SAC: Disaggregated KV Cache System for Sparse Attention LLMs with CXL
Pith reviewed 2026-06-26 16:20 UTC · model grok-4.3
The pith
SAC fetches only the active top-k KV entries via CXL during decoding instead of pulling entire prefix caches as RDMA systems do.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
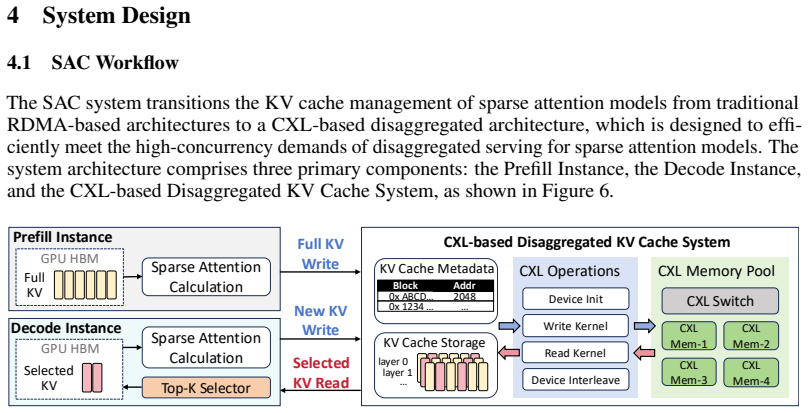
SAC is the first disaggregated KV cache system built for sparse attention models; it uses CXL load/store semantics to fetch only the required top-k KV entries at cache-line granularity during inference, delivering 2.1x higher throughput, 9.7x lower TTFT, and 1.8x lower TBT versus RDMA baselines on DeepSeek-V3.2 with SGLang.
What carries the argument
CXL on-demand fetch of only the active top-k KV cache entries at cache-line granularity.
If this is right
- Long-context sparse models can be served with far less local DRAM because only active entries occupy space.
- Disaggregation stops being bandwidth-wasteful once fetching is limited to the sparse active subset.
- Decoding latency drops because data movement volume shrinks from the full prefix to the top-k subset.
Where Pith is reading between the lines
- If CXL links become contended, software could add lightweight prediction of next active entries to hide latency.
- The same on-demand mechanism might extend to hybrid dense-sparse attention workloads by routing dense blocks differently.
- Memory-pool designers could expose CXL cache-line primitives directly to inference runtimes rather than treating them as generic remote memory.
Load-bearing premise
CXL hardware supplies low-latency remote access at cache-line size without hidden contention or coherence costs that would cancel the reported gains once the full KV cache is not kept locally.
What would settle it
Run the same workload with KV cache sizes larger than local memory under increasing request concurrency and measure whether SAC's latency and throughput advantages over RDMA persist or shrink.
Figures





















read the original abstract
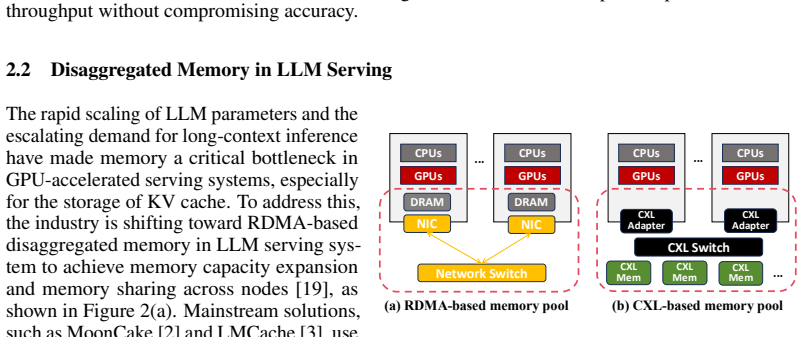
The scaling of LLMs toward long-context inference has shifted the primary serving system bottleneck from computation to memory capacity. Traditional solutions for dense attention models rely on RDMA-based disaggregated memory pools, which perform coarse-grained fetching of the entire prefix KV cache from remote storage to local memory before decoding. However, this approach is fundamentally inefficient for emerging sparse attention models. While only a small fraction of KV entries are active during decoding, these systems still fetch the full KV cache locally, leading to severe transmission bottlenecks and local memory wastage. To address this, we propose SAC, the first efficient disaggregated KV cache system optimized for sparse attention models. By leveraging the low-latency, cache-line granularity load/store semantics of Compute Express Link (CXL), SAC fetches only the required top-k KV entries on demand during inference. Evaluations on DeepSeek-V3.2 using SGLang show that SAC achieves 2.1x higher throughput, 9.7x lower TTFT, and 1.8x lower TBT compared to RDMA-based baselines, establishing CXL-based disaggregation as the superior infrastructure for emerging sparse attention models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes SAC, the first disaggregated KV cache system for sparse attention LLMs. It uses CXL's cache-line-granular load/store semantics to fetch only the required top-k KV entries on demand during decoding, avoiding the full-prefix fetches required by RDMA-based disaggregation. Empirical evaluation on DeepSeek-V3.2 with SGLang reports 2.1x higher throughput, 9.7x lower TTFT, and 1.8x lower TBT versus RDMA baselines.
Significance. If the reported gains are reproducible, the work would be significant for LLM inference systems. It identifies a concrete mismatch between coarse-grained RDMA disaggregation and the access patterns of sparse attention, and supplies an infrastructure-level alternative (CXL) that could reduce both transmission volume and local memory footprint for long-context serving.
major comments (2)
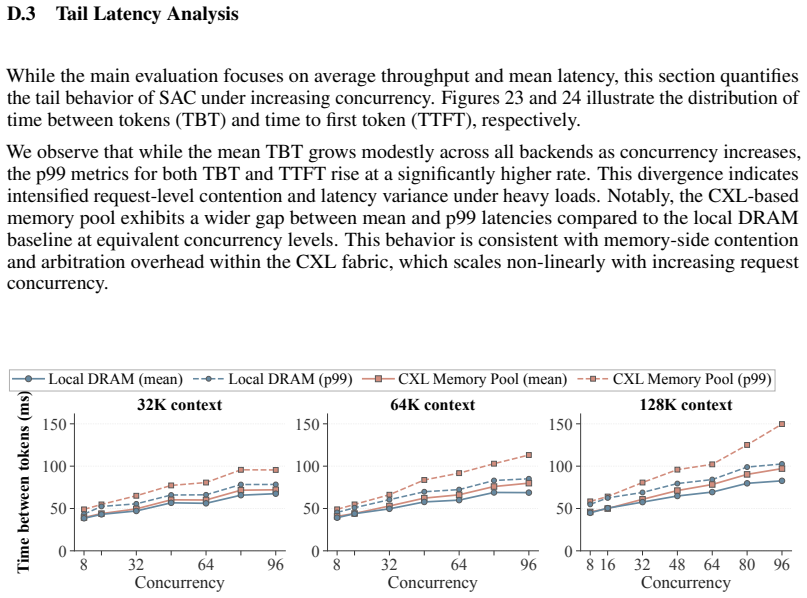
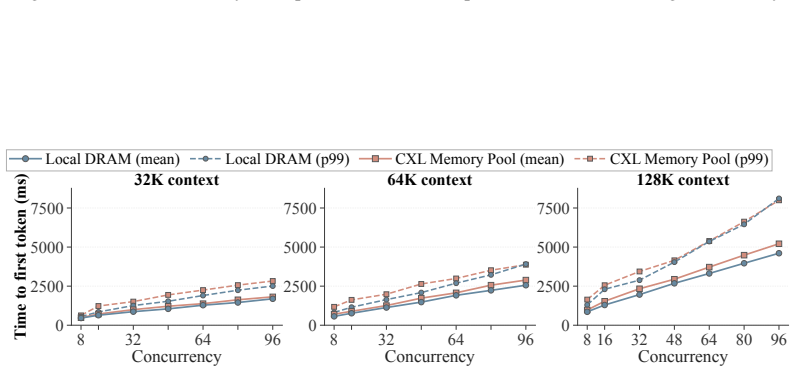
- [§5 (Evaluation)] §5 (Evaluation): The central performance claims (2.1x throughput, 9.7x TTFT, 1.8x TBT) are stated without any description of the experimental setup, hardware configuration (CXL vs. RDMA NICs, cache sizes, multi-tenancy), workload details, number of runs, or error bars. This information is load-bearing for assessing whether the empirical advantage holds.
- [§3 (System Design)] §3 (System Design) and §5: The manuscript does not measure or bound CXL coherence traffic, NUMA contention, or protocol overhead when only sparse top-k entries are touched under realistic cache sizes or concurrent tenants. Without such data, it is unclear whether the fine-grained access advantage survives at scale, which directly affects the comparison to bulk RDMA.
minor comments (2)
- [Abstract] Abstract and §1: The phrase 'the first efficient' should be qualified with a brief related-work comparison to avoid overstatement.
- Figure captions and legends should explicitly state the workload, model, and hardware parameters used for each plotted point.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address the two major comments below and commit to revisions that strengthen the manuscript's reproducibility and analysis.
read point-by-point responses
-
Referee: [§5 (Evaluation)] §5 (Evaluation): The central performance claims (2.1x throughput, 9.7x TTFT, 1.8x TBT) are stated without any description of the experimental setup, hardware configuration (CXL vs. RDMA NICs, cache sizes, multi-tenancy), workload details, number of runs, or error bars. This information is load-bearing for assessing whether the empirical advantage holds.
Authors: We agree that the absence of detailed experimental setup information limits the ability to assess and reproduce the reported gains. In the revised manuscript we will expand §5 with a dedicated subsection describing: (1) exact hardware configurations for CXL (including device model, cache-line size, and interconnect) versus RDMA NICs; (2) cache sizes and memory capacities; (3) multi-tenancy parameters; (4) workload details such as context lengths, batch sizes, and sparsity patterns from DeepSeek-V3.2; (5) number of runs and statistical reporting (means with error bars or confidence intervals). We will also release the evaluation harness and configuration files. revision: yes
-
Referee: [§3 (System Design)] §3 (System Design) and §5: The manuscript does not measure or bound CXL coherence traffic, NUMA contention, or protocol overhead when only sparse top-k entries are touched under realistic cache sizes or concurrent tenants. Without such data, it is unclear whether the fine-grained access advantage survives at scale, which directly affects the comparison to bulk RDMA.
Authors: We acknowledge that direct measurements of CXL coherence traffic, NUMA contention, and protocol overhead under multi-tenant sparse access would provide stronger evidence that the fine-grained advantage persists at scale. Our current evaluation reports only end-to-end metrics. In revision we will add a new analysis subsection (either in §3 or §5) that (a) uses hardware performance counters to bound coherence traffic for the observed top-k access patterns and (b) discusses expected NUMA and protocol overheads based on CXL specification and prior micro-benchmark literature. If additional controlled experiments are required, we will perform and report them. revision: partial
Circularity Check
No circularity: empirical system evaluation with no derived quantities or self-referential fits
full rationale
The paper describes a disaggregated KV cache system (SAC) and reports measured performance gains (2.1x throughput, 9.7x lower TTFT, 1.8x lower TBT) from running DeepSeek-V3.2 under SGLang against RDMA baselines. No equations, parameters fitted to subsets of data, predictions, or uniqueness theorems appear in the provided text. The central claims rest on direct experimental comparison rather than any derivation that reduces to its own inputs by construction. Self-citations, if present in the full manuscript, are not load-bearing for any mathematical result. This is a standard empirical systems paper whose results are externally falsifiable via replication on the stated hardware and workloads.
Axiom & Free-Parameter Ledger
invented entities (1)
-
SAC disaggregated KV cache system
no independent evidence
Reference graph
Works this paper leans on
-
[1]
A Survey on Efficient Inference for Large Language Models
Zixuan Zhou, Xuefei Ning, Ke Hong, Tianyu Fu, Jiaming Xu, Shiyao Li, Yuming Lou, Luning Wang, Zhihang Yuan, Xiuhong Li, et al. A survey on efficient inference for large language models.arXiv preprint arXiv:2404.14294, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Mooncake: Trading more storage for less computation a KVCache-centric architecture for serving LLM chatbot
Ruoyu Qin, Zheming Li, Weiran He, Jialei Cui, Feng Ren, Mingxing Zhang, Yongwei Wu, Weimin Zheng, and Xinran Xu. Mooncake: Trading more storage for less computation a KVCache-centric architecture for serving LLM chatbot. In23rd USENIX Conference on File and Storage Technologies (F AST 25), pages 155–170, 2025
2025
-
[3]
CacheGen: KV cache compression and streaming for fast large language model serving
Yuhan Liu, Hanchen Li, Yihua Cheng, Siddhant Ray, Yuyang Huang, Qizheng Zhang, Kuntai Du, Jiayi Yao, Shan Lu, Ganesh Ananthanarayanan, et al. CacheGen: KV cache compression and streaming for fast large language model serving. InProceedings of the ACM SIGCOMM 2024 Conference, pages 38–56, 2024
2024
-
[4]
NVIDIA Dynamo Open-Source Library Accelerates and Scales AI Reasoning Models
NVIDIA Corporation. NVIDIA Dynamo Open-Source Library Accelerates and Scales AI Reasoning Models. https://nvidianews.nvidia.com/news/ nvidia-dynamoopen-source-library-accelerates-and-scales-ai-reasoningmodels , 2025
2025
-
[5]
DeepSeek-V3.2: Pushing the Frontier of Open Large Language Models
Aixin Liu, Aoxue Mei, Bangcai Lin, Bing Xue, Bingxuan Wang, Bingzheng Xu, Bochao Wu, Bowei Zhang, Chaofan Lin, Chen Dong, et al. Deepseek-v3. 2: Pushing the frontier of open large language models.arXiv preprint arXiv:2512.02556, 2025
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[6]
Glm-5.1.https://huggingface.co/zai-org/GLM-5.1, 2026
Zhipu AI. Glm-5.1.https://huggingface.co/zai-org/GLM-5.1, 2026
2026
-
[7]
Deepseek-v4-pro
DeepSeek-AI. Deepseek-v4-pro. https://huggingface.co/deepseek-ai/ DeepSeek-V4-Pro, 2026. Accessed: 2026-05-02
2026
-
[8]
Hisparse: High-efficiency sparse attention inference in sglang
Tingwei Huang Zhiqiang Xie, Zhangheng Huang. Hisparse: High-efficiency sparse attention inference in sglang. https://www.lmsys.org/blog/2026-04-10-sglang-hisparse/ , April 2026. LMSYS Blog
2026
-
[9]
High-throughput generative inference of large language models with a single gpu
Ying Sheng, Lianmin Zheng, Binhang Yuan, Zhuohan Li, Max Maxane, Beidi Chen, Ce Fu, Zhiqiang Xie, Beidi Chen, Jiaao Chen, et al. High-throughput generative inference of large language models with a single gpu. InInternational Conference on Machine Learning (ICML), 2023
2023
-
[10]
NanoFlow: Towards Optimal Large Language Model Serving Throughput
Kan Zhu, Wenyi Zhao, et al. Nanoflow: Towards optimal capacity and efficiency in throughput- oriented LLM serving. InarXiv preprint arXiv:2408.12757, 2024
-
[11]
Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving
Yinmin Zhong, Shengyu Liu, Junda Chen, Jian Huang, et al. Distserve: Disaggregating prefill and decoding for goodput-optimized large language model serving. InProceedings of the 17th USENIX Symposium on Operating Systems Design and Implementation (OSDI), 2024
2024
-
[12]
An introduction to the compute express link (CXL) interconnect.ACM Computing Surveys, 56(11):1–37, 2024
Debendra Das Sharma, Robert Blankenship, and Daniel Berger. An introduction to the compute express link (CXL) interconnect.ACM Computing Surveys, 56(11):1–37, 2024
2024
-
[13]
Quest: query-aware sparsity for efficient long-context LLM inference
Jiaming Tang, Yilong Zhao, Kan Zhu, Guangxuan Xiao, Baris Kasikci, and Song Han. Quest: query-aware sparsity for efficient long-context LLM inference. InProceedings of the 41st International Conference on Machine Learning, pages 47901–47911, 2024
2024
-
[14]
H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
Zhenyu Zhang, Ying Sheng, Tianyi Zhou, Tianlong Chen, Lianmin Zheng, Ruisi Cai, Zhao Song, Yuandong Tian, Christopher Ré, Clark Barrett, et al. H2o: Heavy-hitter oracle for efficient generative inference of large language models.Advances in Neural Information Processing Systems, 36:34661–34710, 2023
2023
-
[15]
Junqi Zhao, Zhijin Fang, Shu Li, Shaohui Yang, and Shichao He. Buzz: Beehive-structured sparse kv cache with segmented heavy hitters for efficient LLM inference.arXiv preprint arXiv:2410.23079, 2024. 10
-
[16]
SnapKV: LLM knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
Yuhong Li, Yingbing Huang, Bowen Yang, Bharat Venkitesh, Acyr Locatelli, Hanchen Ye, Tianle Cai, Patrick Lewis, and Deming Chen. SnapKV: LLM knows what you are looking for before generation.Advances in Neural Information Processing Systems, 37:22947–22970, 2024
2024
-
[17]
Efficient Streaming Language Models with Attention Sinks
Guangxuan Xiao, Yuandong Tian, Beidi Chen, Song Han, and Mike Lewis. Efficient streaming language models with attention sinks.arXiv preprint arXiv:2309.17453, 2023
work page internal anchor Pith review Pith/arXiv arXiv 2023
-
[18]
arXiv preprint arXiv:2412.03213 , year=
Guangda Liu, Chengwei Li, Jieru Zhao, Chenqi Zhang, and Minyi Guo. Clusterkv: Manipulating LLM KV cache in semantic space for recallable compression.arXiv preprint arXiv:2412.03213, 2024
-
[19]
KVDirect: Distributed disaggregated LLM inference.arXiv preprint arXiv:2501.14743, 2024
Shiyang Chen, Rain Jiang, Dezhi Yu, Jinlai Xu, Mengyuan Chao, Fanlong Meng, Chenyu Jiang, Wei Xu, and Hang Liu. KVDirect: Distributed disaggregated LLM inference.arXiv preprint arXiv:2501.14743, 2024
-
[20]
Datacenter {RPCs} can be general and fast
Anuj Kalia, Michael Kaminsky, and David Andersen. Datacenter {RPCs} can be general and fast. In16th USENIX Symposium on Networked Systems Design and Implementation (NSDI 19), pages 1–16, 2019
2019
-
[21]
Beluga: A cxl-based memory architecture for scalable and efficient LLM kvcache management.Proceedings of the ACM on Management of Data, 4(1 (SIGMOD):1–29, 2026
Xinjun Yang, Qingda Hu, Junru Li, Feifei Li, Yicong Zhu, Yuqi Zhou, Qiuru Lin, Jian Dai, Yang Kong, Jiayu Zhang, et al. Beluga: A cxl-based memory architecture for scalable and efficient LLM kvcache management.Proceedings of the ACM on Management of Data, 4(1 (SIGMOD):1–29, 2026
2026
-
[22]
XC50256: World’s first hybrid CXL 2.0 and PCIe Gen5 switch IC
XConn Technologies. XC50256: World’s first hybrid CXL 2.0 and PCIe Gen5 switch IC. https://www.xconn-tech.com/product, 2023
2023
-
[23]
Unlocking the potential of CXL for disaggregated memory in cloud-native databases
Xinjun Yang, Yingqiang Zhang, Hao Chen, Feifei Li, Gerry Fan, Yang Kong, Bo Wang, Jing Fang, Yuhui Wang, Tao Huang, et al. Unlocking the potential of CXL for disaggregated memory in cloud-native databases. InCompanion of the 2025 International Conference on Management of Data, pages 689–702, 2025
2025
-
[24]
Tigon: A distributed database for a CXL pod
Yibo Huang, Haowei Chen, Newton Ni, Yan Sun, Vijay Chidambaram, Dixin Tang, and Emmett Witchel. Tigon: A distributed database for a CXL pod. In19th USENIX Symposium on Operating Systems Design and Implementation (OSDI 25), pages 109–128, 2025
2025
-
[25]
Rcmp: Reconstructing RDMA-based memory disaggregation via CXL.ACM Transactions on Architecture and Code Optimization, 21(1):1–26, 2024
Zhonghua Wang, Yixing Guo, Kai Lu, Jiguang Wan, Daohui Wang, Ting Yao, and Huatao Wu. Rcmp: Reconstructing RDMA-based memory disaggregation via CXL.ACM Transactions on Architecture and Code Optimization, 21(1):1–26, 2024
2024
-
[26]
Managing memory tiers with CXL in virtualized environments
Yuhong Zhong, Daniel S Berger, Carl Waldspurger, Ryan Wee, Ishwar Agarwal, Rajat Agarwal, Frank Hady, Karthik Kumar, Mark D Hill, Mosharaf Chowdhury, et al. Managing memory tiers with CXL in virtualized environments. In18th USENIX Symposium on Operating Systems Design and Implementation (OSDI 24), pages 37–56, 2024
2024
-
[27]
Memtunnel: A CXL-based rack-scale host memory pooling architecture for cloud service.IEEE Transactions on Parallel and Distributed Systems, 2025
Tianchan Guan, Yijin Guan, Zhaoyang Du, Jiacheng Ma, Boyu Tian, Zhao Wang, Teng Ma, Zheng Liu, Yang Kong, Yuan Xie, et al. Memtunnel: A CXL-based rack-scale host memory pooling architecture for cloud service.IEEE Transactions on Parallel and Distributed Systems, 2025
2025
-
[28]
Pond: CXL-based memory pooling systems for cloud platforms
Huaicheng Li, Daniel S Berger, Lisa Hsu, Daniel Ernst, Pantea Zardoshti, Stanko Novakovic, Monish Shah, Samir Rajadnya, Scott Lee, Ishwar Agarwal, et al. Pond: CXL-based memory pooling systems for cloud platforms. InProceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, V olume 2, pag...
2023
-
[29]
Dongha Yoon, Younghoon Min, Hoshik Kim, Sam H Noh, and Jongryool Kim. TraCT: Disaggregated LLM serving with CXL shared memory KV cache at rack-scale.arXiv preprint arXiv:2512.18194, 2025. 11
-
[30]
Gonzalez, Ion Stoica, and Haier Duan
Wei-Lin Chiang, Zhuohan Li, Zi Lin, Ying Sheng, Zhanghao Wu, Hao Zhang, Lianmin Zheng, Siyuan Zhuang, Yonghao Zhuang, Joseph E. Gonzalez, Ion Stoica, and Haier Duan. Vicuna: An open-source chatbot impressing gpt-4 with 90%* chatgpt quality, March 2023. URL https://lmsys.org/blog/2023-03-30-vicuna/
2023
-
[31]
Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
Lianmin Zheng, Liangsheng Yin, Zhiqiang Xie, Chuyue Sun, Jeff Huang, Cody H Yu, Shiyi Cao, Christos Kozyrakis, Ion Stoica, Joseph E Gonzalez, et al. Sglang: Efficient execution of structured language model programs.Advances in neural information processing systems, 37: 62557–62583, 2024
2024
-
[32]
Ub-mesh: a hierarchically localized nd-fullmesh datacenter network architecture.IEEE Micro, 2025
Heng Liao, Bingyang Liu, Xianping Chen, Zhigang Guo, Chuanning Cheng, Jianbing Wang, Xiangyu Chen, Peng Dong, Rui Meng, Wenjie Liu, et al. Ub-mesh: a hierarchically localized nd-fullmesh datacenter network architecture.IEEE Micro, 2025
2025
-
[33]
Ultra ethernet and ualink: Next-generation interconnects for ai infrastructure
Rajesh Arsid. Ultra ethernet and ualink: Next-generation interconnects for ai infrastructure. IJSAT-International Journal on Science and Technology, 16(2), 2025
2025
-
[34]
Cxl-dl: A cxl-based shared memory architecture for deep learning
Minwoo An, Jinho Kim, Juhyun Oh, Myung-Jae Lee, and Myoungsoo Jung. Cxl-dl: A cxl-based shared memory architecture for deep learning. InProceedings of the 30th IEEE International Symposium on High-Performance Computer Architecture (HPCA), pages 1–14, 2024
2024
-
[35]
Cxl-pnm: A cxl-based processing-near-memory accelerator for large-scale nlp models
Keunsoo Kim, Sang-Won Lee, Jin-Hee Han, Gi-Moon Park, Young-Cheon Kim, and Jung-Hwan Choi. Cxl-pnm: A cxl-based processing-near-memory accelerator for large-scale nlp models. IEEE Computer Architecture Letters, 22(2):157–160, 2023. 12 A Experimental Setup This section provides the detailed hardware and software configuration used in our experiments. To en...
2023
-
[36]
indirect host-staged data path
As standard HiSparse currently does not support Radix Cache, we implemented a custom Radix Cache integration within HiSparse. In this configuration, the KV cache is entirely offloaded to the designated memory backend (CXL or RDMA). 13 A.4 Third-Party Assets and Licenses Table 2 summarizes software, models, and data used in evaluation (see also Section 5)....
-
[37]
This addresses the Transmission Bottleneck (P1) that remains even in fast bulk-transfer systems
From Transfer to On-Demand Fetching: Whereas TraCT and Beluga focus on moving KV blocks, SAC utilizes CXL’s near-DRAM latency to fetch only thetop-k KV entriesin real-time during the attention calculation. This addresses the Transmission Bottleneck (P1) that remains even in fast bulk-transfer systems
-
[38]
full prefetching
Mandatory vs. Optional Substrate: In dense models, CXL is a performance optimizer; for Sparse Attention, SAC demonstrates that CXL is a necessity. By residing the full KV cache in the CXL pool and fetching only active entries, SAC resolves the Local Memory Wasting (P2) inherent in the “full prefetching” strategy used by RDMA-based systems
-
[39]
Fine-Grained Integration: Unlike the block-level management in TraCT, SAC integrates directly with the SGLang runtime to handle the dynamic, runtime-determined indices of sparse attention models, utilizing CXL’s zero-protocol overhead for discrete, cache-line granularity loads. In essence, while prior work focuses on CXL as afaster storage tier, SAC treat...
2019
-
[40]
and TraCT [ 29] primarily focus on prefix KV cache management for dense models, other works explore broader architectural optimizations. For instance, CXL-DL [ 34] investigates using CXL-attached memory to expand capacity for massive embedding tables in recommendation systems, which share the characteristic of sparse memory access with certain LLM configu...
-
[41]
Miss Identification: It identifies which of the dynamically determined Top-k KV entries are missing from the local device buffer
-
[42]
LRU Eviction: It selects eviction candidates from the hot device buffer using a Least Recently Used (LRU) policy to make space for incoming data
-
[43]
long-input, short-output
Page Table Update and Fetch: It updates the internal page table mapping and triggers the fetch of the required KV entries from the remote pool to the local HBM. 17 Figure 16: HiSparse workflow [8]. C.3 SAC Implementation on HiSparse SAC orchestrates a hardware-software co-design by coupling the HiSparse framework with a CXL- centric memory hierarchy. This...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.