Zero-Inflated Gaussian Distributions Enable Parameter-Space Sparsity in Estimation-of-Distribution Algorithms
Pith reviewed 2026-06-27 07:02 UTC · model grok-4.3
The pith
Multivariate zero-inflated Gaussian distributions let estimation-of-distribution algorithms jointly optimize sparsity patterns and active parameter values in black-box problems.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
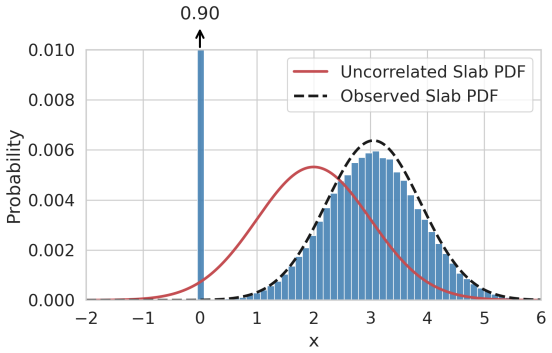
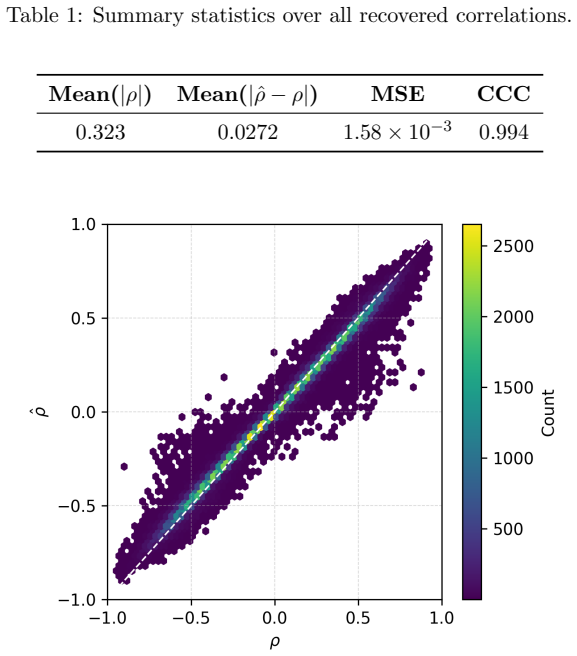
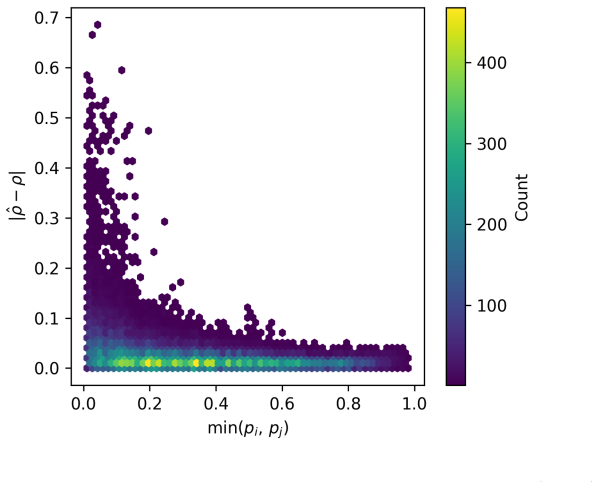
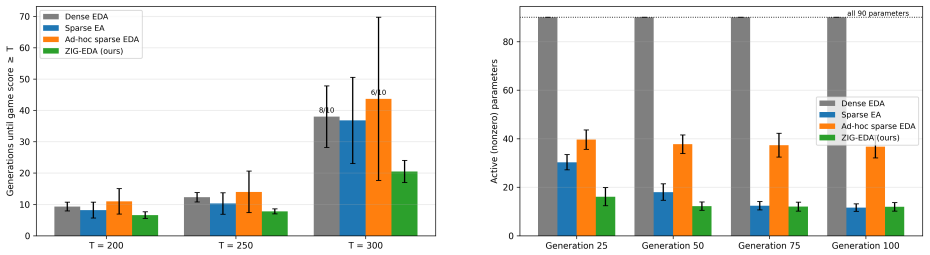
We close this gap by proposing multivariate zero-inflated Gaussian (ZIG) distributions as EDA sampling laws. A latent Gaussian model with separate indicator and value dimensions represents sparsity patterns, correlations among active parameters, and the interactions between the two, so sparsity patterns and active values are optimized jointly, hierarchy-free. We show that the latent parameters of this model are identifiable from observed samples, unlike in the missing-data settings where related constructions originate, and introduce practical amortized inversion-based estimators for them. The estimators accurately recover latent correlation structures, and on the Lunar Lander benchmark the
What carries the argument
multivariate zero-inflated Gaussian (ZIG) distributions: a latent Gaussian model with separate indicator and value dimensions that jointly represents sparsity patterns, active values, and their correlations.
If this is right
- ZIG-EDAs converge faster than dense Gaussian EDAs on the tested benchmark.
- They reach higher final returns while activating only a small fraction of the parameters.
- The latent parameters remain identifiable from observed samples, enabling the estimators.
- The approach eliminates the need for separate support-set and value optimization stages.
- The estimators recover the underlying correlation structures from the sampled data.
Where Pith is reading between the lines
- The same latent construction could be inserted into other model-based optimizers that currently assume dense distributions.
- Identifiability may allow direct use of the fitted ZIG as an interpretable model of solution structure after optimization finishes.
- Scaling the amortized estimators to higher-dimensional parameter spaces would test whether the joint modeling advantage persists.
- If the identifiability result holds for other zero-inflated families, similar extensions could apply to discrete or mixed search spaces.
Load-bearing premise
Samples drawn during the optimization process contain enough statistical information to recover the latent parameters of the zero-inflated model.
What would settle it
On synthetic data generated from a known ZIG distribution, the amortized estimators would fail to recover the true latent correlation matrix within sampling error.
Figures





read the original abstract
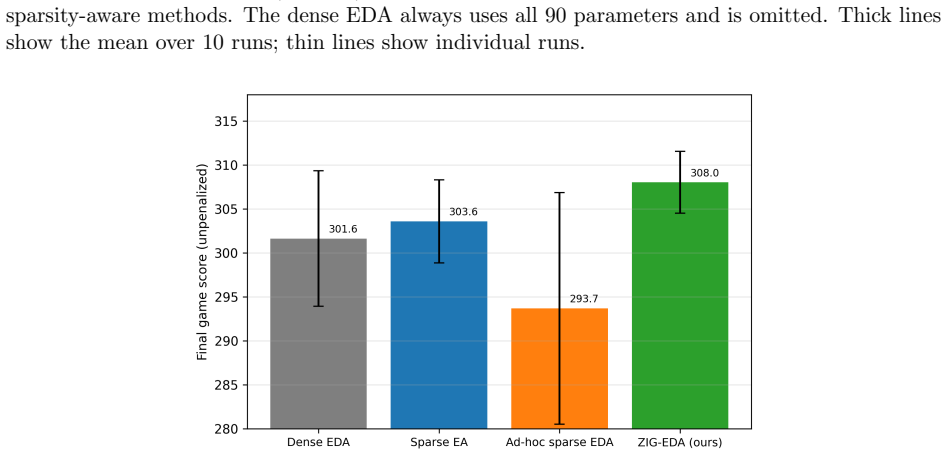
Estimation-of-distribution algorithms (EDAs) are a powerful class of evolutionary methods for black-box optimization, especially when little is known about the structure of the objective. Whereas classical evolutionary algorithms rely on hand-designed mutation and crossover operators, hard to devise for unknown problem structures, and a source of bias, EDAs sidestep operator design entirely: they fit a probability distribution to the best individuals and sample the next generation from it. EDAs are well established on continuous parameter spaces, but they have not previously been generalized to sparse ones, in which most coefficients of a good solution are exactly zero. Existing sparse black-box optimizers therefore reintroduce exactly what EDAs were designed to avoid: hand-crafted sparsity operators, bi-level schemes alternating between support set and active values, zeroing thresholds, and other baked-in assumptions. We close this gap by proposing multivariate zero-inflated Gaussian (ZIG) distributions as EDA sampling laws. A latent Gaussian model with separate indicator and value dimensions represents sparsity patterns, correlations among active parameters, and the interactions between the two, so sparsity patterns and active values are optimized jointly, hierarchy-free. We show that the latent parameters of this model are identifiable from observed samples, unlike in the missing-data settings where related constructions originate, and introduce practical amortized inversion-based estimators for them. The estimators accurately recover latent correlation structures, and on the Lunar Lander benchmark the resulting ZIG-EDA converges faster and reaches higher final returns than a dense Gaussian EDA, a hand-crafted sparse evolutionary algorithm, and an ad-hoc sparse EDA, while finding controllers with only a small fraction of parameters active.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes multivariate zero-inflated Gaussian (ZIG) distributions as sampling distributions for estimation-of-distribution algorithms (EDAs) to handle sparse parameter spaces in black-box optimization. It models sparsity via a latent Gaussian with separate indicator and value dimensions, enabling joint optimization of support patterns and active values without hand-crafted operators or bi-level schemes. The authors assert that the latent parameters (means, covariances, zero-inflation probabilities) are identifiable from observed samples—unlike in missing-data settings—and introduce amortized inversion-based estimators. On the Lunar Lander benchmark, the resulting ZIG-EDA is reported to converge faster, achieve higher returns, and produce controllers with only a small fraction of active parameters, outperforming a dense Gaussian EDA, a hand-crafted sparse evolutionary algorithm, and an ad-hoc sparse EDA.
Significance. If the identifiability claim holds and the estimators prove consistent, the work would extend EDAs to sparse domains while preserving their core advantage of avoiding hand-designed operators. The Lunar Lander results suggest empirical utility for high-dimensional controller optimization. The contribution hinges on the theoretical identifiability result and the practical reliability of the amortized estimators; without those, the joint-optimization advantage and performance claims cannot be substantiated.
major comments (1)
- [Abstract] The assertion that latent ZIG parameters are identifiable from observed samples (unlike missing-data constructions) is load-bearing for estimator consistency and the claim of hierarchy-free joint optimization of support and values. No explicit conditions, proof sketch, or derivation addressing potential degeneracies (e.g., when the Gaussian component can produce exact zeros or when mixing weights interact with means) is supplied in the abstract; this must be provided with concrete uniqueness conditions in the methods section.
minor comments (1)
- [Abstract] Quantitative details on the Lunar Lander experiments (e.g., exact fraction of active parameters, mean returns with standard errors, number of runs) would strengthen the performance claims.
Simulated Author's Rebuttal
We thank the referee for the careful review and for highlighting the centrality of the identifiability result. We will revise the manuscript to supply the requested explicit conditions, proof sketch, and degeneracy analysis in the methods section.
read point-by-point responses
-
Referee: [Abstract] The assertion that latent ZIG parameters are identifiable from observed samples (unlike missing-data constructions) is load-bearing for estimator consistency and the claim of hierarchy-free joint optimization of support and values. No explicit conditions, proof sketch, or derivation addressing potential degeneracies (e.g., when the Gaussian component can produce exact zeros or when mixing weights interact with means) is supplied in the abstract; this must be provided with concrete uniqueness conditions in the methods section.
Authors: We agree that the abstract assertion would be strengthened by explicit supporting material. The current manuscript states the identifiability result but does not yet include the detailed conditions or proof sketch in the methods. We will add a new subsection to the methods that states the concrete uniqueness conditions under which the latent means, covariances, and zero-inflation probabilities are recoverable from observed samples, provides a proof sketch, and explicitly addresses the noted degeneracies (Gaussian component producing exact zeros; mixing-weight/mean interactions). This addition will also clarify the distinction from missing-data constructions. revision: yes
Circularity Check
No circularity: derivation chain self-contained with no equations or self-citation reductions visible
full rationale
The provided abstract and text contain no equations, fitted parameters renamed as predictions, or load-bearing self-citations. The identifiability claim is asserted as a modeling result distinct from missing-data cases, without reducing to prior author work or input data by construction. Central proposal of ZIG-EDA and amortized estimators stands as independent content; no step matches any enumerated circularity pattern.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Latent Gaussian model with separate indicator and value dimensions represents sparsity patterns, correlations among active parameters, and interactions between the two
invented entities (1)
-
multivariate zero-inflated Gaussian (ZIG) distribution
no independent evidence
Reference graph
Works this paper leans on
-
[1]
Sparse and stable Markowitz portfolios
Joshua Brodie, Ingrid Daubechies, Christine De Mol, Domenico Giannone, and Ignace Loris. Sparse and stable Markowitz portfolios. Proceedings of the National Academy of Sciences of the United States of America, 106 0 (30): 0 12267--12272, 2009. doi:10.1073/pnas.0904287106
-
[2]
Conn, Katya Scheinberg, and Luis N
Andrew R. Conn, Katya Scheinberg, and Luis N. Vicente. Introduction to Derivative-Free Optimization. MOS-SIAM Series on Optimization. SIAM, Philadelphia, PA, USA, 2009. ISBN 978-0-89871-668-9
2009
-
[3]
David L. Donoho. Compressed sensing. IEEE Transactions on Information Theory, 52 0 (4): 0 1289--1306, 2006. doi:10.1109/TIT.2006.871582
-
[4]
Joseph Feldman, Jerome P. Reiter, and Daniel R. Kowal. Gaussian copula models for nonignorable missing data using auxiliary marginal quantiles. arXiv preprint arXiv:2406.03463, 2024. doi:10.48550/arXiv.2406.03463. URL https://arxiv.org/abs/2406.03463
-
[5]
Edward I. George and Robert E. McCulloch. Variable selection via Gibbs sampling. Journal of the American Statistical Association, 88 0 (423): 0 881--889, 1993. doi:10.1080/01621459.1993.10476353
-
[6]
Stochastic first- and zeroth-order methods for nonconvex stochastic programming
Saeed Ghadimi and Guanghui Lan. Stochastic first- and zeroth-order methods for nonconvex stochastic programming. SIAM Journal on Optimization, 23 0 (4): 0 2341--2368, 2013. doi:10.1137/120880811
-
[7]
DAIS : Automatic channel pruning via differentiable annealing indicator search
Yushuo Guan, Ning Liu, Pengyu Zhao, Zhengping Che, Kaigui Bian, Yanzhi Wang, and Jian Tang. DAIS : Automatic channel pruning via differentiable annealing indicator search. arXiv preprint, 2020
2020
-
[8]
Song Han, Huizi Mao, and William J. Dally. Deep compression: Compressing deep neural networks with pruning, trained quantization and Huffman coding. In Proceedings of the ICLR Workshops, 2016. Also available as arXiv:1510.00149
Pith/arXiv arXiv 2016
-
[9]
Theory of Estimation-of-Distribution Algorithms
Martin S. Krejca and Carsten Witt. Theory of estimation-of-distribution algorithms. In Benjamin Doerr and Frank Neumann, editors, Theory of Evolutionary Computation: Recent Developments in Discrete Optimization, pages 405--442. Springer, 2020. doi:10.1007/978-3-030-29414-4_9. Also available as arXiv:1806.05392
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-030-29414-4_9 2020
-
[10]
Lozano, editors
Pedro Larrañaga and Jos \'e A. Lozano, editors. Estimation of Distribution Algorithms: A New Tool for Evolutionary Computation. Kluwer Academic Publishers, Boston, MA, USA, 2002. ISBN 978-1-4615-1539-5
2002
-
[11]
Yunqiang Li, Jan C. van Gemert, Torsten Hoefler, Bert Moons, Evangelos Eleftheriou, and Bram-Ernst Verhoef. Differentiable transportation pruning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), pages 16911--16921, 2023. doi:10.1109/ICCV51070.2023.01555. URL https://arxiv.org/abs/2307.08483
-
[12]
T. J. Mitchell and J. J. Beauchamp. Bayesian variable selection in linear regression. Journal of the American Statistical Association, 83 0 (404): 0 1023--1032, 1988. doi:10.1080/01621459.1988.10478694
-
[13]
Goldberg, and Erick Cant \'u -Paz
Martin Pelikan, David E. Goldberg, and Erick Cant \'u -Paz. BOA : The Bayesian optimization algorithm. In Proceedings of the Genetic and Evolutionary Computation Conference (GECCO), pages 525--532, Orlando, Florida, USA, 1999. Morgan Kaufmann
1999
-
[14]
Pradeep Ravikumar, John Lafferty, Han Liu, and Larry Wasserman. Sparse additive models. Journal of the Royal Statistical Society: Series B (Statistical Methodology), 71 0 (5): 0 1009--1030, 2009. doi:10.1111/j.1467-9868.2009.00718.x
-
[15]
Donald B. Rubin. Inference and missing data. Biometrika, 63 0 (3): 0 581--592, 1976. doi:10.1093/biomet/63.3.581. URL https://doi.org/10.1093/biomet/63.3.581
-
[16]
Mauricio Sadinle and Jerome P. Reiter. Itemwise conditionally independent nonresponse modelling for incomplete multivariate data. Biometrika, 104 0 (1): 0 207--220, January 2017. ISSN 0006-3444. doi:10.1093/biomet/asw063. URL https://doi.org/10.1093/biomet/asw063
-
[17]
Modeling with copulas and vines in estimation of distribution algorithms
Marta Soto, Yasser González-Fernández, and Alberto Ochoa. Modeling with copulas and vines in estimation of distribution algorithms. Revista Investigación Operacional, 36 0 (1): 0 1--23, 2015
2015
-
[18]
James C. Spall. Introduction to Stochastic Search and Optimization: Estimation, Simulation, and Control. John Wiley & Sons, Hoboken, NJ, USA, 2003. ISBN 0-471-33052-3
2003
-
[19]
Regression shrinkage and selection via the Lasso
Robert Tibshirani. Regression shrinkage and selection via the Lasso . Journal of the Royal Statistical Society: Series B (Methodological), 58 0 (1): 0 267--288, 1996. doi:10.1111/j.2517-6161.1996.tb02080.x
-
[20]
Xia Wang, Wei Zhao, Jia‐Ning Tang, Zhong‐Bin Dai, and Ya‐Ning Feng. Evolution algorithm with adaptive genetic operator and dynamic scoring mechanism for large‐scale sparse many‐objective optimization. Scientific Reports, 15 0 (1): 0 9267, 2025. doi:10.1038/s41598-025-91245-z
-
[21]
Advancing model pruning via bi-level optimization
Yihua Zhang, Yuguang Yao, Parikshit Ram, Pu Zhao, Tianlong Chen, Mingyi Hong, Yanzhi Wang, and Sijia Liu. Advancing model pruning via bi-level optimization. In Proceedings of the Advances in Neural Information Processing Systems, volume 35, pages 34358--34371. Curran Associates, Inc., 2022. doi:10.48550/arXiv.2210.04092
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.