WeGenBench: A Multidimensional Diagnostic Benchmark towards Text-to-Image Model Optimization
Pith reviewed 2026-06-26 17:52 UTC · model grok-4.3
The pith
WeGenBench uses scene classifications and multi-dimensional tags to pinpoint exact shortcomings in text-to-image models.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
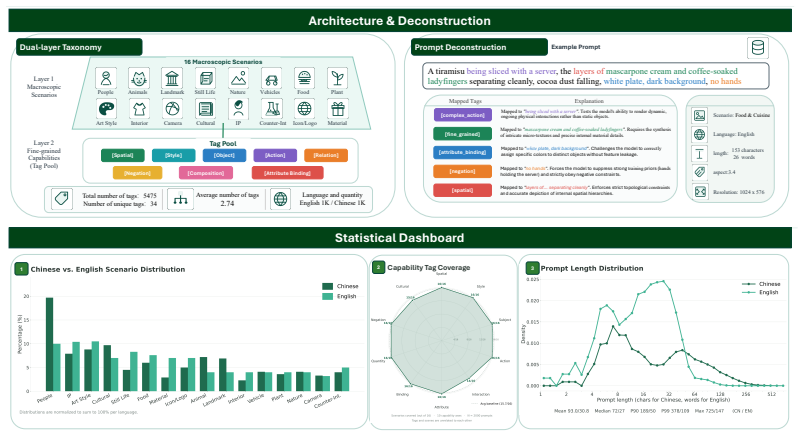
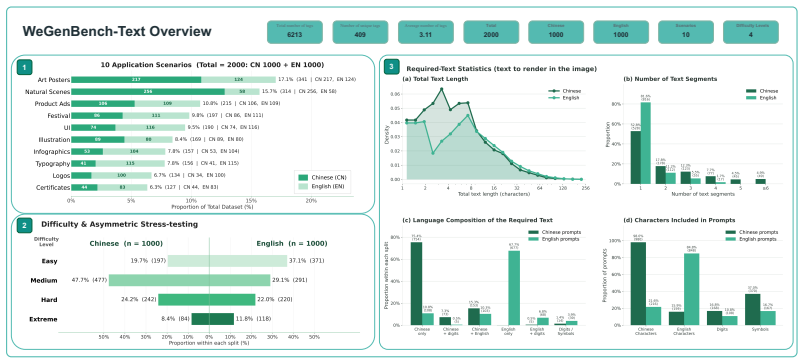
WeGenBench comprises 4,000 test prompts across two primary categories, meticulously balanced between Chinese and English. Each prompt carries multi-dimensional tags in addition to scene classifications. A cross-dimensional evaluation mechanism that leverages both levels of annotation, together with VLM-based metrics that return both assessment outcomes and detailed reasoning trajectories, enables precise identification of model shortcomings in specific generation categories.
What carries the argument
The cross-dimensional evaluation mechanism that pairs scene classifications with multi-dimensional content tags and pairs them with VLM metrics that supply both scores and reasoning trajectories.
If this is right
- Text-to-image models can be diagnosed and improved on the exact sub-categories where the benchmark flags weaknesses.
- Bilingual and cross-cultural generation performance becomes measurable at a finer grain than overall scores allow.
- Reasoning trajectories supplied by the VLM metrics permit direct verification of each assessment result.
- Existing state-of-the-art models exhibit measurable limitations once broken down by the scene and tag dimensions.
Where Pith is reading between the lines
- The diagnostic tags could be used to curate targeted training data that addresses the precise weaknesses identified.
- The same cross-dimensional tagging approach might transfer to related tasks such as text-to-video or image editing evaluation.
- Iterative model optimization loops could incorporate the benchmark outputs as feedback signals for focused retraining.
Load-bearing premise
VLM-based metrics with reasoning trajectories produce accurate and unbiased assessments of generation quality across all tagged sub-categories without human validation of the VLM outputs.
What would settle it
A human study that directly compares VLM scores and reasoning trajectories against human judgments on the same tagged prompts would falsify the central claim if large systematic discrepancies appear within specific sub-categories.
Figures







read the original abstract
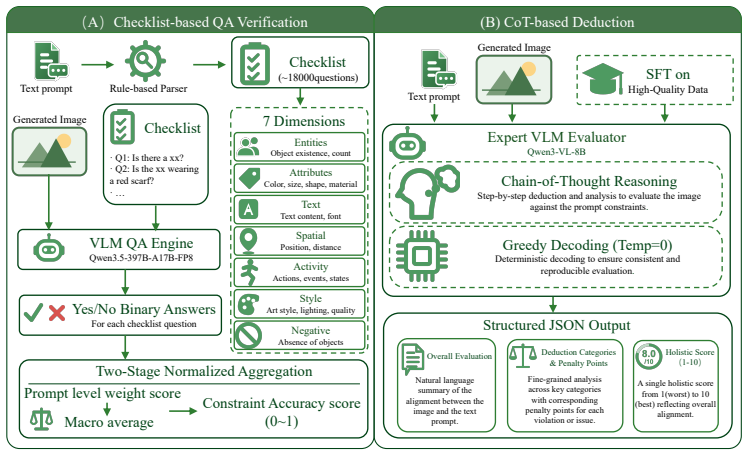
Recent text-to-image generation models have demonstrated remarkable capabilities in synthesizing highly realistic images from text inputs alone. Although existing benchmarks can evaluate the generation capabilities of various models to some extent, they struggle to comprehensively and accurately measure performance across multiple dimensions, often failing to reveal the inherent deficiencies of models in specific categories. To address these limitations, we propose WeGenBench, a novel benchmark designed for the comprehensive, multi-perspective evaluation of text-to-image generation capabilities. Our benchmark comprises a total of 4,000 test prompts across two primary categories, meticulously balanced between Chinese and English to evaluate bilingual and cross-cultural generation capabilities. Beyond macroscopic scene classification, we annotate each prompt with multi-dimensional tags tailored to the distinct content and challenges of each language, thereby refining the generation tasks into more specific sub-categories. Through a cross-dimensional evaluation mechanism leveraging both scene classifications and multi-dimensional tags, WeGenBench can precisely pinpoint model shortcomings in specific generation categories. Furthermore, to measure generation quality more accurately, we design and validate several novel evaluation metrics by integrating Vision-Language Models (VLMs), which assess model performance on domain-specific tasks from three core aspects. Crucially, our approach yields both the assessment outcomes and the detailed reasoning trajectories, facilitating a rigorous verification of the accuracy and soundness of the evaluation results. Finally, we conduct systematic benchmarking on current state-of-the-art methods and provide an in-depth analysis of the limitations present in existing models.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
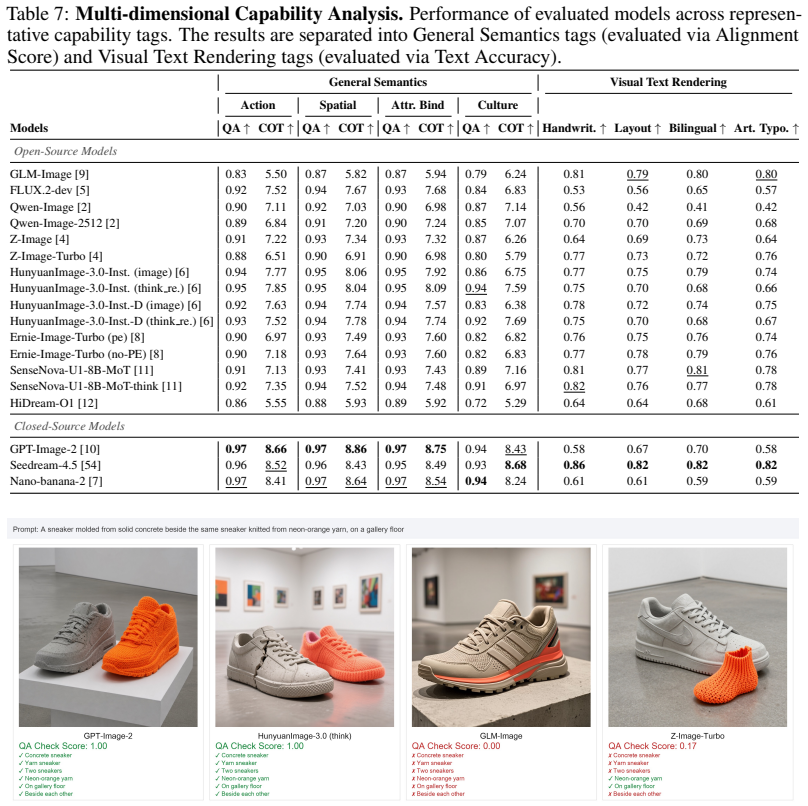
Summary. The paper introduces WeGenBench, a benchmark with 4,000 balanced Chinese-English prompts for text-to-image models. It augments scene-level classification with language-specific multi-dimensional tags to create finer sub-categories, employs a cross-dimensional evaluation mechanism to isolate model weaknesses, and proposes VLM-based metrics (with reasoning trajectories) that score generation quality along three core aspects. The work concludes with systematic benchmarking of current SOTA methods and an analysis of their limitations.
Significance. If the VLM metrics are shown to be reliable and the cross-dimensional tagging mechanism demonstrably isolates category-specific failures, the benchmark would supply a more granular diagnostic instrument than existing T2I evaluations, especially for bilingual and cross-cultural performance. This could directly inform targeted model optimization.
major comments (1)
- [Abstract] Abstract: The claim that the benchmark can 'precisely pinpoint model shortcomings in specific generation categories' is load-bearing and rests on the assertion that the VLM metrics were 'design[ed] and validate[d]' and produce 'rigorous verification' via reasoning trajectories. No quantitative validation results, inter-annotator agreement statistics, or error analysis on the 4,000 prompts are referenced, leaving the accuracy and lack of bias of the VLM assessments unestablished.
Simulated Author's Rebuttal
We thank the referee for highlighting the need for stronger evidence supporting the reliability of our VLM-based metrics. We address this point directly below and will revise the manuscript accordingly.
read point-by-point responses
-
Referee: [Abstract] Abstract: The claim that the benchmark can 'precisely pinpoint model shortcomings in specific generation categories' is load-bearing and rests on the assertion that the VLM metrics were 'design[ed] and validate[d]' and produce 'rigorous verification' via reasoning trajectories. No quantitative validation results, inter-annotator agreement statistics, or error analysis on the 4,000 prompts are referenced, leaving the accuracy and lack of bias of the VLM assessments unestablished.
Authors: We acknowledge that the current manuscript provides only qualitative support via reasoning trajectories and does not include quantitative validation results, inter-annotator agreement statistics, or systematic error analysis on the full set of 4,000 prompts. The abstract's phrasing therefore overstates the strength of the validation evidence. To correct this, we will add a new subsection detailing quantitative validation experiments (e.g., agreement with human raters on a sampled subset, bias checks across languages and categories, and error categorization). We will also tone down the abstract claim to reflect the available evidence until these results are included. revision: yes
Circularity Check
No circularity: benchmark construction is self-contained empirical work
full rationale
The paper presents a benchmark dataset of 4000 prompts with scene classifications and multi-dimensional tags, plus VLM-based evaluation metrics that output scores and reasoning trajectories. No mathematical derivations, fitted parameters, or predictions appear in the provided text or abstract. The central claim that the cross-dimensional mechanism can pinpoint shortcomings is an empirical assertion about the benchmark's utility, not a reduction of any output to its own inputs by construction. No self-citation chains, ansatzes, or uniqueness theorems are invoked to justify core results. The work is therefore self-contained against external benchmarks and receives the default non-circularity finding.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dustin Podell, Zion English, Kyle Lacey, Andreas Blattmann, Tim Dockhorn, Jonas M¨uller, Joe Penna, and Robin Rombach. Sdxl: Improving latent diffusion models for high-resolution image synthesis.arXiv preprint arXiv:2307.01952, 2023
Pith/arXiv arXiv 2023
-
[2]
Qwen-image-2.0 technical report, 2026
Bing Zhao, Chenfei Wu, Deqing Li, Hao Meng, Jiahao Li, Jie Zhang, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kuan Cao, Kun Yan, Liang Peng, Lihan Jiang, Niantong Li, Ningyuan Tang, Shengming Yin, Tianhe Wu, Xiao Xu, Xiaoyue Chen, Xihua Wang, Yan Shu, Yanran Zhang, Yi Wang, Yilei Chen, Ying Ba, Yixian Xu, Yujia Wu, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhe...
Pith/arXiv arXiv 2026
-
[3]
Scaling rectified flow transformers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas M¨uller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow transformers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[4]
Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
Huanqia Cai, Sihan Cao, Ruoyi Du, Peng Gao, Steven Hoi, Zhaohui Hou, Shijie Huang, Dengyang Jiang, Xin Jin, Liangchen Li, et al. Z-image: An efficient image generation foundation model with single-stream diffusion transformer, 2025
2025
-
[5]
FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
Black Forest Labs. FLUX.2: Frontier Visual Intelligence.https://bfl.ai/blog/flux-2, 2025
2025
-
[6]
Hunyuanimage 3.0 technical report, 2026
Siyu Cao, Hangting Chen, Peng Chen, Yiji Cheng, Yutao Cui, Xinchi Deng, Ying Dong, Kipper Gong, Tianpeng Gu, Xiusen Gu, Tiankai Hang, Duojun Huang, Jie Jiang, Zhengkai Jiang, Weijie Kong, Changlin Li, Donghao Li, Junzhe Li, Xin Li, Yang Li, Zhenxi Li, Zhimin Li, Jiaxin Lin, Linus, Lucaz Liu, Shu Liu, Songtao Liu, Yu Liu, Yuhong Liu, Yanxin Long, Fanbin Lu...
Pith/arXiv arXiv 2026
-
[7]
”nano banana 2”, 2026
Google. ”nano banana 2”, 2026. URL https://deepmind.google/models/gemini-image/flash/. Accessed: 2026-06-16
2026
-
[8]
”ernie-image-turbo”, 2026
Baidu. ”ernie-image-turbo”, 2026. URLhttps://yiyan.baidu.com/. Accessed: 2026-06-16
2026
-
[9]
”glm-image”, 2026
Z.ai. ”glm-image”, 2026. URLhttps://github.com/zai-org/GLM-Image. Accessed: 2026-06-16
2026
-
[10]
”gpt-image-2”, 2026
OpenAI. ”gpt-image-2”, 2026. URL https://openai.com/index/ introducing-chatgpt-images-2-0/. Accessed: 2026-06-16
2026
-
[11]
Haiwen Diao, Penghao Wu, Hanming Deng, Jiahao Wang, Shihao Bai, Silei Wu, Weichen Fan, Wenjie Ye, Wenwen Tong, Xiangyu Fan, et al. Sensenova-u1: Unifying multimodal understanding and generation with neo-unify architecture.arXiv preprint arXiv:2605.12500, 2026
Pith/arXiv arXiv 2026
-
[12]
Qi Cai, Jingwen Chen, Chengmin Gao, Zijian Gong, Yehao Li, Tao Mei, Yingwei Pan, Yi Peng, Zhaofan Qiu, Ting Yao, Kai Yu, Yiheng Zhang, et al. Hidream-o1-image: A natively unified image generative foundation model with pixel-level unified transformer.arXiv preprint arXiv:2605.11061, 2026. 25
Pith/arXiv arXiv 2026
-
[13]
Conceptbed: Evaluating concept learning abilities of text-to-image diffusion models
Maitreya Patel, Tejas Gokhale, Chitta Baral, and Yezhou Yang. Conceptbed: Evaluating concept learning abilities of text-to-image diffusion models. InProceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 14554–14562, 2024
2024
-
[14]
Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models
Jaemin Cho, Abhay Zala, and Mohit Bansal. Dall-eval: Probing the reasoning skills and social biases of text-to-image generation models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3043–3054, 2023
2023
-
[15]
Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering
Yushi Hu, Benlin Liu, Jungo Kasai, Yizhong Wang, Mari Ostendorf, Ranjay Krishna, and Noah A Smith. Tifa: Accurate and interpretable text-to-image faithfulness evaluation with question answering. In Proceedings of the IEEE/CVF International Conference on Computer Vision, pages 20406–20417, 2023
2023
-
[16]
Xiangru Zhu, Penglei Sun, Chengyu Wang, Jingping Liu, Zhixu Li, Yanghua Xiao, and Jun Huang. A contrastive compositional benchmark for text-to-image synthesis: A study with unified text-to-image fidelity metrics.arXiv preprint arXiv:2312.02338, 2023
arXiv 2023
-
[17]
Xiwei Hu, Rui Wang, Yixiao Fang, Bin Fu, Pei Cheng, and Gang Yu. Ella: Equip diffusion models with llm for enhanced semantic alignment.arXiv preprint arXiv:2403.05135, 2024
Pith/arXiv arXiv 2024
-
[18]
Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models
Eslam Mohamed Bakr, Pengzhan Sun, Xiaoqian Shen, Faizan Farooq Khan, Li Erran Li, and Mohamed Elhoseiny. Hrs-bench: Holistic, reliable and scalable benchmark for text-to-image models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 20041–20053, 2023
2023
-
[19]
Anytext: Multilingual visual text generation and editing.arXiv preprint arXiv:2311.03054, 2023
Yuxiang Tuo, Wangmeng Xiang, Jun-Yan He, Yifeng Geng, and Xuansong Xie. Anytext: Multilingual visual text generation and editing.arXiv preprint arXiv:2311.03054, 2023
arXiv 2023
-
[20]
T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
Kaiyi Huang, Kaiyue Sun, Enze Xie, Zhenguo Li, and Xihui Liu. T2i-compbench: A comprehensive benchmark for open-world compositional text-to-image generation.Advances in Neural Information Processing Systems, 36:78723–78747, 2023
2023
-
[21]
Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
Jiazheng Xu, Xiao Liu, Yuchen Wu, Yuxuan Tong, Qinkai Li, Ming Ding, Jie Tang, and Yuxiao Dong. Imagereward: Learning and evaluating human preferences for text-to-image generation.Advances in Neural Information Processing Systems, 36:15903–15935, 2023
2023
-
[22]
Qwen-image-bench: From generation to creation in text-to-image evaluation
Niantong Li, Guangzheng Hu, Weixu Qiao, Ying Ba, Qichen Hong, Shijun Shen, Jinlin Wang, Fan Zhou, Jianye Kang, Xin Shang, et al. Qwen-image-bench: From generation to creation in text-to-image evaluation. arXiv preprint arXiv:2605.28091, 2026
Pith/arXiv arXiv 2026
-
[23]
Oneig-bench: Omni-dimensional nuanced evaluation for image generation, 2025
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation, 2025. URL https://arxiv.org/abs/2506.07977
arXiv 2025
-
[24]
Jiahui Yu, Yuanzhong Xu, Jing Yu Koh, Thang Luong, Gunjan Baid, Zirui Wang, Vijay Vasudevan, Alexander Ku, Yinfei Yang, Burcu Karagol Ayan, et al. Scaling autoregressive models for content-rich text-to-image generation.arXiv preprint arXiv:2206.10789, 2(3):5, 2022
Pith/arXiv arXiv 2022
-
[25]
Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
Dhruba Ghosh, Hannaneh Hajishirzi, and Ludwig Schmidt. Geneval: An object-focused framework for evaluating text-to-image alignment.Advances in Neural Information Processing Systems, 36:52132–52152, 2023
2023
-
[26]
Oneig-bench: Omni-dimensional nuanced evaluation for image generation.Advances in Neural Information Processing Systems, 38, 2026
Jingjing Chang, Yixiao Fang, Peng Xing, Shuhan Wu, Wei Cheng, Rui Wang, Xianfang Zeng, Gang Yu, and Hai-Bao Chen. Oneig-bench: Omni-dimensional nuanced evaluation for image generation.Advances in Neural Information Processing Systems, 38, 2026
2026
-
[27]
Tiif-bench: How does your t2i model follow your instructions?arXiv preprint arXiv:2506.02161, 2025
Xinyu Wei, Jinrui Zhang, Zeqing Wang, Hongyang Wei, Zhen Guo, and Lei Zhang. Tiif-bench: How does your t2i model follow your instructions?arXiv preprint arXiv:2506.02161, 2025
arXiv 2025
-
[28]
Yusu Qian, Cheng Wan, Chao Jia, Yinfei Yang, Qingyu Zhao, and Zhe Gan. Prism-bench: A benchmark of puzzle-based visual tasks with cot error detection.arXiv preprint arXiv:2510.23594, 2025
arXiv 2025
-
[29]
Textcrafter: Accurately rendering multiple texts in complex visual scenes.arXiv e-prints, pages arXiv–2503, 2025
Nikai Du, Zhennan Chen, Zhizhou Chen, Shan Gao, Xi Chen, Zhengkai Jiang, Jian Yang, and Ying Tai. Textcrafter: Accurately rendering multiple texts in complex visual scenes.arXiv e-prints, pages arXiv–2503, 2025
2025
-
[30]
Longbench: A bilingual, multitask benchmark for long context understanding
Yushi Bai, Xin Lv, Jiajie Zhang, Hongchang Lyu, Jiankai Tang, Zhidian Huang, Zhengxiao Du, Xiao Liu, Aohan Zeng, Lei Hou, et al. Longbench: A bilingual, multitask benchmark for long context understanding. InProceedings of the 62nd annual meeting of the association for computational linguistics (volume 1: Long papers), pages 3119–3137, 2024. 26
2024
-
[31]
Lusha Wang, Yuchen Li, Su Yuan, and Jungyeul Park. Chinese word boundary recovery through character alignment projection.arXiv preprint arXiv:2605.28128, 2026
Pith/arXiv arXiv 2026
-
[32]
Viescore: Towards explainable metrics for conditional image synthesis evaluation
Max Ku, Dongfu Jiang, Cong Wei, Xiang Yue, and Wenhu Chen. Viescore: Towards explainable metrics for conditional image synthesis evaluation. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 12268–12290, 2024
2024
-
[33]
Seyed Mohammad Hadi Hosseini, Amir Mohammad Izadi, Ali Abdollahi, Armin Saghafian, and Mahdieh Soleymani Baghshah. T2i-fineeval: Fine-grained compositional metric for text-to-image evalua- tion.arXiv preprint arXiv:2503.11481, 2025
arXiv 2025
-
[34]
Multi-modal language models as text-to-image model evaluators.arXiv preprint arXiv:2505.00759, 2025
Jiahui Chen, Candace Ross, Reyhane Askari-Hemmat, Koustuv Sinha, Melissa Hall, Michal Drozdzal, and Adriana Romero-Soriano. Multi-modal language models as text-to-image model evaluators.arXiv preprint arXiv:2505.00759, 2025
arXiv 2025
-
[35]
Llmscore: Unveiling the power of large language models in text-to-image synthesis evaluation.Advances in neural information processing systems, 36:23075–23093, 2023
Yujie Lu, Xianjun Yang, Xiujun Li, Xin Eric Wang, and William Yang Wang. Llmscore: Unveiling the power of large language models in text-to-image synthesis evaluation.Advances in neural information processing systems, 36:23075–23093, 2023
2023
-
[36]
Evaluating text-to-visual generation with image-to-text generation
Zhiqiu Lin, Deepak Pathak, Baiqi Li, Jiayao Li, Xide Xia, Graham Neubig, Pengchuan Zhang, and Deva Ramanan. Evaluating text-to-visual generation with image-to-text generation. InEuropean Conference on Computer Vision, pages 366–384. Springer, 2024
2024
-
[37]
Learn- ing multi-dimensional human preference for text-to-image generation
Sixian Zhang, Bohan Wang, Junqiang Wu, Yan Li, Tingting Gao, Di Zhang, and Zhongyuan Wang. Learn- ing multi-dimensional human preference for text-to-image generation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8018–8027, 2024
2024
-
[38]
Pick-a- pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
Yuval Kirstain, Adam Polyak, Uriel Singer, Shahbuland Matiana, Joe Penna, and Omer Levy. Pick-a- pic: An open dataset of user preferences for text-to-image generation.Advances in neural information processing systems, 36:36652–36663, 2023
2023
-
[39]
Xiaoshi Wu, Yiming Hao, Keqiang Sun, Yixiong Chen, Feng Zhu, Rui Zhao, and Hongsheng Li. Human preference score v2: A solid benchmark for evaluating human preferences of text-to-image synthesis.arXiv preprint arXiv:2306.09341, 2023
Pith/arXiv arXiv 2023
-
[40]
Clipscore: A reference-free evaluation metric for image captioning
Jack Hessel, Ari Holtzman, Maxwell Forbes, Ronan Le Bras, and Yejin Choi. Clipscore: A reference-free evaluation metric for image captioning. InProceedings of the 2021 conference on empirical methods in natural language processing, pages 7514–7528, 2021
2021
-
[41]
Generative adversarial nets.Advances in neural information processing systems, 27, 2014
Ian J Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets.Advances in neural information processing systems, 27, 2014
2014
-
[42]
A style-based generator architecture for generative adversarial networks
Tero Karras, Samuli Laine, and Timo Aila. A style-based generator architecture for generative adversarial networks. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 4401–4410, 2019
2019
-
[43]
Scaling up gans for text-to-image synthesis
Minguk Kang, Jun-Yan Zhu, Richard Zhang, Jaesik Park, Eli Shechtman, Sylvain Paris, and Taesung Park. Scaling up gans for text-to-image synthesis. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10124–10134, 2023
2023
-
[44]
High-resolution image synthesis with latent diffusion models
Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Bj¨orn Ommer. High-resolution image synthesis with latent diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10684–10695, 2022
2022
-
[45]
T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models
Chong Mou, Xintao Wang, Liangbin Xie, Yanze Wu, Jian Zhang, Zhongang Qi, and Ying Shan. T2i- adapter: Learning adapters to dig out more controllable ability for text-to-image diffusion models. In Proceedings of the AAAI conference on artificial intelligence, volume 38, pages 4296–4304, 2024
2024
-
[46]
Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
Zeyue Xue, Jie Wu, Yu Gao, Fangyuan Kong, Lingting Zhu, Mengzhao Chen, Zhiheng Liu, Wei Liu, Qiushan Guo, Weilin Huang, et al. Dancegrpo: Unleashing grpo on visual generation.arXiv preprint arXiv:2505.07818, 2025
Pith/arXiv arXiv 2025
-
[47]
Microsoft coco: Common objects in context
Tsung-Yi Lin, Michael Maire, Serge Belongie, James Hays, Pietro Perona, Deva Ramanan, Piotr Doll´ar, and C Lawrence Zitnick. Microsoft coco: Common objects in context. InEuropean conference on computer vision, pages 740–755. Springer, 2014
2014
-
[48]
Improved techniques for training gans.Advances in neural information processing systems, 29, 2016
Tim Salimans, Ian Goodfellow, Wojciech Zaremba, Vicki Cheung, Alec Radford, and Xi Chen. Improved techniques for training gans.Advances in neural information processing systems, 29, 2016. 27
2016
-
[49]
Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
Martin Heusel, Hubert Ramsauer, Thomas Unterthiner, Bernhard Nessler, and Sepp Hochreiter. Gans trained by a two time-scale update rule converge to a local nash equilibrium.Advances in neural information processing systems, 30, 2017
2017
-
[50]
Winoground: Probing vision and language models for visio-linguistic compositionality
Tristan Thrush, Ryan Jiang, Max Bartolo, Amanpreet Singh, Adina Williams, Douwe Kiela, and Candace Ross. Winoground: Probing vision and language models for visio-linguistic compositionality. InPro- ceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 5238–5248, 2022
2022
-
[51]
Hanshen Zhu, Yuliang Liu, Xuecheng Wu, An-Lan Wang, Hao Feng, Dingkang Yang, Chao Feng, Can Huang, Jingqun Tang, and Xiang Bai. Textpecker: Rewarding structural anomaly quantification for enhancing visual text rendering.arXiv preprint arXiv:2602.20903, 2026
arXiv 2026
-
[52]
Hpsv3: Towards wide-spectrum human preference score
Yuhang Ma, Xiaoshi Wu, Keqiang Sun, and Hongsheng Li. Hpsv3: Towards wide-spectrum human preference score. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15086–15095, 2025
2025
-
[53]
Chunyu Xie, Bin Wang, Fanjing Kong, Jincheng Li, Dawei Liang, Ji Ao, Dawei Leng, and Yuhui Yin. Fg-clip 2: A bilingual fine-grained vision-language alignment model.arXiv preprint arXiv:2510.10921, 2025
Pith/arXiv arXiv 2025
-
[54]
”seedream-4.5”, 2026
ByteDance Seed. ”seedream-4.5”, 2026. URL https://seed.bytedance.com/en/seedream4_5. Accessed: 2026-06-16. 28 A Prompt Templates for Evaluation In this section, we provide the detailed prompt templates utilized by our Vision-Language Model (VLM) evaluators. To ensure reproducibility and transparency, we present the exact instructions used for the Checklis...
2026
-
[55]
Locate the entity referenced in the question; confirm whether it exists and is recognizable in the image
-
[56]
| also get 0)
If the entity does not exist or is unrecognizable -> output 0 immediately (all attribute questions about that entity | color, material, position, action, etc. | also get 0)
-
[57]
If the entity exists -> judge whether its attributes match according to the category-specific rules below
-
[58]
Output 1 when the evidence is sufficient for most people to agree; otherwise output 0 ## General Principles
-
[59]
**Only look at the image**: Do not rely on common knowledge, storylines, titles, identity lore, or inference by imagination
-
[60]
**Objective elements require strict matching**: orange != red, 2 != 3, cherry blossom != peach blossom, short hair != waist-length hair, watercolor style != fine-line painting style
-
[61]
**Insufficient evidence -> 0**: Completely unreadable, heavily occluded/cropped/blurred -> 0; slightly blurry but still recognizable -> 1
-
[62]
**Indirect carriers do not count as real entities**: Content inside posters, picture frames, printed patterns, on-screen images, mirrors/reflections, motifs/statues/figurines is not counted as a real entity and is excluded from quantity counts (unless the question explicitly asks about the content within such carriers)
-
[63]
**Reasonable deviation exemption**: Variations within a broad style category, same-hue color shifts, minor camera angle adjustments, and logically justified content simplification are treated as normal aesthetic variation and should not result in 0. ## Specific Rules by Category ### Style - Evaluate the overall style of the entire image, not the style of ...
-
[64]
Structure: Human body deformities, incorrect number of limbs, garbled text, broken text, logical errors, broken object structures, clipping, false projections, etc
-
[65]
Texture (AI texture): Greasy feel, cheap texture, heavy smearing, stiff postures, plastic feel, waxy feel, algorithmic over-sharpening, excessive noise, falsely smooth textures, dull/dirty image, etc
-
[66]
Lighting: Whether highlights are overexposed (dead white), dark areas have details (dead black), ambient light is unified, shadows conform to physical logic (no void shadows), lighting logic (e.g., subject and background lighting direction match), and whether lighting enhances the atmosphere
-
[67]
Color: Whether colors are balanced, contrast is normal, hue shifts are harmonious, skin tones are natural (avoiding fake red/cyan), and color usage has a premium feel
-
[68]
Whether the scene is cluttered, visual center of gravity shifts, edge cropping is cramped, perspective is reasonable, and foreground/background proportions are imbalanced
Composition: Whether the subject stands out, is interfered with, truncated, occluded, or too small. Whether the scene is cluttered, visual center of gravity shifts, edge cropping is cramped, perspective is reasonable, and foreground/background proportions are imbalanced. The side with a clearer, more eye-catching subject has the advantage
-
[69]
[Scoring Principles]: 31 - Position-Agnostic: Whether the image is on the left or right does not affect the quality judgment
Completeness: Image refinement precision, whether it feels like a ‘‘semi-finished product’’, whether styles are inconsistent causing a mixed feel, whether stylization is insufficient leading to a ‘‘neither fish nor fowl’’ look, whether different areas in the same image have fragmented styles, and whether the subject and background are coordinated. [Scorin...
-
[70]
- ‘‘better’’: Input image is clearly superior to the anchor image in this dimension
Judgment Options: All dimensions must be chosen from [‘‘worse’’, ‘‘similar’’, ‘‘better’’]. - ‘‘better’’: Input image is clearly superior to the anchor image in this dimension. - ‘‘worse’’: Input image is clearly inferior to the anchor image in this dimension. - ‘‘similar’’: The difference in this dimension is insufficient to distinguish superiority. Do no...
-
[71]
If ‘‘structure’’ is ‘‘worse’’, the ‘‘final_decision’’ cannot be higher than ‘‘worse’’
Core Principle: The ‘‘structure’’ dimension has veto power. If ‘‘structure’’ is ‘‘worse’’, the ‘‘final_decision’’ cannot be higher than ‘‘worse’’
-
[72]
If 4 or more dimensions are ‘‘better’’, ‘‘final_decision’’ is at least ‘‘better’’; if 4 or more dimensions are ‘‘worse’’, ‘‘final_decision’’ is at least ‘‘worse’’
‘‘final_decision’’ Derivation Rules: Based primarily on the majority of dimensions, with ‘‘structure’’, ‘‘texture’’, and ‘‘completeness’’ carrying more weight. If 4 or more dimensions are ‘‘better’’, ‘‘final_decision’’ is at least ‘‘better’’; if 4 or more dimensions are ‘‘worse’’, ‘‘final_decision’’ is at least ‘‘worse’’
-
[73]
Think clearly before judging
Output Order: You must strictly follow the JSON format below, writing ‘‘reasoning’’ first, then ‘‘comparisons’’, and finally ‘‘final_decision’’. Think clearly before judging
-
[74]
Even if the overall judgment is ‘‘better’’, truthfully state the input image’s disadvantages (it cannot have no disadvantages)
‘‘reasoning’’ Format: Summarize in one sentence, formatted as ‘‘Advantages: X; 32 Disadvantages: Y; Decisive Factor: Z’’. Even if the overall judgment is ‘‘better’’, truthfully state the input image’s disadvantages (it cannot have no disadvantages)
-
[75]
reasoning
No Nonsense: Output only a standard JSON block. { "reasoning": "Advantages: X; Disadvantages: Y; Decisive Factor: Z", "comparisons": { "structure": "worse|similar|better", "texture": "worse|similar|better", "lighting": "worse|similar|better", "color": "worse|similar|better", "composition": "worse|similar|better", "completeness": "worse|similar|better" }, ...
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.