Taming I2V models for Image HOI Editing: A Cognitive Benchmark and Agentic Self-Correcting Framework
Pith reviewed 2026-06-26 21:29 UTC · model grok-4.3
The pith
I2V models with an agentic self-correcting framework achieve competitive performance on dynamic human-object interaction image editing.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating dynamic relationship remodeling as a temporal generation problem, I2V models can be steered via an agentic self-correcting loop of prompt refinement to produce videos whose extracted frames accurately realize target human-object interactions, delivering results competitive with state-of-the-art image editing models on the HOI-Edit benchmark.
What carries the argument
SCPE (Self-Correcting Process Editing), an agentic loop that iteratively refines prompts to constrain I2V generation so that extracted frames realize the desired HOI.
If this is right
- I2V models supply a unique diagnostic capability by allowing inspection of the generation sequence that led to an interaction error.
- Extracted frames from the final corrected I2V output serve as the edited still image.
- The HOI-Eval metric, by querying a VLM after it sees grounded human-object pairs, can assess both interaction correctness and pair preservation simultaneously.
- Progressive cognitive levels in HOI-Edit let researchers measure editing difficulty from simple attribute changes to complex dynamic interactions.
Where Pith is reading between the lines
- The same self-correcting loop could be tested on other temporal editing tasks such as motion transfer or scene dynamics where static models currently fail.
- If the diagnostic replay property holds, it may allow automated error classification that feeds back into prompt refinement without human intervention.
- The benchmark construction suggests that future interaction benchmarks should separate static attribute control from relational dynamics rather than conflating them.
Load-bearing premise
Image-to-video models are inherently better suited than static image models for editing dynamic human-object interactions because their temporal generation both improves results and supplies diagnostic replays of errors.
What would settle it
A direct comparison in which SCPE applied to I2V models scores lower than leading static editing models on the HOI-Eval interaction metric across the three cognitive levels of HOI-Edit.
Figures










read the original abstract
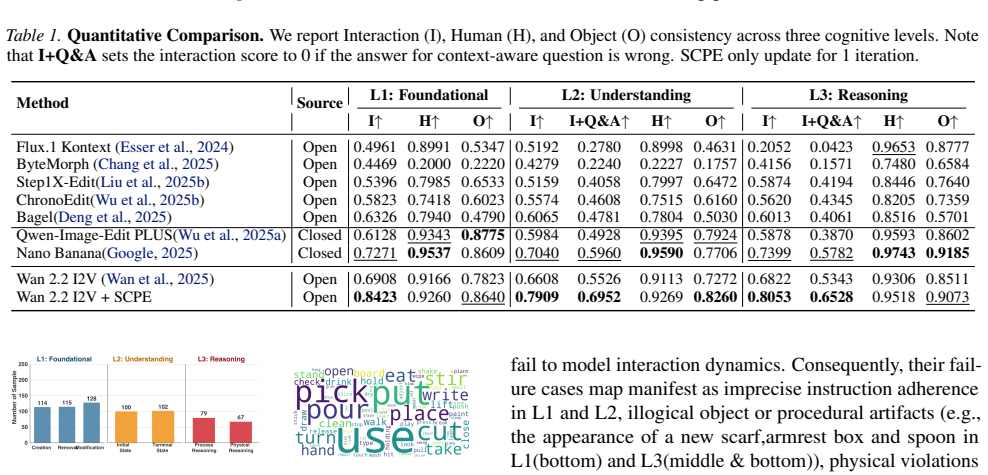
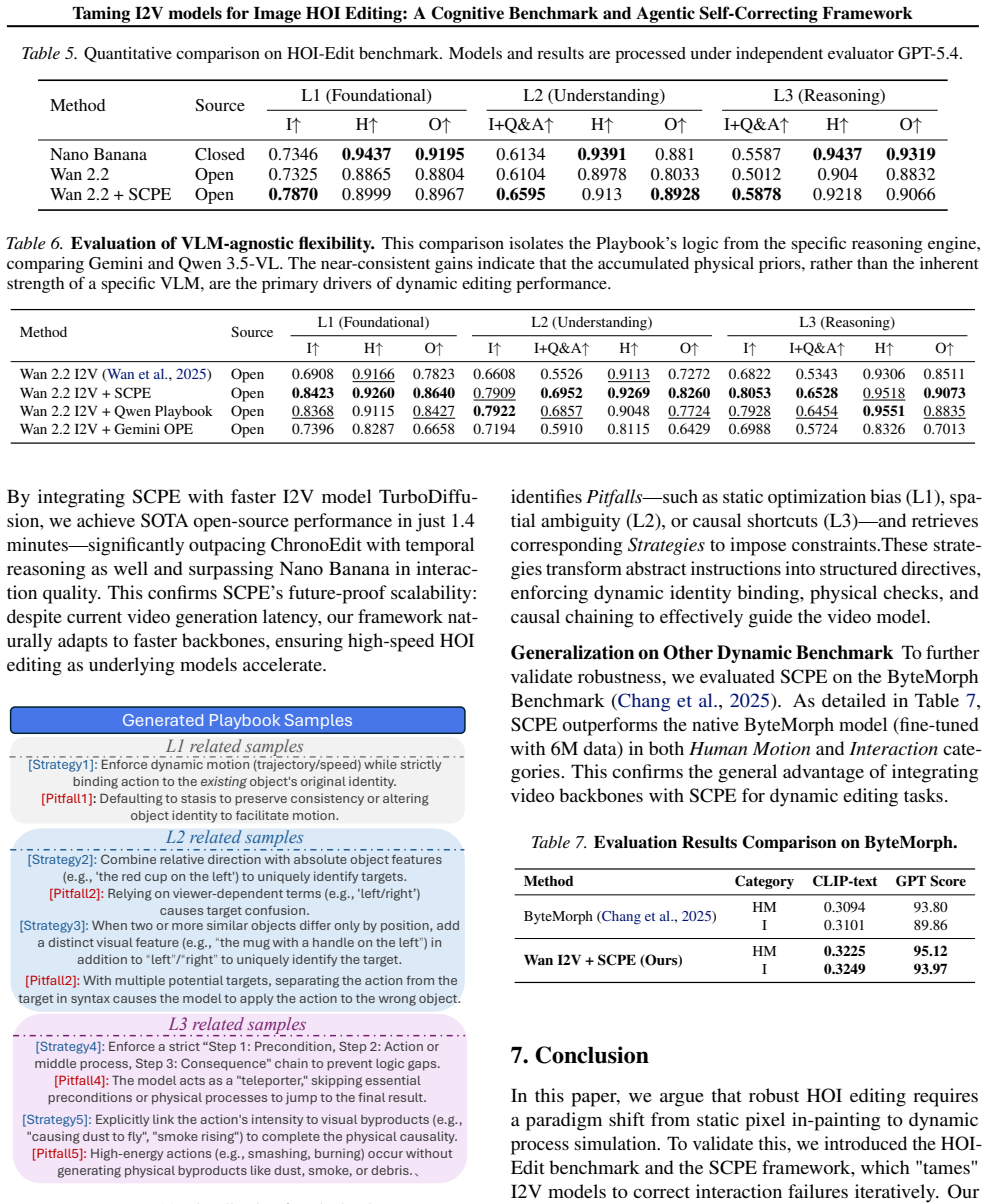
Current image editing methods excel at static attributes but fail at complex Human-Object Interactions (HOI), a critical challenge unaddressed by existing benchmarks that conflate HOI with static attributes, relying on global metrics incapable of simultaneously assessing dynamic interaction validity and entangled human-object pair preservation. Thus, we first introduce HOI-Edit, a comprehensive benchmark with three progressive cognitive levels, which features an automated metric HOI-Eval that reliably evaluates instance-level interaction by letting VLM Q&A after thinking with images containing grounded Human-Object pairs. Considering the task's essence of remodeling dynamic relationships, we benchmark Image-to-Video (I2V) models, finding them inherently suited for dynamic editing due to their temporal generation capabilities. Crucially, beyond superior performance, this capability provides a "replay of the failure process," offering unique diagnosability into why errors occur. We thus propose SCPE (Self-Correcting Process Editing), a novel, agentic self-correcting framework that constrains the generation of I2V models through iteratively refined prompts, enabling the generated videos to more accurately present the target HOI. Extracted frames from these videos are the final editing results. On HOI-Edit, SCPE achieves performance competitive with state-of-the-art (SOTA) editing models like Nano Banana on interaction. Code is available at https://github.com/oceanflowlab/HOI-Edit.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces the HOI-Edit benchmark for Human-Object Interaction (HOI) image editing, structured around three progressive cognitive levels, along with the automated HOI-Eval metric that uses VLM-based grounded Q&A to assess instance-level interactions. It benchmarks Image-to-Video (I2V) models as inherently suited for dynamic HOI editing due to temporal capabilities that also enable failure diagnosis, and proposes the SCPE agentic framework that applies iterative prompt refinement to I2V models, extracting final edited frames from the generated videos. The central empirical claim is that SCPE achieves performance competitive with SOTA editing models such as Nano Banana specifically on the interaction dimension of the HOI-Edit benchmark.
Significance. If the HOI-Eval metric proves reliable through human correlation and the reported competitive results hold under rigorous controls, the work would provide a much-needed cognitive benchmark for HOI editing and demonstrate a practical way to leverage I2V temporal modeling plus self-correction for dynamic interactions. The public code release would further strengthen reproducibility and enable follow-on research.
major comments (2)
- [Abstract] Abstract: The headline claim that SCPE is competitive with SOTA models rests entirely on HOI-Eval scores, yet the manuscript provides no reported correlation between HOI-Eval and human judgments, no inter-annotator agreement figures, and no comparison against existing metrics. This validation gap is load-bearing because an unproven automated evaluator cannot establish that the generated interactions are actually valid or that SCPE outperforms baselines on the intended cognitive dimensions.
- [Abstract] Abstract and evaluation description: No experimental details, error bars, statistical tests, or full baseline comparisons are visible to support the competitive performance numbers, leaving the central claim without visible supporting data or derivation.
minor comments (1)
- [Abstract] Abstract: The model name 'Nano Banana' appears without citation or clarification; if it is a specific published method, a reference should be added.
Simulated Author's Rebuttal
We thank the referee for the thoughtful and constructive review. The two major comments highlight important gaps in validation and experimental reporting that we will address in the revision. We respond point-by-point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The headline claim that SCPE is competitive with SOTA models rests entirely on HOI-Eval scores, yet the manuscript provides no reported correlation between HOI-Eval and human judgments, no inter-annotator agreement figures, and no comparison against existing metrics. This validation gap is load-bearing because an unproven automated evaluator cannot establish that the generated interactions are actually valid or that SCPE outperforms baselines on the intended cognitive dimensions.
Authors: We agree that explicit validation of HOI-Eval against human judgments is essential to support its reliability for assessing instance-level HOI. The manuscript describes the VLM-based grounded Q&A procedure but does not include the requested correlation analysis, inter-annotator agreement, or comparisons to prior metrics. We will add a new subsection (likely in Section 4) reporting human correlation studies, inter-annotator agreement statistics (e.g., Cohen’s kappa or Krippendorff’s alpha), and direct comparisons against existing metrics such as CLIPScore and HOI-specific baselines. These additions will be used to substantiate the claim that HOI-Eval reliably captures the intended cognitive dimensions. revision: yes
-
Referee: [Abstract] Abstract and evaluation description: No experimental details, error bars, statistical tests, or full baseline comparisons are visible to support the competitive performance numbers, leaving the central claim without visible supporting data or derivation.
Authors: We acknowledge that the abstract and main evaluation sections currently lack the requested experimental rigor. In the revised manuscript we will expand the evaluation section to include: (i) error bars (standard deviation across multiple runs or seeds), (ii) statistical significance tests (e.g., paired t-tests or Wilcoxon signed-rank tests with p-values), and (iii) complete baseline tables covering all three cognitive levels of HOI-Edit with all relevant SOTA editing models. The abstract will be updated to reference these detailed results. These changes will make the competitive performance claim fully traceable and reproducible. revision: yes
Circularity Check
No circularity; empirical claims rest on external SOTA comparisons and new benchmark
full rationale
The paper introduces HOI-Edit benchmark and HOI-Eval metric, benchmarks I2V models empirically, and proposes SCPE framework whose performance is reported as competitive with external models (e.g., Nano Banana) on the new benchmark. No equations, fitted parameters renamed as predictions, self-citations, or definitional reductions are present in the provided text. The central claim derives from reported scores against independent baselines rather than any input by construction, satisfying the self-contained criterion against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption I2V models are inherently suited for dynamic editing due to their temporal generation capabilities
Reference graph
Works this paper leans on
-
[1]
Langley , title =
P. Langley , title =
-
[2]
T. M. Mitchell. The Need for Biases in Learning Generalizations. 1980
1980
-
[3]
5-omni technical report , author=
Qwen3. 5-omni technical report , author=. arXiv preprint arXiv:2604.15804 , year=
-
[4]
arXiv preprint arXiv:2601.03267 , year=
Openai gpt-5 system card , author=. arXiv preprint arXiv:2601.03267 , year=
-
[5]
M. J. Kearns , title =
-
[6]
Machine Learning: An Artificial Intelligence Approach, Vol. I. 1983
1983
-
[7]
R. O. Duda and P. E. Hart and D. G. Stork. Pattern Classification. 2000
2000
-
[8]
Suppressed for Anonymity , author=
-
[9]
Newell and P
A. Newell and P. S. Rosenbloom. Mechanisms of Skill Acquisition and the Law of Practice. Cognitive Skills and Their Acquisition. 1981
1981
-
[10]
A. L. Samuel. Some Studies in Machine Learning Using the Game of Checkers. IBM Journal of Research and Development. 1959
1959
-
[11]
Forty-first international conference on machine learning , year=
Scaling rectified flow transformers for high-resolution image synthesis , author=. Forty-first international conference on machine learning , year=
-
[12]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Instructpix2pix: Learning to follow image editing instructions , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[13]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Dit4edit: Diffusion transformer for image editing , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[14]
arXiv preprint arXiv:2504.20690 , year=
In-context edit: Enabling instructional image editing with in-context generation in large scale diffusion transformer , author=. arXiv preprint arXiv:2504.20690 , year=
-
[15]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Anyedit: Mastering unified high-quality image editing for any idea , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[16]
arXiv preprint arXiv:2512.00387 , year=
Wiseedit: Benchmarking cognition-and creativity-informed image editing , author=. arXiv preprint arXiv:2512.00387 , year=
-
[17]
arXiv preprint arXiv:2511.01295 , year=
UniREditBench: A Unified Reasoning-based Image Editing Benchmark , author=. arXiv preprint arXiv:2511.01295 , year=
-
[18]
Advances in Neural Information Processing Systems , volume=
Magicbrush: A manually annotated dataset for instruction-guided image editing , author=. Advances in Neural Information Processing Systems , volume=
-
[19]
arXiv preprint arXiv:2504.17761 , year=
Step1x-edit: A practical framework for general image editing , author=. arXiv preprint arXiv:2504.17761 , year=
-
[20]
arXiv preprint arXiv:2506.03107 , year=
ByteMorph: Benchmarking Instruction-Guided Image Editing with Non-Rigid Motions , author=. arXiv preprint arXiv:2506.03107 , year=
-
[21]
arXiv preprint arXiv:2505.14683 , year=
Emerging properties in unified multimodal pretraining , author=. arXiv preprint arXiv:2505.14683 , year=
-
[22]
arXiv preprint arXiv:2510.04290 , year=
Chronoedit: Towards temporal reasoning for image editing and world simulation , author=. arXiv preprint arXiv:2510.04290 , year=
-
[23]
arXiv preprint arXiv:2508.02324 , year=
Qwen-image technical report , author=. arXiv preprint arXiv:2508.02324 , year=
-
[24]
2025 , month = apr, day =
Introducing Gemini 2.5 Flash Image , howpublished =. 2025 , month = apr, day =
2025
-
[25]
Advances in Neural Information Processing Systems , volume=
I2ebench: A comprehensive benchmark for instruction-based image editing , author=. Advances in Neural Information Processing Systems , volume=
-
[26]
Advances in Neural Information Processing Systems , volume=
Imgedit: A unified image editing dataset and benchmark , author=. Advances in Neural Information Processing Systems , volume=
-
[27]
International conference on machine learning , pages=
Learning transferable visual models from natural language supervision , author=. International conference on machine learning , pages=
-
[28]
arXiv preprint arXiv:2512.16093 , year=
TurboDiffusion: Accelerating Video Diffusion Models by 100-200 Times , author=. arXiv preprint arXiv:2512.16093 , year=
-
[29]
5-vl technical report , author=
Qwen2. 5-vl technical report , author=. arXiv preprint arXiv:2502.13923 , year=
-
[30]
2018 ieee winter conference on applications of computer vision (wacv) , pages=
Learning to detect human-object interactions , author=. 2018 ieee winter conference on applications of computer vision (wacv) , pages=
2018
-
[31]
arXiv preprint arXiv:2203.03605 , year=
Dino: Detr with improved denoising anchor boxes for end-to-end object detection , author=. arXiv preprint arXiv:2203.03605 , year=
-
[32]
arXiv preprint arXiv:2308.07234 , year=
Uniworld: Autonomous driving pre-training via world models , author=. arXiv preprint arXiv:2308.07234 , year=
-
[33]
arXiv preprint arXiv:2510.04618 , year=
Agentic context engineering: Evolving contexts for self-improving language models , author=. arXiv preprint arXiv:2510.04618 , year=
-
[34]
Forty-Second International Conference on Machine Learning , year=
Balancing Preservation and Modification: A Region and Semantic Aware Metric for Instruction-Based Image Editing , author=. Forty-Second International Conference on Machine Learning , year=
-
[35]
International Conference on Machine Learning , pages=
Balancing Preservation and Modification: A Region and Semantic Aware Metric for Instruction-Based Image Editing , author=. International Conference on Machine Learning , pages=
-
[36]
arXiv preprint arXiv:2510.17681 , year=
PICABench: How Far Are We from Physically Realistic Image Editing? , author=. arXiv preprint arXiv:2510.17681 , year=
-
[37]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[38]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Pathways on the image manifold: Image editing via video generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[39]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Hoigen-1m: A large-scale dataset for human-object interaction video generation , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[40]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Lmm4edit: Benchmarking and evaluating multimodal image editing with lmms , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[41]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Recammaster: Camera-controlled generative rendering from a single video , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[42]
International Conference on Learning Representations , volume=
Sam 2: Segment anything in images and videos , author=. International Conference on Learning Representations , volume=
-
[43]
European conference on computer vision , pages=
Grounding dino: Marrying dino with grounded pre-training for open-set object detection , author=. European conference on computer vision , pages=
-
[44]
Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
Conmo: Controllable motion disentanglement and recomposition for zero-shot motion transfer , author=. Proceedings of the Computer Vision and Pattern Recognition Conference , pages=
-
[45]
Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
Open-vocabulary hoi detection with interaction-aware prompt and concept calibration , author=. Proceedings of the IEEE/CVF International Conference on Computer Vision , pages=
-
[46]
Proceedings of the 33rd ACM International Conference on Multimedia , pages=
Interact-Custom: Customized Human Object Interaction Image Generation , author=. Proceedings of the 33rd ACM International Conference on Multimedia , pages=
-
[47]
Chinese Journal of Electronics , volume=
A comprehensive survey on text-to-video generation , author=. Chinese Journal of Electronics , volume=. 2025 , publisher=
2025
-
[48]
Chinese Journal of Electronics , volume=
Review of GAN-based research on Chinese character font generation , author=. Chinese Journal of Electronics , volume=. 2024 , publisher=
2024
-
[49]
Chinese Journal of Electronics , volume=
Psa-nerf: Personalized spatial attention neural rendering for audio-driven talking portraits generation , author=. Chinese Journal of Electronics , volume=. 2025 , publisher=
2025
-
[50]
arXiv preprint arXiv:2503.20314 , year=
Wan: Open and advanced large-scale video generative models , author=. arXiv preprint arXiv:2503.20314 , year=
-
[51]
LoRA: Low-Rank Adaptation of Large Language Models , author=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.