The Hidden Environmental Cost of Poor Coding Practices in TensorFlow and Keras Applications: A Study on Resource Leaks and Carbon Emissions
Pith reviewed 2026-06-26 16:58 UTC · model grok-4.3
The pith
Resource leaks in TensorFlow and Keras code raise electricity use by 32 to 46 percent.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
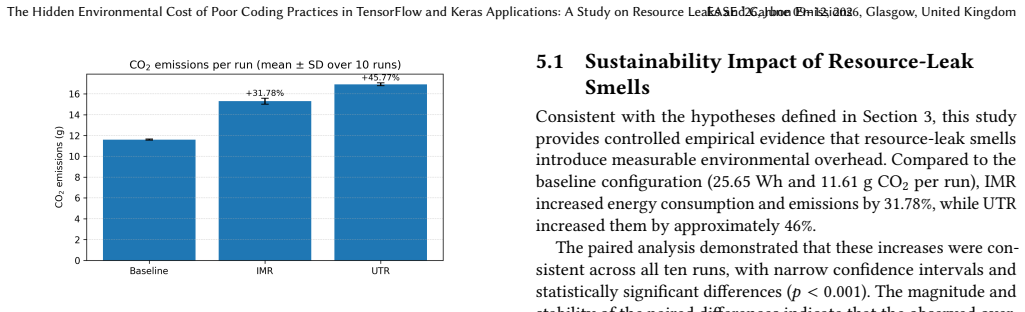
Controlled experiments on identical training tasks show that Improper Model Reuse increases electricity consumption by approximately 32 percent and Unreleased Tensor References by approximately 46 percent, with proportional rises in estimated CO2 emissions; paired statistical tests confirm the differences are systematic and significant.
What carries the argument
Controlled experiments that run identical training tasks against a smell-free baseline to isolate the isolated effects of Improper Model Reuse and Unreleased Tensor References on energy and emissions.
Load-bearing premise
The controlled experiments isolate the effect of the resource leaks alone, with identical training tasks differing only in the presence of IMR or UTR and with accurate energy measurement methods.
What would settle it
Re-running the same training tasks on different hardware or with different models and finding no statistically significant difference in measured electricity use between the versions that contain the smells and the clean baselines.
Figures


read the original abstract
Efficiency and sustainability are critical considerations in the development and deployment of machine learning (ML) applications. Among the factors influencing sustainability, resource leaks in ML code can introduce hidden inefficiencies that elevate energy consumption and CO2 emissions. Despite this, empirical evidence quantifying their environmental impact remains limited. This emerging results paper presents an initial empirical investigation of two common resource-leak smells, namely Improper Model Reuse (IMR) and Unreleased Tensor References (UTR), and their impact on energy consumption and CO2 emissions in TensorFlow and Keras workloads. Controlled experiments were conducted for each smell by executing identical training tasks while comparing against a smell-free baseline. Our preliminary results show that both smells consistently increase estimated electricity usage and carbon emissions. IMR and UTR increased electricity consumption by approximately 32% and 46%, respectively, with proportional increases in CO2 emissions. Paired statistical tests indicate that these differences are systematic and statistically significant, providing initial empirical evidence that resource-leak smells may degrade ML energy efficiency and environmental sustainability. These findings suggest that resource-leak smells pose measurable risks to both software quality and sustainability, emphasizing the importance of integrating resource-lifecycle management and energy-efficiency considerations into ML development.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that two resource-leak code smells in TensorFlow/Keras applications—Improper Model Reuse (IMR) and Unreleased Tensor References (UTR)—increase estimated electricity consumption by approximately 32% and 46% respectively (with proportional CO2 increases) relative to smell-free baselines. This is based on controlled experiments executing identical training tasks, with paired statistical tests reported as showing the differences are systematic and statistically significant.
Significance. If the energy measurements prove accurate and the experiments properly isolate the smells' effects, the work would provide useful initial empirical evidence connecting common ML coding practices to measurable environmental costs, supporting calls to integrate resource-lifecycle management into ML development workflows.
major comments (2)
- [Abstract] Abstract: the headline claims of 32% (IMR) and 46% (UTR) increases in electricity usage rest on an unspecified 'estimation' method. No description is given of the tool, model, sampling rate, calibration procedure, or handling of secondary effects such as changed GPU/CPU utilization or memory pressure induced by the leaks themselves; without this, the deltas cannot be confirmed as reflecting actual joule differences rather than estimator artifacts.
- [Abstract] Abstract: the controlled-experiment description provides no information on training-task specifics (model architecture, dataset, epochs), hardware platform, number of runs per condition, sample sizes, variability measures, or the exact paired statistical test and its results (p-values, degrees of freedom). These omissions make it impossible to assess whether the experiments isolate the smells or whether the significance claims are reliable.
Simulated Author's Rebuttal
Thank you for your review and the recommendation for major revision. We address each of the major comments below and plan to incorporate clarifications and additional details into the revised manuscript.
read point-by-point responses
-
Referee: [Abstract] Abstract: the headline claims of 32% (IMR) and 46% (UTR) increases in electricity usage rest on an unspecified 'estimation' method. No description is given of the tool, model, sampling rate, calibration procedure, or handling of secondary effects such as changed GPU/CPU utilization or memory pressure induced by the leaks themselves; without this, the deltas cannot be confirmed as reflecting actual joule differences rather than estimator artifacts.
Authors: We agree that the abstract omits these methodological details. As this is an emerging results paper, the abstract is kept brief. We will revise the manuscript by adding a methods subsection that specifies the energy estimation tool used, the underlying power model, sampling rate, calibration procedure, and how we accounted for secondary effects like utilization changes due to the leaks. This will allow verification that the increases are attributable to the smells rather than artifacts. revision: yes
-
Referee: [Abstract] Abstract: the controlled-experiment description provides no information on training-task specifics (model architecture, dataset, epochs), hardware platform, number of runs per condition, sample sizes, variability measures, or the exact paired statistical test and its results (p-values, degrees of freedom). These omissions make it impossible to assess whether the experiments isolate the smells or whether the significance claims are reliable.
Authors: We acknowledge this limitation in the current abstract. We will revise the paper to include a comprehensive experimental setup description covering the training task details (model architecture, dataset, epochs), hardware platform, number of runs per condition, sample sizes, variability measures (e.g., standard deviation across runs), and the statistical test results including p-values and degrees of freedom. This will enable readers to evaluate the isolation of the smells' effects and the reliability of the significance claims. revision: yes
Circularity Check
No circularity: direct empirical comparison of controlled runs
full rationale
The paper reports results from controlled experiments that execute identical training tasks with and without the two smells, then apply paired statistical tests to the measured differences in estimated electricity and CO2. No equations, fitted parameters, self-citations, or derivations are present in the provided text that would reduce the reported 32%/46% deltas to inputs by construction. The central claim rests on the experimental design itself rather than any self-referential definition or prior fitted result from the same authors. This is a standard empirical measurement study whose validity hinges on measurement accuracy and isolation (addressed by the skeptic under correctness, not circularity).
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Energy consumption differences can be accurately attributed to the presence or absence of the two resource leaks in controlled runs.
- domain assumption Electricity usage estimates reliably translate to CO2 emission estimates.
Reference graph
Works this paper leans on
-
[1]
Wojciechowska, Gustavo Santos, Edmand Yu, Maxime Lamothe, Alain Abran, and Mohammad Hamdaqa
Bashar Abdallah, Martyna E. Wojciechowska, Gustavo Santos, Edmand Yu, Maxime Lamothe, Alain Abran, and Mohammad Hamdaqa. 2025. From Code Smells to Best Practices: Tackling Resource Leaks in PyTorch, TensorFlow, and Keras.arXiv preprint arXiv:2511.15229(2025). https://arxiv.org/abs/2511.15229
arXiv 2025
-
[2]
Benoit Courty et al. 2024. mlco2/codecarbon: v2.4.1. doi:10.5281/zenodo.11171501 Software package
-
[3]
Hedi Jebnoun, Heba Ben Braiek, Mohammad Masudur Rahman, and Foutse Khomh. 2020. The Scent of Deep Learning Code: An Empirical Study. InProceed- ings of the 17th International Conference on Mining Software Repositories (MSR). 420–430. doi:10.1145/3379597.3387479
-
[4]
Ioannis Mavromatis, Konstantinos Katsaros, and Asad Khan. 2024. Computing Within Limits: An Empirical Study of Energy Consumption in ML Training and Inference.arXiv preprint arXiv:2406.14328(2024). http://arxiv.org/abs/2406.14328
arXiv 2024
-
[5]
Md Rakib Hasan Misu, Jiajun Li, Akhil Bhattiprolu, Yan Liu, Eduardo Almeida, and Iftekhar Ahmed. 2025. Test Smell: A Parasitic Energy Consumer in Software Testing.Information and Software Technology175 (2025), 107671. doi:10.1016/j. infsof.2025.107671
work page doi:10.1016/j 2025
-
[6]
Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean
David Patterson, Joseph Gonzalez, Quoc V. Le, Chen Liang, Lluis-Miquel Munguia, Daniel Rothchild, David So, Maud Texier, and Jeff Dean. 2021. Carbon Emissions and Large Neural Network Training.arXiv preprint arXiv:2104.10350(2021). https://arxiv.org/abs/2104.10350
Pith/arXiv arXiv 2021
-
[7]
Alejandro Sánchez-Mompó, Ioannis Mavromatis, Panagiotis Li, Konstantinos Katsaros, and Asad Khan. 2025. Green MLOps to Green GenOps: An Empirical Study of Energy Consumption in Discriminative and Generative AI Operations. Information16, 4 (2025). doi:10.3390/info16040281
-
[8]
Emma Strubell, Ananya Ganesh, and Andrew McCallum. 2020. Energy and Policy Considerations for Modern Deep Learning Research. InProceedings of the AAAI Conference on Artificial Intelligence, Vol. 34. 13693–13701. doi:10.1609/aaai.v34i09. 7123
-
[9]
2014.Refac- toring for Software Design Smells: Managing Technical Debt
Girish Suryanarayana, Ganesh Samarthyam, and Tushar Sharma. 2014.Refac- toring for Software Design Smells: Managing Technical Debt. Morgan Kaufmann. doi:10.1016/C2013-0-23413-9
-
[10]
Claes Wohlin, Per Runeson, Martin Höst, Magnus C. Ohlsson, Björn Regnell, and Anders Wesslén. 2012.Experimentation in Software Engineering. Springer. doi:10.1007/978-3-642-29044-2
-
[11]
Priyanka Singh Yadav, Raghavendra Selvan Rao, Alok Mishra, and Manish Gupta
-
[12]
Applied Sciences14, 14 (2024), 6149
Machine Learning-Based Methods for Code Smell Detection: A Survey. Applied Sciences14, 14 (2024), 6149. doi:10.3390/app14146149 A Detailed Experimental Results This appendix provides the full per-run measurements supporting the results in Section 4. Energy is reported in kWh and CO2 in kg, consistent with CodeCarbon outputs. Table 3: Per-run energy consum...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.