SIGMA: Skill-Incidence Graphs for Compositional Multi-Agent Design
Pith reviewed 2026-06-26 15:26 UTC · model grok-4.3
The pith
SIGMA constructs multi-agent systems by bundling reusable skills into agents via incidence matrices rather than using fixed agent nodes.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
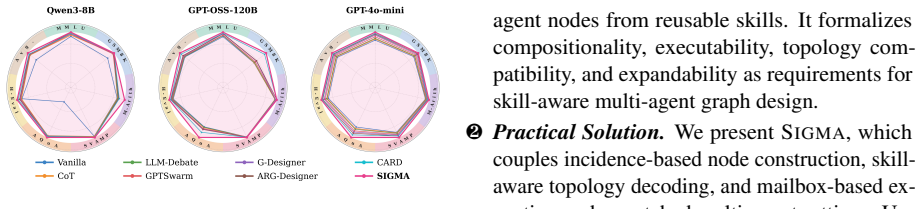
Given a task and skill library, SIGMA predicts a skill-agent incidence matrix, composes agent node embeddings from the selected skills, decodes a communication topology over the constructed agents, and makes the incidence structure operational through skill-specific mailboxes that route messages to the relevant capabilities during execution. On six reasoning and coding benchmarks with three base LLMs, this yields the best average performance and improves over the strongest non-compositional baseline by 2.06, 2.36, and 1.75 points respectively, while dropping only 0.96 points on average under unseen skill libraries.
What carries the argument
The skill-agent incidence matrix that selects and bundles skills into agents and enables direct operational routing via skill-specific mailboxes.
If this is right
- Multi-agent designs can handle tasks whose required capability mixes were absent from training data.
- The incidence structure integrates directly into execution without separate post-processing steps.
- Compositional node construction and topology optimization can be pursued as complementary rather than competing directions.
- Robustness to changes in the underlying skill library increases because new agents are assembled on the fly.
Where Pith is reading between the lines
- The same incidence-matrix idea could be tested in domains where capabilities are already decomposed, such as tool-use agents or modular robotics controllers.
- If skill libraries grow large, the prediction step for the incidence matrix may become a new bottleneck worth optimizing separately.
- The framework implicitly assumes that message routing by skill mailbox remains efficient even as the number of skills per agent increases.
Load-bearing premise
Skills from the library are modular and reusable enough that incidence-matrix combinations produce effective agent capabilities even for tasks needing previously unseen mixes.
What would settle it
A controlled test in which tasks require novel skill combinations and performance with the predicted incidence matrix is no higher than with a fixed-agent baseline that cannot recombine skills.
Figures














read the original abstract
Existing graph-based multi-agent system (MAS) designers mainly improve collaboration by optimizing communication topologies over predefined agents, roles, or groups. However, because each node remains a closed-set entity, these methods struggle to generalize to tasks that require unseen combinations of capabilities. We propose SIGMA, a skill-incidence graph framework that constructs agents as task-conditioned bundles of reusable skills. Given a task and a skill library, SIGMA predicts a skill-agent incidence matrix, composes agent node embeddings from selected skills, and decodes a communication topology over the constructed agents. During execution, skill-specific mailboxes route messages to the relevant assigned capabilities, making the incidence structure directly operational. Across six reasoning and coding benchmarks with three base LLMs, SIGMA achieves the best average performance and improves over CARD, the strongest non-compositional topology-based baseline, by 2.06, 2.36, and 1.75 points, respectively. It also shows stronger robustness to unseen skill libraries, with an average performance drop of only 0.96 points. These results suggest that compositional node construction is a complementary and important axis for multi-agent design beyond communication topology optimization. Code is available at https://anonymous.4open.science/r/SIGMA-2338/.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes SIGMA, a skill-incidence graph framework for multi-agent system design. Instead of optimizing communication topologies over fixed agent nodes, SIGMA predicts a task-conditioned skill-agent incidence matrix from a skill library, composes node embeddings from the selected reusable skills, decodes a topology over the resulting agents, and uses skill-specific mailboxes at runtime. Experiments across six reasoning and coding benchmarks with three base LLMs report that SIGMA outperforms the non-compositional CARD baseline by 2.06, 2.36, and 1.75 points on average and exhibits greater robustness (0.96-point average drop) when skill libraries are replaced with unseen ones. The central claim is that compositional node construction constitutes an important complementary axis to topology optimization.
Significance. If the attribution of gains to incidence-based composition is substantiated, the work would usefully expand the design space for graph-based MAS beyond topology search. The public code release is a clear strength that enables direct verification and extension. The empirical framing (benchmark deltas rather than parameter-free derivations) means significance hinges on the quality of the experimental isolation of the compositional mechanism.
major comments (2)
- [Abstract] Abstract: The reported 2.06–2.36 point gains over CARD are presented as end-to-end results without any ablation that disables incidence-matrix prediction and skill-composition while retaining skill-specific mailboxes and the topology decoder. This omission leaves open whether the observed improvements are driven by the claimed compositional node construction or by auxiliary pipeline components.
- [Abstract] Abstract (and experimental section): The robustness claim (0.96-point average drop under unseen skill libraries) is stated without describing how the replacement libraries are sampled or whether the incidence predictor is retrained or zero-shot on the new libraries. Without these controls, it is unclear whether the smaller drop truly demonstrates superior generalization of the compositional representation.
minor comments (1)
- [Abstract] The abstract states numeric improvements but supplies no statistical significance tests, variance across runs, or number of seeds; adding these details would strengthen the empirical claims.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on experimental isolation and controls. We address each major comment below.
read point-by-point responses
-
Referee: [Abstract] Abstract: The reported 2.06–2.36 point gains over CARD are presented as end-to-end results without any ablation that disables incidence-matrix prediction and skill-composition while retaining skill-specific mailboxes and the topology decoder. This omission leaves open whether the observed improvements are driven by the claimed compositional node construction or by auxiliary pipeline components.
Authors: We agree that an explicit ablation disabling incidence-matrix prediction and skill composition (while retaining mailboxes and the topology decoder) would more cleanly isolate the contribution of compositional node construction. The existing CARD comparison controls for topology but does not hold the auxiliary components fixed in this way. In the revised manuscript we will add this ablation. revision: yes
-
Referee: [Abstract] Abstract (and experimental section): The robustness claim (0.96-point average drop under unseen skill libraries) is stated without describing how the replacement libraries are sampled or whether the incidence predictor is retrained or zero-shot on the new libraries. Without these controls, it is unclear whether the smaller drop truly demonstrates superior generalization of the compositional representation.
Authors: We will expand the experimental section to specify the sampling procedure used to construct the replacement (unseen) skill libraries and to state explicitly that the incidence predictor is evaluated zero-shot without retraining. These details will be added to support the generalization claim. revision: yes
Circularity Check
No circularity; empirical benchmark results only
full rationale
The paper introduces the SIGMA framework for constructing agents via skill-incidence matrices and evaluates it through end-to-end experiments on six benchmarks against the CARD baseline, reporting average performance improvements of 2.06–2.36 points. No derivation chain, first-principles equations, fitted parameters renamed as predictions, or self-citation load-bearing steps appear in the provided text. All reported quantities are direct experimental outcomes on held-out tasks rather than quantities forced by construction from the same data or prior self-referential results, making the work self-contained as an empirical proposal.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Skills from the library are modular and reusable across tasks
Reference graph
Works this paper leans on
-
[1]
Advances in neural information processing systems , volume=
CAMEL: Communicative Agents for ``Mind'' Exploration of Large Language Model Society , author=. Advances in neural information processing systems , volume=
-
[2]
First conference on language modeling , year=
AutoGen: Enabling Next-Gen LLM Applications via Multi-Agent Conversations , author=. First conference on language modeling , year=
-
[3]
International Conference on Learning Representations , year=
MetaGPT: Meta programming for a multi-agent collaborative framework , author=. International Conference on Learning Representations , year=
-
[4]
Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Chatdev: Communicative agents for software development , author=. Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[5]
International Conference on Learning Representations , year=
Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors , author=. International Conference on Learning Representations , year=
-
[6]
First Conference on Language Modeling , year=
A dynamic LLM-powered agent network for task-oriented agent collaboration , author=. First Conference on Language Modeling , year=
-
[7]
Forty-first International Conference on Machine Learning , year=
GPTSwarm: Language Agents as Optimizable Graphs , author=. Forty-first International Conference on Machine Learning , year=
-
[8]
arXiv preprint arXiv:2410.11782 , year=
G-designer: Architecting multi-agent communication topologies via graph neural networks , author=. arXiv preprint arXiv:2410.11782 , year=
-
[9]
International Conference on Learning Representations , year=
Cut the crap: An economical communication pipeline for llm-based multi-agent systems , author=. International Conference on Learning Representations , year=
-
[11]
Advances in neural information processing systems , volume=
Toolformer: Language models can teach themselves to use tools , author=. Advances in neural information processing systems , volume=
-
[12]
arXiv preprint arXiv:2306.05301 , year=
Toolalpaca: Generalized tool learning for language models with 3000 simulated cases , author=. arXiv preprint arXiv:2306.05301 , year=
-
[15]
Advances in Neural Information Processing Systems , volume=
Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face , author=. Advances in Neural Information Processing Systems , volume=
-
[16]
Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
Api-bank: A comprehensive benchmark for tool-augmented llms , author=. Proceedings of the 2023 conference on empirical methods in natural language processing , pages=
2023
-
[18]
International Conference on Learning Representations , year=
Toolllm: Facilitating large language models to master 16000+ real-world apis , author=. International Conference on Learning Representations , year=
-
[20]
International Conference on Learning Representations , year=
Livecodebench: Holistic and contamination free evaluation of large language models for code , author=. International Conference on Learning Representations , year=
-
[24]
Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
Solving general arithmetic word problems , author=. Proceedings of the 2015 conference on empirical methods in natural language processing , pages=
2015
-
[26]
Proceedings of the 55th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
Program induction by rationale generation: Learning to solve and explain algebraic word problems , author=. Proceedings of the 55th annual meeting of the association for computational linguistics (volume 1: Long papers) , pages=
-
[27]
Advances in neural information processing systems , volume=
Chain-of-thought prompting elicits reasoning in large language models , author=. Advances in neural information processing systems , volume=
-
[28]
Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
Agentdropout: Dynamic agent elimination for token-efficient and high-performance llm-based multi-agent collaboration , author=. Proceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers) , pages=
-
[29]
International Conference on Machine Learning , pages=
G-Designer: Architecting Multi-agent Communication Topologies via Graph Neural Networks , author=. International Conference on Machine Learning , pages=. 2025 , organization=
2025
-
[30]
Forty-first international conference on machine learning , year=
Improving factuality and reasoning in language models through multiagent debate , author=. Forty-first international conference on machine learning , year=
-
[31]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Encouraging divergent thinking in large language models through multi-agent debate , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[32]
Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
Generative agents: Interactive simulacra of human behavior , author=. Proceedings of the 36th annual acm symposium on user interface software and technology , pages=
-
[33]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
-
[37]
Sandhini Agarwal, Lama Ahmad, Jason Ai, Sam Altman, Andy Applebaum, Edwin Arbus, Rahul K Arora, Yu Bai, Bowen Baker, Haiming Bao, and 1 others. 2025. gpt-oss-120b & gpt-oss-20b model card. arXiv preprint arXiv:2508.10925
Pith/arXiv arXiv 2025
-
[38]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Ponde De Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, and 1 others. 2021. Evaluating large language models trained on code. arXiv preprint arXiv:2107.03374
Pith/arXiv arXiv 2021
-
[39]
Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chi-Min Chan, Heyang Yu, Yaxi Lu, Yi-Hsin Hung, Chen Qian, and 1 others. 2024. Agentverse: Facilitating multi-agent collaboration and exploring emergent behaviors. In International Conference on Learning Representations
2024
-
[40]
Karl Cobbe, Vineet Kosaraju, Mohammad Bavarian, Mark Chen, Heewoo Jun, Lukasz Kaiser, Matthias Plappert, Jerry Tworek, Jacob Hilton, Reiichiro Nakano, and 1 others. 2021. Training verifiers to solve math word problems. arXiv preprint arXiv:2110.14168
Pith/arXiv arXiv 2021
-
[41]
Yilun Du, Shuang Li, Antonio Torralba, Joshua B Tenenbaum, and Igor Mordatch. 2024. Improving factuality and reasoning in language models through multiagent debate. In Forty-first international conference on machine learning
2024
-
[42]
Dan Hendrycks, Collin Burns, Steven Basart, Andy Zou, Mantas Mazeika, Dawn Song, and Jacob Steinhardt. 2020. Measuring massive multitask language understanding. arXiv preprint arXiv:2009.03300
Pith/arXiv arXiv 2020
-
[43]
Sirui Hong, Mingchen Zhuge, Jonathan Chen, Xiawu Zheng, Yuheng Cheng, Jinlin Wang, Ceyao Zhang, Steven Yau, Zijuan Lin, Liyang Zhou, and 1 others. 2024. Metagpt: Meta programming for a multi-agent collaborative framework. In International Conference on Learning Representations
2024
-
[44]
Aaron Hurst, Adam Lerer, Adam P Goucher, Adam Perelman, Aditya Ramesh, Aidan Clark, AJ Ostrow, Akila Welihinda, Alan Hayes, Alec Radford, and 1 others. 2024. Gpt-4o system card. arXiv preprint arXiv:2410.21276
Pith/arXiv arXiv 2024
-
[45]
Ehud Karpas, Omri Abend, Yonatan Belinkov, Barak Lenz, Opher Lieber, Nir Ratner, Yoav Shoham, Hofit Bata, Yoav Levine, Kevin Leyton-Brown, and 1 others. 2022. Mrkl systems: A modular, neuro-symbolic architecture that combines large language models, external knowledge sources and discrete reasoning. arXiv preprint arXiv:2205.00445
Pith/arXiv arXiv 2022
-
[46]
Guohao Li, Hasan Hammoud, Hani Itani, Dmitrii Khizbullin, and Bernard Ghanem. 2023 a . Camel: Communicative agents for ``mind'' exploration of large language model society. Advances in neural information processing systems, 36:51991--52008
2023
-
[47]
Minghao Li, Yingxiu Zhao, Bowen Yu, Feifan Song, Hangyu Li, Haiyang Yu, Zhoujun Li, Fei Huang, and Yongbin Li. 2023 b . Api-bank: A comprehensive benchmark for tool-augmented llms. In Proceedings of the 2023 conference on empirical methods in natural language processing, pages 3102--3116
2023
-
[48]
Shiyuan Li, Yixin Liu, Qingsong Wen, Chengqi Zhang, and Shirui Pan. 2026. Assemble your crew: Automatic multi-agent communication topology design via autoregressive graph generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 40, pages 23142--23150
2026
-
[49]
Tian Liang, Zhiwei He, Wenxiang Jiao, Xing Wang, Yan Wang, Rui Wang, Yujiu Yang, Shuming Shi, and Zhaopeng Tu. 2024. Encouraging divergent thinking in large language models through multi-agent debate. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 17889--17904
2024
-
[50]
Wang Ling, Dani Yogatama, Chris Dyer, and Phil Blunsom. 2017. Program induction by rationale generation: Learning to solve and explain algebraic word problems. In Proceedings of the 55th annual meeting of the association for computational linguistics (volume 1: Long papers), pages 158--167
2017
-
[51]
Zijun Liu, Yanzhe Zhang, Peng Li, Yang Liu, and Diyi Yang. 2024. A dynamic llm-powered agent network for task-oriented agent collaboration. In First Conference on Language Modeling
2024
-
[52]
Joon Sung Park, Joseph O'Brien, Carrie Jun Cai, Meredith Ringel Morris, Percy Liang, and Michael S Bernstein. 2023. Generative agents: Interactive simulacra of human behavior. In Proceedings of the 36th annual acm symposium on user interface software and technology, pages 1--22
2023
-
[53]
Arkil Patel, Satwik Bhattamishra, and Navin Goyal. 2021. https://doi.org/10.18653/v1/2021.naacl-main.168 Are NLP models really able to solve simple math word problems? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, pages 2080--2094, Online. Association for ...
work page internal anchor Pith review doi:10.18653/v1/2021.naacl-main.168 2021
-
[54]
Shishir G Patil, Tianjun Zhang, Xin Wang, and Joseph E Gonzalez. 2023. Gorilla: Large language model connected with massive apis. arXiv preprint arXiv:2305.15334
Pith/arXiv arXiv 2023
-
[55]
Chen Qian, Wei Liu, Hongzhang Liu, Nuo Chen, Yufan Dang, Jiahao Li, Cheng Yang, Weize Chen, Yusheng Su, Xin Cong, and 1 others. 2024. Chatdev: Communicative agents for software development. In Proceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 15174--15186
2024
-
[56]
Yujia Qin, Shihao Liang, Yining Ye, Kunlun Zhu, Lan Yan, Yaxi Lu, Yankai Lin, Xin Cong, Xiangru Tang, Bill Qian, and 1 others. 2024. Toolllm: Facilitating large language models to master 16000+ real-world apis. In International Conference on Learning Representations
2024
-
[57]
Subhro Roy and Dan Roth. 2015. Solving general arithmetic word problems. In Proceedings of the 2015 conference on empirical methods in natural language processing, pages 1743--1752
2015
-
[58]
Timo Schick, Jane Dwivedi-Yu, Roberto Dess \` , Roberta Raileanu, Maria Lomeli, Eric Hambro, Luke Zettlemoyer, Nicola Cancedda, and Thomas Scialom. 2023. Toolformer: Language models can teach themselves to use tools. Advances in neural information processing systems, 36:68539--68551
2023
-
[59]
Yongliang Shen, Kaitao Song, Xu Tan, Dongsheng Li, Weiming Lu, and Yueting Zhuang. 2023. Hugginggpt: Solving ai tasks with chatgpt and its friends in hugging face. Advances in Neural Information Processing Systems, 36:38154--38180
2023
-
[60]
Guanzhi Wang, Yuqi Xie, Yunfan Jiang, Ajay Mandlekar, Chaowei Xiao, Yuke Zhu, Linxi Fan, and Anima Anandkumar. 2023. Voyager: An open-ended embodied agent with large language models. arXiv preprint arXiv:2305.16291
Pith/arXiv arXiv 2023
-
[61]
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Fei Xia, Ed Chi, Quoc V Le, Denny Zhou, and 1 others. 2022. Chain-of-thought prompting elicits reasoning in large language models. Advances in neural information processing systems, 35:24824--24837
2022
-
[62]
Qingyun Wu, Gagan Bansal, Jieyu Zhang, Yiran Wu, Beibin Li, Erkang Zhu, Li Jiang, Xiaoyun Zhang, Shaokun Zhang, Jiale Liu, and 1 others. 2024. Autogen: Enabling next-gen llm applications via multi-agent conversations. In First conference on language modeling
2024
-
[63]
Tongtong Wu, Yanming Li, Ziye Tang, Chen Jiang, Linhao Luo, Guilin Qi, Shirui Pan, and Gholamreza Haffari. 2026. Card: Towards conditional design of multi-agent topological structures. arXiv preprint arXiv:2603.01089
arXiv 2026
-
[64]
An Yang, Anfeng Li, Baosong Yang, Beichen Zhang, Binyuan Hui, Bo Zheng, Bowen Yu, Chang Gao, Chengen Huang, Chenxu Lv, and 1 others. 2025. Qwen3 technical report. arXiv preprint arXiv:2505.09388
Pith/arXiv arXiv 2025
-
[65]
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. 2022. React: Synergizing reasoning and acting in language models. arXiv preprint arXiv:2210.03629
Pith/arXiv arXiv 2022
-
[66]
Guibin Zhang, Yanwei Yue, Zhixun Li, Sukwon Yun, Guancheng Wan, Kun Wang, Dawei Cheng, Jeffrey Yu, and Tianlong Chen. 2025 a . Cut the crap: An economical communication pipeline for llm-based multi-agent systems. In International Conference on Learning Representations
2025
-
[67]
Guibin Zhang, Yanwei Yue, Xiangguo Sun, Guancheng Wan, Miao Yu, Junfeng Fang, Kun Wang, Tianlong Chen, and Dawei Cheng. 2025 b . G-designer: Architecting multi-agent communication topologies via graph neural networks. In International Conference on Machine Learning, pages 76678--76692. PMLR
2025
-
[68]
Mingchen Zhuge, Wenyi Wang, Louis Kirsch, Francesco Faccio, Dmitrii Khizbullin, and J \"u rgen Schmidhuber. 2024. Gptswarm: Language agents as optimizable graphs. In Forty-first International Conference on Machine Learning
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.