Mix-QVLA: Task-Evidence-Aware Mixed-Precision Quantization of Vision-Language-Action Models
Pith reviewed 2026-06-26 20:55 UTC · model grok-4.3
The pith
Task-evidence maps guide mixed-precision bit allocation in VLA models to preserve action decisions under size and compute limits.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
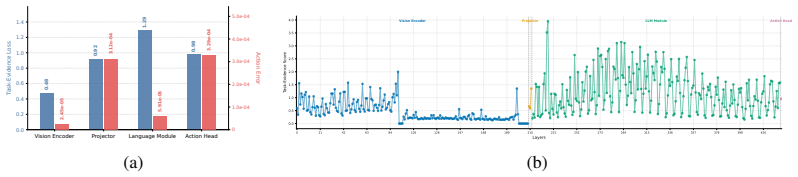
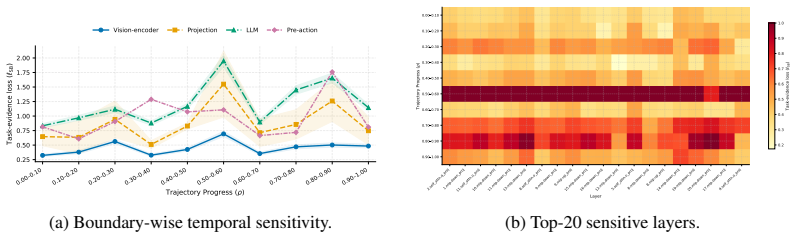
Mix-QVLA computes normalized gradient-weighted task-evidence maps from boundary activations and compares full-precision and quantized maps using evidence-mass and attribution-distribution distortion to capture changes in both the strength and allocation of decision-supporting evidence; a soft-bottleneck objective aggregates boundary-level degradation into layer-wise sensitivity scores that vary over task execution, and the resulting evidence- and time-aware scores guide mixed-precision bit allocation under model-size and BitOps budgets.
What carries the argument
normalized gradient-weighted task-evidence maps from boundary activations, compared using evidence-mass and attribution-distribution distortion
If this is right
- Evidence- and time-aware scores improve the accuracy-efficiency trade-off for low-bit VLA deployment compared with fixed-sensitivity methods.
- On the LIBERO benchmark, OpenVLA-OFT memory drops from 15.4 GB to 4.1 GB while average success stays at 96.3 versus 97.1 for the BF16 model.
- The same allocation yields a 1.52x inference speedup.
- Modeling sensitivity throughout task execution captures phase-dependent shifts in layer importance.
Where Pith is reading between the lines
- The boundary-focused evidence tracking could be adapted to measure quantization effects in other sequential multimodal models.
- Phase-dependent sensitivity implies that static bit assignments may leave performance on the table in tasks with clear execution stages.
- If the maps prove reliable, they could serve as a diagnostic for identifying which layers matter most for action correctness in VLA architectures.
Load-bearing premise
Normalized gradient-weighted task-evidence maps from boundary activations together with evidence-mass and attribution-distribution distortion reliably indicate whether quantization has preserved the information needed for correct task decisions.
What would settle it
A case in which a quantized model shows low map distortion yet produces wrong actions on a held-out task, or high distortion yet produces correct actions, would directly test whether the maps track decision-supporting evidence.
Figures

read the original abstract
We propose Mix-QVLA, a task-evidence-aware mixed-precision PTQ framework for VLA models. Mix-QVLA anchors each quantized variant to the full-precision action-token reference decision and evaluates whether quantization preserves task-relevant evidence across key VLA functional boundaries. It computes normalized gradient-weighted task-evidence maps from boundary activations and compares full-precision and quantized maps using evidence-mass and attribution-distribution distortion, capturing changes in both the strength and allocation of decision-supporting evidence. A soft-bottleneck objective aggregates boundary-level degradation into layer-wise sensitivity scores. Mix-QVLA further models sensitivity throughout task execution, capturing phase-dependent shifts in layer importance rather than assuming a fixed sensitivity profile. The resulting evidence- and time-aware scores guide mixed-precision bit allocation under model-size and BitOps budgets. Extensive evaluations on OpenVLA-style policies show that Mix-QVLA improves the accuracy-efficiency trade-off of low-bit VLA deployment. On LIBERO, Mix-QVLA reduces OpenVLA-OFT memory from 15.4 GB to 4.1 GB, retains 96.3 average success compared with 97.1 for the BF16 model, and achieves a 1.52x inference speedup.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes Mix-QVLA, a task-evidence-aware mixed-precision post-training quantization (PTQ) framework for Vision-Language-Action (VLA) models. It anchors quantized variants to full-precision action-token references, computes normalized gradient-weighted task-evidence maps from boundary activations, and compares full- and low-precision maps via evidence-mass and attribution-distribution distortion metrics. These feed a soft-bottleneck objective yielding layer-wise, phase-dependent sensitivity scores that guide bit allocation under model-size and BitOps constraints. On the LIBERO benchmark with OpenVLA-OFT, the method reduces memory from 15.4 GB to 4.1 GB while retaining 96.3 average success rate (vs. 97.1 for BF16) and achieving 1.52x inference speedup.
Significance. If the central results hold, the work demonstrates a practical route to deploy large VLA policies under tight memory and latency budgets with only marginal task degradation. The explicit use of task-evidence preservation metrics and time-varying sensitivity modeling distinguishes the approach from generic quantization heuristics; the direct reporting of downstream success rates on LIBERO provides an end-to-end falsifiable test of the allocation policy.
major comments (1)
- [Abstract] Abstract: the reported LIBERO gains rest on the assumption that normalized gradient-weighted task-evidence maps, evidence-mass, and attribution-distribution distortion reliably indicate whether quantization has preserved information needed for correct task decisions; however, the abstract supplies no validation that these maps correlate with actual task failure modes or details of how the bit-allocation optimization was performed, leaving the link between the proposed metrics and the observed 96.3 success rate unverified.
minor comments (2)
- Notation for the soft-bottleneck objective and the precise definition of boundary activations should be clarified with an explicit equation or pseudocode block.
- The manuscript would benefit from an ablation isolating the contribution of the time-dependent sensitivity modeling versus a static profile.
Simulated Author's Rebuttal
We thank the referee for the detailed review and constructive comment on the abstract. We address the concern point-by-point below and propose a targeted revision to strengthen the abstract's clarity without altering the manuscript's core claims.
read point-by-point responses
-
Referee: [Abstract] Abstract: the reported LIBERO gains rest on the assumption that normalized gradient-weighted task-evidence maps, evidence-mass, and attribution-distribution distortion reliably indicate whether quantization has preserved information needed for correct task decisions; however, the abstract supplies no validation that these maps correlate with actual task failure modes or details of how the bit-allocation optimization was performed, leaving the link between the proposed metrics and the observed 96.3 success rate unverified.
Authors: We agree that the abstract is necessarily concise and does not itself contain the validation or optimization details. The full manuscript addresses this in Section 3 (method), where Algorithm 1 and the soft-bottleneck formulation (Eq. 7) specify the bit-allocation procedure under memory/BitOps constraints; Section 4.2 details the gradient-weighted evidence map computation and the two distortion metrics; and Section 5.2–5.3 report ablations that directly correlate evidence-mass and attribution-distribution distortion with per-task success rates on LIBERO (including cases where high distortion predicts failure modes). The end-to-end 96.3 success rate is the falsifiable outcome of applying these metrics. To improve readability, we will revise the abstract to add one sentence referencing the empirical correlation between the metrics and task outcomes. revision: yes
Circularity Check
No significant circularity
full rationale
The paper presents a heuristic PTQ framework that derives layer sensitivity scores from gradient-weighted evidence maps, evidence-mass, and attribution distortion computed on the model under test. These scores then guide bit allocation under explicit size/BitOps constraints. The central performance claims (memory reduction, success rate retention, speedup on LIBERO) are obtained by direct end-to-end evaluation on an external benchmark rather than by any algebraic reduction of the reported metrics to quantities fitted from the same data. No self-definitional equations, fitted-input predictions, or load-bearing self-citations appear in the derivation chain.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Changes in normalized gradient-weighted task-evidence maps from boundary activations indicate whether quantization preserves task-relevant evidence.
Reference graph
Works this paper leans on
-
[1]
Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
Moo Jin Kim, Karl Pertsch, Siddharth Karamcheti, Ted Xiao, Ashwin Balakrishna, Suraj Nair, Rafael Rafailov, Ethan Foster, Grace Lam, Pannag Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246,
-
[2]
Moo Jin Kim, Chelsea Finn, and Percy Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645,
-
[3]
π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
Physical Intelligence, Kevin Black, Noah Brown, James Darpinian, Karan Dhabalia, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, et al. π0.5: a vision-language-action model with open-world generalization.arXiv preprint arXiv:2504.16054,
-
[4]
Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
Johan Bjorck, Fernando Castañeda, Nikita Cherniadev, Xingye Da, Runyu Ding, Linxi Fan, Yu Fang, Dieter Fox, Fengyuan Hu, Spencer Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734,
-
[5]
Yantai Yang, Yuhao Wang, Zichen Wen, Luo Zhongwei, Chang Zou, Zhipeng Zhang, Chuan Wen, and Linfeng Zhang. Efficientvla: Training-free acceleration and compression for vision-language- action models.arXiv preprint arXiv:2506.10100,
-
[6]
Yuhao Xu, Yantai Yang, Zhenyang Fan, Yufan Liu, Yuming Li, Bing Li, and Zhipeng Zhang. Qvla: Not all channels are equal in vision-language-action model’s quantization.arXiv preprint arXiv:2602.03782, 2026a. Zihao Zheng, Hangyu Cao, Sicheng Tian, Jiayu Chen, Maoliang Li, Xinhao Sun, Hailong Zou, Zhaobo Zhang, Xuanzhe Liu, Donggang Cao, et al. Dyq-vla: Temp...
-
[7]
Jingxuan Zhang, Yunta Hsieh, Zhongwei Wan, Haokun Lin, Xin Wang, Ziqi Wang, Yingtie Lei, and Mi Zhang. Quantvla: Scale-calibrated post-training quantization for vision-language-action models.arXiv preprint arXiv:2602.20309, 2026a. Siyuan Xu, Tianshi Wang, Fengling Li, Lei Zhu, and Heng Tao Shen. Da-ptq: Drift-aware post- training quantization for efficien...
-
[8]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Han Zhao, Wei Zhao, Zhide Zhong, Zongyuan Ge, Jun Ma, and Haoang Li. Accelerating vision-language-action model integrated with action chunking via parallel decoding.arXiv preprint arXiv:2503.02310, 2025a. Rongyu Zhang, Menghang Dong, Yuan Zhang, Liang Heng, Xiaowei Chi, Gaole Dai, Li Du, Dan Wang, Yuan Du, and Sha...
-
[9]
Elias Frantar, Saleh Ashkboos, Torsten Hoefler, and Dan Alistarh. Gptq: Accurate post-training quantization for generative pre-trained transformers.arXiv preprint arXiv:2210.17323,
-
[10]
Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111,
Qingwen Bu, Yanting Yang, Jisong Cai, Shenyuan Gao, Guanghui Ren, Maoqing Yao, Ping Luo, and Hongyang Li. Univla: Learning to act anywhere with task-centric latent actions.arXiv preprint arXiv:2505.06111,
-
[11]
Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
Octo Model Team, Dibya Ghosh, Homer Walke, Karl Pertsch, Kevin Black, Oier Mees, Sudeep Dasari, Joey Hejna, Tobias Kreiman, Charles Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213,
-
[12]
Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864,
Songming Liu, Lingxuan Wu, Bangguo Li, Hengkai Tan, Huayu Chen, Zhengyi Wang, Ke Xu, Hang Su, and Jun Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864,
-
[13]
π_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
Kevin Black, Noah Brown, Danny Driess, Adnan Esmail, Michael Equi, Chelsea Finn, Niccolo Fusai, Lachy Groom, Karol Hausman, Brian Ichter, et al. π_0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164,
-
[14]
Wenxuan Song, Jiayi Chen, Pengxiang Ding, Yuxin Huang, Han Zhao, Donglin Wang, and Haoang Li. Ceed-vla: Consistency vision-language-action model with early-exit decoding.arXiv preprint arXiv:2506.13725, 2025b. Wenqi Shao, Mengzhao Chen, Zhaoyang Zhang, Peng Xu, Lirui Zhao, Zhiqian Li, Kaipeng Zhang, Peng Gao, Yu Qiao, and Ping Luo. Omniquant: Omnidirectio...
-
[15]
Feng Jiang, Zihao Zheng, Xiuping Cui, Maoliang Li, JIayu Chen, and Xiang Chen. Eaqvla: Encoding- aligned quantization for vision-language-action models.arXiv preprint arXiv:2505.21567,
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.