Visual-OPSD: Cross-Modal On-Policy Self-Distillation for Efficient Unified Multimodal Reasoning
Pith reviewed 2026-06-26 21:45 UTC · model grok-4.3
The pith
Self-distillation from visual-thought generation paths yields a text-only model that beats its expensive teacher while running 14 times faster.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
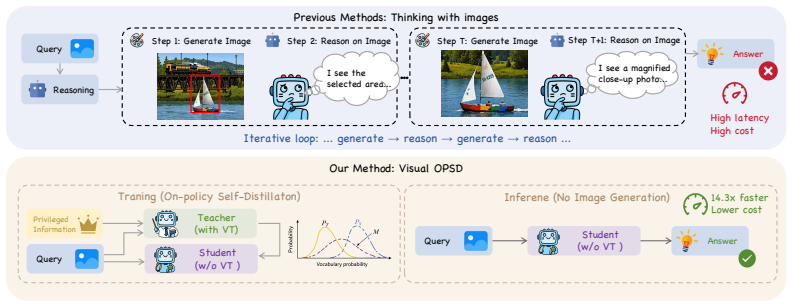
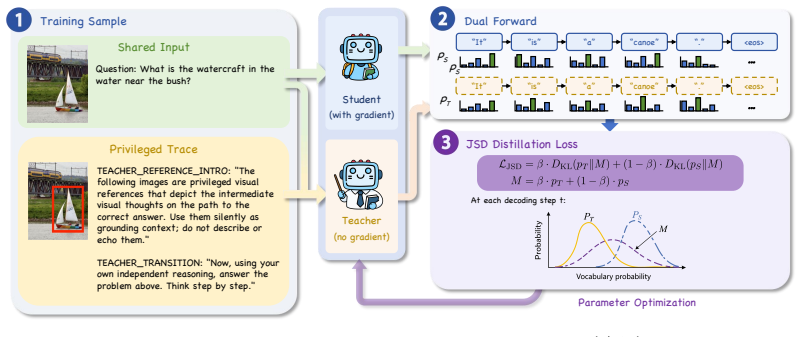
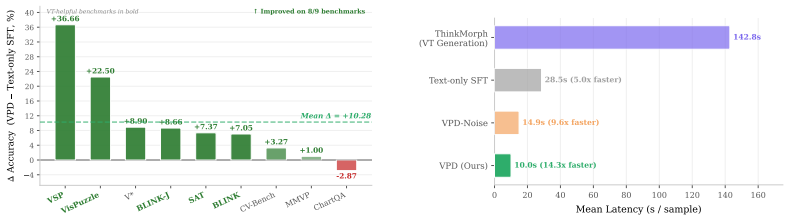
The generation pathway for visual thoughts encodes transferable reasoning information beyond the pixels that appear in the final image. Token-level Jensen-Shannon divergence distillation performed on-policy, with the teacher conditioned on privileged visual thoughts and the student seeing only the question, transfers this information so that a weight-shared student model outperforms the original generative teacher while eliminating the multi-step diffusion cost.
What carries the argument
Visual-OPSD, a cross-modal on-policy self-distillation procedure that aligns the student's next-token distribution to a teacher that receives the full visual-thought trace.
If this is right
- The distilled model improves accuracy by 3.40 percentage points over its generative teacher while delivering a 14.3 times speedup in inference time.
- It outperforms same-scale vision-language models by 63.83 percentage points on the VSP benchmark.
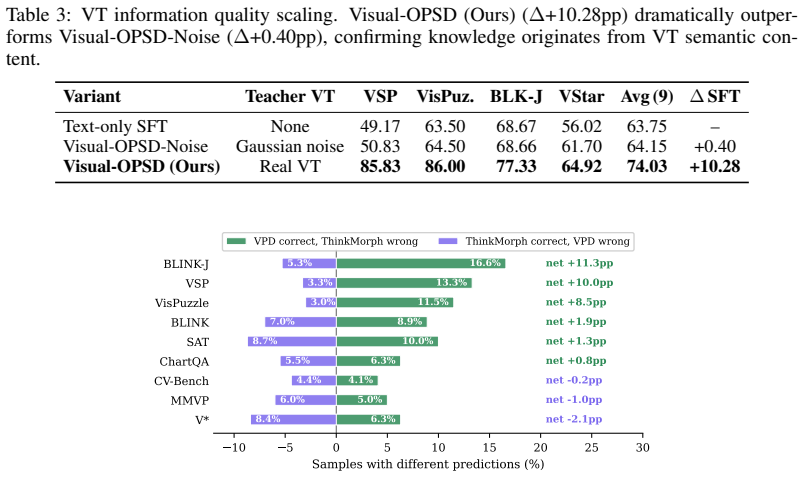
- A Gaussian-noise control yields only +0.40 pp while real visual thoughts yield +10.28 pp, confirming that gains arise from semantic content rather than the rendered image.
- The method closes 58.4 percent of the KL gap between student and teacher distributions.
Where Pith is reading between the lines
- The separation between the value of the generation process and the value of the rendered output may apply to other intermediate generation steps in multimodal systems.
- On-policy distillation could be tested with non-diffusion generators to check whether the same transfer works when the teacher uses different mechanisms.
- The approach suggests that expensive privileged context can be converted into permanent efficiency gains for deployment on resource-limited hardware.
Load-bearing premise
The privileged visual-thought trace contains reasoning information that differs from what the student sees and can be captured by matching token-level output distributions on the student's own generation trajectories.
What would settle it
If training the student with Gaussian-noised visual thoughts instead of real ones produces accuracy gains comparable to the reported +10.28 pp, the claim that semantic content of the generation pathway drives the improvement would be falsified.
Figures








read the original abstract
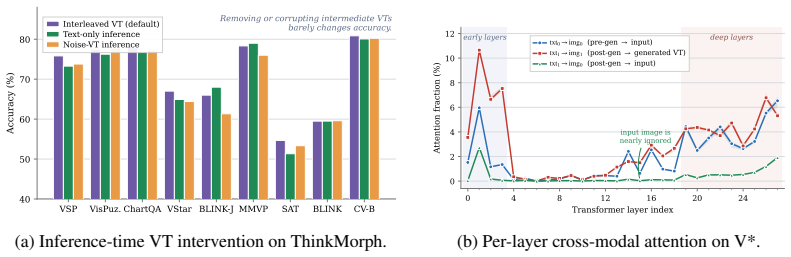
Unified multimodal models (UMMs) interleave generated ''visual thoughts'' (VTs) with text reasoning to improve spatial tasks. This incurs roughly an order-of-magnitude inference cost from multi-step diffusion. We find this cost yields limited direct benefit. On ThinkMorph, removing or noising VTs barely changes accuracy across nine benchmarks. Once rendered, attention concentrates on the VT regardless of content. Yet a KL diagnostic shows that conditioning on a privileged VT trace shifts the model's completion distribution. This suggests the generation pathway encodes useful reasoning beyond the rendered pixels. Motivated by this gap, we propose Visual On-Policy Self-Distillation(Visual-OPSD). Teacher and student share identical weights but differ in context: the teacher sees privileged VTs while the student sees only the question. Token-level JSD distillation on on-policy student trajectories transfers the teacher's reasoning to a text-only student. Across nine benchmarks, Visual-OPSD improves over its generative teacher by $+3.40$pp with $14.3\times$ speedup (10.0s vs. 142.8s per sample) and outperforms same-scale VLMs by $+63.83$pp on VSP. A Gaussian-noise control ($+0.40$pp vs. $+10.28$pp for real VTs) and $58.4\%$ closure of the KL gap confirm that gains come from the semantic content of the generation pathway.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces Visual-OPSD, a cross-modal on-policy self-distillation method for unified multimodal models that generate visual thoughts (VTs). A teacher model conditioned on privileged VTs distills via token-level Jensen-Shannon Divergence to a weight-shared student that receives only the question, using trajectories sampled from the student policy. This is motivated by a KL diagnostic showing distribution shift despite limited accuracy benefit from rendered VTs (removing/noising VTs barely changes accuracy; attention focuses on VTs regardless of content). Results across nine benchmarks report +3.40pp over the generative teacher, 14.3× speedup (10.0s vs. 142.8s), +63.83pp over same-scale VLMs on VSP, with a Gaussian-noise control (+0.40pp vs. +10.28pp) and 58.4% KL-gap closure.
Significance. If the result holds, the work demonstrates a practical route to retain reasoning gains from expensive multimodal generation while achieving text-only inference speed. The concrete deltas, speedup, on-policy setup, and two controls (noise ablation, KL closure) are strengths that support attribution to semantic content rather than artifacts.
major comments (2)
- [Abstract / Motivation] Abstract / Motivation section: The KL diagnostic establishes a distribution shift under privileged VT conditioning, yet the manuscript does not directly test whether this shift encodes transferable task-relevant reasoning that token-level JSD on on-policy student trajectories can capture. The Gaussian-noise control and KL-closure statistic address part of the concern but leave open the possibility that observed gains (+3.40pp) arise from generic regularization if student trajectories do not overlap with regions where VT conditioning supplies useful spatial-inference steps.
- [Experiments] Experiments (nine-benchmark evaluation): The reported +3.40pp gain and +63.83pp on VSP are concrete, but the abstract provides no details on benchmark construction for ThinkMorph, statistical testing (variance across runs, significance), or exact training procedure (e.g., how on-policy trajectories are collected and how many steps), which are load-bearing for assessing whether the gains are robust or post-hoc.
minor comments (2)
- The abstract could explicitly define 'on-policy student trajectories' and contrast them with standard off-policy distillation to clarify the contribution.
- Notation for JSD and the precise form of the distillation loss should be stated in the main text rather than assumed from the abstract.
Simulated Author's Rebuttal
We thank the referee for the constructive report and positive assessment of the work's significance. We address the two major comments point by point below, providing clarifications and indicating where revisions will be made.
read point-by-point responses
-
Referee: [Abstract / Motivation] Abstract / Motivation section: The KL diagnostic establishes a distribution shift under privileged VT conditioning, yet the manuscript does not directly test whether this shift encodes transferable task-relevant reasoning that token-level JSD on on-policy student trajectories can capture. The Gaussian-noise control and KL-closure statistic address part of the concern but leave open the possibility that observed gains (+3.40pp) arise from generic regularization if student trajectories do not overlap with regions where VT conditioning supplies useful spatial-inference steps.
Authors: We agree that an experiment directly isolating whether JSD transfers specific spatial-inference steps (rather than generic regularization) would be stronger evidence. However, the on-policy sampling from the student policy ensures distillation occurs precisely on the trajectories being optimized, and the controls provide supporting evidence: Gaussian noise yields only +0.40pp while real VTs yield +10.28pp, and the 58.4% KL-gap closure shows alignment with the privileged distribution. These results make generic regularization unlikely as the source of the +3.40pp gain. We will add a paragraph in the motivation section explicitly addressing this alternative explanation and its relation to the on-policy setup. revision: partial
-
Referee: [Experiments] Experiments (nine-benchmark evaluation): The reported +3.40pp gain and +63.83pp on VSP are concrete, but the abstract provides no details on benchmark construction for ThinkMorph, statistical testing (variance across runs, significance), or exact training procedure (e.g., how on-policy trajectories are collected and how many steps), which are load-bearing for assessing whether the gains are robust or post-hoc.
Authors: The abstract is space-constrained, but full details appear in the main text: ThinkMorph benchmark construction is described in Section 4.1, the on-policy trajectory collection process and step counts are specified in Section 3.2 along with Algorithm 1, and the overall training procedure is in the experimental setup subsection. We did not report variance across multiple random seeds or statistical significance tests in the submitted version. We will include these in the revision (standard deviations and, where feasible, significance levels) to demonstrate robustness. revision: yes
Circularity Check
No significant circularity; method and claims are empirically grounded
full rationale
The paper motivates Visual-OPSD from an observed KL shift between VT-conditioned and question-only distributions, then defines the teacher-student JSD distillation procedure on on-policy trajectories as an independent algorithmic choice. Reported gains (+3.40 pp, KL closure, controls) are measured outcomes on held-out benchmarks rather than quantities that reduce to the inputs by construction. No equations equate a fitted parameter to a claimed prediction, no self-citation chain is load-bearing for the core premise, and the Gaussian-noise control is an external falsification step. The derivation chain remains self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Privileged visual thought trace encodes transferable reasoning information beyond rendered pixels
Reference graph
Works this paper leans on
-
[1]
arXiv preprint arXiv:2510.27492 , year=
ThinkMorph: Interleaved Thinking and Visual Generation for Multimodal Reasoning , author=. arXiv preprint arXiv:2510.27492 , year=
-
[2]
arXiv preprint arXiv:2505.14683 , year=
Emerging properties in unified multimodal pretraining , author=. arXiv preprint arXiv:2505.14683 , year=
-
[3]
arXiv preprint arXiv:2405.09818 , year=
Chameleon: Mixed-Modal Early-Fusion Foundation Models , author=. arXiv preprint arXiv:2405.09818 , year=
-
[4]
arXiv preprint arXiv:2409.18869 , year=
Emu3: Next-Token Prediction is All You Need , author=. arXiv preprint arXiv:2409.18869 , year=
-
[5]
arXiv preprint arXiv:2410.13848 , year=
Janus: Decoupling Visual Encoding for Unified Multimodal Understanding and Generation , author=. arXiv preprint arXiv:2410.13848 , year=
-
[6]
arXiv preprint arXiv:2408.11039 , year=
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model , author=. arXiv preprint arXiv:2408.11039 , year=
-
[7]
arXiv preprint arXiv:2305.02317 , year=
Visual Chain of Thought: Bridging Logical Gaps with Multimodal Infillings , author=. arXiv preprint arXiv:2305.02317 , year=
-
[8]
arXiv preprint arXiv:2302.00923 , year=
Multimodal Chain-of-Thought Reasoning in Language Models , author=. arXiv preprint arXiv:2302.00923 , year=
-
[9]
arXiv preprint arXiv:2406.09403 , year=
Visual Sketchpad: Sketching as a Visual Chain of Thought for Multimodal Language Models , author=. arXiv preprint arXiv:2406.09403 , year=
-
[10]
arXiv preprint arXiv:1503.02531 , year=
Distilling the Knowledge in a Neural Network , author=. arXiv preprint arXiv:1503.02531 , year=
-
[11]
International Conference on Machine Learning , pages=
Born Again Neural Networks , author=. International Conference on Machine Learning , pages=
-
[12]
Advances in Neural Information Processing Systems , volume=
Direct Preference Optimization: Your Language Model is Secretly a Reward Model , author=. Advances in Neural Information Processing Systems , volume=
-
[13]
arXiv preprint arXiv:2601.18734 , year=
Self-Distilled Reasoner: On-Policy Self-Distillation for Large Language Models , author=. arXiv preprint arXiv:2601.18734 , year=
-
[14]
arXiv preprint arXiv:2605.18740 , year=
Vision-OPD: Learning to See Fine Details for Multimodal LLMs via On-Policy Self-Distillation , author=. arXiv preprint arXiv:2605.18740 , year=
-
[15]
arXiv preprint arXiv:2604.17535 , year=
OPSDL: On-Policy Self-Distillation for Long-Context Language Models , author=. arXiv preprint arXiv:2604.17535 , year=
-
[16]
Journal of Machine Learning Research , volume=
Learning Using Privileged Information: Similarity Control and Knowledge Transfer , author=. Journal of Machine Learning Research , volume=
-
[17]
arXiv preprint arXiv:2602.11858 , year=
Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception , author=. arXiv preprint arXiv:2602.11858 , year=
-
[18]
5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=
Internvl3. 5: Advancing open-source multimodal models in versatility, reasoning, and efficiency , author=. arXiv preprint arXiv:2508.18265 , year=
-
[19]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[20]
Findings of the Association for Computational Linguistics: ACL 2023 , pages=
Distilling Step-by-Step! Outperforming Larger Language Models with Less Training Data and Smaller Model Sizes , author=. Findings of the Association for Computational Linguistics: ACL 2023 , pages=
2023
-
[21]
arXiv preprint arXiv:2212.08410 , year=
Teaching Small Language Models to Reason , author=. arXiv preprint arXiv:2212.08410 , year=
-
[22]
Advances in Neural Information Processing Systems , volume=
Visual CoT: Advancing Multi-Modal Language Models with a Comprehensive Dataset and Benchmark for Chain-of-Thought Reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[23]
Advances in Neural Information Processing Systems , volume=
Beyond the 80/20 rule: High-entropy minority tokens drive effective reinforcement learning for llm reasoning , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
arXiv preprint arXiv:2406.08515 , year=
Measuring Visual Spatial Perception of LLMs , author=. arXiv preprint arXiv:2406.08515 , year=
-
[25]
arXiv preprint arXiv:2404.12390 , year=
BLINK: Multimodal Large Language Models Can See but Not Perceive , author=. arXiv preprint arXiv:2404.12390 , year=
-
[26]
arXiv preprint arXiv:2312.14135 , year=
V*: Guided Visual Search as a Core Mechanism in Multimodal LLMs , author=. arXiv preprint arXiv:2312.14135 , year=
-
[27]
arXiv preprint arXiv:2401.06209 , year=
Eyes Wide Shut? Exploring the Visual Shortcomings of Multimodal LLMs , author=. arXiv preprint arXiv:2401.06209 , year=
-
[28]
arXiv preprint arXiv:2203.10244 , year=
ChartQA: A Benchmark for Question Answering about Charts with Visual and Logical Reasoning , author=. arXiv preprint arXiv:2203.10244 , year=
-
[29]
arXiv preprint arXiv:2504.12828 , year=
VisPuzzle: A Benchmark for Evaluating Visual Spatial Reasoning in LMMs , author=. arXiv preprint arXiv:2504.12828 , year=
-
[30]
arXiv preprint arXiv:2406.16860 , year=
Cambrian-1: A Fully Open, Vision-Centric Exploration of Multimodal LLMs , author=. arXiv preprint arXiv:2406.16860 , year=
-
[31]
arXiv preprint arXiv:2501.09792 , year=
SAT: Spatial Aptitude Training for Multimodal Language Models , author=. arXiv preprint arXiv:2501.09792 , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.