Repository-Level Solidity Code Generation with Large Language Models: From Prompting to Fine-Tuning
Pith reviewed 2026-06-26 16:46 UTC · model grok-4.3
The pith
Supervised fine-tuning on Solidity data produces larger gains in repository-level smart contract generation than any prompting or retrieval method.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
General-purpose code models exhibit systematic structural deficiencies when asked to synthesize complete repository-level Solidity contracts; among non-parametric techniques retrieval-augmented generation performs best while in-context learning degrades past two examples; supervised fine-tuning delivers the largest improvement by embedding Solidity-specific constraints into the model parameters.
What carries the argument
SolidityBench benchmark paired with SolidityScore metric, which together measure how well generated contracts satisfy security modifiers, contract declarations, and Solidity keywords in full repository contexts.
If this is right
- Fine-tuned models satisfy Solidity constraints at inference time without external retrieval or lengthy prompts.
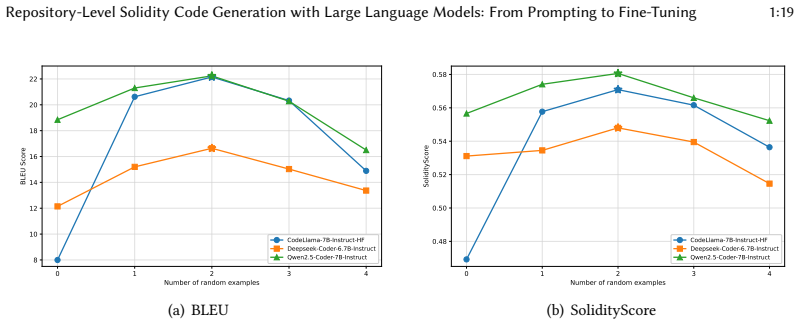
- Adding more than two in-context examples reduces generation quality because of context saturation in this domain.
- General code LLMs require domain-specific adaptation to avoid missing required modifiers and declarations in complete contracts.
Where Pith is reading between the lines
- The same supervised-fine-tuning pattern may transfer to other high-constraint languages such as those used in financial or safety-critical systems.
- A benchmark focused on single-contract generation leaves open the question of how well models handle multi-contract repository interactions and inheritance.
- If SolidityScore correlates with outcomes from professional audits, the metric could serve as an early filter before on-chain deployment.
Load-bearing premise
The 5,470 contracts in SolidityBench are representative of real repository-level Solidity tasks and SolidityScore captures the security, language, and engineering constraints that matter most.
What would settle it
Apply the same models and methods to a fresh collection of deployed mainnet Solidity contracts not present in the benchmark and check whether fine-tuned models still receive the highest SolidityScore.
Figures









read the original abstract
Large Language Models (LLMs) have shown strong capabilities in general-purpose code generation, but their effectiveness in specialized software domains remains underexplored. Solidity smart contracts represent a high-stakes domain where generated code must satisfy strict language-level, security, and software-engineering constraints. Existing benchmarks and metrics remain insufficient for repository-level Solidity generation, where models must synthesize complete contracts from natural language requirements. To address this gap, we introduce SolidityBench, a benchmark of 5,470 repository-level Solidity smart contracts paired with natural language descriptions. We also propose SolidityScore, a Solidity-aware semantic metric that emphasizes domain-critical constructs such as security modifiers, contract declarations, and Solidity-specific keywords. Using this benchmark, we evaluate representative code LLMs, including Qwen2.5-Coder, DeepSeek-Coder, and CodeLlama, across zero-shot prompting, Chain-of-Thought reasoning, in-context learning, retrieval-augmented generation, and supervised fine-tuning. The results show that general-purpose models exhibit systematic structural deficiencies in repository-level Solidity generation. Among non-parametric methods, retrieval-augmented generation performs best, while in-context learning degrades beyond two examples due to context saturation. Supervised fine-tuning achieves the largest improvement by internalizing Solidity-specific constraints into model parameters. Overall, our study provides a comprehensive benchmark for repository-level Solidity code generation and shows that high-quality domain data combined with supervised fine-tuning is the most effective strategy for improving the reliability of LLM-generated smart contracts.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces SolidityBench, a benchmark of 5,470 repository-level Solidity smart contracts paired with natural language descriptions, and SolidityScore, a domain-aware semantic metric emphasizing security modifiers, contract declarations, and Solidity-specific keywords. It evaluates representative code LLMs (Qwen2.5-Coder, DeepSeek-Coder, CodeLlama) across zero-shot, CoT, ICL, RAG, and supervised fine-tuning, reporting that RAG is strongest among non-parametric methods while SFT yields the largest gains by internalizing Solidity constraints.
Significance. If the benchmark construction and metric validation hold, the work supplies a needed large-scale resource for repository-level code generation in a high-stakes domain and supplies empirical evidence favoring supervised fine-tuning over prompting variants. The scale of the benchmark and the systematic method comparison are strengths that could inform domain-adaptation research.
major comments (3)
- [§3] §3 (Benchmark Construction): The description of SolidityBench provides no information on source repositories, filtering criteria, temporal splits, or leakage checks against the evaluated models. This directly affects the claim that the 5,470 contracts are representative of real repository-level tasks and that SFT internalizes genuine constraints rather than benchmark artifacts.
- [§4] §4 (SolidityScore): No correlation study, inter-annotator agreement, or comparison against static-analysis tools or human expert judgments on security/engineering correctness is reported. Without such validation, higher post-SFT scores cannot be confidently attributed to internalization of domain constraints as stated in the abstract and §6.
- [§5] §5 (Experimental Setup and Results): The paper omits details on train/validation/test splits for fine-tuning, statistical significance testing of the reported deltas, and contract-level validation procedures. These omissions are load-bearing for the central ranking of SFT over RAG and other methods.
minor comments (1)
- [Table 2] Table 2: Column headers for the metric components could explicitly note whether higher or lower values are better to avoid ambiguity in interpreting SolidityScore.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback, which identifies key areas for strengthening the manuscript's rigor and reproducibility. We will revise the paper to incorporate the requested details on benchmark construction, metric validation, and experimental procedures. Our point-by-point responses are below.
read point-by-point responses
-
Referee: [§3] §3 (Benchmark Construction): The description of SolidityBench provides no information on source repositories, filtering criteria, temporal splits, or leakage checks against the evaluated models. This directly affects the claim that the 5,470 contracts are representative of real repository-level tasks and that SFT internalizes genuine constraints rather than benchmark artifacts.
Authors: We agree these details are necessary to substantiate representativeness and rule out artifacts. In the revised manuscript we will expand §3 with: source repositories drawn from public GitHub Solidity projects meeting repository-level criteria; explicit filtering rules (minimum size, multi-contract interactions, exclusion of trivial or test-only code); temporal splits (pre-2023 contracts for training/fine-tuning, post-2023 for evaluation); and leakage checks performed by exact-string and semantic similarity searches against the pre-training data of Qwen2.5-Coder, DeepSeek-Coder, and CodeLlama. These additions will directly support the claim that SFT internalizes genuine Solidity constraints. revision: yes
-
Referee: [§4] §4 (SolidityScore): No correlation study, inter-annotator agreement, or comparison against static-analysis tools or human expert judgments on security/engineering correctness is reported. Without such validation, higher post-SFT scores cannot be confidently attributed to internalization of domain constraints as stated in the abstract and §6.
Authors: We acknowledge that empirical validation strengthens attribution of score gains to domain internalization. Although the original submission defined SolidityScore from domain expertise, the revision will add a validation subsection in §4 reporting: (i) correlation of SolidityScore with Slither-detected vulnerabilities on the full benchmark, (ii) agreement metrics from a pilot study with two Solidity experts on 150 sampled contracts, and (iii) comparison of score deltas against human correctness ratings. This will provide the requested evidence linking post-SFT improvements to constraint internalization. revision: yes
-
Referee: [§5] §5 (Experimental Setup and Results): The paper omits details on train/validation/test splits for fine-tuning, statistical significance testing of the reported deltas, and contract-level validation procedures. These omissions are load-bearing for the central ranking of SFT over RAG and other methods.
Authors: These omissions limit interpretability of the SFT ranking. The revised §5 will specify: the train/validation/test split ratios and construction method (including temporal separation), statistical significance testing (paired bootstrap confidence intervals and Wilcoxon tests on method deltas), and contract-level validation (compilation success, automated security checks, and manual review of a 200-contract sample). These additions will substantiate the reported superiority of supervised fine-tuning. revision: yes
Circularity Check
No circularity: purely empirical evaluation of prompting and fine-tuning methods on introduced benchmark
full rationale
The paper introduces SolidityBench (5,470 contracts) and SolidityScore, then reports empirical results across prompting variants and SFT. No equations, derivations, or 'predictions' are claimed; performance deltas are measured directly on the benchmark. No self-citation load-bearing uniqueness theorems, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear. The central claim (SFT internalizes constraints) is an interpretation of observed score improvements, not a reduction to inputs by construction. This matches the default non-circular case for benchmark papers.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Standard prompting and fine-tuning techniques developed for general code are appropriate starting points for Solidity without domain-specific validation.
invented entities (2)
-
SolidityBench
no independent evidence
-
SolidityScore
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Elvira Albert, Jesús Correas, Pablo Gordillo, Guillermo Román-Díez, and Albert Rubio. 2020. GASOL: Gas analysis and optimization for ethereum smart contracts. InTools and Algorithms for the Construction and Analysis of Systems - 26th International Conference, TACAS 2020, Held as Part of the European Joint Conferences on Theory and Practice of Software, ET...
-
[3]
Vivi Andersson, Sofia Bobadilla, Harald Hobbelhagen, and Martin Monperrus. 2025. PoCo: Agentic proof-of-concept exploit generation for smart contracts.CoRRabs/2511.02780 (2025). https://doi.org/10.48550/ARXIV.2511.02780 arXiv:2511.02780
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2511.02780 2025
-
[4]
Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J
Jacob Austin, Augustus Odena, Maxwell I. Nye, Maarten Bosma, Henryk Michalewski, David Dohan, Ellen Jiang, Carrie J. Cai, Michael Terry, Quoc V. Le, and Charles Sutton. 2021. Program Ssynthesis with large language models. CoRRabs/2108.07732 (2021). arXiv:2108.07732 https://arxiv.org/abs/2108.07732
Pith/arXiv arXiv 2021
-
[5]
C., Arun Iyer, Suresh Parthasarathy, Sriram K
Ramakrishna Bairi, Atharv Sonwane, Aditya Kanade, Vageesh D. C., Arun Iyer, Suresh Parthasarathy, Sriram K. Rajamani, Balasubramanyan Ashok, and Shashank Shet. 2024. CodePlan: Repository-level coding using LLMs and planning.Proc. ACM Softw. Eng.1, FSE (2024), 675–698. https://doi.org/10.1145/3643757
-
[6]
Tom B. Brown, Benjamin Mann, Nick Ryder, Melanie Subbiah, Jared Kaplan, Prafulla Dhariwal, Arvind Neelakantan, Pranav Shyam, Girish Sastry, Amanda Askell, Sandhini Agarwal, Ariel Herbert-Voss, Gretchen Krueger, Tom Henighan, Rewon Child, Aditya Ramesh, Daniel M. Ziegler, Jeffrey Wu, Clemens Winter, Christopher Hesse, Mark Chen, Eric Sigler, Mateusz Litwin...
2020
-
[7]
Vitalik Buterin et al. 2014. A next-generation smart contract and decentralized application platform.white paper3, 37 (2014), 2–1
2014
-
[8]
Stefanos Chaliasos, Arthur Gervais, and Benjamin Livshits. 2022. A study of inline assembly in solidity smart contracts. Proc. ACM Program. Lang.6, OOPSLA2 (2022), 1123–1149. https://doi.org/10.1145/3563328
-
[9]
Mark Chen, Jerry Tworek, Heewoo Jun, Qiming Yuan, Henrique Pondé de Oliveira Pinto, Jared Kaplan, Harri Edwards, Yuri Burda, Nicholas Joseph, Greg Brockman, Alex Ray, Raul Puri, Gretchen Krueger, Michael Petrov, Heidy Khlaaf, Girish Sastry, Pamela Mishkin, Brooke Chan, Scott Gray, Nick Ryder, Mikhail Pavlov, Alethea Power, Lukasz Kaiser, Mohammad Bavarian...
Pith/arXiv arXiv 2021
-
[10]
Yuxiao Chen, Jingzheng Wu, Xiang Ling, Changjiang Li, Zhiqing Rui, Tianyue Luo, and Yanjun Wu. 2024. When Large Language Models Confront Repository-Level Automatic Program Repair: How Well They Done?. InProceedings of the 2024 IEEE/ACM 46th International Conference on Software Engineering: Companion Proceedings, ICSE Companion 2024, Lisbon, Portugal, Apri...
-
[11]
Etienne Daspe, Mathis Durand, Julien Hatin, and Salma Bradai. 2024. Benchmarking Large Language Models for Ethereum Smart Contract Development. In6th Conference on Blockchain Research & Applications for Innovative Networks and Services , BRAINS 2024, Berlin, Germany, October 9-11, 2024. IEEE, 1–4. https://doi.org/10.1109/BRAINS63024.2024. 10732686
-
[12]
DeepSeek-AI, Qihao Zhu, Daya Guo, Zhihong Shao, Dejian Yang, Peiyi Wang, Runxin Xu, Y. Wu, Yukun Li, Huazuo Gao, Shirong Ma, Wangding Zeng, Xiao Bi, Zihui Gu, Hanwei Xu, Damai Dai, Kai Dong, Liyue Zhang, Yishi Piao, Zhibin Gou, Zhenda Xie, Zhewen Hao, Bingxuan Wang, Junxiao Song, Deli Chen, Xin Xie, Kang Guan, Yuxiang You, Aixin Liu, Qiushi Du, Wenjun Gao...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.11931 2024
-
[13]
Jesse Dodge, Gabriel Ilharco, Roy Schwartz, Ali Farhadi, Hannaneh Hajishirzi, and Noah A. Smith. 2020. Fine-Tuning Pretrained Language Models: Weight Initializations, Data Orders, and Early Stopping.CoRRabs/2002.06305 (2020). arXiv:2002.06305 https://arxiv.org/abs/2002.06305
arXiv 2020
-
[14]
Ferreira, Rui Abreu, and Pedro Cruz
Thomas Durieux, João F. Ferreira, Rui Abreu, and Pedro Cruz. 2020. Empirical review of automated analysis tools on 47, 587 Ethereum smart contracts. InICSE ’20: 42nd International Conference on Software Engineering, Seoul, South Korea, 27 June - 19 July, 2020. ACM, 530–541. https://doi.org/10.1145/3377811.3380364
-
[15]
Mikhail Evtikhiev, Egor Bogomolov, Yaroslav Sokolov, and Timofey Bryksin. 2023. Out of the BLEU: How should we assess quality of the Code Generation models?J. Syst. Softw.203 (2023), 111741. https://doi.org/10.1016/J.JSS.2023.111741 J. ACM, Vol. 37, No. 4, Article 1. Publication date: August 2018. 1:30 S. Chen et al
-
[16]
Josselin Feist, Gustavo Grieco, and Alex Groce. 2019. Slither: A static analysis framework for smart contracts. In Proceedings of the 2nd International Workshop on Emerging Trends in Software Engineering for Blockchain, WETSEB@ICSE 2019, Montreal, QC, Canada, May 27, 2019. IEEE / ACM, 8–15. https://doi.org/10.1109/WETSEB.2019.00008
-
[17]
Zhangyin Feng, Daya Guo, Duyu Tang, Nan Duan, Xiaocheng Feng, Ming Gong, Linjun Shou, Bing Qin, Ting Liu, Daxin Jiang, and Ming Zhou. 2020. CodeBERT: A Pre-Trained Model for Programming and Natural Languages. InFindings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16-20 November 2020 (Findings of ACL, Vol. EMNLP 2020). Assoc...
-
[18]
Zhipeng Gao, Lingxiao Jiang, Xin Xia, David Lo, and John Grundy. 2021. Checking smart contracts with structural code embedding.IEEE Trans. Software Eng.47, 12 (2021), 2874–2891. https://doi.org/10.1109/TSE.2020.2971482
-
[19]
Qian-wen Gou, Yunwei Dong, YuJiao Wu, and Qiao Ke. 2024. RRGcode: Deep hierarchical search-based code generation. Journal of Systems and Software211 (2024), 111982. https://doi.org/10.1016/J.JSS.2024.111982
-
[20]
Xiaodong Gu, Meng Chen, Yalan Lin, Yuhan Hu, Hongyu Zhang, Chengcheng Wan, Zhao Wei, Yong Xu, and Juhong Wang. 2025. On the effectiveness of large language models in domain-specific code generation.ACM Trans. Softw. Eng. Methodol.34, 3 (2025), 78:1–78:22. https://doi.org/10.1145/3697012
-
[21]
Rui He, Liang Zhang, Mengyao Lyu, Liangqing Lyu, and Changbin Xue. 2025. Using large language models for aerospace code generation: Methods, benchmarks, and potential values.Aerospace12, 6 (2025), 498
2025
-
[22]
Soneya Binta Hossain, Nan Jiang, Qiang Zhou, Xiaopeng Li, Wen-Hao Chiang, Yingjun Lyu, Hoan Anh Nguyen, and Omer Tripp. 2024. A Deep Dive into Large Language Models for Automated Bug Localization and Repair.Proc. ACM Softw. Eng.1, FSE (2024), 1471–1493. https://doi.org/10.1145/3660773
-
[23]
Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen
Edward J. Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. 2022. LoRA: Low-rank adaptation of large language models. InThe Tenth International Conference on Learning Representations, ICLR 2022, Virtual Event, April 25-29, 2022. OpenReview.net. https://openreview.net/forum?id=nZeVKeeFYf9
2022
-
[24]
Binyuan Hui, Jian Yang, Zeyu Cui, Jiaxi Yang, Dayiheng Liu, Lei Zhang, Tianyu Liu, Jiajun Zhang, Bowen Yu, Kai Dang, An Yang, Rui Men, Fei Huang, Xingzhang Ren, Xuancheng Ren, Jingren Zhou, and Junyang Lin. 2024. Qwen2.5-Coder Technical Report.CoRRabs/2409.12186 (2024). https://doi.org/10.48550/ARXIV.2409.12186 arXiv:2409.12186
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2409.12186 2024
-
[25]
Hamel Husain, Ho-Hsiang Wu, Tiferet Gazit, Miltiadis Allamanis, and Marc Brockschmidt. 2019. CodeSearchNet Challenge: Evaluating the State of Semantic Code Search.CoRRabs/1909.09436 (2019). arXiv:1909.09436 http: //arxiv.org/abs/1909.09436
Pith/arXiv arXiv 2019
-
[26]
Maliheh Izadi, Jonathan Katzy, Tim van Dam, Marc Otten, Razvan Mihai Popescu, and Arie van Deursen. 2024. Language models for code completion: A practical evaluation. InProceedings of the 46th IEEE/ACM International Conference on Software Engineering, ICSE 2024, Lisbon, Portugal, April 14-20, 2024. ACM, 79:1–79:13. https://doi.org/10.1145/3597503. 3639138
-
[27]
Juyong Jiang, Fan Wang, Jiasi Shen, Sungju Kim, and Sunghun Kim. 2025. A survey on large language models for code generation.ACM Trans. Softw. Eng. Methodol.(July 2025). https://doi.org/10.1145/3747588 Just Accepted
-
[28]
Xue Jiang, Yihong Dong, Lecheng Wang, Zheng Fang, Qiwei Shang, Ge Li, Zhi Jin, and Wenpin Jiao. 2024. Self-planning code generation with large language models.ACM Transactions on Software Engineering and Methodology33, 7 (2024), 182:1–182:30. https://doi.org/10.1145/3672456
-
[29]
Deokhyung Kang, Jeonghun Cho, Yejin Jeon, Sunbin Jang, Minsub Lee, Jawoon Cho, and Gary Geunbae Lee. 2025. Retrieval-Augmented Fine-Tuning With Preference Optimization For Visual Program Generation. InProceedings of the 63rd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2025, Vienna, Austria, July 27 - August...
2025
-
[30]
Nirmal Joshua Kapu and Mihit Sreejith. 2024. DemoCraft: Using in-context learning to improve code generation in large language models.CoRRabs/2411.00865 (2024). https://doi.org/10.48550/ARXIV.2411.00865 arXiv:2411.00865
-
[31]
Faizan Khan, Istvan David, Dániel Varró, and Shane McIntosh. 2023. Code cloning in smart contracts on the ethereum platform: An extended replication study.IEEE Trans. Software Eng.49, 4 (2023), 2006–2019. https://doi.org/10.1109/ TSE.2022.3207428
arXiv 2023
-
[32]
Ranim Khojah, Francisco Gomes de Oliveira Neto, Mazen Mohamad, and Philipp Leitner. 2025. The impact of prompt programming on function-level code generation.IEEE Transactions on Software Engineering51, 8 (2025), 2381–2395. https://doi.org/10.1109/TSE.2025.3587794
-
[33]
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen-tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. 2020. Retrieval-augmented generation for knowledge-intensive NLP tasks. InAdvances in Neural Information Processing Systems 33: Annual Conference on Neural Information...
2020
-
[34]
Jia Li, Ge Li, Yongmin Li, and Zhi Jin. 2025. Structured chain-of-thought prompting for code generation.ACM Transactions on Software Engineering and Methodology34, 2 (2025), 37:1–37:23. https://doi.org/10.1145/3690635 J. ACM, Vol. 37, No. 4, Article 1. Publication date: August 2018. Repository-Level Solidity Code Generation with Large Language Models: Fro...
-
[35]
Rongao Li, Jie Fu, Bo-Wen Zhang, Tao Huang, Zhihong Sun, Chen Lyu, Guang Liu, Zhi Jin, and Ge Li. 2023. TACO: Topics in algorithmic code generation dataset.CoRRabs/2312.14852 (2023). https://doi.org/10.48550/ARXIV.2312.14852 arXiv:2312.14852
-
[36]
Weijia Li, Yongjie Qian, Ke Gao, Haixin Chen, Xinyu Wang, Yuchen Tong, Ling Li, Yanjun Wu, and Chen Zhao. 2025. Coft: Making large language models better zero-shot learners for code generation. In33rd IEEE/ACM International Conference on Program Comprehension, ICPC@ICSE 2025, Ottawa, ON, Canada, April 27-28, 2025. IEEE, 489–499. https://doi.org/10.1109/IC...
-
[37]
Zongjie Li, Daoyuan Wu, Shuai Wang, and Zhendong Su. 2025. API-guided dataset synthesis to finetune large code models.Proc. ACM Program. Lang.9, OOPSLA1 (2025), 786–815. https://doi.org/10.1145/3720449
-
[38]
Zhou Liao, Shuwei Song, Hang Zhu, Xiapu Luo, Zheyuan He, Renkai Jiang, Ting Chen, Jiachi Chen, Tao Zhang, and Xiaosong Zhang. 2023. Large-scale empirical study of inline assembly on 7.6 million ethereum smart contracts.IEEE Trans. Software Eng.49, 2 (2023), 777–801. https://doi.org/10.1109/TSE.2022.3163614
-
[39]
Tianyang Liu, Canwen Xu, and Julian J. McAuley. 2024. RepoBench: Benchmarking repository-level code auto- completion systems. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=pPjZIOuQuF
2024
-
[40]
Ilya Loshchilov and Frank Hutter. 2017. SGDR: Stochastic Gradient Descent with Warm Restarts. In5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net. https://openreview.net/forum?id=Skq89Scxx
2017
-
[41]
Shuai Lu, Daya Guo, Shuo Ren, Junjie Huang, Alexey Svyatkovskiy, Ambrosio Blanco, Colin B. Clement, Dawn Drain, Daxin Jiang, Duyu Tang, Ge Li, Lidong Zhou, Linjun Shou, Long Zhou, Michele Tufano, Ming Gong, Ming Zhou, Nan Duan, Neel Sundaresan, Shao Kun Deng, Shengyu Fu, and Shujie Liu. 2021. CodeXGLUE: A Machine Learning Benchmark Dataset for Code Unders...
2021
-
[42]
Marcos Macedo, Yuan Tian, Pengyu Nie, Filipe Roseiro Côgo, and Bram Adams. 2025. INTERTRANS: Lever- aging Transitive Intermediate Translations to Enhance LLM-Based Code Translation. In47th IEEE/ACM Interna- tional Conference on Software Engineering, ICSE 2025, Ottawa, ON, Canada, April 26 - May 6, 2025. IEEE, 1153–1164. https://doi.org/10.1109/ICSE55347.2...
-
[43]
James Miller. 2008. Triangulation as a basis for knowledge discovery in software engineering.Empir. Softw. Eng.13, 2 (2008), 223–228. https://doi.org/10.1007/S10664-008-9063-Y
-
[44]
Sewon Min, Mike Lewis, Luke Zettlemoyer, and Hannaneh Hajishirzi. 2022. MetaICL: Learning to learn in context. InProceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, NAACL 2022, Seattle, W A, United States, July 10-15, 2022. Association for Computational Linguistics...
-
[45]
Marius Mosbach, Maksym Andriushchenko, and Dietrich Klakow. 2021. On the Stability of Fine-tuning BERT: Misconceptions, Explanations, and Strong Baselines. In9th International Conference on Learning Representations, ICLR 2021, Virtual Event, Austria, May 3-7, 2021. OpenReview.net. https://openreview.net/forum?id=nzpLWnVAyah
2021
-
[46]
Satoshi Nakamoto, Bit Bit, et al. 2007. Bitcoin: A peer-to-peer electronic cash system.2008(2007)
2007
-
[47]
OpenAI. 2023. GPT-4 Technical Report.CoRRabs/2303.08774 (2023). https://doi.org/10.48550/ARXIV.2303.08774 arXiv:2303.08774
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2303.08774 2023
-
[48]
Kishore Papineni, Salim Roukos, Todd Ward, and Wei-Jing Zhu. 2002. BlEU: A method for automatic evaluation of machine translation. InProceedings of the 40th Annual Meeting of the Association for Computational Linguistics, July 6-12, 2002, Philadelphia, PA, USA. ACL, 311–318. https://doi.org/10.3115/1073083.1073135
-
[49]
Arkil Patel, Siva Reddy, Dzmitry Bahdanau, and Pradeep Dasigi. 2024. Evaluating In-Context Learning of Libraries for Code Generation. InProceedings of the 2024 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (Volume 1: Long Papers), NAACL 2024, Mexico City, Mexico, June 16-21, 2024. As...
-
[50]
Zhiyuan Peng, Xin Yin, Rui Qian, Peiqin Lin, Yongkang Liu, Chenhao Ying, and Yuan Luo. 2025. SolEval: Benchmarking Large Language Models for Repository-level Solidity Code Generation.CoRRabs/2502.18793 (2025). https://doi.org/ 10.48550/ARXIV.2502.18793 arXiv:2502.18793
-
[51]
Lutz Prechelt. 1996. InNeural Networks: Tricks of the Trade. Lecture Notes in Computer Science, Vol. 1524. Springer, 55–69. https://doi.org/10.1007/3-540-49430-8_3
-
[52]
Musfiqur Rahman, SayedHassan Khatoonabadi, and Emad Shihab. 2025. Beyond Synthetic Benchmarks: Evaluating LLM Performance on Real-World Class-Level Code Generation.CoRRabs/2510.26130 (2025). https://doi.org/10.48550/ ARXIV.2510.26130 arXiv:2510.26130
arXiv 2025
-
[53]
Shuo Ren, Daya Guo, Shuai Lu, Long Zhou, Shujie Liu, Duyu Tang, Neel Sundaresan, Ming Zhou, Ambrosio Blanco, and Shuai Ma. 2020. CodeBLEU: A method for automatic evaluation of code synthesis.CoRRabs/2009.10297 (2020). J. ACM, Vol. 37, No. 4, Article 1. Publication date: August 2018. 1:32 S. Chen et al. arXiv:2009.10297 https://arxiv.org/abs/2009.10297
Pith/arXiv arXiv 2020
-
[54]
Stephen E. Robertson and Hugo Zaragoza. 2009. The Probabilistic Relevance Framework: BM25 and Beyond.Found. Trends Inf. Retr.3, 4 (2009), 333–389. https://doi.org/10.1561/1500000019
-
[55]
Baptiste Rozière, Jonas Gehring, Fabian Gloeckle, Sten Sootla, Itai Gat, Xiaoqing Ellen Tan, Yossi Adi, Jingyu Liu, Tal Remez, Jérémy Rapin, Artyom Kozhevnikov, Ivan Evtimov, Joanna Bitton, Manish Bhatt, Cristian Canton-Ferrer, Aaron Grattafiori, Wenhan Xiong, Alexandre Défossez, Jade Copet, Faisal Azhar, Hugo Touvron, Louis Martin, Nicolas Usunier, Thoma...
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2308.12950 2023
-
[56]
Chaochen Shi, Yong Xiang, Jiangshan Yu, Keshav Sood, and Longxiang Gao. 2023. Machine translation-based fine- grained comments generation for solidity smart contracts.Inf. Softw. Technol.153 (2023), 107065. https://doi.org/10. 1016/J.INFSOF.2022.107065
arXiv 2023
-
[57]
Zhengxiang Shi and Aldo Lipani. 2023. Don’t stop pretraining? Make prompt-based fine-tuning powerful learner. In Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. http://papers.nips.cc/paper_files/paper/2023/hash/ 1289f9195d2ef8...
2023
-
[58]
Miklós Sipos and Sándor Szénási. 2025. Optimal gas consumption in ethereum smart contracts: A targeted review of empirical results, design patterns and formal methods. InIEEE 25th International Symposium on Computational Intelligence and Informatics (CINTI 2025). https://doi.org/10.1109/CINTI67731.2025.11311839
-
[59]
Qiyang Song, Heqing Huang, Xiaoqi Jia, Yuanbo Xie, and Jiahao Cao. 2025. Silence false alarms: Identifying anti- reentrancy patterns on ethereum to refine smart contract reentrancy detection. In32nd Annual Network and Dis- tributed System Security Symposium, NDSS 2025, San Diego, California, USA, February 24-28, 2025. The Internet Soci- ety. https://www.n...
2025
-
[60]
Florian Tambon, Amin Nikanjam, Cyrine Zid, Foutse Khomh, and Giuliano Antoniol. 2025. TaskEval: Assessing difficulty of code generation tasks for large language models.ACM Trans. Softw. Eng. Methodol.(Oct. 2025). https: //doi.org/10.1145/3773285 Just Accepted
-
[61]
Shailja Thakur, Baleegh Ahmad, Hammond Pearce, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri, and Siddharth Garg. 2024. VeriGen: A large language model for verilog code generation.ACM Trans. Design Autom. Electr. Syst.29, 3 (2024), 46:1–46:31. https://doi.org/10.1145/3643681
-
[62]
Pedro Vale and Fernando Pereira. 2023. Automatic Python code generation for Embedded/Cyber-Physical Systems. In 2023 7th International Young Engineers Forum (YEF-ECE). 49–55. https://doi.org/10.1109/YEF-ECE58420.2023.10209340
-
[63]
Saurous, and Yoon Kim
Bailin Wang, Zi Wang, Xuezhi Wang, Yuan Cao, Rif A. Saurous, and Yoon Kim. 2023. Grammar Prompting for Domain- Specific Language Generation with Large Language Models. InAdvances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023. http://p...
2023
-
[64]
Yilin Wang, Xiangping Chen, Yuan Huang, Hao-Nan Zhu, Jing Bian, and Zibin Zheng. 2023. An empirical study on real bug fixes from solidity smart contract projects.J. Syst. Softw.204 (2023), 111787. https://doi.org/10.1016/J.JSS.2023. 111787
-
[65]
Smith, Daniel Khashabi, and Hannaneh Hajishirzi
Yizhong Wang, Yeganeh Kordi, Swaroop Mishra, Alisa Liu, Noah A. Smith, Daniel Khashabi, and Hannaneh Hajishirzi
-
[66]
InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14,
Self-Instruct: Aligning Language Models with Self-Generated Instructions. InProceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, Canada, July 9-14,
2023
-
[67]
https://doi.org/10.18653/V1/2023.ACL-LONG.754
Association for Computational Linguistics, 13484–13508. https://doi.org/10.18653/V1/2023.ACL-LONG.754
-
[68]
Chi, Quoc V
Jason Wei, Xuezhi Wang, Dale Schuurmans, Maarten Bosma, Brian Ichter, Fei Xia, Ed H. Chi, Quoc V. Le, and Denny Zhou. 2022. Chain-of-thought prompting elicits reasoning in large language models. InAdvances in Neu- ral Information Processing Systems 35: Annual Conference on Neural Information Processing Systems 2022, NeurIPS 2022, New Orleans, LA, USA, Nov...
2022
-
[69]
Yuxiang Wei, Zhe Wang, Jiawei Liu, Yifeng Ding, and Lingming Zhang. 2023. Magicoder: Source Code Is All You Need. CoRRabs/2312.02120 (2023). https://doi.org/10.48550/ARXIV.2312.02120 arXiv:2312.02120
-
[70]
Sam Werner, Daniel Perez, Lewis Gudgeon, Ariah Klages-Mundt, Dominik Harz, and William J. Knottenbelt. 2022. SoK: Decentralized Finance (DeFi). InProceedings of the 4th ACM Conference on Advances in Financial Technologies, AFT 2022, Cambridge, MA, USA, September 19-21, 2022. ACM, 30–46. https://doi.org/10.1145/3558535.3559780
-
[71]
Martin Weyssow, Xin Zhou, Kisub Kim, David Lo, and Houari A. Sahraoui. 2025. Exploring parameter-efficient fine-tuning techniques for code generation with large language models.ACM Trans. Softw. Eng. Methodol.34, 7 (2025), 204:1–204:25. https://doi.org/10.1145/3714461 J. ACM, Vol. 37, No. 4, Article 1. Publication date: August 2018. Repository-Level Solid...
-
[72]
Yuhui Xu, Lingxi Xie, Xiaotao Gu, Xin Chen, Heng Chang, Hengheng Zhang, Zhengsu Chen, Xiaopeng Zhang, and Qi Tian. 2024. QA-LoRA: Quantization-aware low-rank adaptation of large language models. InThe Twelfth International Conference on Learning Representations, ICLR 2024, Vienna, Austria, May 7-11, 2024. OpenReview.net. https://openreview.net/forum?id=WvFoJccpo8
2024
-
[73]
Guang Yang, Yu Zhou, Xiang Chen, Xiangyu Zhang, Terry Yue Zhuo, and Taolue Chen. 2024. Chain-of-thought in neural code generation: From and for lightweight language models.IEEE Transactions on Software Engineering50, 9 (2024), 2437–2457. https://doi.org/10.1109/TSE.2024.3440503
-
[75]
Zezhou Yang, Sirong Chen, Cuiyun Gao, Zhenhao Li, Xing Hu, Kui Liu, and Xin Xia. 2025. An empirical study of retrieval-augmented code generation: Challenges and opportunities.ACM Trans. Softw. Eng. Methodol.34, 7 (2025), 188:1–188:28. https://doi.org/10.1145/3717061
-
[76]
Zhen Yang, Jacky Wai Keung, Zeyu Sun, Yunfei Zhao, Ge Li, Zhi Jin, Shuo Liu, and Yishu Li. 2024. Improving domain-specific neural code generation with few-shot meta-learning.Inf. Softw. Technol.166 (2024), 107365. https: //doi.org/10.1016/J.INFSOF.2023.107365
-
[77]
Xin Yin, Chao Ni, Shaohua Wang, Zhenhao Li, Limin Zeng, and Xiaohu Yang. 2024. ThinkRepair: Self-Directed Automated Program Repair. InProceedings of the 33rd ACM SIGSOFT International Symposium on Software Testing and Analysis, ISSTA 2024, Vienna, Austria, September 16-20, 2024. ACM, 1274–1286. https://doi.org/10.1145/3650212.3680359
-
[78]
Zhaojian Yu, Yilun Zhao, Arman Cohan, and Xiaoping Zhang. 2025. HumanEval Pro and MBPP Pro: Evaluating Large Language Models on Self-invoking Code Generation Task. InFindings of the Association for Computational Linguistics, ACL 2025, Vienna, Austria, July 27 - August 1, 2025. Association for Computational Linguistics, 13253–13279. https://aclanthology.or...
2025
-
[79]
Jianqing Zhang, Wei Xia, Hande Dong, Qiang Lin, and Jian Cao. 2025. AP2O: Correcting LLM-generated code errors type by type like humans via adaptive progressive preference optimization.CoRRabs/2510.02393 (2025). https://doi.org/10.48550/ARXIV.2510.02393 arXiv:2510.02393
-
[80]
Sheng Zhang, Yifan Ding, Shuquan Lian, Shun Song, and Hui Li. 2025. CodeRAG: Finding relevant and necessary knowledge for retrieval-augmented repository-level code completion.CoRRabs/2509.16112 (2025). https://doi.org/10. 48550/ARXIV.2509.16112 arXiv:2509.16112
arXiv 2025
-
[81]
Shudan Zhang, Hanlin Zhao, Xiao Liu, Qinkai Zheng, Zehan Qi, Xiaotao Gu, Yuxiao Dong, and Jie Tang. 2024. NaturalCodeBench: Examining Coding Performance Mismatch on HumanEval and Natural User Queries. InFindings of the Association for Computational Linguistics, ACL 2024, Bangkok, Thailand and virtual meeting, August 11-16, 2024. Association for Computatio...
-
[82]
Jiawei Zhao, Zhenyu Zhang, Beidi Chen, Zhangyang Wang, Anima Anandkumar, and Yuandong Tian. 2024. GaLore: Memory-Efficient LLM Training by Gradient Low-Rank Projection. InForty-first International Conference on Machine Learning, ICML 2024, Vienna, Austria, July 21-27, 2024. OpenReview.net. https://openreview.net/forum?id=hYHsrKDiX7
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.