LaViSA: A Language and Vision Structural Ambiguity Benchmark
Pith reviewed 2026-06-26 20:39 UTC · model grok-4.3
The pith
Vision-language models use images to resolve some sentence ambiguities but still fail on specific types and subtle distinctions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
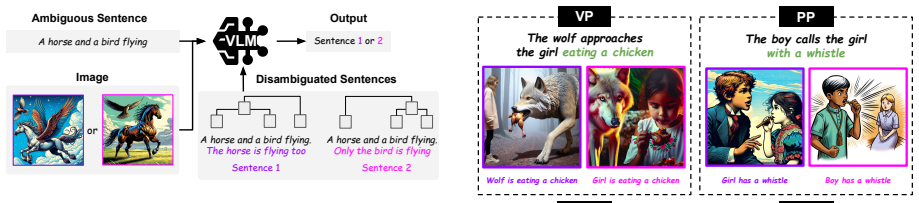
LaViSA evaluates the ability of VLMs to resolve structural ambiguity leveraging visual scenes. It consists of ambiguous sentences, their disambiguated sentences, and corresponding images of these disambiguated sentences across seven ambiguity categories. Experimental results show that although recent VLMs can leverage visual scenes to resolve structural ambiguity to some extent, they still struggle with certain ambiguity types and visually subtle semantic distinctions, indicating remaining limitations in resolving structural ambiguity using visual scenes.
What carries the argument
LaViSA benchmark, which supplies structurally ambiguous sentences paired with disambiguated interpretations and their unique visual depictions across seven categories.
If this is right
- VLMs exhibit uneven performance across the seven ambiguity categories, with some types remaining harder even when visuals are provided.
- Visually subtle semantic distinctions continue to limit model accuracy regardless of overall model scale or reasoning ability.
- Current visual-linguistic integration in models is insufficient for full resolution of structural ambiguity in all cases.
- Targeted improvements in how models map visual details to syntactic alternatives would be required to close the observed gaps.
Where Pith is reading between the lines
- The benchmark could be extended to dynamic scenes or video to test whether motion cues further aid disambiguation.
- Results point toward the value of training objectives that explicitly reward alignment between syntactic parses and visual features.
- Similar datasets in additional languages would allow testing whether the observed limitations are language-specific or general.
- The findings connect to broader efforts to make multimodal systems robust when linguistic input alone is under-specified.
Load-bearing premise
The images created for each disambiguated sentence accurately and uniquely represent only that interpretation without introducing new visual ambiguities or biases.
What would settle it
Re-running the model evaluations on a fresh set of images for the same sentences, or having independent raters judge whether each image uniquely matches only one interpretation, would show whether performance differences stem from the benchmark design itself.
Figures





read the original abstract
Structural ambiguity arises when a single sentence admits multiple valid interpretations due to its syntactic structure, posing a fundamental challenge for language understanding. Visual scenes serve as useful cues for resolving such ambiguity, and Vision and Language Models (VLMs) need to be capable of deriving possible semantic interpretations from visual scenes. We introduce Language and Vision Structural Ambiguity (LaViSA), a benchmark designed to evaluate the ability of VLMs to resolve structural ambiguity leveraging visual scenes. LaViSA consists of ambiguous sentences, their disambiguated sentences, and corresponding images of these disambiguated sentences across seven ambiguity categories. Using LaViSA, we conduct a comprehensive evaluation of diverse VLMs, including both proprietary and open-source models with varying parameter scales and reasoning capabilities. Experimental results show that although recent VLMs can leverage visual scenes to resolve structural ambiguity to a some extent, they still struggle with certain ambiguity types and visually subtle semantic distinctions, indicating remaining limitations in resolving structural ambiguity using visual scenes.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces LaViSA, a benchmark of ambiguous sentences, their disambiguated variants, and corresponding images across seven structural ambiguity categories. It evaluates a range of VLMs (proprietary and open-source) and reports that models can leverage visual scenes to resolve ambiguity to some extent but continue to struggle with certain categories and visually subtle semantic distinctions.
Significance. If the image-sentence pairs are shown to cleanly isolate the intended readings, the benchmark would offer a useful diagnostic for multimodal structural ambiguity resolution, an area where current VLMs remain limited; the work also supplies an explicit dataset that could support future controlled experiments.
major comments (2)
- [§3 and §4] §3 (Benchmark Construction) and §4 (Image Generation): the manuscript provides no inter-annotator agreement scores, no validation protocol confirming that each image uniquely supports only the target disambiguation, and no checks that images avoid introducing new visual ambiguities or exploitable biases. Because every performance number flows through these image-sentence pairs, this validation gap directly undermines attribution of model errors to limitations in 'resolving structural ambiguity using visual scenes.'
- [§5] §5 (Experiments): results are summarized at the level of 'struggle with certain ambiguity types' without per-category accuracy tables, statistical significance tests, or error analysis that isolates whether failures stem from syntactic ambiguity versus low-level visual recognition. This makes it impossible to assess whether the central claim holds after controlling for image quality.
minor comments (2)
- [Abstract] Abstract: 'to a some extent' is a typographical error.
- [Related Work] The paper does not cite prior benchmarks on syntactic ambiguity (e.g., PP-attachment or coordination ambiguity datasets) or recent VLM work on visual grounding of syntax.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and will revise the manuscript accordingly to improve the reporting of validation procedures and experimental details.
read point-by-point responses
-
Referee: [§3 and §4] §3 (Benchmark Construction) and §4 (Image Generation): the manuscript provides no inter-annotator agreement scores, no validation protocol confirming that each image uniquely supports only the target disambiguation, and no checks that images avoid introducing new visual ambiguities or exploitable biases. Because every performance number flows through these image-sentence pairs, this validation gap directly undermines attribution of model errors to limitations in 'resolving structural ambiguity using visual scenes.'
Authors: We acknowledge that the manuscript does not explicitly report inter-annotator agreement or a formal validation protocol. During benchmark construction, multiple annotators reviewed each image-sentence pair to confirm alignment with the target disambiguation and to flag potential new visual ambiguities, but these steps were not documented in detail. We will add a subsection to §3 describing the full annotation and validation process, including agreement scores and bias checks. This revision will strengthen the basis for attributing model performance to structural ambiguity resolution. revision: yes
-
Referee: [§5] §5 (Experiments): results are summarized at the level of 'struggle with certain ambiguity types' without per-category accuracy tables, statistical significance tests, or error analysis that isolates whether failures stem from syntactic ambiguity versus low-level visual recognition. This makes it impossible to assess whether the central claim holds after controlling for image quality.
Authors: We agree that more granular reporting would strengthen the experimental section. While the manuscript includes some category-level observations, we will expand §5 to include complete per-category accuracy tables, statistical significance tests across models and categories, and a dedicated error analysis distinguishing visual recognition issues from ambiguity resolution failures. These additions will better support evaluation of the central claims. revision: yes
Circularity Check
Empirical benchmark evaluation with no derivation chain
full rationale
The paper introduces LaViSA as a benchmark consisting of ambiguous sentences, disambiguated sentences, and corresponding images across seven categories, then reports direct empirical evaluations of VLMs on this dataset. No equations, fitted parameters, predictions derived from inputs, or self-citation chains appear in the manuscript. All reported results are measurements on the constructed benchmark rather than reductions of claims to prior self-defined quantities, rendering the work self-contained with no circularity in any derivation.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Visual scenes provide sufficient cues to resolve syntactic structural ambiguity in language.
Reference graph
Works this paper leans on
-
[1]
and Ullman, Jeffrey D
Aho, Alfred V. and Ullman, Jeffrey D. , title =. 1972 , isbn =
1972
-
[2]
Publications Manual , year =
-
[3]
Chandra and Dexter C
Ashok K. Chandra and Dexter C. Kozen and Larry J. Stockmeyer , year =. Alternation , journal =
-
[4]
Scalable training of
Andrew, Galen and Gao, Jianfeng , booktitle=. Scalable training of. 2007 , url =
2007
-
[5]
1997 , publisher =
Dan Gusfield , title =. 1997 , publisher =
1997
-
[6]
Tetreault , year =
Mohammad Sadegh Rasooli and Joel R. Tetreault , year =
-
[7]
Journal of Machine Learning Research , year =
Rie Kubota Ando and Tong Zhang , title =. Journal of Machine Learning Research , year =
-
[8]
Studia Linguistica , year=
Ambiguity in Linguistics1 , author=. Studia Linguistica , year=
-
[9]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[10]
Proceedings of the 11th International Conference on Learning Representations , year=
When and why vision-language models behave like bags-of-words, and what to do about it? , author=. Proceedings of the 11th International Conference on Learning Representations , year=
-
[11]
Berzak, Yevgeni and Barbu, Andrei and Harari, Daniel and Katz, Boris and Ullman, Shimon , booktitle =. Do You See What. 2015 , url =. doi:10.18653/v1/D15-1172 , pages =
-
[12]
Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
Resolving Ambiguities in Text-to-Image Generative Models , author =. Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics , year =
-
[13]
Computer Science , volume=
Improving image generation with better captions , author=. Computer Science , volume=. 2023 , url=
2023
-
[14]
2023 , howpublished=
Hierarchical Text-Conditional Image Generation with CLIP Latents , author=. 2023 , howpublished=
2023
-
[15]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
Rombach, Robin and Blattmann, Andreas and Lorenz, Dominik and Esser, Patrick and Ommer, Bj\"orn , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year=
-
[16]
Proceedings of the 38th International Conference on Machine Learning , pages =
Learning Transferable Visual Models From Natural Language Supervision , author =. Proceedings of the 38th International Conference on Machine Learning , pages =. 2021 , volume =
2021
-
[17]
Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
Zhai, Xiaohua and Mustafa, Basil and Kolesnikov, Alexander and Beyer, Lucas , title =. Proceedings of the IEEE/CVF International Conference on Computer Vision , year =
-
[18]
2024 , howpublished=
Building and better understanding vision-language models: insights and future directions , author=. 2024 , howpublished=
2024
-
[19]
Tang, Yingtian and Yamada, Yutaro and Zhang, Yoyo and Yildirim, Ilker , booktitle =. 2023 , url =. doi:10.18653/v1/2023.emnlp-main.886 , pages =
-
[20]
An Examination of the Compositionality of Large Generative Vision-Language Models
Ma, Teli and Li, Rong and Liang, Junwei. An Examination of the Compositionality of Large Generative Vision-Language Models. Proceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2024. doi:10.18653/v1/2024.naacl-long.39
-
[21]
2024 , url=
Irene Huang and Wei Lin and Muhammad Jehanzeb Mirza and Jacob A Hansen and Sivan Doveh and Victor Ion Butoi and Roei Herzig and Assaf Arbelle and Hilde Kuehne and Trevor Darrell and Chuang Gan and Aude Oliva and Rogerio Feris and Leonid Karlinsky , booktitle=. 2024 , url=
2024
-
[22]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Mitra, Chancharik and Huang, Brandon and Darrell, Trevor and Herzig, Roei , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[23]
Holographic
Yamaki, Ryosuke and Taniguchi, Tadahiro and Mochihashi, Daichi , booktitle =. Holographic. 2023 , url =
2023
-
[24]
Michael Tschannen and Alexey Gritsenko and Xiao Wang and Muhammad Ferjad Naeem and Ibrahim M. Alabdulmohsin and Nikhil Parthasarathy and Talfan Evans and Lucas Beyer and Ye Xia and Basil Mustafa and Olivier H'enaff and Jeremiah Harmsen and Andreas Steiner and Xiao-Qi Zhai , year=
-
[25]
Demystifying
Hu Xu and Saining Xie and Xiaoqing Tan and Po-Yao Huang and Russell Howes and Vasu Sharma and Shang-Wen Li and Gargi Ghosh and Luke Zettlemoyer and Christoph Feichtenhofer , booktitle=. Demystifying. 2024 , url=
2024
-
[26]
Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
Cherti, Mehdi and Beaumont, Romain and Wightman, Ross and Wortsman, Mitchell and Ilharco, Gabriel and Gordon, Cade and Schuhmann, Christoph and Schmidt, Ludwig and Jitsev, Jenia , title =. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition , year =
-
[27]
Quan Sun and Yuxin Fang and Ledell Yu Wu and Xinlong Wang and Yue Cao , year=
-
[28]
Weinberger and Yoav Artzi , booktitle=
Tianyi Zhang and Varsha Kishore and Felix Wu and Kilian Q. Weinberger and Yoav Artzi , booktitle=. 2020 , url=
2020
-
[29]
2013 , url =
Banarescu, Laura and Bonial, Claire and Cai, Shu and Georgescu, Madalina and Griffitt, Kira and Hermjakob, Ulf and Knight, Kevin and Koehn, Philipp and Palmer, Martha and Schneider, Nathan , booktitle =. 2013 , url =
2013
-
[30]
2013 , url =
Cai, Shu and Knight, Kevin , booktitle =. 2013 , url =
2013
-
[31]
Bleu: a method for automatic evaluation of machine translation
Papineni, Kishore and Roukos, Salim and Ward, Todd and Zhu, Wei-Jing , booktitle =. 2002 , url =. doi:10.3115/1073083.1073135 , pages =
-
[32]
Liu, Haotian and Li, Chunyuan and Li, Yuheng and Li, Bo and Zhang, Yuanhan and Shen, Sheng and Lee, Yong Jae , year=
-
[33]
2025 , howpublished=
Gemma 3 Technical Report , author=. 2025 , howpublished=
2025
-
[34]
Shuai Bai and Keqin Chen and Xuejing Liu and Jialin Wang and Wenbin Ge and Sibo Song and Kai Dang and Peng Wang and Shijie Wang and Jun Tang and Humen Zhong and Yuanzhi Zhu and Mingkun Yang and Zhaohai Li and Jianqiang Wan and Pengfei Wang and Wei Ding and Zheren Fu and Yiheng Xu and Jiabo Ye and Xi Zhang and Tianbao Xie and Zesen Cheng and Hang Zhang and...
-
[35]
Pixtral 12
Pravesh Agrawal and Szymon Antoniak and Emma Bou Hanna and Devendra Singh Chaplot and Jessica Chudnovsky and Saurabh Garg and Th. Pixtral 12. 2024 , howpublished=
2024
-
[36]
2024 , howpublished=
2024
-
[37]
Proceedings of the 12th Conference of the
Learning to Interpret Utterances Using Dialogue History , author =. Proceedings of the 12th Conference of the. 2009 , url =
2009
-
[38]
Widiaputri, Ruhiyah and Purwarianti, Ayu and Lestari, Dessi and Azizah, Kurniawati and Tanaya, Dipta and Sakti, Sakriani , booktitle =. Speech Recognition and Meaning Interpretation: Towards Disambiguation of Structurally Ambiguous Spoken Utterances in. 2023 , url =. doi:10.18653/v1/2023.emnlp-main.1045 , pages =
-
[39]
Proceedings of the 31st International Conference on Computational Linguistics , year =
Does Vision Accelerate Hierarchical Generalization in Neural Language Learners? , author =. Proceedings of the 31st International Conference on Computational Linguistics , year =
-
[40]
Frontiers in Psychology , year=
Why Is There So Much More Research on Vision Than on Any Other Sensory Modality? , author=. Frontiers in Psychology , year=
-
[41]
User Intent Recognition and Satisfaction with Large Language Models: A User Study with
Anna Bodonhelyi and Efe Bozkir and Shuo Yang and Enkelejda Kasneci and Gjergji Kasneci , howpublished =. User Intent Recognition and Satisfaction with Large Language Models: A User Study with. 2024 , url =
2024
-
[42]
2024 , howpublished =
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author =. 2024 , howpublished =
2024
-
[43]
Gemini 3.1
Google , howpublished=. Gemini 3.1. 2025 , url=
2025
-
[44]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
Deep Residual Learning for Image Recognition , author=. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year=
-
[45]
An Image is Worth
Alexey Dosovitskiy and Lucas Beyer and Alexander Kolesnikov and Dirk Weissenborn and Xiaohua Zhai and Thomas Unterthiner and Mostafa Dehghani and Matthias Minderer and Georg Heigold and Sylvain Gelly and Jakob Uszkoreit and Neil Houlsby , booktitle=. An Image is Worth. 2020 , url=
2020
-
[46]
Zhuang Liu and Hanzi Mao and Chaozheng Wu and Christoph Feichtenhofer and Trevor Darrell and Saining Xie , booktitle=. A. 2022 , pages=
2022
-
[47]
Zettlemoyer and Xinlei Chen and Zhuang Liu and Saining Xie and Wen-tau Yih and Shang-Wen Li and Hu Xu , year=
Yung-Sung Chuang and Yang Li and Dong Wang and Ching-Feng Yeh and Kehan Lyu and Ramya Raghavendra and James Glass and Lifei Huang and Jason Weston and Luke S. Zettlemoyer and Xinlei Chen and Zhuang Liu and Saining Xie and Wen-tau Yih and Shang-Wen Li and Hu Xu , year=. Meta
-
[48]
Journal of the American Statistical Association , year=
Probable Inference, the Law of Succession, and Statistical Inference , author=. Journal of the American Statistical Association , year=
-
[49]
When are Lemons Purple? The Concept Association Bias of
Yutaro Yamada and Yingtian Tang and Ilker Yildirim , booktitle =. When are Lemons Purple? The Concept Association Bias of. 2023 , pages =
2023
-
[50]
2025 , number=
Jiwan Chung and Seungwon Lim and Sangkyu Lee and Youngjae Yu , booktitle=. 2025 , number=
2025
-
[51]
2025 , url =
Xiaolong Wang and Zhaolu Kang and Wangyuxuan Zhai and Xinyue Lou and Yunghwei Lai and Ziyue Wang and Yawen Wang and Kaiyu Huang and Yile Wang and Peng Li and Yang Liu , booktitle =. 2025 , url =
2025
-
[52]
Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =
Can visual language models resolve textual ambiguity with visual cues? Let visual puns tell you! , author =. Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing , pages =. 2024 , url =
2024
-
[53]
Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year =
Shun Inadumi and Seiya Kawano and Akishige Yuguchi and Yasutomo Kawanishi and Koichiro Yoshino , title =. Proceedings of the 2024 Joint International Conference on Computational Linguistics, Language Resources and Evaluation , year =
2024
-
[54]
OpenAI , howpublished=
-
[55]
2025 , url=
Shuai Bai and Yuxuan Cai and Ruizhe Chen and Keqin Chen and Xiong-Hui Chen and Zesen Cheng and Lianghao Deng and Wei Ding and Rongyao Fang and Chang Gao and Chunjiang Ge and Wenbin Ge and Zhifang Guo and Qidong Huang and Jie Huang and Fei Huang and Binyuan Hui and Shutong Jiang and Zhaohai Li and Mingsheng Li and Mei Li and Kaixin Li and Zicheng Lin and J...
2025
-
[56]
2020 , booktitle =
A Simple Framework for Contrastive Learning of Visual Representations , author =. 2020 , booktitle =
2020
-
[57]
Proceedings of the 34th International Conference on Neural Information Processing Systems , year =
Supervised Contrastive Learning , author =. Proceedings of the 34th International Conference on Neural Information Processing Systems , year =
-
[58]
Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing , pages =
Learning Semantic Representations of Users and Products for Document Level Sentiment Classification , author=. Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing , pages =. 2015 , url=
2015
-
[59]
Understanding Natural Language Commands for Robotic Navigation and Mobile Manipulation , booktitle=
Tellex, Stefanie and Kollar, Thomas and Dickerson, Steven and Walter, Matthew and Banerjee, Ashis and Teller, Seth and Roy, Nicholas , year=. Understanding Natural Language Commands for Robotic Navigation and Mobile Manipulation , booktitle=
-
[60]
Proceedings of the Robotics Science and Systems , year=
Asking for Help Using Inverse Semantics , author=. Proceedings of the Robotics Science and Systems , year=
-
[61]
2020 , pages=
Mohit Shridhar and Jesse Thomason and Daniel Gordon and Yonatan Bisk and Winson Han and Roozbeh Mottaghi and Luke Zettlemoyer and Dieter Fox , booktitle=. 2020 , pages=
2020
-
[62]
Artificial Intelligence , year=
Connecting language to the world , author=. Artificial Intelligence , year=. doi:https://doi.org/10.1016/j.artint.2005.06.002 , url =
-
[63]
2005 , doi =
Word sense disambiguation with pictures , journal =. 2005 , doi =
2005
-
[64]
2005 , doi =
Choosing words in computer-generated weather forecasts , journal =. 2005 , doi =
2005
-
[65]
2005 , doi =
Semiotic schemas: A framework for grounding language in action and perception , journal =. 2005 , doi =
2005
-
[66]
2024 , howpublished=
DeepSeek-V3 Technical Report , author=. 2024 , howpublished=
2024
-
[67]
Bo Li and Yuanhan Zhang and Dong Guo and Renrui Zhang and Feng Li and Hao Zhang and Kaichen Zhang and Yanwei Li and Ziwei Liu and Chunyuan Li , year=
-
[68]
Structural Ambiguity and Lexical Relations
Hindle, Donald and Rooth, Mats. Structural Ambiguity and Lexical Relations. Computational Linguistics. 1993
1993
-
[69]
Aspects of the Theory of Syntax , year =
Noam Chomsky , publisher =. Aspects of the Theory of Syntax , year =
-
[70]
Proceedings of the 10th Linguistic Annotation Workshop held in conjunction with
Generating Disambiguating Paraphrases for Structurally Ambiguous Sentences , author =. Proceedings of the 10th Linguistic Annotation Workshop held in conjunction with. 2016 , url =. doi:10.18653/v1/W16-1718 , pages =
-
[71]
Why Did the Chicken Cross the Road? Rephrasing and Analyzing Ambiguous Questions in
Stengel-Eskin, Elias and Guallar-Blasco, Jimena and Zhou, Yi and Van Durme, Benjamin , booktitle =. Why Did the Chicken Cross the Road? Rephrasing and Analyzing Ambiguous Questions in. 2023 , url =. doi:10.18653/v1/2023.acl-long.569 , pages =
-
[72]
Challenges of Syntactic Ambiguity in ESL Learners: A Case Study of QUEST Nawabshah , volume =
Chandio, Ali and Oad, Shan and Tunio, Wazir , journal =. Challenges of Syntactic Ambiguity in ESL Learners: A Case Study of QUEST Nawabshah , volume =. 2025 , pages =
2025
-
[73]
Samuel Joseph Amouyal and Aya Meltzer-Asscher and Jonathan Berant , booktitle=. When the. 2025 , url =. doi:10.18653/v1/2025.acl-long.403 , pages =
-
[74]
2024 , howpublished=
Syntactic Surprisal From Neural Models Predicts, But Underestimates, Human Processing Difficulty From Syntactic Ambiguities , author=. 2024 , howpublished=
2024
-
[75]
Language, Cognition and Neuroscience , year=
On the parsing of garden-path sentences , author=. Language, Cognition and Neuroscience , year=
-
[76]
Quarterly Journal of Experimental Psychology , year=
The interaction of visual and linguistic saliency during syntactic ambiguity resolution , author=. Quarterly Journal of Experimental Psychology , year=
-
[77]
International Conference on Language Resources and Evaluation , year=
Adding Syntactic Annotations to Flickr30k Entities Corpus for Multimodal Ambiguous Prepositional-Phrase Attachment Resolution , author=. International Conference on Language Resources and Evaluation , year=
-
[78]
Kankan Zhou and Eason Lai and Kyriakos Mouratidis and Jing Jiang , booktitle=. 2025 , volume =. doi:10.18653/v1/2025.acl-long.1337 , pages =
-
[79]
A Safety Report on
Xingjun Ma and Yixu Wang and Hengyuan Xu and Yutao Wu and Yifan Ding and Yunhan Zhao and Zilong Wang and Jiabin Hua and Ming Wen and Jianan Liu and Ranjie Duan and Yifeng Gao and Yingshui Tan and Yunhao Chen and Hui Xue and Xin Wang and Wei Cheng and Jingjing Chen and Zuxuan Wu and Bo Li and Yu-Gang Jiang , year=. A Safety Report on
-
[80]
Xiang An and Yin Xie and Kaicheng Yang and Wenkang Zhang and Xiuwei Zhao and Zhengxue Cheng and Yirui Wang and Songcen Xu and Changrui Chen and Chun Yat Wu and Huajie Tan and Chunyuan Li and Jing Yang and Jiecao Yu and Xiyao Wang and Bin Qin and Yumeng Wang and Zizhen Yan and Ziyong Feng and Ziwei Liu and Bo Li and Jiankang Deng , year=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.