base model' supplies no protocol for matching architecture weights, optimizer state, hyperparameter search budget, data preprocessing, or random-seed handling. Without this, the reported 2.58–2.83 pp Pair F1 deltas cannot be attributed to the margin constraint and corrupted-view alignment rather than implementation discrepancies.
- [Results section] Results section: the three-seed mean Pair F1 and AUPRC figures are presented without error bars, standard deviations across seeds, or statistical significance tests. This omission prevents assessment of whether the observed improvements are consistent or could arise from seed variance alone.
- [Results section] Results section: no ablation tables isolate the individual contributions of the confidence-difference margin versus the corrupted-view alignment loss, nor compare against alternative regularizers. This leaves open whether both proposed constraints are necessary for the reported gains.
minor comments (1)
- [Method] Notation for the corrupted-view alignment loss could be clarified with an explicit equation showing how the corruption is applied to utterance representations.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback highlighting areas where our empirical claims require stronger documentation and analysis. We respond to each major comment below and will revise the manuscript to address the concerns.
read point-by-point responses
-
Referee: [Abstract / experimental claims paragraph] Abstract and experimental claims paragraph: the assertion of improvement 'over a matched base model' supplies no protocol for matching architecture weights, optimizer state, hyperparameter search budget, data preprocessing, or random-seed handling. Without this, the reported 2.58–2.83 pp Pair F1 deltas cannot be attributed to the margin constraint and corrupted-view alignment rather than implementation discrepancies.
Authors: We agree a documented protocol is necessary for attribution. The matched base model shares identical architecture, hyperparameters, optimizer, preprocessing, and random seeds with the RPCL variant; the sole difference is the addition of the two RPCL loss terms. We will insert a dedicated 'Matched Base Model Protocol' subsection in the revised manuscript to explicitly list these controls. revision: yes
-
Referee: [Results section] Results section: the three-seed mean Pair F1 and AUPRC figures are presented without error bars, standard deviations across seeds, or statistical significance tests. This omission prevents assessment of whether the observed improvements are consistent or could arise from seed variance alone.
Authors: We accept that error bars and significance tests strengthen the results. Although three-seed means are reported, we will add per-seed standard deviations as error bars to the tables and include paired t-test p-values comparing base and RPCL models in the revision. revision: yes
-
Referee: [Results section] Results section: no ablation tables isolate the individual contributions of the confidence-difference margin versus the corrupted-view alignment loss, nor compare against alternative regularizers. This leaves open whether both proposed constraints are necessary for the reported gains.
Authors: The manuscript prioritizes the joint RPCL effect supported by diagnostic gap analysis. To isolate contributions we will add an ablation table in the revision showing base, margin-only, alignment-only, and full RPCL variants, plus brief comparison to a standard regularizer where space allows. revision: yes
Circularity Check
No significant circularity; empirical training procedure on public benchmarks
full rationale
The paper introduces RPCL as a training-only framework consisting of a margin constraint on gold vs. hard-negative pair confidences plus a corrupted-view alignment loss. These are applied during training; inference uses the unchanged base scorer. Reported Pair F1 and AUPRC gains are measured on the public datasets ECF, MECAD, and MEC4 against a matched base model. No equations, self-definitional reductions, fitted-input predictions, or load-bearing self-citations appear in the provided text that would make the claimed improvements equivalent to the inputs by construction. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
free parameters (1)
- confidence-difference margin
Reference graph
Works this paper leans on
-
[1]
doi:10.18653/v1/2023.eacl- main.240
Association for Computational Linguistics. doi:10.18653/v1/2023.eacl- main.240. Guimin Hu, Zhihong Zhu, Daniel Hershcovich, Lijie Hu, Hasti Seifi, and Jiayuan Xie. UniMEEC: Towards unified multimodal emotion recognition and emotion cause. In Yaser Al-Onaizan, Mohit Bansal, and Yun-Nung Chen, editors,Findings of the Association for Computational Linguistic...
-
[2]
Qianer Li, Peijie Huang, Jiawei Chen, Jialin Wu, Yuhong Xu, and Peiyuan Lin. Multimodal emotion recognition in conversation with mutual information maximization and contrastive loss. In Maosong Sun, Bing Qin, Xipeng Qiu, Jing Jiang, and Xianpei Han, editors,Proceedings of the 22nd Chinese National Conference on Computational Linguistics, pages 264–276, Ha...
-
[3]
Bobo Li, Hao Fei, Fei Li, Tat-Seng Chua, and Donghong Ji
doi:10.1145/3558548. Bobo Li, Hao Fei, Fei Li, Tat-Seng Chua, and Donghong Ji. Multimodal emotion-cause pair extraction with holistic interaction and label constraint.ACM Transactions on Multimedia Computing, Communications, and Applications, 21(11):307:1–307:19,
-
[4]
Yuwei Wang, Yuling Li, Kui Yu, and Jing Yang
doi:10.1016/J.ESW A.2023.121386. Yuwei Wang, Yuling Li, Kui Yu, and Jing Yang. A semantic structure-based emotion-guided model for emotion-cause pair extraction.Pattern Recognition, 161:111296,
-
[5]
Xincheng Ju, Dong Zhang, Junhui Li, Shoushan Li, and Guodong Zhou
doi:10.1016/J.PATCOG.2024.111296. Xincheng Ju, Dong Zhang, Junhui Li, Shoushan Li, and Guodong Zhou. Enhanced generative framework with LLMs for multimodal emotion-cause pair extraction in conversations.IEEE Transactions on Multimedia, 27:4924–4935,
-
[6]
Qiao Liang, Ying Shen, Tiantian Chen, and Lin Zhang
doi:10.1109/TAFFC.2024.3446646. Qiao Liang, Ying Shen, Tiantian Chen, and Lin Zhang. M 3HG: Multimodal, multi-scale, and multi-type node heterogeneous graph for emotion cause triplet extraction in conversations. InFindings of the Association for Computational Linguistics: ACL 2025, pages 11416–11431,
-
[7]
Generative emotion cause triplet extraction in conversations with commonsense knowledge
Fanfan Wang, Jianfei Yu, and Rui Xia. Generative emotion cause triplet extraction in conversations with commonsense knowledge. InFindings of the Association for Computational Linguistics: EMNLP 2023, pages 3952–3963, 2023b. Zhaoxin Yu, Xinglin Xiao, and Wenji Mao. One unified model for diverse tasks: Emotion cause analysis via self- promote cognitive stru...
-
[8]
Meng Luo, Han Zhang, Shengqiong Wu, Bobo Li, Hong Han, and Hao Fei
doi:10.18653/V1/2024.SEMEV AL-1.97. Meng Luo, Han Zhang, Shengqiong Wu, Bobo Li, Hong Han, and Hao Fei. NUS-emo at SemEval-2024 task 3: Instruction-tuning LLM for multimodal emotion-cause analysis in conversations. In Atul Kr. Ojha, A. Seza Do ˘gruöz, Harish Tayyar Madabushi, Giovanni Da San Martino, Sara Rosenthal, and Aiala Rosá, editors,Proceedings of ...
-
[9]
doi:10.18653/v1/2024.semeval-1.226
Association for Computational Linguistics. doi:10.18653/v1/2024.semeval-1.226. Fanfan Wang, Heqing Ma, Xiangqing Shen, Jianfei Yu, and Rui Xia. Observe before generate: Emotion-cause aware video caption for multimodal emotion cause generation in conversations. In Jianfei Cai, Mohan S. Kankan- halli, Balakrishnan Prabhakaran, Susanne Boll, Ramanathan Subra...
-
[10]
doi:10.18653/v1/2023.acl-long.62
Association for Computational Linguistics. doi:10.18653/v1/2023.acl-long.62. Guimin Hu, Yi Zhao, and Guangming Lu. Unifying emotion-oriented and cause-oriented predictions for emotion-cause pair extraction.Neural Networks, 178:106431, 2024b. doi:10.1016/J.NEUNET.2024.106431. Guimin Hu, Yi Zhao, and Guangming Lu. Improving representation with hierarchical ...
-
[11]
Jincheng Huang, Jie Xu, Xiaoshuang Shi, Ping Hu, Lei Feng, and Xiaofeng Zhu
doi:10.1109/TAFFC.2024.3390223. Jincheng Huang, Jie Xu, Xiaoshuang Shi, Ping Hu, Lei Feng, and Xiaofeng Zhu. Revisiting confidence calibration for misclassification detection in VLMs. InInternational Conference on Learning Representations,
-
[12]
RoBERTa: A robustly optimized BERT pretraining approach.CoRR, abs/1907.11692,
Yinhan Liu, Myle Ott, Naman Goyal, Jingfei Du, Mandar Joshi, Danqi Chen, Omer Levy, Mike Lewis, Luke Zettlemoyer, and Veselin Stoyanov. RoBERTa: A robustly optimized BERT pretraining approach.CoRR, abs/1907.11692,
Pith/arXiv arXiv 1907
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.