ORAgentBench: Can LLM Agents Solve Challenging Operations Research Tasks End to End?
Pith reviewed 2026-06-26 17:29 UTC · model grok-4.3
The pith
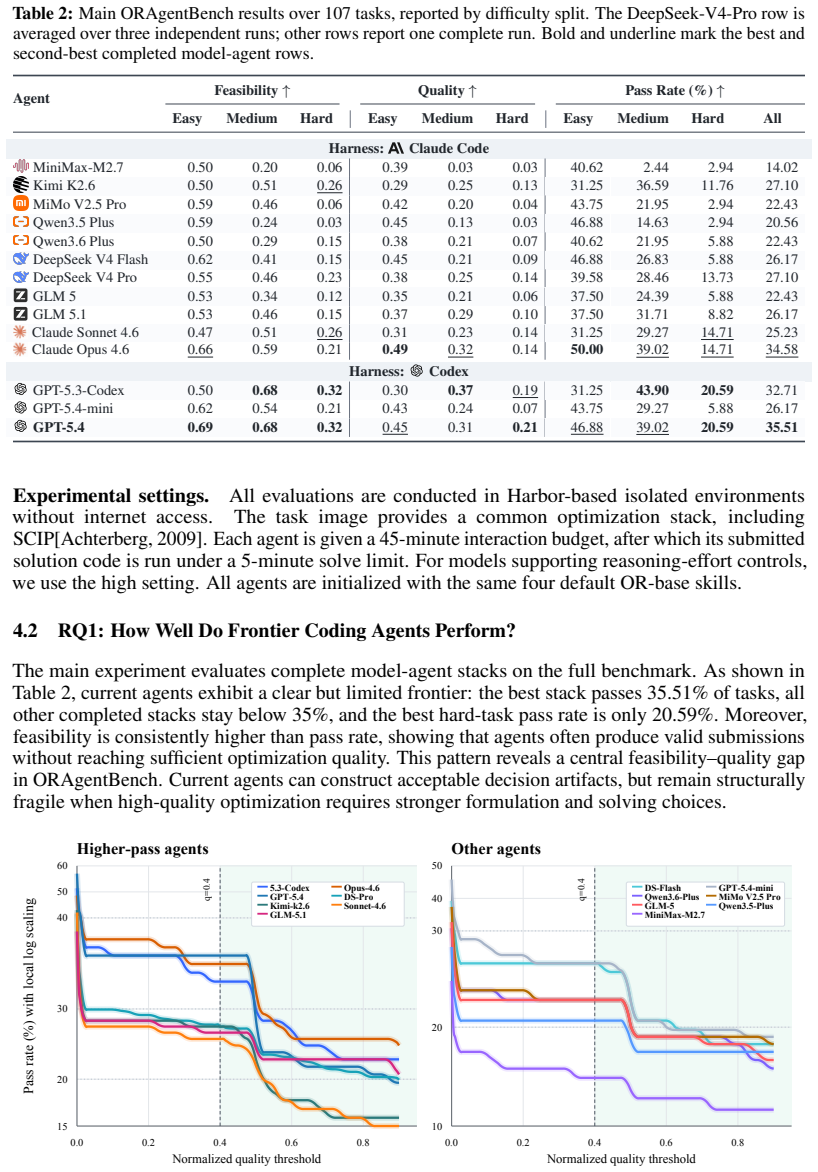
Current LLM agents pass only 35.51 percent of end-to-end operations research tasks and 20.59 percent of the hard ones.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
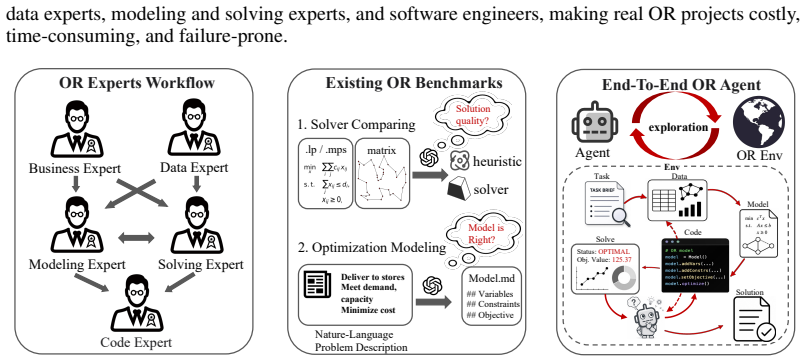
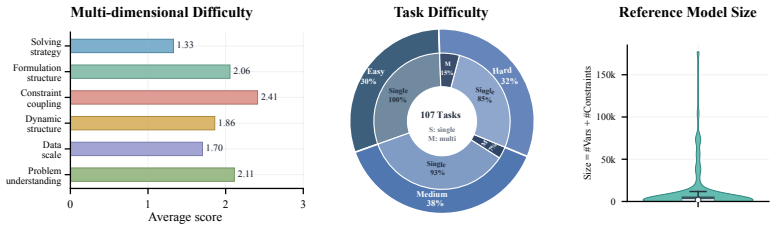
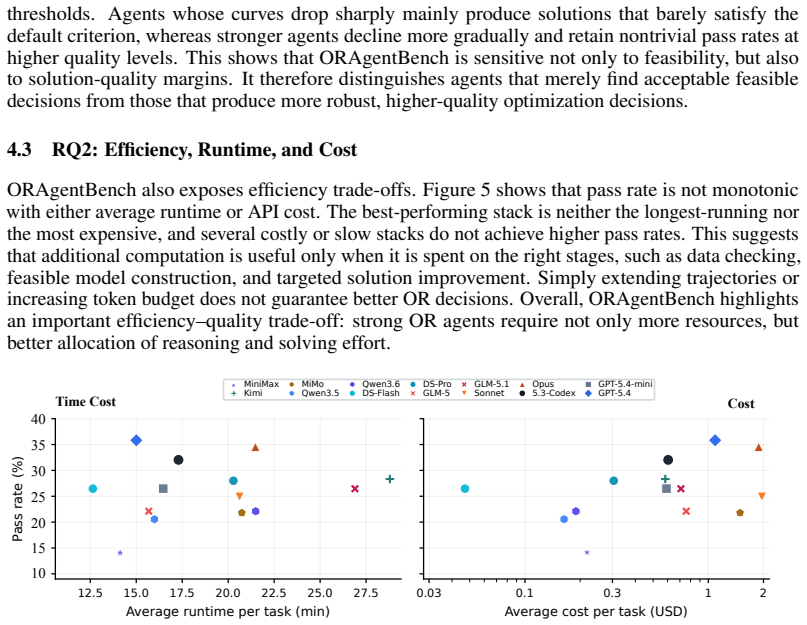
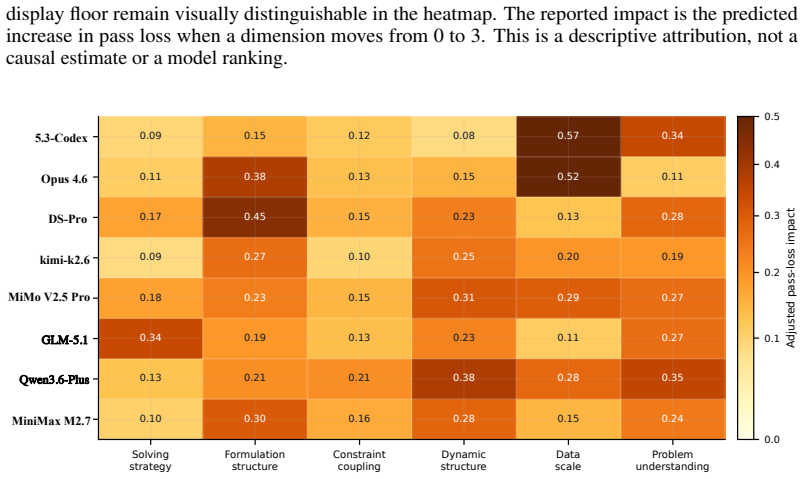
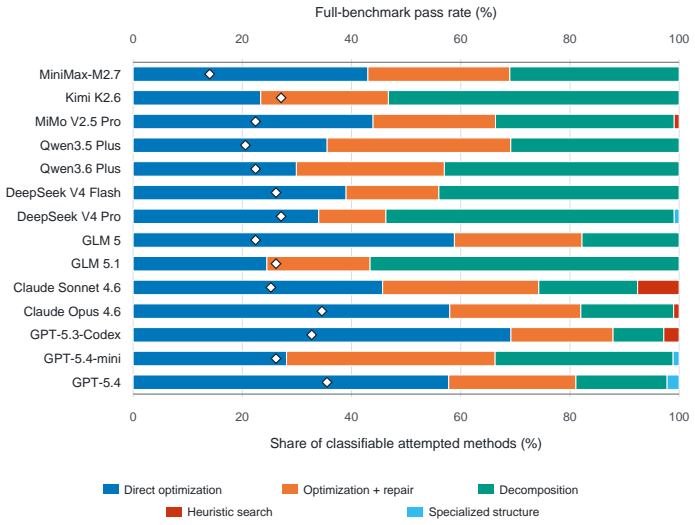
ORAgentBench supplies 107 tasks, each with a natural-language brief, multi-file data, configuration artifacts, and a required submission schema; agents must write and execute code whose output is scored by hidden validators on validity, feasibility, and quality. The best of fourteen tested configurations passes 35.51 percent of all tasks and 20.59 percent of hard tasks, while many feasible submissions still fall short of the quality threshold. Failure modes are dominated by strategic weaknesses rather than low-level coding mistakes, and OR-specific procedural skills improve feasibility without reliably raising pass rates or solution quality.
What carries the argument
ORAgentBench, an execution-grounded suite of 107 tasks that requires agents to move from operational artifacts to validator-approved decisions using hidden checks on schema, feasibility, and objective quality.
If this is right
- OR-specific procedural skills raise hard-task feasibility but do not improve solution quality or overall pass rates.
- Strategic weaknesses in rule adherence, formulation, and iterative improvement remain the primary barriers to reliable performance.
- Dependable OR agents will require capabilities beyond generating plausible optimization code.
- Progress depends on developing agents that produce high-quality operational decisions rather than merely feasible ones.
Where Pith is reading between the lines
- If agents close the gap on this benchmark, automated OR workflows could become practical for logistics and resource allocation problems that currently require expert modelers.
- The benchmark design could be reused to compare hybrid LLM-plus-solver systems against pure agent approaches on the same tasks.
- Persistent quality shortfalls suggest that future work may need explicit mechanisms for objective-function refinement and constraint tightening rather than relying on general reasoning alone.
Load-bearing premise
The 107 tasks packaged with natural-language briefs, multi-file data, and hidden validators accurately represent the complexity and quality standards of realistic end-to-end operations research problems.
What would settle it
A new agent configuration that passes at least 70 percent of the hard tasks while also meeting the quality threshold on those passes would directly contradict the reported performance gap.
Figures

read the original abstract
Large language models are increasingly deployed as autonomous agents for multi-step tasks in executable environments, yet their ability to perform realistic operations research (OR) work remains unclear. Existing OR evaluations often decouple modeling from solving, rely on pre-formalized or text-only instances, and rarely test the full workflow from operational artifacts to validated decisions. In this work, we introduce ORAgentBench, an execution-grounded benchmark for evaluating autonomous agents on challenging end-to-end operations research tasks. It contains 107 human-reviewed tasks across diverse operational scenarios, each packaged in an isolated environment with a natural-language brief, multi-file data, configuration artifacts, and a required submission schema. Agents must write and run solution code, and their submissions are evaluated by hidden validators for schema validity, hard-constraint feasibility, and normalized objective quality. Experiments with fourteen frontier agent-model configurations show that current agents remain far from reliable OR practice. The best agent passes only 35.51% of all tasks and 20.59% of hard tasks, and many feasible submissions still fall below the required quality threshold. Failure analysis further shows that errors are dominated by strategic weaknesses, including missed operational rules, brittle formulations, weak feasible-solution construction, and insufficient solution improvement. OR-specific procedural skills increase hard-task feasibility, but do not reliably improve solution quality or pass rate. These results suggest that progress in OR agents requires moving beyond plausible optimization code toward dependable, high-quality operational decision-making.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces ORAgentBench, an execution-grounded benchmark containing 107 human-reviewed end-to-end operations research tasks. Each task includes a natural-language brief, multi-file data, configuration artifacts, and a hidden validator assessing schema validity, hard-constraint feasibility, and normalized objective quality. Experiments across fourteen frontier agent-model configurations report that the best agent achieves a 35.51% pass rate overall and 20.59% on hard tasks, with failures dominated by missed operational rules, brittle formulations, weak feasible-solution construction, and insufficient improvement; OR-specific procedural skills improve feasibility but not overall pass rate or quality.
Significance. If the tasks accurately reflect realistic OR complexity, constraint tightness, and quality thresholds, the results provide concrete evidence that current LLM agents fall short of reliable end-to-end OR practice. The benchmark's use of hidden validators and multi-file operational artifacts strengthens evaluation beyond decoupled modeling or text-only instances. The failure-mode analysis supplies actionable distinctions between code plausibility and dependable decision-making.
major comments (3)
- [paragraph describing benchmark construction and evaluation criteria] Paragraph describing benchmark construction and evaluation criteria: no selection protocol, inter-rater reliability statistics, pilot validation against practicing OR analysts, or comparison of constraint tightness to published industrial instances is supplied. This directly affects whether the headline pass rates (35.51% overall, 20.59% hard) can be interpreted as evidence of general agent limitations rather than benchmark-specific artifacts.
- [abstract and implied experiments section] Abstract and implied experiments section: the reported pass rates lack accompanying statistical tests, confidence intervals, or details on how 'hard' tasks were defined and stratified, making it impossible to assess whether the performance gap between agents is robust.
- [failure analysis] Failure analysis: the categorization of errors into strategic weaknesses (missed rules, brittle formulations, etc.) is presented without quantitative breakdowns per agent or inter-annotator agreement on classification, weakening the claim that OR-specific procedural skills increase feasibility but do not improve solution quality or pass rate.
minor comments (1)
- A summary table listing the fourteen agent-model configurations together with their individual overall and hard-task pass rates would improve readability of the experimental results.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback on ORAgentBench. The comments identify important gaps in documentation of benchmark construction, statistical reporting, and failure-mode quantification. We address each point below, indicating revisions where we can strengthen the manuscript without misrepresenting the work performed.
read point-by-point responses
-
Referee: Paragraph describing benchmark construction and evaluation criteria: no selection protocol, inter-rater reliability statistics, pilot validation against practicing OR analysts, or comparison of constraint tightness to published industrial instances is supplied. This directly affects whether the headline pass rates (35.51% overall, 20.59% hard) can be interpreted as evidence of general agent limitations rather than benchmark-specific artifacts.
Authors: We acknowledge the absence of a formal multi-rater protocol, inter-rater reliability metrics, external pilot validation with practicing analysts, and quantitative comparison of constraint tightness to industrial instances. Task curation was performed internally by the author team drawing on domain expertise, with each task human-reviewed for executability and realism. In revision we will add a dedicated subsection detailing the selection criteria, domain coverage, and internal review process. We will also expand the limitations section to explicitly note the lack of external validation and inter-rater statistics and discuss implications for generalizability. These additions will allow readers to better evaluate whether the reported pass rates reflect agent limitations or benchmark-specific features. revision: partial
-
Referee: Abstract and implied experiments section: the reported pass rates lack accompanying statistical tests, confidence intervals, or details on how 'hard' tasks were defined and stratified, making it impossible to assess whether the performance gap between agents is robust.
Authors: We agree that statistical support and clearer stratification details are needed. In the revised manuscript we will report 95% bootstrap confidence intervals for the overall and hard-task pass rates. We will also expand the experimental section to define 'hard' tasks explicitly (based on the number of decision variables, constraints, and operational-rule complexity assessed at curation) and describe the stratification procedure. Where sample sizes permit, we will add pairwise statistical comparisons between agent configurations. revision: yes
-
Referee: Failure analysis: the categorization of errors into strategic weaknesses (missed rules, brittle formulations, etc.) is presented without quantitative breakdowns per agent or inter-annotator agreement on classification, weakening the claim that OR-specific procedural skills increase feasibility but do not improve solution quality or pass rate.
Authors: The error taxonomy was derived from manual inspection of agent trajectories. We will add a table providing quantitative per-agent breakdowns of each error category (missed rules, brittle formulations, weak feasible-solution construction, insufficient improvement). We will state that classification was performed by a single OR-experienced annotator and note the absence of inter-annotator agreement as a limitation. These changes will make the failure analysis more quantitative while preserving the original qualitative observations. revision: partial
Circularity Check
No circularity: empirical benchmark with direct measurements only.
full rationale
This is an empirical benchmark paper with no derivation chain, equations, fitted parameters, or first-principles predictions. Results consist of direct pass-rate measurements (35.51% overall, 20.59% hard) on 107 human-reviewed tasks evaluated by hidden validators; the benchmark construction itself is described as an input artifact rather than derived. No self-citation load-bearing steps, self-definitional reductions, or ansatz smuggling appear in the provided text. The work is self-contained as an observational study.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption The 107 human-reviewed tasks represent challenging, realistic end-to-end operations research problems across diverse scenarios
Reference graph
Works this paper leans on
-
[1]
Accessed: 2026-06-07. OpenAI. Introducing GPT-5.3-Codex. https://openai.com/index/ introducing-gpt-5-3-codex/, 2026a. Accessed: 2026-06-07. OpenAI. Introducing GPT-5.4. https://openai.com/index/introducing-gpt-5-4/ , 2026b. Accessed: 2026-06-07. OpenAI. Introducing GPT-5.4 mini and nano. https://openai.com/index/ introducing-gpt-5-4-mini-and-nano/, 2026c....
work page internal anchor Pith review Pith/arXiv arXiv doi:10.1007/978-3-319-26580-3 2026
-
[2]
ISBN 9781118443330. Xiaomi MiMo Team. MiMo-V2.5 model card. https://huggingface.co/XiaomiMiMo/ MiMo-V2.5, 2026. Accessed: 2026-06-07. Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, et al. Osworld: Benchmarking multimodal agents for open-ended tasks in real computer ...
Pith/arXiv arXiv 2026
-
[3]
Read ‘/app/PROBLEM_STATEMENT.md‘ and every file under ‘/app/data/‘
-
[4]
Write a complete mathematical model to ‘/app/submissions/model.md‘ before finalizing code
-
[5]
Implement the solver in ‘/app/submissions/solve.py‘ using PySCIPOpt
-
[6]
If ‘ORCLAW_SOLVE_TIME_LIMIT_SECONDS‘ is set, use a time limit no larger than that value
Use SCIP relative gap ‘0.0005‘. If ‘ORCLAW_SOLVE_TIME_LIMIT_SECONDS‘ is set, use a time limit no larger than that value. Preserve solution values with precision up to ‘1e-8‘ after the decimal point
-
[7]
Make ‘/app/submissions/solve.py‘ solve from scratch when run as ‘python /app/submissions/solve.py‘
-
[8]
Write the required solution file under ‘/app/submissions/‘ using the task schema
-
[9]
Note: You may improve the modeling and solving strategy based on preliminary results, but each individual solve attempt is limited to 5 minutes
Write ‘/app/submissions/solve_log.md‘ with commands, solver status, objective or score if available, and validation checks. Note: You may improve the modeling and solving strategy based on preliminary results, but each individual solve attempt is limited to 5 minutes. The whole workflow is also time-limited, so do not perform unlimited full solve-and-iter...
-
[10]
Use stronger mathematical formulations and more sophisticated modeling strategies tailored to the structure, special properties, and scale of the given problem instance
-
[11]
Solve directly with SCIP when the model is tractable
-
[12]
Design effective heuristic, local-search, repair, or rounding methods when exact optimization is too slow
-
[13]
Combine heuristics with SCIP, for example by generating an initial feasible solution, fixing or relaxing selected variables, using warm starts if supported, or solving restricted subproblems
-
[14]
Do not default to a naive formulation
Run short diagnostic solves to estimate difficulty, then refine the model or solution method. Do not default to a naive formulation. Before coding, explicitly analyze whether the problem is better represented as an assignment model, network flow model, set partitioning model, time- indexed model, interval/order-based scheduling model, routing model, or de...
-
[15]
Correctly modeled setup activation, printer hours, scrap-adjusted material use, medical certification, and integer production
-
[16]
Added an order-acceptance binaryy o and replaced the public lower bound withP p xop ≥L oyo, allowing an order to be rejected with zero production
-
[17]
Its independent checker repeated the same interpretation, accepting each order quantity if it was either zero or within its fill interval
-
[18]
Verifier evidence:three hard errors, O02/O07/O18 misses required fill rate; the plan was infeasible, so quality was zero
The resulting plan omitted O02, O07, and O18, reported profit 12,305.9483, and passed all of its local checks. Verifier evidence:three hard errors, O02/O07/O18 misses required fill rate; the plan was infeasible, so quality was zero. DeepSeek-V4-Pro: success (F= 1,q= 2)
-
[19]
Kept the fill constraint unconditional for every order:⌈ρ oDo⌉ ≤ P p xop ≤D o
-
[20]
Linked every production variable to a qualified setup, filtered regulated orders to certified printers, and modeled printer-hour and material capacities
-
[21]
Solved the compact MIP to the requested relative gap and activated seven printer–material setups
-
[22]
Verifier evidence:zero errors, feasibility one, and maximum quality scoreq= 2
Submitted positive production for all 20 orders; the hidden evaluator verified 628 parts, zero errors, and profit 11,688.0909. Verifier evidence:zero errors, feasibility one, and maximum quality scoreq= 2. Failure analysis The public packet states thatevery orderhas a minimum fill rate and that shipped quantity for that order must reach the stated fractio...
-
[23]
Built feasible 27-project portfolios with MILP seeds and greedy project swaps
-
[24]
Coded impedance as flat through 20 minutes, then used only the shallow first slope through 40 minutes
-
[25]
Used that routine to rank every move and validate the final portfolio
-
[26]
Verifier evidence:exact objective 204,851,681 versus reference 216,495,022; replaying Qwen’s formula on the verifier paths exactly reproduces its reported 300,734,176
Reported 300,734,176 after side-constraint checks, without independent objective validation. Verifier evidence:exact objective 204,851,681 versus reference 216,495,022; replaying Qwen’s formula on the verifier paths exactly reproduces its reported 300,734,176. Kimi K2.6: success (F= 1,q= 1)
-
[27]
Rejected a full path formulation as unnecessarily large and initialized a restricted path set
-
[28]
Solved a project-selection master problem using those candidate routes
-
[29]
Evaluated the incumbent with exact shortest paths, detected missing improving routes, and added them
-
[30]
Verifier evidence:feasible portfolio and objective 216,495,021.89, matching the verified reference
Re-optimized to convergence and polished the portfolio with exact-objective one-swap checks. Verifier evidence:feasible portfolio and objective 216,495,021.89, matching the verified reference. 26 Failure analysis This was an objective-function specification error, not a feasibility or weak-search failure. Qwen treated the first breakpoint as a zero-penalt...
-
[31]
Built a deterministic-equivalent assignment model with scenario costs and CVaR, reporting a 0.00% MIP gap
-
[32]
Enforced equipment use counts by day and added turnaround corrections for same-pool cases within one OR block
-
[33]
Sequenced and validated each block independently, then reported 34 of 36 cases scheduled with zero internal errors
-
[34]
Verifier evidence:one hard-constraint error: robotic_scopeoccupancy reached 2 on day 3 although only one unit was available
Assigned S023 and S024 to different day-3 rooms, both at minute 15, although both require the single-unitrobotic_scope. Verifier evidence:one hard-constraint error: robotic_scopeoccupancy reached 2 on day 3 although only one unit was available. GPT-5.3-Codex: success (F= 1,q= 0.921)
-
[35]
Used a compact assignment, interval, and ordering formulation for blocks and shared resources
-
[36]
Integrated expected scenario cost and CVaR while retaining a valid incumbent during improvement
-
[37]
Scheduled 34 of 36 cases and preserved the sequence and start-time semantics required by the evaluator
-
[38]
Verifier evidence:zero errors; objective 110,193.65 versus reference 111,966.26, yielding normalized quality 0.921
Re-parsed the final artifact and independently checked schema and hard feasibility. Verifier evidence:zero errors; objective 110,193.65 versus reference 111,966.26, yielding normalized quality 0.921. 28 Failure analysis The submission contract was valid and the evaluator reconstructed the full schedule. The failure instead came from an incomplete shared-r...
-
[39]
Produced feasible initial and step-2 plans, including path, empty-move, and inventory decisions for all visible bookings
-
[40]
At the final event, expanded the model to 128 bookings and incorporated the new medical-reefer and yard-disruption tables
-
[41]
Stated that departures on day 8 were frozen, but implemented the test asdepart_day <
-
[42]
It therefore classified B053 and B061, both routed on L16 departing on day 8, as changeable and rejected them
-
[43]
Its internal checks reused these definitions and therefore accepted an invalid optimum
Mis-timed customs events in its MIP: it ignored origin preclearance shifts, charged transfers on the outgoing departure day rather than the incoming arrival day, and delayed reefer imports by one day. Its internal checks reused these definitions and therefore accepted an invalid optimum. Verifier evidence:the five messages represent three physical violati...
-
[44]
Built a compact path-selection model coupled to empty inventory, repositioning, leasing, service, and event-specific capacity constraints
-
[45]
Reloaded each prior submission as binding state and explicitly preserved accepted paths whose departures fell inside the freeze window
-
[46]
Rebuilt candidate paths and operating constraints after each event, including protected slots, transfer caps, customs windows, and medical rules
-
[47]
Verifier evidence:all three stages had zero errors
Re-parsed the final artifact and compared it with the previous plan before submission; no frozen acceptance decision or path changed. Verifier evidence:all three stages had zero errors. The final plan accepted 121 of 128 bookings, used two empty moves and four leases, incurred no change cost, and achieved verified profit 43,116.05. Failure analysis This i...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.