Physics-IQ Verified
Pith reviewed 2026-06-26 21:12 UTC · model grok-4.3
The pith
Refining prompts, ground-truth videos, and scoring in the Physics-IQ benchmark produces a more reliable measure of physical understanding in video generative models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By improving prompt and ground-truth quality to reduce the influence of confounding factors and introducing a sample-level scoring system that weights each sample and metric equally, the benchmark provides a more faithful signal of physical understanding, as shown by the fact that 57.6 percent of samples are refined and model rankings change with Kendall's tau of 0.46.
What carries the argument
The sample-level scoring system that assigns equal weight to each sample and each metric.
If this is right
- Improved prompt and ground-truth quality reduces the effect of non-physical factors on scores.
- Equal weighting across samples and metrics produces rankings that more closely reflect physical understanding.
- Moderate ranking changes indicate that earlier evaluations may have been distorted by confounding factors.
- The updated benchmark supplies a clearer signal for developing video generative models that capture physical reality.
Where Pith is reading between the lines
- Models previously tuned to the original benchmark may need re-training or re-testing under the verified version.
- Similar audit-and-refine steps could be applied to other video or world-modeling benchmarks.
- Downstream tasks that rely on video models as world simulators may see different performance once the benchmark is updated.
Load-bearing premise
The revisions to prompts and ground-truth videos together with equal-weight sample-level scoring actually reduce confounding factors instead of merely changing which models score highest.
What would settle it
Re-evaluate the six image-to-video models on both the original and verified benchmarks using additional held-out real-world physical experiments and check whether ranking changes persist or disappear.
Figures



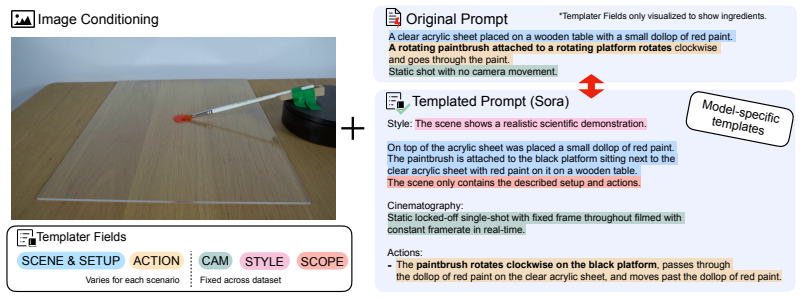














read the original abstract
Video generative models ( VGMs) have become a new frontier that can be used not just for video generation but for a multitude of downstream tasks, including world modeling. To advance these tasks, a good video model must understand the physical reality of the world. Evaluating this understanding is an emerging field and has led to the Physics-IQ benchmark, which quantifies this explicitly by comparing model-generated videos to real-world videos of physical experiments. In this work, we present a systematic audit of the Physics-IQ benchmark, expose shortcomings and propose three solutions that sharpen how we can measure physical understanding of VGMs. Specifically, we improve prompt and ground-truth quality to reduce the influence of confounding factors and further introduce a sample-level scoring system that weights each sample and metric equally. Our resulting benchmark, Physics-IQ Verified, refines 57.6\% of all samples and improves over 34.8\% of prompts. In a comparison study using six image-to-video generative models, we observe moderate but meaningful ranking changes (Kendall's $\tau = 0.46$). We hope Physics-IQ Verified advances the community by providing a more reliable signal toward physically accurate VGMs. The code for the benchmark can be accessed at https://github.com/google-deepmind/physics-iq-benchmark
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents an audit of the Physics-IQ benchmark for measuring physical understanding in video generative models. It identifies issues with prompt and ground-truth quality that introduce confounding factors, proposes three solutions including prompt/GT revisions and a new sample-level equal-weight scoring system, reports that the updated benchmark refines 57.6% of samples and improves 34.8% of prompts, and shows moderate ranking shifts (Kendall's τ = 0.46) across six image-to-video models. The revised benchmark and code are released publicly.
Significance. If the revisions and scoring changes demonstrably reduce confounding and yield a more faithful measure of physical understanding, the work would strengthen evaluation practices for world-modeling capabilities in VGMs. The public code release is a clear strength that supports reproducibility and community follow-up.
major comments (2)
- [Abstract] Abstract: The central claim that the revisions produce 'a more reliable signal' rests on the reported refinements (57.6% samples, 34.8% prompts) and ranking change (Kendall's τ = 0.46), yet no derivation, criteria for identifying confounding factors, or error bars are supplied. This absence directly undermines assessment of whether the changes improve measurement fidelity.
- [Abstract] Comparison study (abstract): The only quantitative support offered for reduced confounding is the moderate ranking shift across six models. No external validation criterion—such as correlation with expert-labeled physics violations or held-out real-world physical accuracy—is reported, leaving open the possibility that the new metric simply reshuffles scores without increasing faithfulness.
minor comments (1)
- [Abstract] Abstract: The Kendall's τ value is given without the number of models or ties considered; adding this context would improve interpretability of the reported ranking changes.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on the abstract's claims. We address the two major comments below regarding justification of refinements and external validation. We will revise the abstract to better qualify our statements without overstating the results.
read point-by-point responses
-
Referee: [Abstract] Abstract: The central claim that the revisions produce 'a more reliable signal' rests on the reported refinements (57.6% samples, 34.8% prompts) and ranking change (Kendall's τ = 0.46), yet no derivation, criteria for identifying confounding factors, or error bars are supplied. This absence directly undermines assessment of whether the changes improve measurement fidelity.
Authors: The abstract is intentionally concise, but we agree it lacks explicit criteria and error bars. Section 3 of the manuscript details the audit criteria (e.g., prompt ambiguity, mismatched ground-truth physics, and metric inconsistencies) used to identify confounding factors through systematic review. We will revise the abstract to briefly summarize these criteria and add that ranking shifts are computed across six models without claiming statistical significance via error bars, as the focus is on observed changes rather than inference. revision: yes
-
Referee: [Abstract] Comparison study (abstract): The only quantitative support offered for reduced confounding is the moderate ranking shift across six models. No external validation criterion—such as correlation with expert-labeled physics violations or held-out real-world physical accuracy—is reported, leaving open the possibility that the new metric simply reshuffles scores without increasing faithfulness.
Authors: We agree that the Kendall's τ = 0.46 ranking shift alone does not constitute external validation of improved fidelity to physical understanding. The manuscript does not report correlations with expert labels or held-out real-world accuracy, as this work is an audit and refinement of the existing benchmark rather than a new validation study. We will revise the abstract to remove the phrase 'more reliable signal' and instead describe the outcome as 'refined benchmark with moderate ranking shifts,' accurately reflecting the evidence provided. revision: yes
- No external validation (e.g., expert-labeled physics violations or real-world accuracy correlation) is available in the current work to directly confirm reduced confounding.
Circularity Check
No circularity: empirical benchmark audit with direct revisions, no equations or self-referential derivations
full rationale
The paper performs a manual audit of the existing Physics-IQ benchmark and applies direct revisions to prompts, ground-truth videos, and scoring (sample-level equal weighting). It reports the fraction of samples refined (57.6%) and prompts improved (34.8%), plus an observed Kendall τ ranking shift across six models. No equations, fitted parameters, predictions derived from prior outputs, or load-bearing self-citations appear in the provided text. The central claim rests on the explicit changes made rather than any reduction to the paper's own inputs by construction, making the work self-contained as an empirical refinement effort.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The original Physics-IQ benchmark contains confounding factors in prompts and ground-truth videos that can be systematically identified and corrected.
Reference graph
Works this paper leans on
-
[1]
Do generative video mod- els understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
Saman Motamed, Laura Culp, Kevin Swersky, Priyank Jaini, and Robert Geirhos. Do generative video mod- els understand physical principles? InProceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 948–958, 2026
2026
-
[2]
Jürgen Schmidhuber.Making the world differentiable: on using self supervised fully recurrent neural networks for dynamic reinforcement learning and planning in non-stationary environments, volume 126. Inst. für Informatik, 1990
1990
-
[3]
A path towards autonomous machine intelligence version 0.9
Yann LeCun et al. A path towards autonomous machine intelligence version 0.9. 2, 2022-06-27.Open Review, 62(1):1–62, 2022
2022
-
[4]
Genie: Generative interactive environments
Jake Bruce, Michael D Dennis, Ashley Edwards, Jack Parker-Holder, Yuge Shi, Edward Hughes, Matthew Lai, Aditi Mavalankar, Richie Steigerwald, Chris Apps, et al. Genie: Generative interactive environments. InForty-first International Conference on Machine Learning, 2024
2024
-
[5]
Dreamgen: Unlocking generalization in robot learning through video world models
Joel Jang, Seonghyeon Ye, Zongyu Lin, Jiannan Xiang, Johan Bjorck, Yu Fang, Fengyuan Hu, Spencer Huang, Kaushil Kundalia, Yen-Chen Lin, et al. Dreamgen: Unlocking generalization in robot learning through video world models. InConference on Robot Learning, pages 5170–5194. PMLR, 2025
2025
-
[6]
Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025
Thaddäus Wiedemer, Yuxuan Li, Paul Vicol, Shixiang Shane Gu, Nick Matarese, Kevin Swersky, Been Kim, Priyank Jaini, and Robert Geirhos. Video models are zero-shot learners and reasoners.arXiv preprint arXiv:2509.20328, 2025
Pith/arXiv arXiv 2025
-
[7]
World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
David Ha and Jürgen Schmidhuber. World models.arXiv preprint arXiv:1803.10122, 2(3):440, 2018
Pith/arXiv arXiv 2018
-
[8]
FVD: A new metric for video generation, 2019
Thomas Unterthiner, Sjoerd van Steenkiste, Karol Kurach, Raphaël Marinier, Marcin Michalski, and Sylvain Gelly. FVD: A new metric for video generation, 2019. URL https://openreview.net/ forum?id=rylgEULtdN
2019
-
[9]
Jiahe Liu, Youran Qu, Qi Yan, Xiaohui Zeng, Lele Wang, and Renjie Liao. Fr \’echet video motion distance: A metric for evaluating motion consistency in videos.arXiv preprint arXiv:2407.16124, 2024
arXiv 2024
-
[10]
A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026
Maijunxian Wang, Ruisi Wang, Juyi Lin, Ran Ji, Thaddäus Wiedemer, Qingying Gao, Dezhi Luo, Yaoyao Qian, Lianyu Huang, Zelong Hong, et al. A very big video reasoning suite.arXiv preprint arXiv:2602.20159, 2026
arXiv 2026
-
[11]
Daniel M Bear, Elias Wang, Damian Mrowca, Felix J Binder, Hsiao-Yu Fish Tung, RT Pramod, Cameron Holdaway, Sirui Tao, Kevin Smith, Fan-Yun Sun, et al. Physion: Evaluating physical prediction from vision in humans and machines.arXiv preprint arXiv:2106.08261, 2021
arXiv 2021
-
[12]
Hsiao-Yu Tung, Mingyu Ding, Zhenfang Chen, Daniel Bear, Chuang Gan, Josh Tenenbaum, Dan Yamins, Judith Fan, and Kevin Smith. Physion++: Evaluating physical scene understanding that requires online inference of different physical properties.Advances in Neural Information Processing Systems, 36: 67048–67068, 2023
2023
-
[13]
Craft: A benchmark for causal reasoning about forces and interactions
Tayfun Ates, M Ate¸ so˘glu, Ça ˘gatay Yi˘git, Ilker Kesen, Mert Kobas, Erkut Erdem, Aykut Erdem, Tilbe Goksun, and Deniz Yuret. Craft: A benchmark for causal reasoning about forces and interactions. In Findings of the Association for Computational Linguistics: ACL 2022, pages 2602–2627, 2022. 10
2022
-
[14]
Ronan Riochet, Mario Ynocente Castro, Mathieu Bernard, Adam Lerer, Rob Fergus, Véronique Izard, and Emmanuel Dupoux. Intphys: A framework and benchmark for visual intuitive physics reasoning.arXiv preprint arXiv:1803.07616, 2018
arXiv 2018
-
[15]
Cophy: Counterfactual learning of physical dynamics.arXiv preprint arXiv:1909.12000, 2019
Fabien Baradel, Natalia Neverova, Julien Mille, Greg Mori, and Christian Wolf. Cophy: Counterfactual learning of physical dynamics.arXiv preprint arXiv:1909.12000, 2019
arXiv 1909
-
[16]
Kexin Yi, Chuang Gan, Yunzhu Li, Pushmeet Kohli, Jiajun Wu, Antonio Torralba, and Joshua B Tenenbaum. Clevrer: Collision events for video representation and reasoning.arXiv preprint arXiv:1910.01442, 2019
Pith/arXiv arXiv 1910
-
[17]
Esprit: Explaining solutions to physical reasoning tasks
Nazneen Fatema Rajani, Rui Zhang, Yi Chern Tan, Stephan Zheng, Jeremy Weiss, Aadit Vyas, Abhijit Gupta, Caiming Xiong, Richard Socher, and Dragomir Radev. Esprit: Explaining solutions to physical reasoning tasks. InProceedings of the 58th Annual Meeting of the Association for Computational Linguistics, pages 7906–7917, 2020
2020
-
[18]
Bingyi Kang, Yang Yue, Rui Lu, Zhijie Lin, Yang Zhao, Kaixin Wang, Gao Huang, and Jiashi Feng. How far is video generation from world model: A physical law perspective.arXiv preprint arXiv:2411.02385, 2024
Pith/arXiv arXiv 2024
-
[19]
Phyre: A new benchmark for physical reasoning.Advances in Neural Information Processing Systems, 32, 2019
Anton Bakhtin, Laurens van der Maaten, Justin Johnson, Laura Gustafson, and Ross Girshick. Phyre: A new benchmark for physical reasoning.Advances in Neural Information Processing Systems, 32, 2019
2019
-
[20]
Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Niket Agarwal, Arslan Ali, Maciej Bala, Yogesh Balaji, Erik Barker, Tiffany Cai, Prithvijit Chattopadhyay, Yongxin Chen, Yin Cui, Yifan Ding, et al. Cosmos world foundation model platform for physical ai.arXiv preprint arXiv:2501.03575, 2025
Pith/arXiv arXiv 2025
-
[21]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Improving the physics of video generation with vjepa-2 reward signal.arXiv preprint arXiv:2510.21840, 2025
arXiv 2025
-
[22]
Jianhao Yuan, Xiaofeng Zhang, Felix Friedrich, Nicolas Beltran-Velez, Melissa Hall, Reyhane Askari- Hemmat, Xiaochuang Han, Nicolas Ballas, Michal Drozdzal, and Adriana Romero-Soriano. Inference-time physics alignment of video generative models with latent world models.arXiv preprint arXiv:2601.10553, 2026
arXiv 2026
-
[23]
Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Hansi Teng, Hongyu Jia, Lei Sun, Lingzhi Li, Maolin Li, Mingqiu Tang, Shuai Han, Tianning Zhang, WQ Zhang, Weifeng Luo, et al. Magi-1: Autoregressive video generation at scale.arXiv preprint arXiv:2505.13211, 2025
Pith/arXiv arXiv 2025
-
[24]
Sora 2 system card openai september 30, 2025 1, Sep 2025
Open AI. Sora 2 system card openai september 30, 2025 1, Sep 2025. URL https://cdn.openai.com/ pdf/50d5973c-c4ff-4c2d-986f-c72b5d0ff069/sora_2_system_card.pdf
2025
-
[25]
Video-gpt via next clip diffusion.arXiv preprint arXiv:2505.12489, 2025
Shaobin Zhuang, Zhipeng Huang, Ying Zhang, Fangyikang Wang, Canmiao Fu, Binxin Yang, Chong Sun, Chen Li, and Yali Wang. Video-gpt via next clip diffusion.arXiv preprint arXiv:2505.12489, 2025
arXiv 2025
-
[26]
Yang Liu, Xilin Zhao, Peisong Wen, Siran Dai, and Qingming Huang. Bootstrapping physics-grounded video generation through vlm-guided iterative self-refinement.arXiv preprint arXiv:2511.20280, 2025
arXiv 2025
-
[27]
Haoran Lu, Shang Wu, Jianshu Zhang, Maojiang Su, Guo Ye, Chenwei Xu, Lie Lu, Pranav Maneriker, Fan Du, Manling Li, et al. Phys4d: Fine-grained physics-consistent 4d modeling from video diffusion.arXiv preprint arXiv:2603.03485, 2026
Pith/arXiv arXiv 2026
-
[28]
VideoPhy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
Hritik Bansal, Zongyu Lin, Tianyi Xie, Zeshun Zong, Michal Yarom, Yonatan Bitton, Chenfanfu Jiang, Yizhou Sun, Kai-Wei Chang, and Aditya Grover. VideoPhy: Evaluating physical commonsense for video generation.arXiv preprint arXiv:2406.03520, 2024
Pith/arXiv arXiv 2024
-
[29]
Fanqing Meng, Jiaqi Liao, Xinyu Tan, Wenqi Shao, Quanfeng Lu, Kaipeng Zhang, Yu Cheng, Dianqi Li, Yu Qiao, and Ping Luo. Towards world simulator: Crafting physical commonsense-based benchmark for video generation.arXiv preprint arXiv:2410.05363, 2024
Pith/arXiv arXiv 2024
-
[30]
Language models are not naysayers: an analysis of language models on negation benchmarks
Thinh Hung Truong, Timothy Baldwin, Karin Verspoor, and Trevor Cohn. Language models are not naysayers: an analysis of language models on negation benchmarks. InProceedings of the 12th Joint Conference on Lexical and Computational Semantics (* SEM 2023), pages 101–114, 2023
2023
-
[31]
This is not a dataset: A large negation benchmark to challenge large language models
Iker García-Ferrero, Begoña Altuna, Javier Alvez, Itziar Gonzalez-Dios, and German Rigau. This is not a dataset: A large negation benchmark to challenge large language models. InProceedings of the 2023 conference on empirical methods in natural language processing, pages 8596–8615, 2023. 11
2023
-
[32]
Valse: A task-independent benchmark for vision and language models centered on linguistic phenomena
Letitia Parcalabescu, Michele Cafagna, Lilitta Muradjan, Anette Frank, Iacer Calixto, and Albert Gatt. Valse: A task-independent benchmark for vision and language models centered on linguistic phenomena. InProceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 8253–8280, 2022
2022
-
[33]
Vision-language models do not understand negation
Kumail Alhamoud, Shaden Alshammari, Yonglong Tian, Guohao Li, Philip HS Torr, Yoon Kim, and Marzyeh Ghassemi. Vision-language models do not understand negation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 29612–29622, 2025
2025
-
[34]
Colin Conwell, Rupert Tawiah-Quashie, and Tomer Ullman. Relations, negations, and numbers: Looking for logic in generative text-to-image models.arXiv preprint arXiv:2411.17066, 2024
arXiv 2024
-
[35]
Team Wan, Ang Wang, Baole Ai, Bin Wen, Chaojie Mao, Chen-Wei Xie, Di Chen, Feiwu Yu, Haiming Zhao, Jianxiao Yang, et al. Wan: Open and advanced large-scale video generative models.arXiv preprint arXiv:2503.20314, Accessed: 2026-04-29, 2025
Pith/arXiv arXiv 2026
-
[36]
Weijie Kong, Qi Tian, Zijian Zhang, Rox Min, Zuozhuo Dai, Jin Zhou, Jiangfeng Xiong, Xin Li, Bo Wu, Jianwei Zhang, et al. Hunyuanvideo: A systematic framework for large video generative models.arXiv preprint arXiv:2412.03603, Accessed: 2026-04-29, 2024
Pith/arXiv arXiv 2026
-
[37]
Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
Niket Agarwal, Arslan Ali, Jon Allen, Martin Antolini, Adeline Aubame, Alisson Azzolini, Junjie Bai, Maciej Bala, Yogesh Balaji, Josh Bapst, et al. Cosmos 3: Omnimodal world models for physical ai.arXiv preprint arXiv:2606.02800, 2026
Pith/arXiv arXiv 2026
-
[38]
URL https://www.pruna.ai/
Efficient machine learning with pruna, 2023. URL https://www.pruna.ai/. Software available from pruna.ai, Accessed: 2026-04-29
2023
-
[39]
Grok Imagine API: State-of-the-art video generation across quality, cost, and latency
xAI. Grok Imagine API: State-of-the-art video generation across quality, cost, and latency. https: //x.ai/news/grok-imagine-api, 2026. Accessed: 2026-04-29
2026
-
[40]
The treatment of ties in ranking problems.Biometrika, 33(3):239–251, 1945
Maurice G Kendall. The treatment of ties in ranking problems.Biometrika, 33(3):239–251, 1945
1945
-
[41]
The proof and measurement of association between two things
Charles Spearman. The proof and measurement of association between two things. 1961
1961
-
[42]
Lawrence Erlbaum Associates, Inc, 1977
Jacob Cohen.Statistical power analysis for the behavioral sciences, Rev. Lawrence Erlbaum Associates, Inc, 1977
1977
-
[43]
Individual comparisons by ranking methods.Biometrics bulletin, 1(6):80–83, 1945
Frank Wilcoxon. Individual comparisons by ranking methods.Biometrics bulletin, 1(6):80–83, 1945
1945
-
[44]
Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
Janez Demšar. Statistical comparisons of classifiers over multiple data sets.Journal of Machine learning research, 7(Jan):1–30, 2006
2006
-
[45]
Paradoxical effects of thought suppression.Journal of personality and social psychology, 53(1):5, 1987
Daniel M Wegner, David J Schneider, Samuel R Carter, and Teri L White. Paradoxical effects of thought suppression.Journal of personality and social psychology, 53(1):5, 1987
1987
-
[46]
Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation
Qiyao Xue, Xiangyu Yin, Boyuan Yang, and Wei Gao. Phyt2v: Llm-guided iterative self-refinement for physics-grounded text-to-video generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 18826–18836, 2025
2025
-
[47]
VBench: Comprehensive benchmark suite for video generative models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench: Comprehensive benchmark suite for video generative models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recogniti...
2024
-
[48]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, and Ziwei Liu. VBench++: Comprehensive and versatile benchmark suite for video generative models.arXiv preprint arXiv:2411.13503, 2024
arXiv 2024
-
[49]
EvalCrafter: Benchmarking and evaluating large video generation models
Yaofang Liu, Xiaodong Cun, Xuebo Liu, Xintao Wang, Yong Zhang, Haoxin Chen, Yang Liu, Tieyong Zeng, Raymond Chan, and Ying Shan. EvalCrafter: Benchmarking and evaluating large video generation models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2024
2024
-
[50]
Dian Zheng, Ziqi Huang, Hongbo Liu, Kai Zou, Yinan He, Fan Zhang, Yuanhan Zhang, Jingwen He, Wei-Shi Zheng, Yu Qiao, and Ziwei Liu. VBench-2.0: Advancing video generation benchmark suite for intrinsic faithfulness.arXiv preprint arXiv:2503.21755, 2025. 12
Pith/arXiv arXiv 2025
-
[51]
Zihan Wang, Songlin Li, Lingyan Hao, Xinyu Hu, and Bowen Song. What you see is what matters: A novel visual and physics-based metric for evaluating video generation quality.arXiv preprint arXiv:2411.13609, 2024
arXiv 2024
-
[52]
Static shot with no camera movement
Chenyu Zhang, Daniil Cherniavskii, Antonios Tragoudaras, Antonios V ozikis, Thijmen Nijdam, Derck WE Prinzhorn, Mark Bodracska, Nicu Sebe, Andrii Zadaianchuk, and Efstratios Gavves. Morpheus: Bench- marking physical reasoning of video generative models with real physical experiments.arXiv preprint arXiv:2504.02918, 2025. 13 Appendix Table of Contents A Pr...
arXiv 2025
-
[53]
Guidelines: • The answer [N/A] means that the paper does not involve crowdsourcing nor research with human subjects
Institutional review board (IRB) approvals or equivalent for research with human subjects Question: Does the paper describe potential risks incurred by study participants, whether such risks were disclosed to the subjects, and whether Institutional Review Board (IRB) approvals (or an equivalent approval/review based on the requirements of your country or ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.