MetaResearcher: Scaling Deep Research via Self-Reflective Reinforcement Learning in Adversarial Virtual Environments
Pith reviewed 2026-06-26 17:40 UTC · model grok-4.3
The pith
MetaResearcher scales deep research agent training across four dimensions: an evolving virtual world, discovery tasks, self-reflective rewards, and multi-agent swarms.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MetaResearcher scales deep research agent training across four synergistic dimensions—an Evolving Virtual World that injects temporal dynamics and adversarial misinformation, Discovery-Oriented Tasks such as hypothesis generation and contradiction resolution, a Self-Reflective Meta-Reward mechanism within the GRPO framework, and a Heterogeneous Multi-Agent Swarm of Scout, Filter, and Synthesizer models—to produce substantial improvements in benchmark performance on GAIA and Xbench-DS together with greater epistemic robustness under adversarial conditions.
What carries the argument
The MetaResearcher framework, whose four dimensions—an evolving virtual world, discovery-oriented tasks, self-reflective meta-reward in GRPO, and heterogeneous multi-agent swarm—jointly train agents for research behaviors beyond simple retrieval.
If this is right
- Agents acquire source credibility assessment skills through repeated exposure to adversarial misinformation.
- Agents gain temporal conflict resolution abilities from the time-varying environment.
- Benchmark scores rise on GAIA and Xbench-DS relative to prior static-environment training.
- Epistemic robustness increases when agents face coordinated misinformation attacks.
- All gains occur with zero marginal API cost by building on the LiteResearcher infrastructure.
Where Pith is reading between the lines
- The swarm architecture could reduce repetitive action loops by distributing roles across specialized models.
- The self-reflective reward might generalize to other reinforcement-learning domains that suffer from inefficient search paths.
- Success on these dimensions would suggest that dynamic, adversarial training environments are broadly useful for building reliable autonomous reasoning systems.
Load-bearing premise
The premise that an evolving virtual world with temporal dynamics and adversarial misinformation will force agents to develop source credibility assessment and temporal conflict resolution skills.
What would settle it
If agents trained under MetaResearcher show no measurable gains over baselines in detecting misinformation or resolving time-based information conflicts on separate adversarial test sets, the contribution of the evolving virtual world dimension and the overall scaling claim would be falsified.
Figures



read the original abstract
Deep research agents have demonstrated remarkable capabilities in autonomous information gathering and synthesis, yet their training remains constrained by the static nature of simulated environments, the limits of fact-retrieval-only task designs, and the inefficiency of outcome-based reinforcement learning. In this work, we propose MetaResearcher, a novel framework that scales deep research agent training across four synergistic dimensions. First, we introduce an Evolving Virtual World that injects temporal dynamics and adversarial misinformation into the training environment, forcing agents to develop source credibility assessment and temporal conflict resolution skills. Second, we design Discovery-Oriented Tasks -- including hypothesis generation and contradiction resolution -- that transcend simple fact retrieval and push agents toward genuine research behaviors. Third, we propose a Self-Reflective Meta-Reward mechanism within the GRPO framework that jointly optimizes for answer correctness, search path efficiency, reflection depth, and tool call diversity, directly addressing the repetitive action loop problem observed in prior work. Fourth, we introduce a Heterogeneous Multi-Agent Swarm architecture comprising specialized Scout, Filter, and Synthesizer models that learn collaborative research strategies through coordinated reinforcement learning. Built upon the LiteResearcher infrastructure, MetaResearcher requires zero marginal API cost for training while targeting substantial improvements in both benchmark performance (GAIA, Xbench-DS) and epistemic robustness under adversarial conditions. We present the complete framework design, training methodology, and planned experimental validation.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes MetaResearcher, a framework scaling deep research agent training across four dimensions: an Evolving Virtual World injecting temporal dynamics and adversarial misinformation, Discovery-Oriented Tasks (hypothesis generation, contradiction resolution), a Self-Reflective Meta-Reward in GRPO optimizing correctness/efficiency/reflection/diversity, and a Heterogeneous Multi-Agent Swarm (Scout/Filter/Synthesizer) for collaborative RL. Built on LiteResearcher with zero marginal API cost, it targets gains on GAIA/Xbench-DS and epistemic robustness under adversarial conditions, presenting the full design, methodology, and planned validation.
Significance. If implemented and shown to work, the framework could meaningfully advance research-agent training by moving beyond static fact-retrieval settings and outcome-only RL toward more realistic epistemic skills and collaborative strategies. The zero-marginal-cost claim and explicit focus on falsifiable benchmark predictions are strengths worth noting. At present the significance remains prospective because the manuscript supplies only the design.
major comments (2)
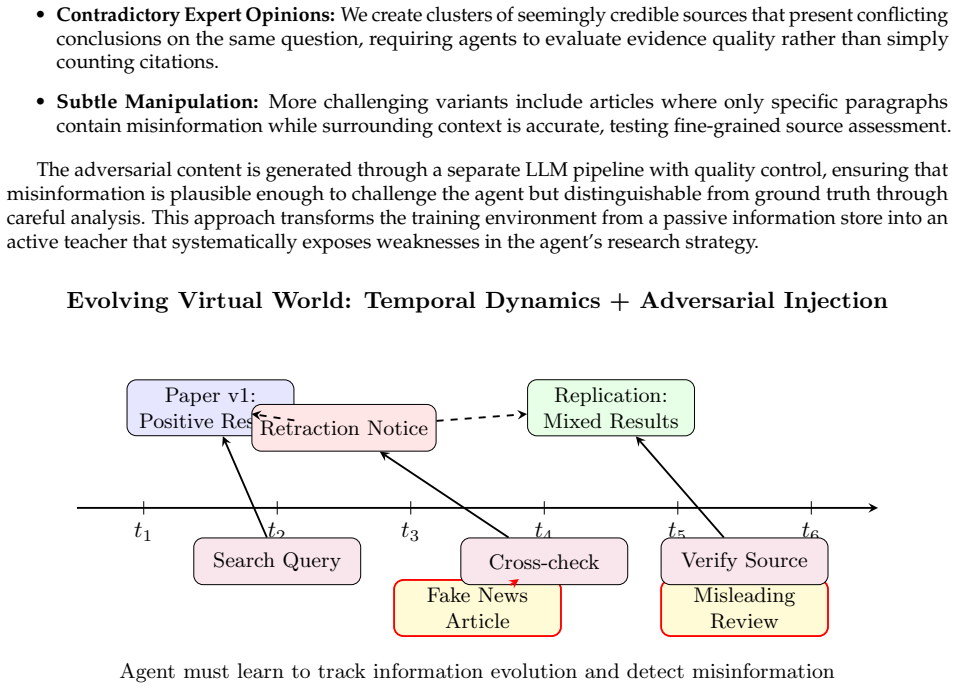
- [Abstract] Abstract (first dimension): the premise that temporal dynamics plus adversarial misinformation will force development of source-credibility assessment and temporal-conflict-resolution skills is asserted at a high level with no mechanism description, pseudocode, or even an illustrative example of misinformation injection; this premise is load-bearing for the claim that the four dimensions produce synergistic scaling and robustness gains.
- [Abstract] Abstract: the statement that MetaResearcher 'targets substantial improvements in both benchmark performance (GAIA, Xbench-DS) and epistemic robustness' rests entirely on the untested design; no results, ablation plan, or error analysis is supplied, leaving the central empirical claim without anchor.
minor comments (1)
- [Abstract] The acronym GRPO is used without expansion or citation on first appearance.
Simulated Author's Rebuttal
We thank the referee for the careful reading and constructive feedback on our framework proposal. We agree that the abstract would benefit from greater concreteness on mechanisms and clearer framing of the prospective claims. Below we respond point-by-point and commit to revisions that strengthen the manuscript without altering its core contribution as a design paper.
read point-by-point responses
-
Referee: [Abstract] Abstract (first dimension): the premise that temporal dynamics plus adversarial misinformation will force development of source-credibility assessment and temporal-conflict-resolution skills is asserted at a high level with no mechanism description, pseudocode, or even an illustrative example of misinformation injection; this premise is load-bearing for the claim that the four dimensions produce synergistic scaling and robustness gains.
Authors: We accept that the abstract states the premise concisely. The full manuscript elaborates the Evolving Virtual World in the methodology section through evolving knowledge graphs, time-stamped fact updates, and injected contradictory sources generated by an adversarial module. To make this load-bearing premise more transparent and directly responsive to the comment, we will insert a short illustrative example of misinformation injection (e.g., a temporal contradiction between two sources) together with a high-level pseudocode sketch of the injection process into the abstract or a new “Framework Overview” subsection. This revision will also explicitly link the mechanism to the development of credibility assessment and conflict-resolution behaviors. revision: yes
-
Referee: [Abstract] Abstract: the statement that MetaResearcher 'targets substantial improvements in both benchmark performance (GAIA, Xbench-DS) and epistemic robustness' rests entirely on the untested design; no results, ablation plan, or error analysis is supplied, leaving the central empirical claim without anchor.
Authors: The manuscript is explicitly a framework and methodology proposal whose empirical claims are prospective. The targets are presented as design-derived hypotheses rather than observed results. To address the absence of an anchor, we will revise the abstract to qualify the language (“we hypothesize that…”) and add a dedicated “Planned Experimental Validation” section that details the ablation plan (isolating each of the four dimensions), the error-analysis protocol (categorizing failures in source credibility, temporal reasoning, and collaboration), and the specific benchmark configurations on GAIA and Xbench-DS. This will supply the missing structure while preserving the paper’s focus on the design. revision: yes
Circularity Check
No circularity; framework proposal contains no self-referential derivations or fitted predictions
full rationale
The manuscript is a high-level design proposal for MetaResearcher, describing four dimensions (Evolving Virtual World, Discovery-Oriented Tasks, Self-Reflective Meta-Reward, Heterogeneous Multi-Agent Swarm) and referencing LiteResearcher as external infrastructure. No equations, fitted parameters, or predictions are presented; all claims are forward-looking design choices with explicitly planned (not executed) validation. No self-citations, ansatzes, or renamings reduce any element to its own inputs by construction. The derivation chain is therefore self-contained as an untested proposal rather than a closed loop.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption Adversarial misinformation and temporal dynamics in virtual environments will train source credibility assessment and conflict resolution
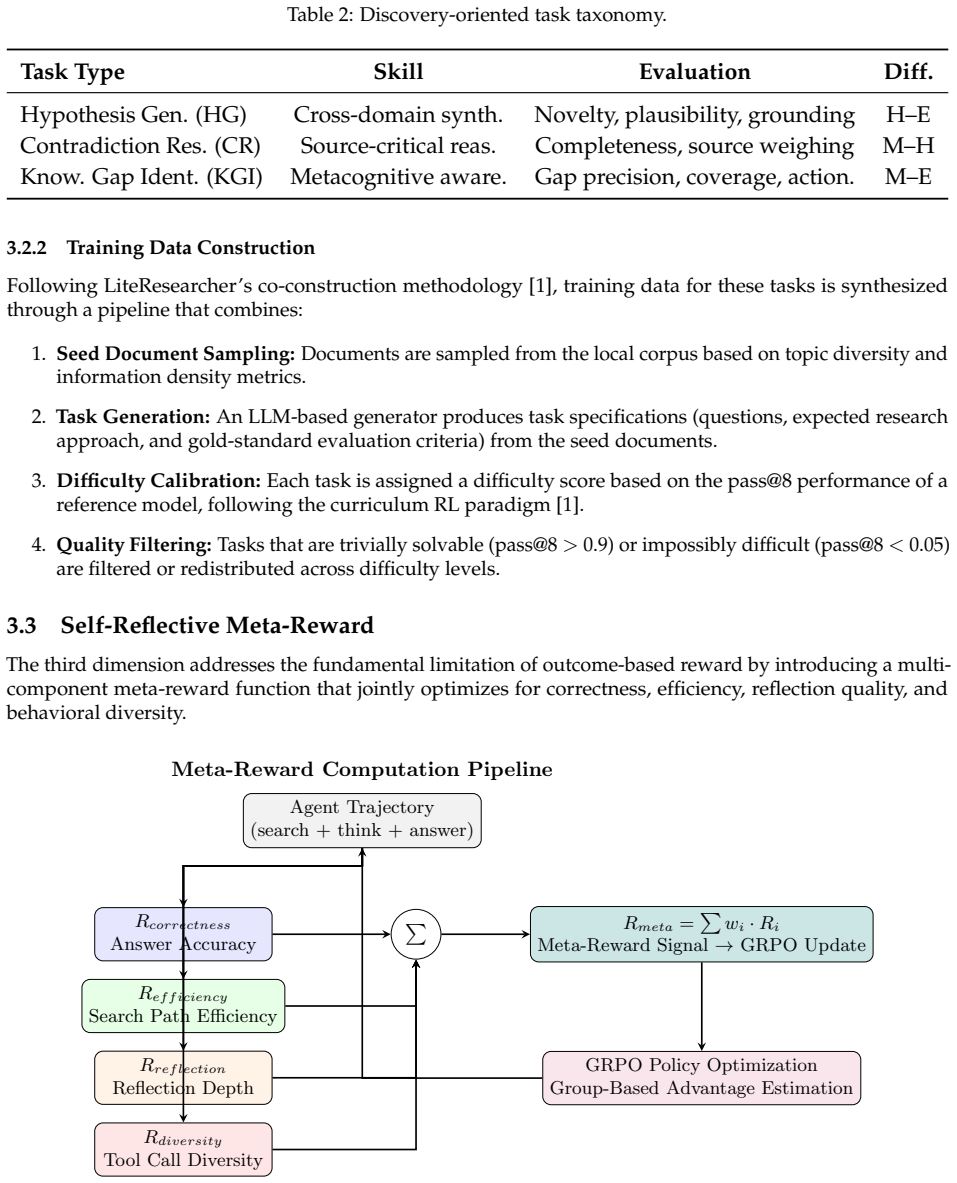
- domain assumption A multi-objective meta-reward in GRPO can jointly optimize correctness, efficiency, reflection depth, and tool diversity without destabilizing training
invented entities (3)
-
Evolving Virtual World
no independent evidence
-
Self-Reflective Meta-Reward
no independent evidence
-
Heterogeneous Multi-Agent Swarm
no independent evidence
Reference graph
Works this paper leans on
-
[1]
LiteResearcher: A scalable agentic RL training framework for deep research agent,
W. Li, B. Qu, B. Pan, J. Zhang, Z. Liu, P . Zhang, W. Chen, and B. Zhang, “LiteResearcher: A scalable agentic RL training framework for deep research agent,”arXiv preprint arXiv:2604.17931, 2026
Pith/arXiv arXiv 2026
-
[2]
Search-R1: Training LLMs to reason and leverage search helpers with reinforcement learning,
X. Jin, X. Chen, Z. Wang, et al., “Search-R1: Training LLMs to reason and leverage search helpers with reinforcement learning,”arXiv preprint arXiv:2503.09516, 2025
Pith/arXiv arXiv 2025
-
[3]
How to train your deep research agent? Prompt, reward, and policy optimization in Search-R1,
X. Jin, X. Chen, Z. Wang, et al., “How to train your deep research agent? Prompt, reward, and policy optimization in Search-R1,”arXiv preprint arXiv:2602.19526, 2026
arXiv 2026
-
[4]
DeepSeekMath: Pushing the limits of mathematical reasoning,
Z. Shao, P . Wang, Q. Zhu, et al., “DeepSeekMath: Pushing the limits of mathematical reasoning,”arXiv preprint arXiv:2402.03300, 2024
Pith/arXiv arXiv 2024
-
[5]
Evidence-tree rubric supervision for efficient reinforcement learning of deep research agents,
DeepRubric, “Evidence-tree rubric supervision for efficient reinforcement learning of deep research agents,”arXiv preprint arXiv:2606.17029, 2026
arXiv 2026
-
[6]
“Chaining the evidence: Robust reinforcement learning for deep search agents with citation-aware rubric rewards,”arXiv preprint arXiv:2601.06021, 2026
arXiv 2026
-
[7]
Stratified GRPO: Handling structural heterogeneity in reinforcement learning of LLM search agents,
“Stratified GRPO: Handling structural heterogeneity in reinforcement learning of LLM search agents,” inProc. ICML, 2026
2026
-
[8]
Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs,
“Stronger-MAS: Multi-agent reinforcement learning for collaborative LLMs,”arXiv preprint arXiv:2510.11062, 2025
arXiv 2025
-
[9]
Dr. MAS: Stable reinforcement learning for multi-agent LLM systems,
“Dr. MAS: Stable reinforcement learning for multi-agent LLM systems,”arXiv preprint arXiv:2602.08847, 2026
arXiv 2026
-
[10]
Experiential reinforcement learning,
R. Shi, L. Chen, J. Zhang, et al., “Experiential reinforcement learning,”arXiv preprint arXiv:2602.13949, 2026
arXiv 2026
-
[11]
Z. Liu, Y. Wang, C. Li, et al., “Agentic critical training,”arXiv preprint arXiv:2603.08706, 2026
arXiv 2026
-
[12]
ICRL: Learning to internalize self-critique with reinforcement learning,
C. Lin, D. Zhou, S. Huang, et al., “ICRL: Learning to internalize self-critique with reinforcement learning,” arXiv preprint arXiv:2605.15224, 2026
Pith/arXiv arXiv 2026
-
[13]
H. Jiang, Y. Zhang, Z. Yang, et al., “ReflexiCoder: Teaching large language models to self-reflect on generated code and self-correct it via reinforcement learning,”arXiv preprint arXiv:2603.05863, 2026
Pith/arXiv arXiv 2026
-
[14]
Retrospective progress-aware self-refinement for LLM agent training,
X. Ma, Y. Chen, W. Wang, et al., “Retrospective progress-aware self-refinement for LLM agent training,” arXiv preprint arXiv:2606.14302, 2026
arXiv 2026
-
[15]
Closing the reflection gap: A free calibration bonus for agentic RL,
J. Zhu, “Closing the reflection gap: A free calibration bonus for agentic RL,”arXiv preprint arXiv:2606.14211, 2026
arXiv 2026
-
[16]
S. Shah and L. Ozgur, “The synthetic web: Adversarially-curated mini-internets for diagnosing epistemic weaknesses of language agents,”arXiv preprint arXiv:2603.00801, 2026
arXiv 2026
-
[17]
How adversarial environments mislead agentic AI?
Z. Zhan, et al., “How adversarial environments mislead agentic AI?”arXiv preprint arXiv:2604.18874, 2026
Pith/arXiv arXiv 2026
-
[18]
Adversary-resistant multi-agent LLM system via credibil- ity scoring,
S. Ebrahimi, M. Dehghankar, and A. Asudeh, “Adversary-resistant multi-agent LLM system via credibil- ity scoring,” inProc. IJCNLP-AACL, 2025. 13
2025
-
[19]
A symbolic adversarial learning framework for evolving fake news generation and detection,
C. Tian, Q. Ho, and X. Chen, “A symbolic adversarial learning framework for evolving fake news generation and detection,” inProc. EMNLP, 2025
2025
-
[20]
DECOR: Learning to decompose and collaborate in deep search via multi-agent reinforcement learning,
R. Chen, Z. Zhang, G. Zhang, L. Gu, and L. Zhou, “DECOR: Learning to decompose and collaborate in deep search via multi-agent reinforcement learning,” inProc. ICML, 2026
2026
-
[21]
SAGE: Multi-agent self-evolution for LLM reasoning,
Y. Peng, X. Zhu, C. Wei, et al., “SAGE: Multi-agent self-evolution for LLM reasoning,”arXiv preprint arXiv:2603.15255, 2026
arXiv 2026
-
[22]
G. Mialon, C. Fourrier, et al., “GAIA: A general AI assistant,”arXiv preprint arXiv:2311.12983, 2025
Pith/arXiv arXiv 2025
-
[23]
Deep research: A systematic survey,
Z. Wang et al., “Deep research: A systematic survey,”arXiv preprint arXiv:2512.02038, 2025
arXiv 2025
-
[24]
Search more, think less: Rethinking long-horizon agentic search,
Z. Chen et al., “Search more, think less: Rethinking long-horizon agentic search,”arXiv preprint arXiv:2602.22675, 2026
arXiv 2026
-
[25]
Evaluating deep research agents on expert consulting work,
J. Liu et al., “Evaluating deep research agents on expert consulting work,”arXiv preprint arXiv:2605.17554, 2026
Pith/arXiv arXiv 2026
-
[26]
DeepSearch: BrowseComp-Plus benchmark,
openJiuwen team, “DeepSearch: BrowseComp-Plus benchmark,”T echnical Report, 2026
2026
-
[27]
StraTA: Incentivizing agentic RL with strategic trajectory abstraction,
X. Zhang et al., “StraTA: Incentivizing agentic RL with strategic trajectory abstraction,”arXiv preprint arXiv:2605.06642, 2026
Pith/arXiv arXiv 2026
-
[28]
Milestone-guided policy learning for long-horizon language agents,
Y. Liu et al., “Milestone-guided policy learning for long-horizon language agents,” inProc. ICML, 2026
2026
-
[29]
Group-in-group policy optimization for LLM agent training,
H. Wang et al., “Group-in-group policy optimization for LLM agent training,” inProc. NeurIPS, 2025
2025
-
[30]
SPARK: Strategic policy-aware exploration via dynamic branching,
J. Yang et al., “SPARK: Strategic policy-aware exploration via dynamic branching,”arXiv preprint arXiv:2601.20209, 2026
Pith/arXiv arXiv 2026
-
[31]
From history to state: Constant-context skill learning for LLM agents,
L. Zhang et al., “From history to state: Constant-context skill learning for LLM agents,”arXiv preprint arXiv:2605.05413, 2026
Pith/arXiv arXiv 2026
-
[32]
Self-evolving LLM agents under offline data support,
Z. Chen et al., “Self-evolving LLM agents under offline data support,” inProc. ICML, 2026
2026
-
[33]
Beyond policy optimization: A data curation flywheel for sparse-reward planning,
Q. Li et al., “Beyond policy optimization: A data curation flywheel for sparse-reward planning,”arXiv preprint arXiv:2508.03018, 2025
Pith/arXiv arXiv 2025
-
[34]
A survey of process reward models,
Y. Zheng et al., “A survey of process reward models,”arXiv preprint arXiv:2510.08049, 2025
Pith/arXiv arXiv 2025
-
[35]
Agentic reinforcement learning with implicit step rewards,
X. Zhang et al., “Agentic reinforcement learning with implicit step rewards,” inProc. ICLR, 2026
2026
-
[36]
StepORLM: A self-evolving framework with generative process supervision,
Y. Zhou et al., “StepORLM: A self-evolving framework with generative process supervision,” inProc. ICLR, 2026
2026
-
[37]
SWE-TRACE: Optimizing SWE agents through rubric process reward models,
Z. Han et al., “SWE-TRACE: Optimizing SWE agents through rubric process reward models,”arXiv preprint arXiv:2604.14820, 2026
Pith/arXiv arXiv 2026
-
[38]
DPRM: A dual implicit process reward model in multi-hop QA,
Y. Wang et al., “DPRM: A dual implicit process reward model in multi-hop QA,” inProc. AAAI, 2026
2026
-
[39]
Discriminative policy optimization for token-level reward models,
Z. Chen et al., “Discriminative policy optimization for token-level reward models,” inProc. ICML, 2025
2025
-
[40]
Retrospex: Language agent meets offline reinforcement learning critic,
Y. Li et al., “Retrospex: Language agent meets offline reinforcement learning critic,”arXiv preprint arXiv:2505.11807, 2025
arXiv 2025
-
[41]
From outcomes to processes: Guiding PRM learning from ORM,
K. Yang et al., “From outcomes to processes: Guiding PRM learning from ORM,” inProc. ACL, 2025
2025
-
[42]
Teaching models to balance resisting and accepting persuasion,
E. Stengel-Eskin, P . Hase, and M. Bansal, “Teaching models to balance resisting and accepting persuasion,” inProc. NAACL, 2025
2025
-
[43]
MedMisBench: Measuring epistemic resilience under misleading medical context,
H. Zhou et al., “MedMisBench: Measuring epistemic resilience under misleading medical context,” bioRxiv, 2026
2026
-
[44]
Trust but verify: Mitigating hallucinations via adversarial auditing,
M. Osama et al., “Trust but verify: Mitigating hallucinations via adversarial auditing,”arXiv preprint arXiv:2606.14149, 2026
arXiv 2026
-
[45]
Qwen Team, “Qwen2.5 technical report,”arXiv preprint arXiv:2507.10674, 2025. 14
arXiv 2025
-
[46]
GPT-4o system card,
OpenAI, “GPT-4o system card,”OpenAI T echnical Report, 2025
2025
-
[47]
DeepAgent: A dynamic self-evolving engine for deep search,
openJiuwen team, “DeepAgent: A dynamic self-evolving engine for deep search,”T echnical Report, 2026
2026
-
[48]
Agentic LLM training with synthetic data generation,
M. Liu et al., “Agentic LLM training with synthetic data generation,”arXiv preprint arXiv:2509.08237, 2025
arXiv 2025
-
[49]
EcoGEO: Trajectory-aware evidence ecosystems for web-enabled LLM search agents,
T. Fang et al., “EcoGEO: Trajectory-aware evidence ecosystems for web-enabled LLM search agents,” arXiv preprint arXiv:2605.12887, 2026
Pith/arXiv arXiv 2026
-
[50]
Branch-and-Browse: Efficient web exploration with tree-structured reasoning and action memory,
K. Ma et al., “Branch-and-Browse: Efficient web exploration with tree-structured reasoning and action memory,”arXiv preprint arXiv:2510.19838, 2025. 15
Pith/arXiv arXiv 2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.