EquiVLA: A General Framework for Rotationally Equivariant Vision-Language-Action Models
Pith reviewed 2026-06-26 17:27 UTC · model grok-4.3
The pith
EquiVLA adds an end-to-end SO(2) equivariance chain to vision-language-action models and lifts success rates on manipulation benchmarks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
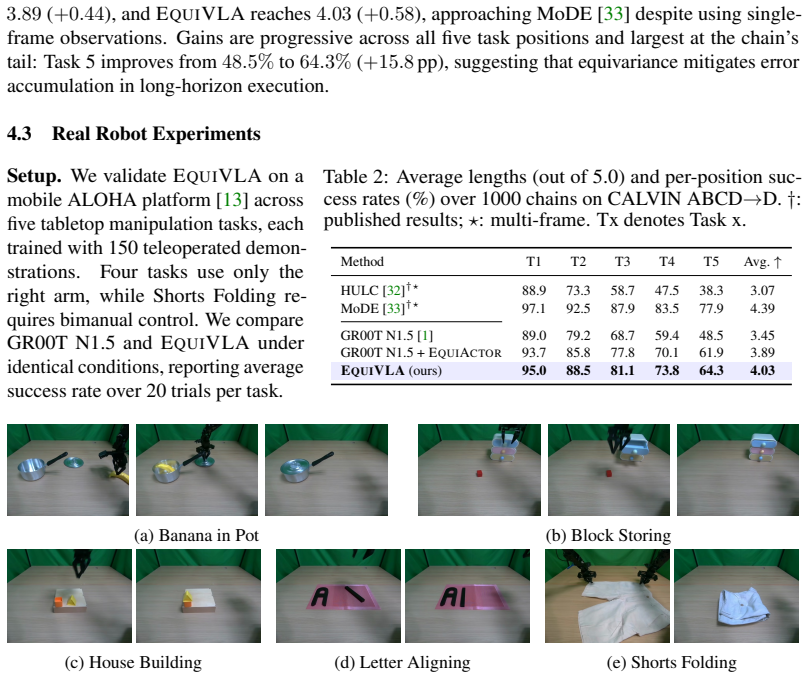
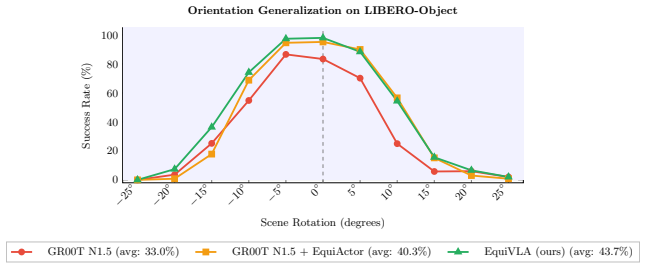
EquiVLA is the first general framework for end-to-end SO(2)-equivariant VLA models. It introduces EquiPerceptor, which produces approximately SO(2)-equivariant visual representations from frozen ViT features, and EquiActor, an exactly SO(2)-equivariant flow-matching Diffusion Transformer action head. Together they establish an approximate SO(2) equivariance chain from camera observations to predicted action sequences, delivering 92.6 percent average success on LIBERO, an average sequence length of 4.03 on CALVIN, and 72 percent real-robot success.
What carries the argument
The EquiPerceptor plus EquiActor pair that converts frozen ViT features into an approximate-to-exact SO(2) equivariance chain for action prediction.
If this is right
- The framework applies to any VLA architecture that freezes a vision-language backbone and uses a flow-matching Diffusion Transformer action head.
- Policies generalize across rotational configurations with less additional data.
- The equivariance holds from raw camera observations through to full action sequences.
- Reported gains reach 92.6 percent average success on LIBERO, 4.03 average sequence length on CALVIN, and 72 percent success on real-robot tasks.
Where Pith is reading between the lines
- The same modular split could be tested with other group symmetries such as translations or discrete rotations if analogous equivariant layers are substituted.
- If the symmetry benefit holds, data collection for new robot setups could focus on fewer orientations and still cover the full rotation group.
- The framework may interact with existing data-augmentation strategies, so measuring the combined effect on sample efficiency would be a direct next measurement.
- Extending the chain to handle partial occlusions or changing camera intrinsics would test whether the equivariance remains useful under realistic visual variation.
Load-bearing premise
The performance gains result from the imposed rotational symmetry rather than from differences in model capacity or training details that were not fully ablated.
What would settle it
An experiment that keeps parameter count and training schedule identical but removes the equivariance operations from both EquiPerceptor and EquiActor, then checks whether success rates fall back to the non-equivariant baseline levels.
Figures




read the original abstract
Vision-Language-Action (VLA) models have emerged as a powerful paradigm for generalist robot manipulation, yet they lack geometric inductive biases: policies trained at specific orientations require substantially more data to generalize across rotational configurations. We present \textsc{EquiVLA}, the first general framework for end-to-end $\mathrm{SO}(2)$-equivariant VLA models, applicable to any architecture coupling a frozen vision-language backbone with a flow-matching Diffusion Transformer action head. \textsc{EquiVLA} introduces \textsc{EquiPerceptor}, which produces approximately $\mathrm{SO}(2)$-equivariant visual representations from frozen ViT features; and \textsc{EquiActor}, an exactly $\mathrm{SO}(2)$-equivariant flow-matching Diffusion Transformer action head. Together, they establish an approximate $\mathrm{SO}(2)$ equivariance chain from camera observations to predicted action sequences. Instantiated on GR00T~N1.5 and evaluated across four LIBERO suites, CALVIN ABCD$\to$D, and five real-robot tasks on Mobile ALOHA, \textsc{EquiVLA} achieves $92.6\%$ average success on LIBERO (vs. $78.1\%$ baseline), an average sequence length of $4.03$ on CALVIN (vs. $3.45$), and improves real-robot success from $54\%$ to $72\%$.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents EquiVLA as the first general framework for end-to-end SO(2)-equivariant Vision-Language-Action models. It introduces EquiPerceptor to generate approximately SO(2)-equivariant visual representations from frozen ViT features of a vision-language backbone, and EquiActor as an exactly SO(2)-equivariant flow-matching Diffusion Transformer for the action head. The framework is instantiated on GR00T N1.5 and evaluated on LIBERO, CALVIN, and real-robot tasks on Mobile ALOHA, reporting average success rates of 92.6% on LIBERO (vs. 78.1% baseline), 4.03 sequence length on CALVIN (vs. 3.45), and 72% real-robot success (vs. 54%).
Significance. If the gains are attributable to the approximate-to-exact SO(2) equivariance chain, the work would meaningfully advance VLA models by adding geometric inductive biases that improve rotational generalization. The multi-benchmark evaluation spanning simulation suites and real-robot tasks on Mobile ALOHA is a positive aspect of the empirical contribution.
major comments (2)
- [§3.2] §3.2 (EquiPerceptor construction): The method produces approximately SO(2)-equivariant features from a frozen non-equivariant ViT backbone, but provides no quantitative verification (e.g., feature transformation tests under explicit SO(2) rotations of input images) that the output representations transform as required; this verification is load-bearing for the end-to-end equivariance chain asserted in the abstract and for attributing gains to symmetry.
- [§5] §5 (Experiments, LIBERO and CALVIN results): The reported deltas (92.6% vs 78.1% on LIBERO; 4.03 vs 3.45 on CALVIN) compare against baselines without ablations that exactly match parameter count, training schedule, and optimizer while disabling the group-equivariant layers in both EquiPerceptor and EquiActor; without these controls the performance improvements cannot be attributed to the equivariance mechanism rather than capacity or training differences.
minor comments (1)
- [Abstract, §1] The abstract and §1 would benefit from an explicit statement of the precise group representation used for the SO(2) action on image features and actions.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive comments. We address each major point below and indicate where revisions will be made to strengthen the manuscript.
read point-by-point responses
-
Referee: [§3.2] §3.2 (EquiPerceptor construction): The method produces approximately SO(2)-equivariant features from a frozen non-equivariant ViT backbone, but provides no quantitative verification (e.g., feature transformation tests under explicit SO(2) rotations of input images) that the output representations transform as required; this verification is load-bearing for the end-to-end equivariance chain asserted in the abstract and for attributing gains to symmetry.
Authors: We agree that quantitative verification of the approximate SO(2) equivariance in EquiPerceptor is important for supporting the claimed chain and for attributing performance gains. In the revised manuscript we will add explicit feature transformation tests: we will rotate input images by multiples of 90 degrees, extract EquiPerceptor features, apply the corresponding group action to the features, and report the L2 discrepancy between the transformed and directly computed features, averaged over the evaluation sets. revision: yes
-
Referee: [§5] §5 (Experiments, LIBERO and CALVIN results): The reported deltas (92.6% vs 78.1% on LIBERO; 4.03 vs 3.45 on CALVIN) compare against baselines without ablations that exactly match parameter count, training schedule, and optimizer while disabling the group-equivariant layers in both EquiPerceptor and EquiActor; without these controls the performance improvements cannot be attributed to the equivariance mechanism rather than capacity or training differences.
Authors: We acknowledge that the current baselines do not include parameter-matched ablations that isolate the effect of the group-equivariant layers. In the revision we will add controlled ablations on both LIBERO and CALVIN: we will replace the SO(2)-equivariant layers in EquiPerceptor and EquiActor with standard (non-equivariant) counterparts while preserving identical parameter counts, training schedules, optimizers, and data, and report the resulting performance to better attribute gains to the symmetry mechanism. revision: yes
Circularity Check
No circularity in derivation chain
full rationale
The paper presents EquiVLA as an empirical framework that combines an approximate-equivariant EquiPerceptor module on frozen ViT features with an exactly equivariant EquiActor Diffusion Transformer head, then reports benchmark improvements on LIBERO, CALVIN, and real-robot tasks. No equations, first-principles derivations, fitted parameters renamed as predictions, or self-citation chains appear in the provided text that would reduce any claimed result to its own inputs by construction. The performance numbers are presented as direct empirical comparisons, not as outputs of a closed mathematical loop.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Frozen ViT features can be transformed into approximately SO(2)-equivariant representations via EquiPerceptor without retraining the backbone.
invented entities (2)
-
EquiPerceptor
no independent evidence
-
EquiActor
no independent evidence
Reference graph
Works this paper leans on
-
[1]
J. Bjorck, F. Casta˜neda, N. Cherniadev, X. Da, R. Ding, L. Fan, Y . Fang, D. Fox, F. Hu, S. Huang, et al. Gr00t n1: An open foundation model for generalist humanoid robots.arXiv preprint arXiv:2503.14734, 2025
Pith/arXiv arXiv 2025
-
[2]
K. Black, N. Brown, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, L. Groom, K. Hausman, B. Ichter, et al. π0: A vision-language-action flow model for general robot control.arXiv preprint arXiv:2410.24164, 2024
Pith/arXiv arXiv 2024
-
[3]
M. J. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, et al. Openvla: An open-source vision-language-action model.arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[4]
D. Wang, B. Hu, S. Song, R. Walters, and R. Platt. A practical guide for incorporating symmetry in diffusion policy.arXiv preprint arXiv:2505.13431, 2025
arXiv 2025
-
[5]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt. Equivariant diffusion policy.arXiv preprint arXiv:2407.01812, 2024
arXiv 2024
-
[6]
J. Yang, Z.-a. Cao, C. Deng, R. Antonova, S. Song, and J. Bohg. Equibot: Sim (3)-equivariant diffusion policy for generalizable and data efficient learning.arXiv preprint arXiv:2407.01479, 2024
arXiv 2024
-
[7]
D. Wang, R. Walters, and R. Platt. SO(2)-equivariant reinforcement learning.arXiv preprint arXiv:2203.04439, 2022
arXiv 2022
-
[8]
C. Tie, Y . Chen, R. Wu, B. Dong, Z. Li, C. Gao, and H. Dong. ET-SEED: Efficient trajectory- level SE(3) equivariant diffusion policy. InInternational Conference on Learning Representa- tions, 2025
2025
-
[9]
X. Zhu, Y . Qi, Y . Zhu, R. Walters, and R. Platt. Equact: An se (3)-equivariant multi-task transformer for open-loop robotic manipulation.arXiv preprint arXiv:2505.21351, 2025
arXiv 2025
-
[10]
J. Deng, Y . Wang, Y . Zhu, T. Feng, T. Wo, and Z. Shao. Eq.Bot: Enhance robotic manipulation learning via group equivariant canonicalization.arXiv preprint arXiv:2511.15194, 2025
arXiv 2025
-
[11]
B. Liu, Y . Zhu, C. Gao, Y . Feng, Q. Liu, Y . Zhu, and P. Stone. Libero: Benchmarking knowledge transfer for lifelong robot learning.Advances in Neural Information Processing Systems, 36: 44776–44791, 2023
2023
-
[12]
O. Mees, L. Hermann, E. Rosete-Beas, and W. Burgard. Calvin: A benchmark for language- conditioned policy learning for long-horizon robot manipulation tasks.IEEE Robotics and Automation Letters, 7(3):7327–7334, 2022
2022
-
[13]
Z. Fu, T. Z. Zhao, and C. Finn. Mobile aloha: Learning bimanual mobile manipulation with low-cost whole-body teleoperation.arXiv preprint arXiv:2401.02117, 2024
Pith/arXiv arXiv 2024
-
[14]
O. Puny, M. Atzmon, H. Ben-Hamu, I. Misra, A. Grover, E. J. Smith, and Y . Lipman. Frame averaging for invariant and equivariant network design.arXiv preprint arXiv:2110.03336, 2021
arXiv 2021
-
[15]
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Haus- man, A. Herzog, J. Hsu, et al. Rt-1: Robotics transformer for real-world control at scale.arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[16]
Zitkovich, T
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahid, et al. Rt-2: Vision-language-action models transfer web knowledge to robotic control. InConference on Robot Learning, pages 2165–2183. PMLR, 2023. 9
2023
-
[17]
O. M. Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, T. Kreiman, C. Xu, et al. Octo: An open-source generalist robot policy.arXiv preprint arXiv:2405.12213, 2024
Pith/arXiv arXiv 2024
-
[18]
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusai, et al. π0.5: a vision-language-action model with open-world generalization. arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[19]
S. Liu, L. Wu, B. Li, H. Tan, H. Chen, Z. Wang, K. Xu, H. Su, and J. Zhu. Rdt-1b: a diffusion foundation model for bimanual manipulation.arXiv preprint arXiv:2410.07864, 2024
Pith/arXiv arXiv 2024
-
[20]
Q. Li, Y . Liang, Z. Wang, L. Luo, X. Chen, M. Liao, F. Wei, Y . Deng, S. Xu, Y . Zhang, et al. Cogact: A foundational vision-language-action model for synergizing cognition and action in robotic manipulation.arXiv preprint arXiv:2411.19650, 2024
Pith/arXiv arXiv 2024
-
[21]
M. Shukor, D. Aubakirova, F. Capuano, P. Kooijmans, S. Palma, A. Zouitine, M. Aractingi, C. Pascal, M. Russi, A. Marafioti, et al. Smolvla: A vision-language-action model for affordable and efficient robotics.arXiv preprint arXiv:2506.01844, 2025
Pith/arXiv arXiv 2025
-
[22]
M. J. Kim, C. Finn, and P. Liang. Fine-tuning vision-language-action models: Optimizing speed and success.arXiv preprint arXiv:2502.19645, 2025
Pith/arXiv arXiv 2025
-
[23]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, R. Tedrake, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems, 2023
2023
- [24]
-
[25]
M. Jia, D. Wang, G. Su, D. Klee, X. Zhu, R. Walters, and R. Platt. Seil: Simulation-augmented equivariant imitation learning.arXiv preprint arXiv:2211.00194, 2022
arXiv 2022
-
[26]
James, Z
S. James, Z. Ma, D. R. Arrojo, and A. J. Davison. Rlbench: The robot learning benchmark & learning environment.IEEE Robotics and Automation Letters, 5(2):3019–3026, 2020
2020
-
[27]
A. Dosovitskiy, L. Beyer, A. Kolesnikov, D. Weissenborn, X. Zhai, T. Unterthiner, M. Dehghani, M. Minderer, G. Heigold, S. Gelly, et al. An image is worth 16x16 words: Transformers for image recognition at scale.arXiv preprint arXiv:2010.11929, 2020
Pith/arXiv arXiv 2010
-
[28]
Z. Li, J. Cen, B. Su, W. Huang, T. Xu, Y . Rong, and D. Zhao. Large language-geometry model: When llm meets equivariance.arXiv preprint arXiv:2502.11149, 2025
arXiv 2025
-
[29]
Weiler and G
M. Weiler and G. Cesa. General e (2)-equivariant steerable cnns.Advances in neural information processing systems, 32, 2019
2019
-
[30]
Weiler, P
M. Weiler, P. Forr´e, E. Verlinde, and M. Welling. Equivariant and coordinate independent convolutional networks.A Gauge Field Theory of Neural Networks, 110, 2023
2023
-
[31]
G. Cesa, L. Lang, and M. Weiler. A program to build e (n)-equivariant steerable cnns. In International conference on learning representations, 2022
2022
-
[32]
O. Mees, L. Hermann, and W. Burgard. What matters in language conditioned robotic imitation learning over unstructured data.IEEE Robotics and Automation Letters, 7(4):11205–11212, 2022
2022
-
[33]
Reuss, J
M. Reuss, J. Pari, P. Agrawal, and R. Lioutikov. Efficient diffusion transformer policies with mixture of expert denoisers for multitask learning. InInternational Conference on Learning Representations, volume 2025, pages 17247–17275, 2025. 10
2025
-
[34]
A. A. Duval, V . Schmidt, A. Hern ´andez-Garcıa, S. Miret, F. D. Malliaros, Y . Bengio, and D. Rolnick. Faenet: Frame averaging equivariant gnn for materials modeling. InInternational Conference on Machine Learning, pages 9013–9033. PMLR, 2023
2023
-
[35]
J. Y . Park, S. Bhatt, S. Zeng, L. L. Wong, A. Koppel, S. Ganesh, and R. Walters. Approximate equivariance in reinforcement learning.arXiv preprint arXiv:2411.04225, 2024
arXiv 2024
-
[36]
A” block is placed at one of the four corners of the table, and a letter “I
B. Elesedy and S. Zaidi. Provably strict generalisation benefit for equivariant models. In International conference on machine learning, pages 2959–2969. PMLR, 2021. 11 Appendix Contents A Real-Robot Environment Details 13 B Training Details 14 C Equivariance Analysis 14 C.1 Exact Equivariance . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . ...
2021
-
[37]
GR00T N1.5(no equivariance constraint) shows error growing monotonically from 0◦ to 180◦, consistent with the cosine distance of rotations on a non-equivariant feature space. 2.GR00T N1.5 + EQUIACTORshows an oscillating pattern with higher error at45 ◦-offset angles (45◦,135 ◦,225 ◦,315 ◦) than at C4 angles (90◦,180 ◦,270 ◦), consistent with Theorem 5(b–c...
-
[38]
EQUIVLAremains near-zero and approximately flat across all angles, confirming that EQUIPER- CEPTORsuppresses the upstream vision equivariance violation uniformly across the group. 0◦ 45◦ 90◦ 135◦ 180◦ 225◦ 270◦ 315◦ 2.8 5.5 8.3 11 GR00T N1.5 GR00T N1.5 + EQUIACTOR EQUIVLA (ours) Figure 4: Per-group equivariance error ϵeq at each C8 rotation angle, measure...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.