MirrorDuo: Reflection-Consistent Visuomotor Learning from Mirrored Demonstration Pairs
Pith reviewed 2026-06-26 17:27 UTC · model grok-4.3
The pith
MirrorDuo generates a mirrored demonstration for every original one, doubling effective data for reflection-symmetric robot tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
MirrorDuo formulates visuomotor learning on mirrored demonstration pairs so that the policy respects reflection consistency, thereby improving sample efficiency and enabling cross-side transfer whenever the workspace admits a clean reflection symmetry.
What carries the argument
The reflection mapping that converts an original image-proprioception-6-DoF-action tuple into a valid mirrored counterpart lying on the same task manifold.
If this is right
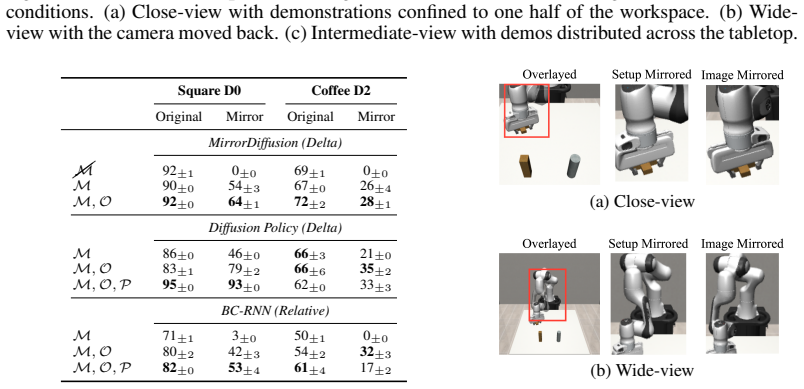
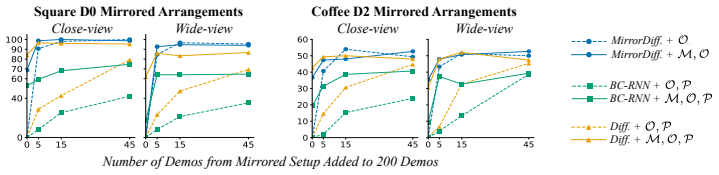
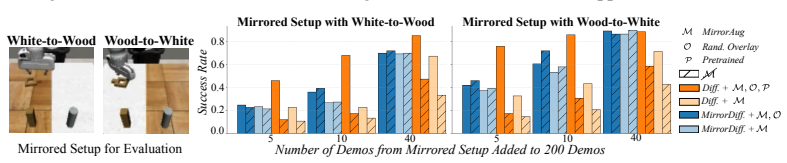
- Performance improves significantly under the same data budget when demonstrations are evenly distributed across both sides of the workspace.
- Skill transfer to the mirrored workspace is possible with as few as zero or five demonstrations collected in the target arrangement.
- MirrorDuo can be inserted as data augmentation into standard behavior cloning or diffusion policy training.
- The same pairs can be used as a structural prior inside reflection-equivariant policy networks.
Where Pith is reading between the lines
- The same symmetry exploitation could be tested on tasks whose dominant symmetry is rotational rather than reflectional.
- Combining MirrorDuo with other geometric augmentations might further lower the number of real-world demonstrations needed in partially symmetric environments.
- Measuring the drop in performance when the reflection assumption is deliberately violated would quantify the method's robustness boundary.
Load-bearing premise
The workspace and task admit a clean reflection symmetry such that mirroring images, proprioception, and actions produces valid, collision-free demonstrations.
What would settle it
Observing that mirrored actions produce collisions or task failures on a physical robot whose workspace lacks exact reflection symmetry would falsify the central assumption.
Figures









read the original abstract
Image-based behaviour cloning leverages demonstrations captured from ubiquitous RGB cameras. However, it remains constrained by the cost of collecting diverse demos, especially for generalizing across workspace variations. We propose MirrorDuo, a reflection-based formulation that operates on image, proprioception, and full 6-DoF end-effector action tuples, generating a mirrored counterpart for each original demonstration, effectively achieving "collect one, get one for free". It can be applied as a data augmentation strategy for existing learning pipelines, such as standard behaviour cloning or diffusion policy, or as a structural prior for reflection-equivariant policy networks. By leveraging the overlap between the original and mirrored domains, MirrorDuo achieves significantly improved performance under the same data budget when demonstrations are evenly distributed across both sides of the workspace. When demonstrations are confined to one side, MirrorDuo enables efficient skill transfer to the mirrored workspace with as few as zero or five demos in the target arrangement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces MirrorDuo, a reflection-based method that generates a mirrored counterpart for each original demonstration consisting of image, proprioception, and 6-DoF end-effector action tuples. It can be used either as data augmentation for standard behavior cloning or diffusion policies, or as a structural prior to enforce reflection-equivariance in policy networks. The central claims are that this yields significantly better performance under fixed data budgets when demonstrations are distributed across workspace sides, and enables skill transfer to the mirrored workspace with as few as zero or five target-side demonstrations.
Significance. If the reflection symmetry holds without introducing invalid trajectories, the method provides a simple, parameter-free way to effectively double demonstration data for symmetric tasks, directly addressing the high cost of collecting diverse visuomotor demonstrations. The dual use as augmentation and equivariant prior is a practical strength.
major comments (2)
- [§3.2] §3.2 (Mirroring Formulation): The procedure for mirroring 6-DoF end-effector poses and actions is presented as producing valid demonstrations on the same task manifold, but no derivation or explicit transformation rules are given for rotations under reflection, nor is there analysis of when this mapping preserves collision-free paths or kinematic feasibility.
- [§5] §5 (Experiments): Results claim performance gains and transfer with 0-5 target demos, but the evaluation does not include controlled tests on environments with partial symmetry violations (e.g., asymmetric fixtures or obstacles), which directly tests the load-bearing assumption that mirrored trajectories remain on-manifold.
minor comments (2)
- The abstract states performance improvements but the main text should include explicit baseline comparisons and error bars in all reported tables for the distributed-data and transfer settings.
- Notation for the reflection operator on images vs. actions could be unified for clarity in the method section.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. We address the two major comments point by point below and outline the revisions we will make.
read point-by-point responses
-
Referee: [§3.2] §3.2 (Mirroring Formulation): The procedure for mirroring 6-DoF end-effector poses and actions is presented as producing valid demonstrations on the same task manifold, but no derivation or explicit transformation rules are given for rotations under reflection, nor is there analysis of when this mapping preserves collision-free paths or kinematic feasibility.
Authors: We agree that the current presentation in §3.2 would benefit from greater formality. In the revised manuscript we will insert an explicit derivation of the reflection operator on SE(3), specifying the action on translation (sign flip on the appropriate axis) and on rotation (conjugation by the reflection matrix, or equivalently negating the appropriate quaternion components while preserving the rotation sense). We will also add a short paragraph discussing the kinematic and collision-free conditions under which the mirrored trajectory remains on-manifold, namely that the original demonstration must itself be collision-free and that the workspace symmetry (no asymmetric fixtures) is respected. revision: yes
-
Referee: [§5] §5 (Experiments): Results claim performance gains and transfer with 0-5 target demos, but the evaluation does not include controlled tests on environments with partial symmetry violations (e.g., asymmetric fixtures or obstacles), which directly tests the load-bearing assumption that mirrored trajectories remain on-manifold.
Authors: The referee correctly notes that our experiments assume full reflection symmetry. We will add a dedicated limitations paragraph in §5 (and a corresponding sentence in the conclusion) that explicitly states the method’s reliance on workspace symmetry and describes the expected degradation when asymmetric obstacles or fixtures are present. Because constructing and collecting data for controlled partial-symmetry environments would require an entirely new experimental campaign outside the scope of the present study, we do not plan to add such experiments; the added discussion will instead clarify the boundary conditions under which MirrorDuo is guaranteed to produce valid demonstrations. revision: partial
Circularity Check
No circularity: method is a data-augmentation prior with empirical validation
full rationale
The paper introduces MirrorDuo as a reflection-based augmentation that generates mirrored (image, proprioception, 6-DoF action) tuples from original demonstrations. No derivation chain, fitted parameters, or predictions are presented that reduce to the inputs by construction. Performance improvements are reported via experiments under fixed data budgets; the symmetry assumption is stated explicitly as a precondition rather than derived. No self-citation load-bearing steps or ansatz smuggling appear in the provided text. This is a standard engineering contribution whose central claims remain independent of its own outputs.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
J. Gao, A. Xie, T. Xiao, C. Finn, and D. Sadigh. Efficient data collection for robotic manipula- tion via compositional generalization. InProceedings of Robotics: Science and Systems (RSS), 2024
2024
- [2]
-
[3]
Eisner, Y
B. Eisner, Y . Yang, T. Davchev, M. Vecerik, J. Scholz, and D. Held. Deep se (3)-equivariant geometric reasoning for precise placement tasks. InThe Twelfth International Conference on Learning Representations, 2024
2024
-
[4]
Ryu, H.-i
H. Ryu, H.-i. Lee, J.-H. Lee, and J. Choi. Equivariant descriptor fields: Se (3)-equivariant energy-based models for end-to-end visual robotic manipulation learning. InThe Eleventh International Conference on Learning Representations, 2023
2023
-
[5]
J. Yang, Z. Cao, C. Deng, R. Antonova, S. Song, and J. Bohg. Equibot: Sim (3)-equivariant diffusion policy for generalizable and data efficient learning. In8th Annual Conference on Robot Learning, 2024
2024
-
[6]
D. Wang, R. Walters, and R. Platt.SO(2)-equivariant reinforcement learning. InInternational Conference on Learning Representations, 2022
2022
-
[7]
D. Wang, S. Hart, D. Surovik, T. Kelestemur, H. Huang, H. Zhao, M. Yeatman, J. Wang, R. Walters, and R. Platt. Equivariant diffusion policy. In8th Annual Conference on Robot Learning, 2024
2024
-
[8]
M. Jia, D. Wang, G. Su, D. Klee, X. Zhu, R. Walters, and R. Platt. Seil: Simulation-augmented equivariant imitation learning. In2023 IEEE International Conference on Robotics and Au- tomation (ICRA), pages 1845–1851. IEEE, 2023
2023
-
[9]
D. Wang, J. Y . Park, N. Sortur, L. L. Wong, R. Walters, and R. Platt. The surprising effective- ness of equivariant models in domains with latent symmetry. InInternational Conference on Learning Representations. International Conference on Learning Representations, 2023
2023
-
[10]
D. A. Pomerleau. Alvinn: An autonomous land vehicle in a neural network. InConference on Advances in Neural Information Processing Systems (NeurIPS), 1988
1988
-
[11]
Rahmatizadeh, P
R. Rahmatizadeh, P. Abolghasemi, L. B ¨ol¨oni, and S. Levine. Vision-based multi-task manip- ulation for inexpensive robots using end-to-end learning from demonstration.International Conference on Robotics and Automation (ICRA), 2018
2018
-
[12]
Mandlekar, D
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın. What matters in learning from offline human demonstrations for robot manipulation. InConference on Robot Learning (CoRL), 2021
2021
-
[13]
Florence, C
P. Florence, C. Lynch, A. Zeng, O. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mor- datch, and J. Tompson. Implicit behavioral cloning.Conference on Robot Learning (CoRL), 2021
2021
-
[14]
C. Chi, S. Feng, Y . Du, Z. Xu, E. Cousineau, B. Burchfiel, and S. Song. Diffusion policy: Visuomotor policy learning via action diffusion. InRobotics: Science and Systems (RSS), 2023. 11
2023
-
[15]
Consistency policy: Accelerated visuomotor policies via consistency distillation,
A. Prasad, K. Lin, J. Wu, L. Zhou, and J. Bohg. Consistency policy: Accelerated visuomotor policies via consistency distillation.arXiv preprint arXiv:2405.07503, 2024
-
[16]
Y . Ze, G. Zhang, K. Zhang, C. Hu, M. Wang, and H. Xu. 3d diffusion policy: Generalizable visuomotor policy learning via simple 3d representations.Robotics: Science and Systems, 2024
2024
-
[17]
Mandlekar, S
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox. Mimicgen: A data generation system for scalable robot learning using human demonstrations. InConference on Robot Learning (CoRL), 2023
2023
-
[18]
Hoque, A
R. Hoque, A. Mandlekar, C. Garrett, K. Goldberg, and D. Fox. Intervengen: Interventional data generation for robust and data-efficient robot imitation learning. In2024 IEEE/RSJ In- ternational Conference on Intelligent Robots and Systems (IROS), pages 2840–2846. IEEE, 2024
2024
-
[19]
C. Garrett, A. Mandlekar, B. Wen, and D. Fox. Skillmimicgen: Automated demonstration generation for efficient skill learning and deployment.arXiv preprint arXiv:2410.18907, 2024
-
[20]
Dexmimicgen: Automated data generation for biman- ual dexterous manipulation via imitation learning,
Z. Jiang, Y . Xie, K. Lin, Z. Xu, W. Wan, A. Mandlekar, L. Fan, and Y . Zhu. Dexmimicgen: Automated data generation for bimanual dexterous manipulation via imitation learning.arXiv preprint arXiv:2410.24185, 2024
-
[21]
Hoogeboom, V
E. Hoogeboom, V . G. Satorras, C. Vignac, and M. Welling. Equivariant diffusion for molecule generation in 3d. InInternational conference on machine learning, pages 8867–8887. PMLR, 2022
2022
-
[22]
Y . Zhou, C. Barnes, J. Lu, J. Yang, and H. Li. On the continuity of rotation representations in neural networks. 2019 ieee. InCVF Conference on Computer Vision and Pattern Recognition (CVPR), volume 3, 2018
2019
-
[23]
G. Cesa, L. Lang, and M. Weiler. A program to build e (n)-equivariant steerable cnns. In International conference on learning representations, 2022
2022
-
[24]
J. Ho, A. Jain, and P. Abbeel. Denoising diffusion probabilistic models.Conference on Neural Information Processing Systems (NeurIPS), 2020
2020
-
[25]
T. Ren, S. Liu, A. Zeng, J. Lin, K. Li, H. Cao, J. Chen, X. Huang, Y . Chen, F. Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[26]
K. He, X. Zhang, S. Ren, and J. Sun. Deep residual learning for image recognition. InPro- ceedings of the IEEE conference on computer vision and pattern recognition, pages 770–778, 2016
2016
-
[27]
J. Deng, W. Dong, R. Socher, L.-J. Li, K. Li, and L. Fei-Fei. Imagenet: A large-scale hierar- chical image database. InConference on Computer Vision and Pattern Recognition (CVPR), 2009
2009
-
[28]
Burns, Z
K. Burns, Z. Witzel, J. I. Hamid, T. Yu, C. Finn, and K. Hausman. What makes pre-trained visual representations successful for robust manipulation? In8th Annual Conference on Robot Learning, 2024
2024
-
[29]
Hansen and X
N. Hansen and X. Wang. Generalization in reinforcement learning by soft data augmentation. In2021 IEEE International Conference on Robotics and Automation (ICRA), pages 13611– 13617. IEEE, 2021
2021
-
[30]
Zhuang, R
Z. Zhuang, R. Wang, N. Ingelhag, V . Kyrki, and D. Kragic. Enhancing visual domain robust- ness in behaviour cloning via saliency-guided augmentation. In8th Annual Conference on Robot Learning, 2024. 12
2024
-
[31]
bm9A7SfqLlZigWYdavpxjAUKIig=
M. C. Welle, N. Ingelhag, M. Lippi, M. Wozniak, A. Gasparri, and D. Kragic. Quest2ros: An app to facilitate teleoperating robots. In7th International Workshop on Virtual, Augmented, and Mixed-Reality for Human-Robot Interactions, 2024. 13 AFormulation Derivations Eye-in-hand Local-frame Reparameterization For an eye-in-hand camera setup, let the current c...
2024
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.