Essential Subspace Merging for Multi-Task Learning
Pith reviewed 2026-06-26 21:32 UTC · model grok-4.3
The pith
Task updates concentrate their output energy in a few principal directions, so isolating and orthogonally merging only those directions produces a compact multi-task model with reduced interference.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
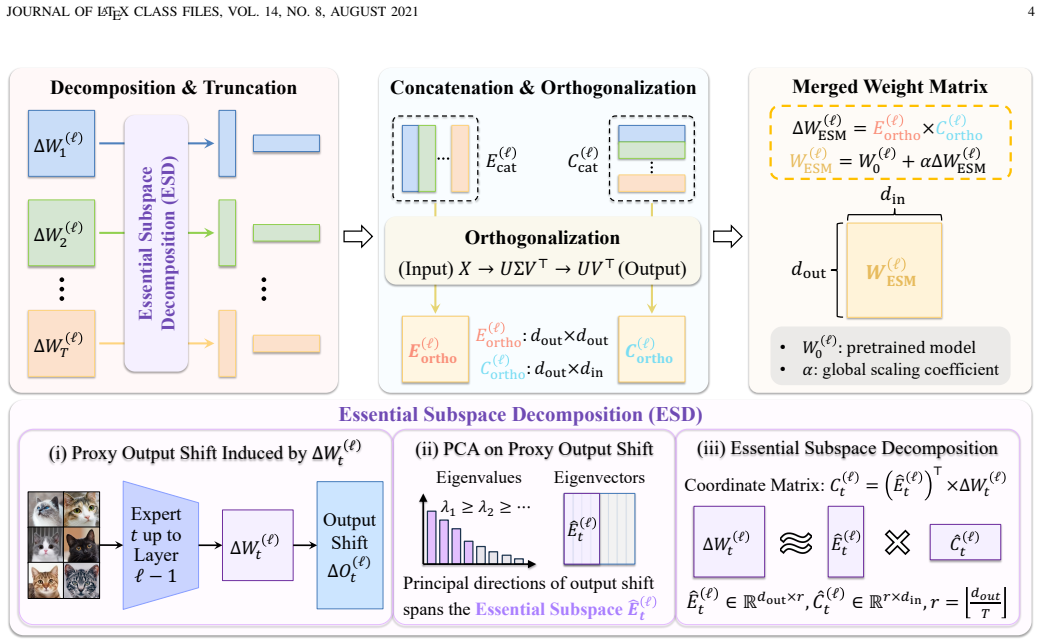
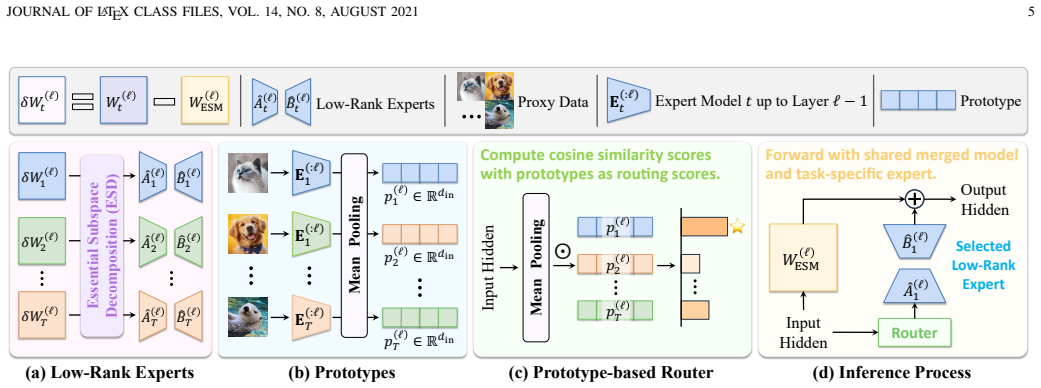
The essential subspace is the span of the top principal components of the activation shifts induced by each task update. Essential Subspace Decomposition projects every task delta onto this subspace, after which Essential Subspace Merging orthogonalizes the resulting essential components and sums them into one shared model; the non-essential residuals are either discarded or, in ESM++, further factored into low-rank experts that are selected by prototype routing during forward passes.
What carries the argument
Essential Subspace Decomposition (ESD): the projection of each task update onto the principal directions of its own output-shift matrix, used to isolate task-relevant energy before orthogonal fusion.
If this is right
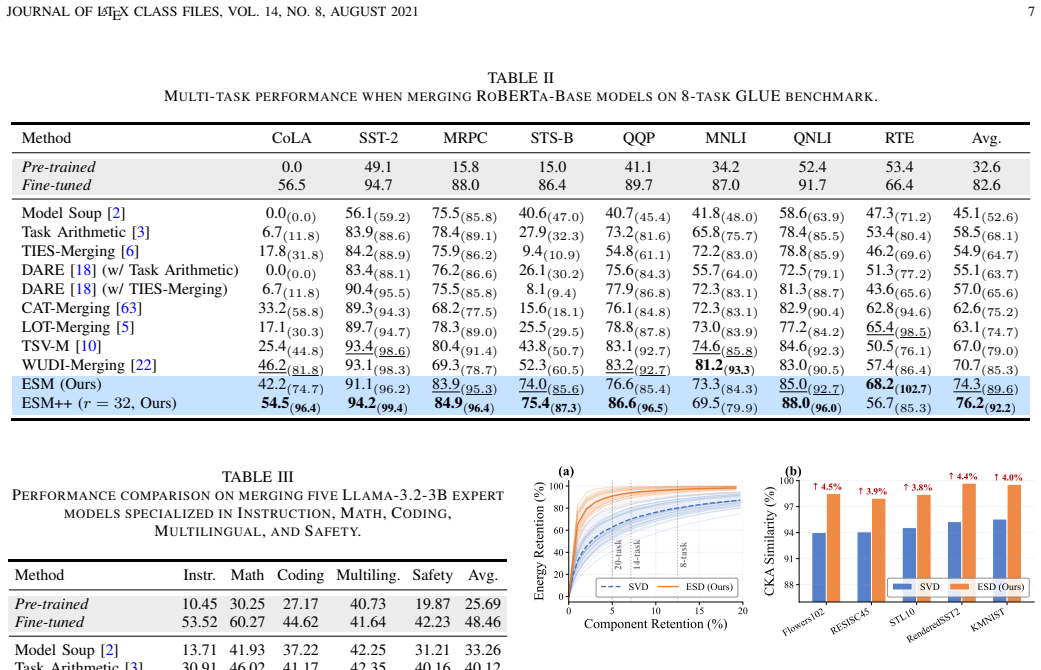
- A training-free static merge produces one model that simultaneously solves multiple tasks with less cross-task degradation than simple averaging.
- The same decomposition extends to a dynamic router that selects among low-rank experts at inference time without retraining.
- The approach remains effective across different numbers of tasks and different model scales.
- Orthogonalization of the essential components prevents the accumulation of low-energy directions that would otherwise amplify interference.
Where Pith is reading between the lines
- If the principal directions remain stable when new tasks are added, the method could support incremental merging without recomputing the full subspace each time.
- The same decomposition step could be inserted into existing averaging or Fisher-weighted merging pipelines to reduce their interference without changing their overall structure.
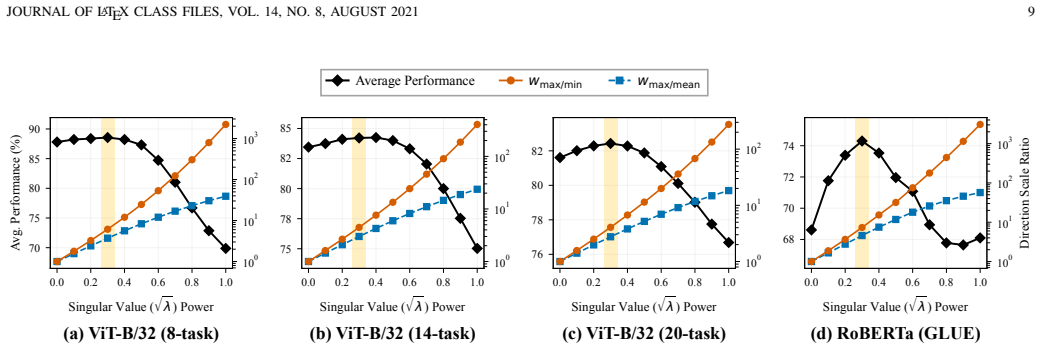
- Empirical checks on whether the required rank of the essential subspace grows with the number of tasks would clarify the method's scaling limits.
Load-bearing premise
The energy of task-induced output shifts is concentrated in a small number of principal directions whose orthogonalization will not discard task-relevant information or introduce new interference when fused.
What would settle it
Measure per-task accuracy after merging; if accuracy on held-out tasks falls substantially below the level achieved by the original fine-tuned models while the number of retained principal directions is increased, the concentration assumption does not hold.
Figures









read the original abstract
Model merging aims to enable multi-task learning by integrating the capabilities of multiple models fine-tuned from the same pre-trained checkpoint into a single model. Its core challenge is inter-task interference among task-specific parameter updates. In this paper, we analyze the output shifts induced by task updates and observe that their energy is concentrated in a small number of principal directions. We call the subspace spanned by these directions the essential subspace. In contrast, most remaining directions carry little task-relevant energy, but their accumulation across multiple task updates can cause severe interference during merging. Motivated by this observation, we propose Essential Subspace Decomposition (ESD), which decomposes each task update according to the principal components of its activation shift. Based on ESD, we introduce Essential Subspace Merging (ESM), a training-free static merging method that orthogonalizes and fuses essential components into one compact multi-task model. We further extend ESM to ESM++, a training-free dynamic merging method that decomposes task-specific residuals into low-rank experts and selects the most relevant expert through prototype-based routing during forward inference. Extensive experiments across multiple task sets and model scales demonstrate that ESM and ESM++ effectively preserves task knowledge while reducing inter-task interference. Code is available at https://github.com/kiddo127/ESM.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that task-induced output shifts in fine-tuned models have their energy concentrated in a small number of principal directions (the 'essential subspace'), while the remaining directions accumulate interference across tasks. It introduces Essential Subspace Decomposition (ESD) to decompose updates along these components, then proposes Essential Subspace Merging (ESM) as a static, training-free method that orthogonalizes and fuses the essential components, and ESM++ as a dynamic variant using low-rank experts with prototype-based routing. Experiments across task sets and model scales are reported to show that both methods preserve task knowledge while reducing inter-task interference compared to baselines.
Significance. If the subspace concentration observation holds and the orthogonalization/fusion steps preserve signal without introducing new interference, the work offers a practical training-free route to multi-task model merging that scales across model sizes. The public code release is a clear strength for reproducibility and follow-up work.
major comments (2)
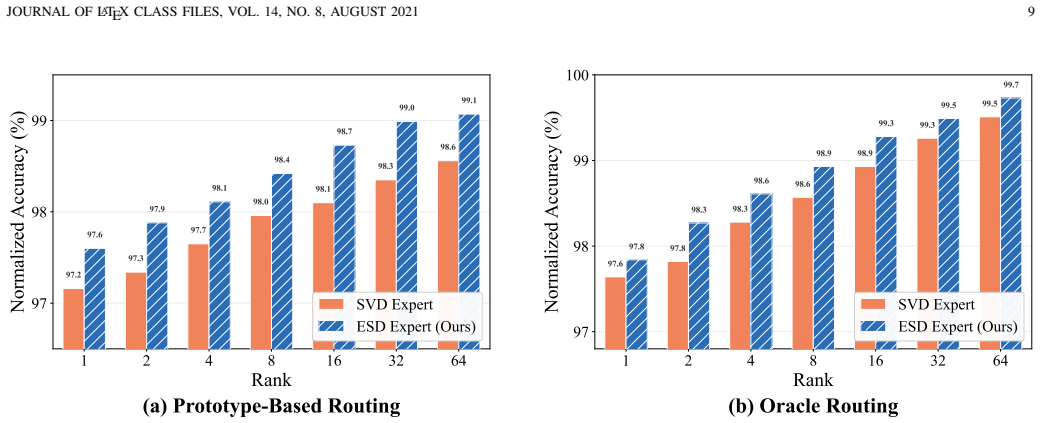
- [Experiments / §5] The central claim rests on the empirical observation that output-shift energy concentrates in few principal directions, yet the manuscript supplies no quantitative threshold, cumulative-energy plot, or ablation on the number of retained components (e.g., in the experiments section or Appendix). Without this, it is impossible to assess how sensitive ESM/ESM++ performance is to the choice of subspace dimension.
- [§3.2 / ESM definition] Section 3.2 and the fusion step in ESM: the claim that orthogonalized essential components can be fused without discarding task-relevant information or creating new interference is asserted but lacks any subspace-overlap analysis or error-bound argument across tasks. If the principal directions of different tasks are not sufficiently orthogonal after accumulation, the interference-reduction guarantee does not follow.
minor comments (2)
- [§3.1] Notation for the activation-shift matrix and its SVD is introduced without an explicit equation reference; adding a numbered equation would improve clarity.
- [Figures 2-4] Figure captions should state the exact number of tasks and models used in each panel to allow direct comparison with the tables.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below, clarifying our empirical observations and indicating revisions to strengthen the manuscript.
read point-by-point responses
-
Referee: [Experiments / §5] The central claim rests on the empirical observation that output-shift energy concentrates in few principal directions, yet the manuscript supplies no quantitative threshold, cumulative-energy plot, or ablation on the number of retained components (e.g., in the experiments section or Appendix). Without this, it is impossible to assess how sensitive ESM/ESM++ performance is to the choice of subspace dimension.
Authors: We agree that additional quantitative support is needed to substantiate the energy concentration claim. In the revised version, we will add cumulative energy plots (showing variance explained by top-k components) and an ablation study on subspace dimension in §5 and the Appendix, reporting performance sensitivity across tasks and models. revision: yes
-
Referee: [§3.2 / ESM definition] Section 3.2 and the fusion step in ESM: the claim that orthogonalized essential components can be fused without discarding task-relevant information or creating new interference is asserted but lacks any subspace-overlap analysis or error-bound argument across tasks. If the principal directions of different tasks are not sufficiently orthogonal after accumulation, the interference-reduction guarantee does not follow.
Authors: We will add a subspace-overlap analysis (e.g., principal angles and cosine similarities between task essential subspaces) to §3.2 and experiments to empirically support limited interference post-orthogonalization. Our work is empirical rather than providing formal error bounds or guarantees; we will clarify this motivation and reliance on experimental validation in the text. revision: partial
Circularity Check
No circularity; derivation follows from stated empirical observation without self-referential reduction.
full rationale
The paper states an empirical observation that output-shift energy concentrates in principal directions, names the spanned subspace the 'essential subspace,' and motivates ESD/ESM/ESM++ from that observation. No equation or step reduces a claimed prediction or result to a fitted parameter or self-citation by construction; the central method is presented as a direct consequence of the observation rather than a quantity defined in terms of itself. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling appear in the text. The chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Model merging in the essential subspace,
L. Li, L. Qi, Q. Tian, and X. Geng, “Model merging in the essential subspace,” inCVPR, 2026
2026
-
[2]
Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,
M. Wortsman, G. Ilharco, S. Y . Gadre, R. Roelofs, R. Gontijo-Lopes, A. S. Morcos, H. Namkoong, A. Farhadi, Y . Carmon, S. Kornblith et al., “Model soups: averaging weights of multiple fine-tuned models improves accuracy without increasing inference time,” inICML, 2022
2022
-
[3]
Editing models with task arithmetic,
G. Ilharco, M. T. Ribeiro, M. Wortsman, L. Schmidt, H. Hajishirzi, and A. Farhadi, “Editing models with task arithmetic,” inICLR, 2023
2023
-
[4]
Calm: Consensus-aware localized merging for multi-task learning,
K. Yan, M. Zhang, S. Cui, Q. Zikun, B. Jiang, F. Liu, and C. Zhang, “Calm: Consensus-aware localized merging for multi-task learning,” in ICML, 2025
2025
-
[5]
Towards minimizing feature drift in model merging: Layer-wise task vector fusion for adaptive knowledge integration,
W. Sun, Q. Li, W. Wang, Y . Liu, Y . Geng, and B. Li, “Towards minimizing feature drift in model merging: Layer-wise task vector fusion for adaptive knowledge integration,” inNeurIPS, 2025
2025
-
[6]
Ties- merging: Resolving interference when merging models,
P. Yadav, D. Tam, L. Choshen, C. A. Raffel, and M. Bansal, “Ties- merging: Resolving interference when merging models,” inNeurIPS, 2023
2023
-
[7]
Merging models with fisher-weighted averaging,
M. S. Matena and C. A. Raffel, “Merging models with fisher-weighted averaging,” inNeurIPS, 2022
2022
-
[8]
Dataless knowledge fusion by merging weights of language models,
X. Jin, X. Ren, D. Preotiuc-Pietro, and P. Cheng, “Dataless knowledge fusion by merging weights of language models,” inICLR, 2023
2023
-
[9]
Model merging with svd to tie the knots,
G. Stoica, P. Ramesh, B. Ecsedi, L. Choshen, and J. Hoffman, “Model merging with svd to tie the knots,” inICLR, 2025
2025
-
[10]
Task singular vectors: Reducing task interference in model merging,
A. A. Gargiulo, D. Crisostomi, M. S. Bucarelli, S. Scardapane, F. Sil- vestri, and E. Rodola, “Task singular vectors: Reducing task interference in model merging,” inCVPR, 2025
2025
-
[11]
No task left behind: Isotropic model merging with common and task-specific subspaces,
D. Marczak, S. Magistri, S. Cygert, B. Twardowski, A. D. Bagdanov, and J. van de Weijer, “No task left behind: Isotropic model merging with common and task-specific subspaces,” inICML, 2025
2025
-
[12]
Dc-merge: Improving model merging with directional consistency,
H.-C. Zhang, Z.-H. Zhou, M.-L. Luo, S. Di, M.-L. Zhang, and T. Wei, “Dc-merge: Improving model merging with directional consistency,” in CVPR, 2026
2026
-
[13]
Improving model fusion by training-time neuron alignment with fixed neuron anchors,
Z. Li, Z. Li, J. Lin, T. Shen, J. Xiao, Y . Guo, T. Lin, and C. Wu, “Improving model fusion by training-time neuron alignment with fixed neuron anchors,”TPAMI, 2026
2026
-
[14]
Model fusion via optimal transport,
S. P. Singh and M. Jaggi, “Model fusion via optimal transport,”NeurIPS, vol. 33, pp. 22 045–22 055, 2020
2020
-
[15]
Optimizing mode connectivity via neuron alignment,
N. Tatro, P.-Y . Chen, P. Das, I. Melnyk, P. Sattigeri, and R. Lai, “Optimizing mode connectivity via neuron alignment,”NeurIPS, vol. 33, pp. 15 300–15 311, 2020
2020
-
[16]
Re-basin via implicit sinkhorn differentiation,
F. A. G. Pe ˜na, H. R. Medeiros, T. Dubail, M. Aminbeidokhti, E. Granger, and M. Pedersoli, “Re-basin via implicit sinkhorn differentiation,” in CVPR, 2023, pp. 20 237–20 246
2023
-
[17]
Adamerging: Adaptive model merging for multi-task learning,
E. Yang, Z. Wang, L. Shen, S. Liu, G. Guo, X. Wang, and D. Tao, “Adamerging: Adaptive model merging for multi-task learning,” in ICLR, 2024
2024
-
[18]
Language models are super mario: Absorbing abilities from homologous models as a free lunch,
L. Yu, B. Yu, H. Yu, F. Huang, and Y . Li, “Language models are super mario: Absorbing abilities from homologous models as a free lunch,” in ICML, 2024
2024
-
[19]
Parameter competition balancing for model merging,
G. Du, J. Lee, J. Li, R. Jiang, Y . Guo, S. Yu, H. Liu, S. K. Goh, H.-K. Tang, D. Heet al., “Parameter competition balancing for model merging,” inNeurIPS, 2024
2024
-
[20]
Knowledge composition using task vectors with learned anisotropic scaling,
F. Z. Zhang, P. Albert, C. Rodriguez-Opazo, A. van den Hengel, and E. Abbasnejad, “Knowledge composition using task vectors with learned anisotropic scaling,” inNeurIPS, 2024
2024
-
[21]
Lines: Post-training layer scaling prevents forgetting and enhances model merging,
K. Wang, N. Dimitriadis, A. Favero, G. Ortiz-Jimenez, F. Fleuret, and P. Frossard, “Lines: Post-training layer scaling prevents forgetting and enhances model merging,” inICLR, 2025
2025
-
[22]
Whoever started the interference should end it: Guiding data-free model merging via task vectors,
R. Cheng, F. Xiong, Y . Wei, W. Zhu, and C. Yuan, “Whoever started the interference should end it: Guiding data-free model merging via task vectors,” inICML, 2025
2025
-
[23]
Emr-merging: Tuning-free high-performance model merging,
C. Huang, P. Ye, T. Chen, T. He, X. Yue, and W. Ouyang, “Emr-merging: Tuning-free high-performance model merging,” inNeurIPS, 2024
2024
-
[24]
Free-merging: Fourier transform for efficient model merging,
S. Zheng and H. Wang, “Free-merging: Fourier transform for efficient model merging,” inICCV, 2025
2025
-
[25]
Efficient and effective weight-ensembling mixture of experts for multi-task model merging,
L. Shen, A. Tang, E. Yang, G. Guo, Y . Luo, L. Zhang, X. Cao, B. Du, and D. Tao, “Efficient and effective weight-ensembling mixture of experts for multi-task model merging,”TPAMI, 2026
2026
-
[26]
Zero-shot sparse mixture of low-rank experts construction from pre- trained foundation models,
A. Tang, L. Shen, Y . Luo, S. Xie, H. Hu, L. Zhang, B. Du, and D. Tao, “Zero-shot sparse mixture of low-rank experts construction from pre- trained foundation models,”TPAMI, 2026
2026
-
[27]
Svd-llm: Truncation-aware singular value decomposition for large language model compression,
X. Wang, Y . Zheng, Z. Wan, and M. Zhang, “Svd-llm: Truncation-aware singular value decomposition for large language model compression,” in ICLR, 2025
2025
-
[28]
Stratified knowledge-density super-network for scalable vision transformers,
L. Li, L. Qi, and X. Geng, “Stratified knowledge-density super-network for scalable vision transformers,” inAAAI, vol. 40, no. 27, 2026, pp. 22 985–22 993
2026
-
[29]
Energy-structured low-rank adaptation for continual learning,
L. Li, L. Qi, Q. Tian, and X. Geng, “Energy-structured low-rank adaptation for continual learning,”arXiv preprint arXiv:2605.27482, 2026
Pith/arXiv arXiv 2026
-
[30]
Lora: Low-rank adaptation of large language models,
E. J. Hu, P. Wallis, Z. Allen-Zhu, Y . Li, S. Wang, L. Wang, W. Chen et al., “Lora: Low-rank adaptation of large language models,” inICLR, 2022
2022
-
[31]
Qlora: Efficient finetuning of quantized llms,
T. Dettmers, A. Pagnoni, A. Holtzman, and L. Zettlemoyer, “Qlora: Efficient finetuning of quantized llms,” inNeurIPS, 2023
2023
-
[32]
Parameter-efficient fine-tuning of large-scale pre-trained language models,
N. Ding, Y . Qin, G. Yang, F. Wei, Z. Yang, Y . Su, S. Hu, Y . Chen, C.- M. Chan, W. Chenet al., “Parameter-efficient fine-tuning of large-scale pre-trained language models,”NMI, 2023
2023
-
[33]
Singular value fine-tuning: Few-shot segmentation requires few-parameters fine-tuning,
Y . Sun, Q. Chen, X. He, J. Wang, H. Feng, J. Han, E. Ding, J. Cheng, Z. Li, and J. Wang, “Singular value fine-tuning: Few-shot segmentation requires few-parameters fine-tuning,” inNeurIPS, 2022
2022
-
[34]
Svdiff: Compact parameter space for diffusion fine-tuning,
L. Han, Y . Li, H. Zhang, P. Milanfar, D. Metaxas, and F. Yang, “Svdiff: Compact parameter space for diffusion fine-tuning,” inICCV, 2023
2023
-
[35]
Losparse: Structured compression of large language models based on low-rank and sparse approximation,
Y . Li, Y . Yu, Q. Zhang, C. Liang, P. He, W. Chen, and T. Zhao, “Losparse: Structured compression of large language models based on low-rank and sparse approximation,” inICML, 2023
2023
-
[36]
Matrix compression via ran- domized low rank and low precision factorization,
R. Saha, V . Srivastava, and M. Pilanci, “Matrix compression via ran- domized low rank and low precision factorization,” inNeurIPS, 2023
2023
-
[37]
Svd-llm v2: Opti- mizing singular value truncation for large language model compression,
X. Wang, S. Alam, Z. Wan, H. Shen, and M. Zhang, “Svd-llm v2: Opti- mizing singular value truncation for large language model compression,” inNAACL, 2025
2025
-
[38]
Localizing task information for improved model merging and compres- sion,
K. Wang, N. Dimitriadis, G. Ortiz-Jimenez, F. Fleuret, and P. Frossard, “Localizing task information for improved model merging and compres- sion,” inICML, 2024
2024
-
[39]
3d object representations for fine-grained categorization,
J. Krause, M. Stark, J. Deng, and L. Fei-Fei, “3d object representations for fine-grained categorization,” inICCV workshops, 2013
2013
-
[40]
Describing textures in the wild,
M. Cimpoi, S. Maji, I. Kokkinos, S. Mohamed, and A. Vedaldi, “Describing textures in the wild,” inCVPR, 2014
2014
-
[41]
Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,
P. Helber, B. Bischke, A. Dengel, and D. Borth, “Eurosat: A novel dataset and deep learning benchmark for land use and land cover classification,”JSTARS, 2019
2019
-
[42]
The german traffic sign recognition benchmark: a multi-class classification competition,
J. Stallkamp, M. Schlipsing, J. Salmen, and C. Igel, “The german traffic sign recognition benchmark: a multi-class classification competition,” in IJCNN, 2011
2011
-
[43]
Gradient-based learning applied to document recognition,
Y . LeCun, L. Bottou, Y . Bengio, and P. Haffner, “Gradient-based learning applied to document recognition,”Proceedings of the IEEE, 2002
2002
-
[44]
Remote sensing image scene classifica- tion: Benchmark and state of the art,
G. Cheng, J. Han, and X. Lu, “Remote sensing image scene classifica- tion: Benchmark and state of the art,”Proceedings of the IEEE, 2017
2017
-
[45]
Sun database: Exploring a large collection of scene categories,
J. Xiao, K. A. Ehinger, J. Hays, A. Torralba, and A. Oliva, “Sun database: Exploring a large collection of scene categories,”IJCV, 2016
2016
-
[46]
Reading digits in natural images with unsupervised feature learning,
Y . Netzer, T. Wang, A. Coates, A. Bissacco, B. Wu, A. Y . Nget al., “Reading digits in natural images with unsupervised feature learning,” inNeurIPS workshops, 2011
2011
-
[47]
Learning multiple layers of features from tiny images,
A. Krizhevsky, G. Hintonet al., “Learning multiple layers of features from tiny images,” Toronto, ON, Canada, Tech. Rep., 2009
2009
-
[48]
An analysis of single-layer networks in unsupervised feature learning,
A. Coates, A. Ng, and H. Lee, “An analysis of single-layer networks in unsupervised feature learning,” inAISTATS, 2011
2011
-
[49]
Automated flower classification over a large number of classes,
M.-E. Nilsback and A. Zisserman, “Automated flower classification over a large number of classes,” inICVGIP, 2008
2008
-
[50]
Cats and dogs,
O. M. Parkhi, A. Vedaldi, A. Zisserman, and C. Jawahar, “Cats and dogs,” inCVPR, 2012
2012
-
[51]
Rotation equivariant cnns for digital pathology,
B. S. Veeling, J. Linmans, J. Winkens, T. Cohen, and M. Welling, “Rotation equivariant cnns for digital pathology,” inMICCAI, 2018
2018
-
[52]
Chal- lenges in representation learning: A report on three machine learning contests,
I. J. Goodfellow, D. Erhan, P. L. Carrier, A. Courville, M. Mirza, B. Hamner, W. Cukierski, Y . Tang, D. Thaler, D.-H. Leeet al., “Chal- lenges in representation learning: A report on three machine learning contests,” inICONIP, 2013
2013
-
[53]
Emnist: Extending mnist to handwritten letters,
G. Cohen, S. Afshar, J. Tapson, and A. Van Schaik, “Emnist: Extending mnist to handwritten letters,” inIJCNN, 2017
2017
-
[54]
Food-101–mining dis- criminative components with random forests,
L. Bossard, M. Guillaumin, and L. Van Gool, “Food-101–mining dis- criminative components with random forests,” inECCV, 2014
2014
-
[55]
Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,
H. Xiao, K. Rasul, and R. V ollgraf, “Fashion-mnist: a novel image dataset for benchmarking machine learning algorithms,”arXiv preprint arXiv:1708.07747, 2017
Pith/arXiv arXiv 2017
-
[56]
Recursive deep models for semantic compositionality over a sentiment treebank,
R. Socher, A. Perelygin, J. Wu, J. Chuang, C. D. Manning, A. Y . Ng, and C. Potts, “Recursive deep models for semantic compositionality over a sentiment treebank,” inEMNLP, 2013
2013
-
[57]
Deep learning for classical japanese literature,
T. Clanuwat, M. Bober-Irizar, A. Kitamoto, A. Lamb, K. Yamamoto, and D. Ha, “Deep learning for classical japanese literature,”arXiv preprint arXiv:1812.01718, 2018. JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 12
Pith/arXiv arXiv 2018
-
[58]
Learning transferable visual models from natural language supervision,
A. Radford, J. W. Kim, C. Hallacy, A. Ramesh, G. Goh, S. Agarwal, G. Sastry, A. Askell, P. Mishkin, J. Clarket al., “Learning transferable visual models from natural language supervision,” inICML, 2021
2021
-
[59]
Glue: A multi-task benchmark and analysis platform for natural language understanding,
A. Wang, A. Singh, J. Michael, F. Hill, O. Levy, and S. Bowman, “Glue: A multi-task benchmark and analysis platform for natural language understanding,” inEMNLP workshop, 2018, pp. 353–355
2018
-
[60]
Roberta: A robustly optimized bert pretraining approach,
Y . Liu, M. Ott, N. Goyal, J. Du, M. Joshi, D. Chen, O. Levy, M. Lewis, L. Zettlemoyer, and V . Stoyanov, “Roberta: A robustly optimized bert pretraining approach,”arXiv preprint arXiv:1907.11692, 2019
Pith/arXiv arXiv 1907
-
[61]
Mergebench: A benchmark for merging domain-specialized llms,
Y . He, S. Zeng, Y . Hu, R. Yang, T. Zhang, and H. Zhao, “Mergebench: A benchmark for merging domain-specialized llms,”NeurIPS, vol. 38, 2026
2026
-
[62]
A. Grattafiori, A. Dubey, A. Jauhri, A. Pandey, A. Kadian, A. Al-Dahle, A. Letman, A. Mathur, A. Schelten, A. Vaughanet al., “The llama 3 herd of models,”arXiv preprint arXiv:2407.21783, 2024
Pith/arXiv arXiv 2024
-
[63]
Cat merging: A training-free approach for resolving conflicts in model merging,
W. Sun, Q. Li, Y . Geng, and B. Li, “Cat merging: A training-free approach for resolving conflicts in model merging,” inICML. PMLR, 2025, pp. 57 523–57 543
2025
-
[64]
Localize-and-stitch: Efficient model merging via sparse task arithmetic,
Y . He, Y . Hu, Y . Lin, T. Zhang, and H. Zhao, “Localize-and-stitch: Efficient model merging via sparse task arithmetic,”TMLR, 2024
2024
-
[65]
Similarity of neural network representations revisited,
S. Kornblith, M. Norouzi, H. Lee, and G. Hinton, “Similarity of neural network representations revisited,” inICML, 2019
2019
-
[66]
Imagenet large scale visual recognition challenge,
O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang, A. Karpathy, A. Khosla, M. Bernsteinet al., “Imagenet large scale visual recognition challenge,”IJCV, 2015
2015
-
[67]
Pointer sentinel mixture models,
S. Merity, C. Xiong, J. Bradbury, and R. Socher, “Pointer sentinel mixture models,”arXiv preprint arXiv:1609.07843, 2016
Pith/arXiv arXiv 2016
-
[68]
Instruction-following evaluation for large language models,
J. Zhou, T. Lu, S. Mishra, S. Brahma, S. Basu, Y . Luan, D. Zhou, and L. Hou, “Instruction-following evaluation for large language models,” arXiv preprint arXiv:2311.07911, 2023
Pith/arXiv arXiv 2023
-
[69]
Training verifiers to solve math word problems,
K. Cobbe, V . Kosaraju, M. Bavarian, M. Chen, H. Jun, L. Kaiser, M. Plappert, J. Tworek, J. Hilton, R. Nakanoet al., “Training verifiers to solve math word problems,”arXiv preprint arXiv:2110.14168, 2021
Pith/arXiv arXiv 2021
-
[70]
Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback,
V . Lai, C. Nguyen, N. Ngo, T. Nguy ˜en, F. Dernoncourt, R. Rossi, and T. Nguyen, “Okapi: Instruction-tuned large language models in multiple languages with reinforcement learning from human feedback,” inEMNLP, 2023, pp. 318–327
2023
-
[71]
Evaluating large language models trained on code,
M. Chen, J. Tworek, H. Jun, Q. Yuan, H. P. D. O. Pinto, J. Kaplan, H. Edwards, Y . Burda, N. Joseph, G. Brockmanet al., “Evaluating large language models trained on code,”arXiv preprint arXiv:2107.03374, 2021
Pith/arXiv arXiv 2021
-
[72]
Program synthesis with large language models,
J. Austin, A. Odena, M. Nye, M. Bosma, H. Michalewski, D. Dohan, E. Jiang, C. Cai, M. Terry, Q. Leet al., “Program synthesis with large language models,”arXiv preprint arXiv:2108.07732, 2021
Pith/arXiv arXiv 2021
-
[73]
Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,
S. Han, K. Rao, A. Ettinger, L. Jiang, B. Y . Lin, N. Lambert, Y . Choi, and N. Dziri, “Wildguard: Open one-stop moderation tools for safety risks, jailbreaks, and refusals of llms,”NeurIPS, vol. 37, pp. 8093–8131, 2024
2024
-
[74]
Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,
M. Mazeika, L. Phan, X. Yin, A. Zou, Z. Wang, N. Mu, E. Sakhaee, N. Li, S. Basart, B. Liet al., “Harmbench: A standardized evaluation framework for automated red teaming and robust refusal,”arXiv preprint arXiv:2402.04249, 2024
Pith/arXiv arXiv 2024
-
[75]
” do anything now
X. Shen, Z. Chen, M. Backes, Y . Shen, and Y . Zhang, “” do anything now”: Characterizing and evaluating in-the-wild jailbreak prompts on large language models,” inACM CCS, 2024, pp. 1671–1685
2024
-
[76]
Xstest: A test suite for identifying exaggerated safety behaviours in large language models,
P. R ¨ottger, H. Kirk, B. Vidgen, G. Attanasio, F. Bianchi, and D. Hovy, “Xstest: A test suite for identifying exaggerated safety behaviours in large language models,” inNAACL, 2024, pp. 5377–5400. Longhua Lireceived the B.S. degree in Artificial Intelligence from Shandong University in 2023. He is currently pursuing a Ph.D. degree in Artificial Intellige...
2024
-
[77]
!" 𝐸""" 𝐶$!
Empirical Evidence: Pairwise Task Interaction.:We further analyze the pairwise influence between task matrices. As shown in Fig. 8(a), each column represents how the performance of two tasks changes when the task update of the column task JOURNAL OF LATEX CLASS FILES, VOL. 14, NO. 8, AUGUST 2021 5 TABLE X FINE-GRAINED ABLATION STUDY OF THE THREE LEVELS IN...
2021
-
[78]
Polarized Scaling Method:Motivated by this observation, we apply Polarized Scaling to increase the contrast among parameter updates before merging. Specifically, updates with larger norms are further amplified because they are more likely to correspond to task-critical directions or consensus knowledge accumulated across tasks, whereas smaller-norm update...
-
[79]
Reverse”:TAKING THE RECIPROCAL OF THE SCALING FACTORS; (II) “Noise−−
Ablation Study on the Exponent of the Scaling Factor:The default configuration of our method employs a power of 2in the polarized scaling coefficient, i.e.,( norm E[norm])2. The rationale for this choice is to amplify significant parameters while suppressing redundant ones. To validate the sensitivity of our approach to this hyperparameter, we conducted a...
2021
-
[80]
Reverse”, which applies the reciprocal of the scaling factors; (ii) “Noise−−
Detailed Ablation Study of Polarized Scaling.:We perform a detailed ablation of the Polarized Scaling in Table XI. We compare three alternatives: (i) “Reverse”, which applies the reciprocal of the scaling factors; (ii) “Noise−−”, which retains only factors<1to suppress noisy parameters; and (iii) “Signal++”, which retains only factors>1to enhance importan...
2021
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.