FrozenDrive: Zero-Shot Text-Guided Driving Scene Generation and Data Augmentation with Parameter-Free Frozen Diffusion Model
Pith reviewed 2026-06-26 18:32 UTC · model grok-4.3
The pith
A frozen diffusion model with knowledge-preserving spatio-temporal attention generates coherent multi-view driving scenes from text without fine-tuning or parameter updates.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
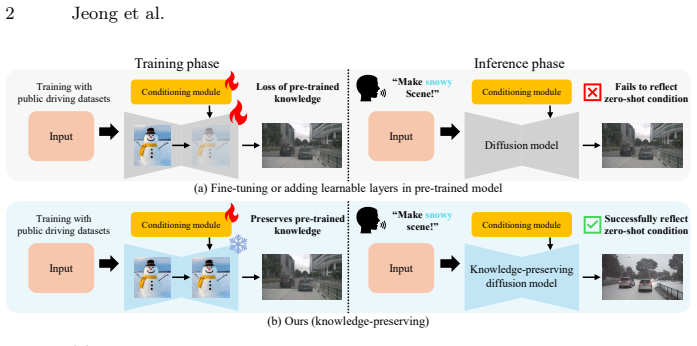
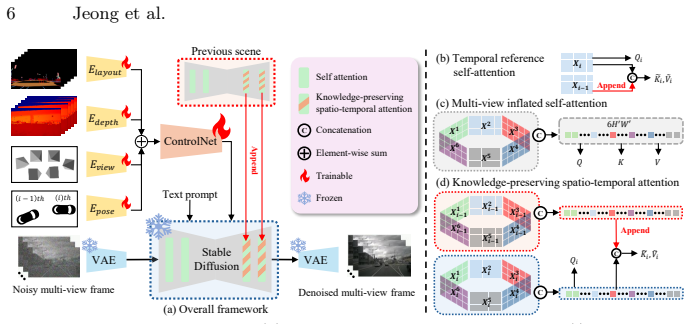
FrozenDrive conditions on rich driving-stack signals and text prompts, and introduces knowledge-preserving spatio-temporal attention to impose cross-view alignment and temporal coherence in a single pass within a parameter-free frozen diffusion backbone. An additional object-focused constraint improves per-object fidelity for rare categories. Without any weather- or scene-specific fine-tuning, the model synthesizes globally coherent multi-view driving scenes from text, particularly under adverse and rare conditions, and surpasses prior baselines. On nuScenes, FrozenDrive augmented data significantly improves AD models performance, especially at night and in rain.
What carries the argument
Knowledge-preserving spatio-temporal attention mechanism that imposes cross-view alignment and temporal coherence while preserving the pre-trained diffusion model's knowledge and text alignment without any parameter updates or added layers.
If this is right
- The approach enables synthesis of driving scenes under adverse weather and rare configurations without any fine-tuning.
- Data generated by the model augments training sets and raises autonomous driving model accuracy, especially at night and in rain.
- Text alignment and per-object fidelity for infrequent classes remain higher than in fine-tuned alternatives.
- A single forward pass produces globally consistent multi-view output that exceeds prior methods on the same benchmarks.
- The object-focused constraint directly lifts fidelity on rare object categories in the generated scenes.
Where Pith is reading between the lines
- The same frozen consistency mechanism could be tested on other multi-camera or video domains where retraining diffusion models is costly.
- Targeted text prompts might let practitioners generate specific edge-case scenarios on demand rather than relying on real-world collection.
- If the attention module generalizes, similar lightweight additions could extend to other pre-trained generative backbones without domain-specific retraining.
- Downstream gains on nuScenes suggest the generated data fills distribution gaps that real datasets under-sample.
Load-bearing premise
The added spatio-temporal attention can enforce multi-view and temporal consistency while leaving the original model's knowledge and text alignment completely intact.
What would settle it
A direct comparison showing that scenes generated by the frozen model with the new attention still lack cross-view or temporal coherence, or that AD models trained on the augmented data show no improvement over baselines in night or rain conditions on nuScenes.
Figures




read the original abstract
Synthetic data for autonomous driving is surging, powered by diffusion models that promise scalable scene generation. Yet key obstacles remain, as enforcing multi-view and temporal consistency often relies on backbone fine-tuning or added layers, which erodes pre-trained knowledge and weakens text alignment. Models also stay close to the training distribution, struggling under adverse weather and unseen configurations, and fidelity favors frequent over rare classes. We address these gaps with FrozenDrive, a controllable generative framework that preserves a pretrained diffusion models knowledge while achieving strong consistency. FrozenDrive conditions on rich driving-stack signals and text prompts, and introduces knowledge-preserving spatio-temporal attention to impose cross-view alignment and temporal coherence in a single pass within a parameter-free frozen diffusion backbone. An additional object-focused constraint improves per-object fidelity for rare categories. Without any weather- or scene-specific fine-tuning, our model synthesizes globally coherent multi-view driving scenes from text, particularly under adverse and rare conditions, and surpasses prior baselines. On nuScenes, FrozenDrive augmented data significantly improves AD models performance, especially at night and in rain, demonstrating stronger robustness when trained with our scenario-targeted data.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript presents FrozenDrive, a framework for zero-shot text-guided generation of multi-view driving scenes using a frozen pre-trained diffusion model. It introduces a knowledge-preserving spatio-temporal attention mechanism to achieve cross-view and temporal consistency without any parameter updates or additional layers, along with an object-focused constraint to improve fidelity for rare categories. The paper claims that this approach generates globally coherent scenes particularly under adverse and rare conditions, surpasses prior baselines, and when used to augment nuScenes data, significantly improves the performance of autonomous driving models, especially at night and in rain.
Significance. If the central claims hold, the work would be significant for the field of synthetic data generation for autonomous driving. By enabling controllable, consistent multi-view scene synthesis without fine-tuning a diffusion backbone, it could facilitate the creation of targeted data for rare and adverse scenarios while preserving the generative capabilities and text alignment of pre-trained models. This has potential to enhance the robustness of AD systems through data augmentation, as demonstrated on nuScenes.
major comments (2)
- [Abstract] Abstract: The abstract asserts that the model 'surpasses prior baselines' and that 'FrozenDrive augmented data significantly improves AD models performance' but provides no quantitative metrics, baselines, error bars, or ablation details to support these claims. This makes the performance assertions difficult to evaluate and is load-bearing for the central superiority claim.
- [Method] Method (knowledge-preserving spatio-temporal attention): The mechanism is described as imposing cross-view alignment and temporal coherence in a single pass on a frozen backbone without parameter updates or added layers. Standard diffusion attention operates within single-view latents; no equation, derivation, or analysis is supplied showing how pre-existing attention maps already contain the necessary geometric and temporal correspondences for arbitrary text prompts (including adverse conditions). This assumption is load-bearing for the zero-shot consistency and downstream AD improvement claims.
minor comments (1)
- [Abstract] Abstract: The term 'rich driving-stack signals' is used without definition or example, which reduces clarity for readers not already familiar with the conditioning inputs.
Simulated Author's Rebuttal
We appreciate the referee's thorough review and constructive feedback on our manuscript. Below, we provide point-by-point responses to the major comments.
read point-by-point responses
-
Referee: [Abstract] Abstract: The abstract asserts that the model 'surpasses prior baselines' and that 'FrozenDrive augmented data significantly improves AD models performance' but provides no quantitative metrics, baselines, error bars, or ablation details to support these claims. This makes the performance assertions difficult to evaluate and is load-bearing for the central superiority claim.
Authors: The full paper provides detailed quantitative evaluations, including comparisons to baselines with specific metrics, error bars from multiple runs, and ablation studies in Sections 4.2 and 4.3. However, we agree that the abstract would benefit from including key quantitative results to make the claims more concrete. We will revise the abstract to incorporate representative metrics, such as the improvement percentages on nuScenes under adverse conditions. revision: yes
-
Referee: [Method] Method (knowledge-preserving spatio-temporal attention): The mechanism is described as imposing cross-view alignment and temporal coherence in a single pass on a frozen backbone without parameter updates or added layers. Standard diffusion attention operates within single-view latents; no equation, derivation, or analysis is supplied showing how pre-existing attention maps already contain the necessary geometric and temporal correspondences for arbitrary text prompts (including adverse conditions). This assumption is load-bearing for the zero-shot consistency and downstream AD improvement claims.
Authors: The manuscript describes the knowledge-preserving spatio-temporal attention as a modification to the attention mechanism that incorporates multi-view and temporal information by attending across the concatenated latents from different views and frames, leveraging the pre-trained model's ability to handle such correspondences through the conditioning signals. We acknowledge that a more formal derivation and analysis of why the pre-existing attention maps suffice for consistency in zero-shot settings would strengthen the presentation. We will add equations detailing the attention computation and an analysis section or appendix discussing the geometric correspondences. revision: yes
Circularity Check
No significant circularity; claims rest on described novel mechanism without reduction to inputs or self-citations
full rationale
The provided manuscript text introduces FrozenDrive via a parameter-free knowledge-preserving spatio-temporal attention applied to a frozen diffusion backbone, with no equations, derivations, or fitted parameters shown that reduce any prediction or consistency claim to a self-referential fit. No self-citations are invoked as load-bearing for uniqueness or ansatzes, and the central technique is presented as an independent conditioning approach rather than a renaming or construction from the target outputs. The derivation chain is therefore self-contained against external benchmarks, consistent with the absence of any quoted reduction steps.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Pre-trained diffusion models retain useful knowledge when kept frozen and conditioned with driving-stack signals and text prompts.
Reference graph
Works this paper leans on
-
[1]
International Journal of Computer Vision126(9), 961–972 (2018) 4
Abu Alhaija, H., Mustikovela, S.K., Mescheder, L., Geiger, A., Rother, C.: Aug- mented reality meets computer vision: Efficient data generation for urban driving scenes. International Journal of Computer Vision126(9), 961–972 (2018) 4
2018
-
[2]
arXiv preprint arXiv:2008.03156 (2020) 13
Aghajanyan, A., Shrivastava, A., Gupta, A., Goyal, N., Zettlemoyer, L., Gupta, S.: Better fine-tuning by reducing representational collapse. arXiv preprint arXiv:2008.03156 (2020) 13
arXiv 2008
-
[3]
arXiv preprint arXiv:2408.06071 (2024) 4
Assion, F., Gressner, F., Augustine, N., Klemenc, J., Hammam, A., Krattinger, A., Trittenbach, H., Philippsen, A., Riemer, S.: A-bdd: Leveraging data aug- mentations for safe autonomous driving in adverse weather and lighting. arXiv preprint arXiv:2408.06071 (2024) 4
arXiv 2024
-
[4]
arXiv preprint arXiv:2311.15127 (2023) 2, 4
Blattmann, A., Dockhorn, T., Kulal, S., Mendelevitch, D., Kilian, M., Lorenz, D., Levi, Y., English, Z., Voleti, V., Letts, A., et al.: Stable video diffusion: Scaling latent video diffusion models to large datasets. arXiv preprint arXiv:2311.15127 (2023) 2, 4
Pith/arXiv arXiv 2023
-
[5]
In: CVPR (2023) 4
Brooks, T., Holynski, A., Efros, A.A.: Instructpix2pix: Learning to follow image editing instructions. In: CVPR (2023) 4
2023
-
[6]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Caesar, H., Bankiti, V., Lang, A.H., Vora, S., Liong, V.E., Xu, Q., Krishnan, A., Pan,Y.,Baldan,G.,Beijbom,O.:nuscenes:Amultimodaldatasetforautonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 11621–11631 (2020) 2, 9, 10, 16, 17, 18
2020
-
[7]
In: Proceedings of the IEEE/CVF international conference on computer vision
Caron, M., Touvron, H., Misra, I., Jégou, H., Mairal, J., Bojanowski, P., Joulin, A.: Emerging properties in self-supervised vision transformers. In: Proceedings of the IEEE/CVF international conference on computer vision. pp. 9650–9660 (2021) 14
2021
-
[8]
Author et al
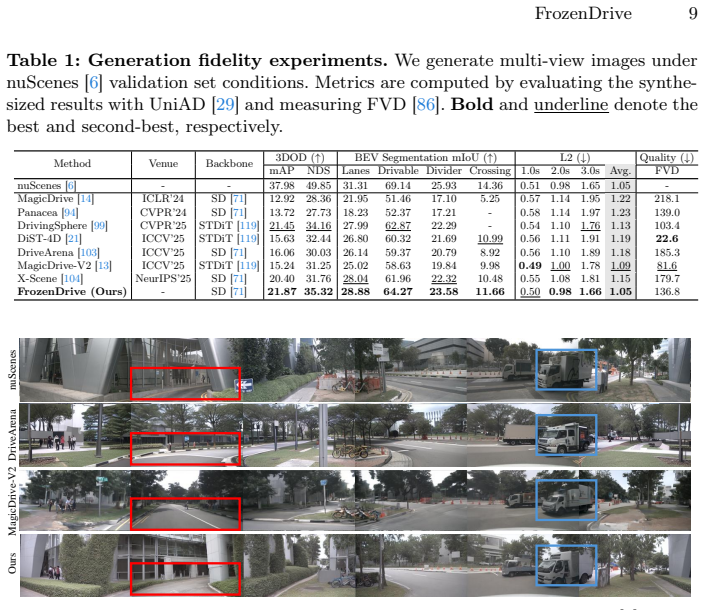
Chen, Y., Rong, F., Duggal, S., Wang, S., Yan, X., Manivasagam, S., Xue, S., Yumer, E., Urtasun, R.: Geosim: Realistic video simulation via geometry-aware 26 F. Author et al. nuScenesDriveArena MD-V2 Ours Ours MD-V2 DriveArena nuScenes Ours MD-V2 DriveArena nuScenes Fig.H:Qualitative comparison of generated samples. MD-V2 denotes MagicDrive- V2 [13]. Abbr...
2021
-
[9]
In: ICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)
Cheng, H., Xu, J., Peng, L., Yang, Z., He, X., Wu, B.: Object-level data augmen- tation for visual 3d object detection in autonomous driving. In: ICASSP 2025- 2025 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). pp. 1–5. IEEE (2025) 4
2025
-
[10]
arXiv preprint arXiv:2504.18448 (2025) 4
Dong, H., Wang, X., Lin, D., Wu, Y., Chen, Q., Liu, R., Yang, K., Li, P., Guo, Q.: Noisecontroller: Towards consistent multi-view video generation via noise de- composition and collaboration. arXiv preprint arXiv:2504.18448 (2025) 4
arXiv 2025
-
[11]
arXiv preprint arXiv:2401.03771 (2024) 4
Feldmann, C., Siegenheim, N., Hars, N., Rabuzin, L., Ertugrul, M., Wolfart, L., Pollefeys, M., Bauer, Z., Oswald, M.R.: Nerfmentation: Nerf-based augmentation for monocular depth estimation. arXiv preprint arXiv:2401.03771 (2024) 4
arXiv 2024
-
[12]
arXiv preprint arXiv:2405.14475 (2024) 2, 4
Gao, R., Chen, K., Li, Z., Hong, L., Li, Z., Xu, Q.: Magicdrive3d: Control- lable 3d generation for any-view rendering in street scenes. arXiv preprint arXiv:2405.14475 (2024) 2, 4
arXiv 2024
-
[13]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Gao, R., Chen, K., Xiao, B., Hong, L., Li, Z., Xu, Q.: Magicdrive-v2: High- resolution long video generation for autonomous driving with adaptive control. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 28135–28144 (2025) 2, 4, 9, 10, 11, 13, 14, 17, 18, 26
2025
-
[14]
In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview
Gao, R., Chen, K., Xie, E., HONG, L., Li, Z., Yeung, D.Y., Xu, Q.: Magicdrive: Street view generation with diverse 3d geometry control. In: The Twelfth Inter- national Conference on Learning Representations (2024),https://openreview. net/forum?id=sBQwvucduK2, 3, 4, 5, 9, 10, 23
2024
-
[15]
Advances in Neural Information Processing Systems37, 91560–91596 (2024)
Gao, S., Yang, J., Chen, L., Chitta, K., Qiu, Y., Geiger, A., Zhang, J., Li, H.: Vista: A generalizable driving world model with high fidelity and versatile con- trollability. Advances in Neural Information Processing Systems37, 91560–91596 (2024)
2024
-
[16]
arXiv preprint arXiv:2506.11526 (2025)
Gao, Y., Piccinini, M., Zhang, Y., Wang, D., Moller, K., Brusnicki, R., Zarrouki, B., Gambi, A., Totz, J.F., Storms, K., et al.: Foundation models in autonomous driving: A survey on scenario generation and scenario analysis. arXiv preprint arXiv:2506.11526 (2025)
arXiv 2025
-
[17]
In: Proceedings of the IEEE conference on computer vision and pattern recognition
Gatys, L.A., Ecker, A.S., Bethge, M.: Image style transfer using convolutional neural networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition. pp. 2414–2423 (2016) 4
2016
-
[18]
arXiv preprint arXiv:2503.18108 (2025)
Ge, J., Liu, Z., Fan, L., Jiang, Y., Su, J., Li, Y., Zhang, Z., Chen, S.: Unraveling the effects of synthetic data on end-to-end autonomous driving. arXiv preprint arXiv:2503.18108 (2025)
arXiv 2025
-
[19]
IEEE Robotics and Automation Letters6(3), 4947– 4954 (2021) 22
Gehrig, M., Aarents, W., Gehrig, D., Scaramuzza, D.: Dsec: A stereo event camera dataset for driving scenarios. IEEE Robotics and Automation Letters6(3), 4947– 4954 (2021) 22
2021
-
[20]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Gu, J., Hu, C., Zhang, T., Chen, X., Wang, Y., Wang, Y., Zhao, H.: Vip3d: End-to-end visual trajectory prediction via 3d agent queries. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 5496–5506 (2023) 1
2023
-
[21]
arXiv preprint arXiv:2503.15208 (2025) 2, 4, 9, 10, 23
Guo, J., Ding, Y., Chen, X., Chen, S., Li, B., Zou, Y., Lyu, X., Tan, F., Qi, X., Li, Z., et al.: Dist-4d: Disentangled spatiotemporal diffusion with metric depth for 4d driving scene generation. arXiv preprint arXiv:2503.15208 (2025) 2, 4, 9, 10, 23
arXiv 2025
-
[22]
Author et al
Guo, X., Wu, Z., Xiong, K., Xu, Z., Zhou, L., Xu, G., Xu, S., Sun, H., WANG, B., Chen, G., Ye, H., Liu, W., Wang, X.: Genesis: Multimodal driving scene 28 F. Author et al. generation with spatio-temporal and cross-modal consistency. In: The Thirty- ninth Annual Conference on Neural Information Processing Systems (2025), https://openreview.net/forum?id=Q7YnqREWLq4
2025
-
[23]
In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume
He, T., Liu, J., Cho, K., Ott, M., Liu, B., Glass, J., Peng, F.: Analyzing the forget- ting problem in pretrain-finetuning of open-domain dialogue response models. In: Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics: Main Volume. pp. 1121–1133 (2021) 5, 13
2021
-
[24]
arXiv preprint arXiv:2211.13221 (2022) 4
He, Y., Yang, T., Zhang, Y., Shan, Y., Chen, Q.: Latent video diffusion models for high-fidelity long video generation. arXiv preprint arXiv:2211.13221 (2022) 4
Pith/arXiv arXiv 2022
-
[25]
In: The Eleventh International Conference on Learning Representations (2023),https: //openreview.net/forum?id=_CDixzkzeyb4
Hertz, A., Mokady, R., Tenenbaum, J., Aberman, K., Pritch, Y., Cohen- Or, D.: Prompt-to-prompt image editing with cross-attention control. In: The Eleventh International Conference on Learning Representations (2023),https: //openreview.net/forum?id=_CDixzkzeyb4
2023
-
[26]
Advances in neural information processing systems33, 6840–6851 (2020) 4, 8
Ho, J., Jain, A., Abbeel, P.: Denoising diffusion probabilistic models. Advances in neural information processing systems33, 6840–6851 (2020) 4, 8
2020
-
[27]
arXiv preprint arXiv:2207.12598 (2022) 4
Ho, J., Salimans, T.: Classifier-free diffusion guidance. arXiv preprint arXiv:2207.12598 (2022) 4
Pith/arXiv arXiv 2022
-
[28]
arXiv preprint arXiv:2309.17080 (2023) 4
Hu, A., Russell, L., Yeo, H., Murez, Z., Fedoseev, G., Kendall, A., Shotton, J., Corrado, G.: Gaia-1: A generative world model for autonomous driving. arXiv preprint arXiv:2309.17080 (2023) 4
Pith/arXiv arXiv 2023
-
[29]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Hu, Y., Yang, J., Chen, L., Li, K., Sima, C., Zhu, X., Chai, S., Du, S., Lin, T., Wang, W., et al.: Planning-oriented autonomous driving. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 17853– 17862 (2023) 1, 3, 9, 10, 18
2023
-
[30]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Huang, Z., He, Y., Yu, J., Zhang, F., Si, C., Jiang, Y., Zhang, Y., Wu, T., Jin, Q., Chanpaisit, N., et al.: Vbench: Comprehensive benchmark suite for video generative models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 21807–21818 (2024) 14
2024
-
[31]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Islam, K., Zaheer, M.Z., Mahmood, A., Nandakumar, K.: Diffusemix: Label- preserving data augmentation with diffusion models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 27621– 27630 (2024) 2, 4
2024
-
[32]
Advances in Neural Information Processing Systems37, 74211–74232 (2024)
Jang, H.K., Kim, J., Kweon, H., Yoon, K.J.: Talos: Enhancing semantic scene completion via test-time adaptation on the line of sight. Advances in Neural Information Processing Systems37, 74211–74232 (2024)
2024
-
[33]
In: CVPR (2020)
Jaritz, M., Vu, T.H., de Charette, R., Wirbel, E., Pérez, P.: xMUDA: Cross-modal unsupervised domain adaptation for 3D semantic segmentation. In: CVPR (2020)
2020
-
[34]
In: European Conference on Computer Vision
Jeong, Y., Cho, H., Yoon, K.J.: Towards robust event-based networks for night- time via unpaired day-to-night event translation. In: European Conference on Computer Vision. pp. 286–306. Springer (2024)
2024
-
[35]
arXiv preprint arXiv:2503.22231 (2025) 4
Ji, Y., Zhu, Z., Zhu, Z., Xiong, K., Lu, M., Li, Z., Zhou, L., Sun, H., Wang, B., Lu, T.: Cogen: 3d consistent video generation via adaptive conditioning for autonomous driving. arXiv preprint arXiv:2503.22231 (2025) 4
arXiv 2025
-
[36]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Jiang, B., Chen, S., Xu, Q., Liao, B., Chen, J., Zhou, H., Zhang, Q., Liu, W., Huang, C., Wang, X.: Vad: Vectorized scene representation for efficient au- tonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 8340–8350 (2023) 1
2023
-
[37]
arXiv preprint arXiv:2504.19614 (2025) 4 Abbreviated paper title 29
Jiang, J., Hong, G., Zhang, M., Hu, H., Zhan, K., Shao, R., Nie, L.: Dive: Efficient multi-view driving scenes generation based on video diffusion transformer. arXiv preprint arXiv:2504.19614 (2025) 4 Abbreviated paper title 29
arXiv 2025
-
[38]
Advances in neural information processing systems35, 23593–23606 (2022)
Kawar, B., Elad, M., Ermon, S., Song, J.: Denoising diffusion restoration models. Advances in neural information processing systems35, 23593–23606 (2022)
2022
-
[39]
ACM Trans
Kerbl, B., Kopanas, G., Leimkühler, T., Drettakis, G.: 3d gaussian splatting for real-time radiance field rendering. ACM Trans. Graph.42(4), 139–1 (2023) 4
2023
-
[40]
In: NeurIPS 2023 Workshop on Distribution Shifts: New Frontiers with Foundation Models (2024),https: //openreview.net/forum?id=wkQy8mLIb95
Kotha, S., Springer, J., Raghunathan, A.: Understanding catastrophic forget- ting in language models via implicit inference. In: NeurIPS 2023 Workshop on Distribution Shifts: New Frontiers with Foundation Models (2024),https: //openreview.net/forum?id=wkQy8mLIb95
2023
-
[41]
In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition
Kumari, N., Zhang, B., Zhang, R., Shechtman, E., Zhu, J.Y.: Multi-concept cus- tomization of text-to-image diffusion. In: Proceedings of the IEEE/CVF confer- ence on computer vision and pattern recognition. pp. 1931–1941 (2023) 5, 13
1931
-
[42]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Li, B., Guo, J., Liu, H., Zou, Y., Ding, Y., Chen, X., Zhu, H., Tan, F., Zhang, C., Wang, T., et al.: Uniscene: Unified occupancy-centric driving scene generation. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 11971–11981 (2025) 10, 19
2025
-
[43]
In: IEEE International Conference on Robotics and Automation (ICRA)
Li, H., Yang, Z., Qian, Z., Zhao, G., Huang, Y., Yu, J., Zhou, H., Liu, L.: Duald- iff: Dual-branch diffusion model for autonomous driving with semantic fusion. In: IEEE International Conference on Robotics and Automation (ICRA). IEEE (2025),https://arxiv.org/abs/2505.018574
arXiv 2025
-
[44]
In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition
Li, J., Li, B., Tu, Z., Liu, X., Guo, Q., Juefei-Xu, F., Xu, R., Yu, H.: Light the night: A multi-condition diffusion framework for unpaired low-light enhancement in autonomous driving. In: Proceedings of the IEEE/CVF Conference on Com- puter Vision and Pattern Recognition. pp. 15205–15215 (2024) 2, 4
2024
-
[45]
In: 2022 international conference on robotics and automation (ICRA)
Li, N., Song, F., Zhang, Y., Liang, P., Cheng, E.: Traffic context aware data aug- mentation for rare object detection in autonomous driving. In: 2022 international conference on robotics and automation (ICRA). pp. 4548–4554. IEEE (2022) 4
2022
-
[46]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Li, R., Cheong, L.F., Tan, R.T.: Heavy rain image restoration: Integrating physics model and conditional adversarial learning. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 1633–1642 (2019) 11
2019
-
[47]
In: European Conference on Computer Vision
Li, X., Zhang, Y., Ye, X.: Drivingdiffusion: layout-guided multi-view driving sce- narios video generation with latent diffusion model. In: European Conference on Computer Vision. pp. 469–485. Springer (2024) 4
2024
-
[48]
arXiv preprint arXiv:2103.05422 (2021) 4
Li, X., Kou, K., Zhao, B.: Weather gan: Multi-domain weather translation using generative adversarial networks. arXiv preprint arXiv:2103.05422 (2021) 4
arXiv 2021
-
[49]
In: Proceedings of the ieee/cvf in- ternational conference on computer vision
Li, Y., Lin, Z.H., Forsyth, D., Huang, J.B., Wang, S.: Climatenerf: Extreme weather synthesis in neural radiance field. In: Proceedings of the ieee/cvf in- ternational conference on computer vision. pp. 3227–3238 (2023) 4
2023
-
[50]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Li, Z., Li, L., Zhu, J.: Read: Large-scale neural scene rendering for autonomous driving. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 37, pp. 1522–1529 (2023) 4
2023
-
[51]
arXiv preprint arXiv:2203.04600 (2022) 5
Li, Z., Ren, K., Jiang, X., Li, B., Zhang, H., Li, D.: Domain generalization using pretrained models without fine-tuning. arXiv preprint arXiv:2203.04600 (2022) 5
arXiv 2022
-
[52]
In: Proceedings of the AAAI Conference on Artificial Intelligence
Liang, Y., Yan, Z., Chen, L., Zhou, J., Yan, L., Zhong, S., Zou, X.: Driveeditor: A unified 3d information-guided framework for controllable object editing in driving scenes. In: Proceedings of the AAAI Conference on Artificial Intelligence. vol. 39, pp. 5164–5172 (2025) 4
2025
-
[53]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Liao, Y.C., Chen, J.J., Huang, C.P., Lin, C.S., Wu, M.L., Wang, Y.C.F.: Con- tinual personalization for diffusion models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 15511–15520 (2025) 5, 13 30 F. Author et al
2025
-
[54]
In: Proceedings of the 32nd ACM International Conference on Multimedia
Liu, B., Wang, K., Liu, Y., Bao, J., Han, T., Yu, J.: Mvpbev: Multi-view perspec- tive image generation from bev with test-time controllability and generalizability. In: Proceedings of the 32nd ACM International Conference on Multimedia. pp. 8393–8401 (2024) 4
2024
-
[55]
Loshchilov,I.,Hutter,F.:Decoupledweightdecayregularization.In:International Conference on Learning Representations (2019) 17
2019
-
[56]
arXiv preprint arXiv:2412.03520 (2024) 4
Lu, H., Wu, X., Wang, S., Qin, X., Zhang, X., Han, J., Zuo, W., Tao, J.: Seeing beyond views: Multi-view driving scene video generation with holistic attention. arXiv preprint arXiv:2412.03520 (2024) 4
arXiv 2024
-
[57]
In: European Conference on Computer Vision
Lu, J., Huang, Z., Yang, Z., Zhang, J., Zhang, L.: Wovogen: World volume-aware diffusion for controllable multi-camera driving scene generation. In: European Conference on Computer Vision. pp. 329–345. Springer (2024) 4
2024
-
[58]
In: Proceedings of the IEEE/CVF International Conference on Computer Vision
Lu,Y.,Ren,X.,Yang,J., Shen,T., Wu,Z.,Gao,J., Wang, Y.,Chen, S.,Chen, M., Fidler,S.,etal.:Infinicube:Unboundedandcontrollabledynamic3ddrivingscene generation with world-guided video models. In: Proceedings of the IEEE/CVF International Conference on Computer Vision. pp. 27272–27283 (2025) 4
2025
-
[59]
arXiv preprint arXiv:2409.04003 (2024) 4
Mei, J., Hu, T., Yang, X., Wen, L., Yang, Y., Wei, T., Ma, Y., Dou, M., Shi, B., Liu, Y.: Dreamforge: Motion-aware autoregressive video generation for multi-view driving scenes. arXiv preprint arXiv:2409.04003 (2024) 4
arXiv 2024
-
[60]
In: International Conference on Learning Representations (2022) 4
Meng, C., He, Y., Song, Y., Song, J., Wu, J., Zhu, J.Y., Ermon, S.: SDEdit: Guided image synthesis and editing with stochastic differential equations. In: International Conference on Learning Representations (2022) 4
2022
-
[61]
Com- munications of the ACM65(1), 99–106 (2021) 4
Mildenhall, B., Srinivasan, P.P., Tancik, M., Barron, J.T., Ramamoorthi, R., Ng, R.: Nerf: Representing scenes as neural radiance fields for view synthesis. Com- munications of the ACM65(1), 99–106 (2021) 4
2021
-
[62]
Ming, Y., Li, Y.: How does fine-tuning impact out-of-distribution detection for vision-language models? International Journal of Computer Vision132(2), 596– 609 (2024) 5
2024
-
[63]
arXiv preprint arXiv:2308.13320 (2023) 13
Mukhoti, J., Gal, Y., Torr, P.H., Dokania, P.K.: Fine-tuning can cripple your foundation model; preserving features may be the solution. arXiv preprint arXiv:2308.13320 (2023) 13
arXiv 2023
-
[64]
In: Proceedings of the Computer Vision and Pattern Recognition Conference
Ni, C., Zhao, G., Wang, X., Zhu, Z., Qin, W., Huang, G., Liu, C., Chen, Y., Wang, Y., Zhang, X., et al.: Recondreamer: Crafting world models for driving scene reconstruction via online restoration. In: Proceedings of the Computer Vision and Pattern Recognition Conference. pp. 1559–1569 (2025) 4
2025
-
[65]
arXiv preprint arXiv:2409.08248 (2024) 5, 13
Park, N., Kim, K., Shim, H.: Textboost: Towards one-shot personalization of text- to-image models via fine-tuning text encoder. arXiv preprint arXiv:2409.08248 (2024) 5, 13
Pith/arXiv arXiv 2024
-
[66]
The International Journal of Robotics Research40(4-5), 681–690 (2021) 22
Pitropov, M., Garcia, D.E., Rebello, J., Smart, M., Wang, C., Czarnecki, K., Waslander, S.: Canadian adverse driving conditions dataset. The International Journal of Robotics Research40(4-5), 681–690 (2021) 22
2021
-
[67]
Qian, C., Guo, Y., Mo, Y., Li, W.: Weatherdg: Llm-assisted procedural weather generation for domain-generalized semantic segmentation. IEEE Robotics and Automation Letters10(6), 5919–5926 (2025).https://doi.org/10.1109/LRA. 2025.35598214
work page doi:10.1109/lra 2025
-
[68]
In: International conference on machine learning
Radford,A.,Kim,J.W.,Hallacy,C.,Ramesh,A.,Goh,G.,Agarwal,S.,Sastry,G., Askell, A., Mishkin, P., Clark, J., et al.: Learning transferable visual models from natural language supervision. In: International conference on machine learning. pp. 8748–8763. PmLR (2021) 14, 19 Abbreviated paper title 31
2021
-
[69]
In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV)
Ram, S., Neiman, T., Feng, Q., Stuart, A., Tran, S., Chilimbi, T.: Dreamblend: Advancing personalized fine-tuning of text-to-image diffusion models. In: 2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV). pp. 3614–3623. IEEE (2025) 13
2025
-
[70]
Ren, X., Lu, Y., Cao, T., Gao, R., Huang, S., Sabour, A., Shen, T., Pfaff, T., Wu, J.Z., Chen, R., et al.: Cosmos-drive-dreams: Scalable synthetic driving data generationwithworldfoundationmodels.arXivpreprintarXiv:2506.09042(2025)
arXiv 2025
-
[71]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Rombach, R., Blattmann, A., Lorenz, D., Esser, P., Ommer, B.: High-resolution image synthesis with latent diffusion models. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 10684–10695 (2022) 2, 4, 5, 9, 17
2022
-
[72]
In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision
Rothmeier, T., Huber, W., Knoll, A.C.: Time to shine: Fine-tuning object de- tection models with synthetic adverse weather images. In: Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision. pp. 4447– 4456 (2024) 4
2024
-
[73]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Ruiz, N., Li, Y., Jampani, V., Pritch, Y., Rubinstein, M., Aberman, K.: Dream- booth: Fine tuning text-to-image diffusion models for subject-driven generation. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 22500–22510 (2023) 13
2023
-
[74]
arXiv preprint arXiv:2503.20523 (2025) 4
Russell, L., Hu, A., Bertoni, L., Fedoseev, G., Shotton, J., Arani, E., Corrado, G.: Gaia-2: A controllable multi-view generative world model for autonomous driving. arXiv preprint arXiv:2503.20523 (2025) 4
Pith/arXiv arXiv 2025
-
[75]
In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition
Ryu, K., Hwang, S., Park, J.: Instant domain augmentation for lidar semantic segmentation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. pp. 9350–9360 (2023) 4
2023
-
[76]
arXiv preprint arXiv:2310.15110 (2023)
Shi, R., Chen, H., Zhang, Z., Liu, M., Xu, C., Wei, X., Chen, L., Zeng, C., Su, H.: Zero123++: a single image to consistent multi-view diffusion base model. arXiv preprint arXiv:2310.15110 (2023)
Pith/arXiv arXiv 2023
-
[77]
arXiv:2010.02502 (October 2020),https://arxiv.org/abs/2010.025024
Song, J., Meng, C., Ermon, S.: Denoising diffusion implicit models. arXiv:2010.02502 (October 2020),https://arxiv.org/abs/2010.025024
Pith/arXiv arXiv 2010
-
[78]
In: International Conference on Learning Representations (2021),https : / / openreview.net/forum?id=PxTIG12RRHS4
Song, Y., Sohl-Dickstein, J., Kingma, D.P., Kumar, A., Ermon, S., Poole, B.: Score-based generative modeling through stochastic differential equations. In: International Conference on Learning Representations (2021),https : / / openreview.net/forum?id=PxTIG12RRHS4
2021
-
[79]
In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition
Sun, P., Kretzschmar, H., Dotiwalla, X., Chouard, A., Patnaik, V., Tsui, P., Guo, J., Zhou, Y., Chai, Y., Caine, B., et al.: Scalability in perception for autonomous driving: Waymo open dataset. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. pp. 2446–2454 (2020) 2, 22
2020
-
[80]
In: 2025 IEEE International Conference on Robotics and Automation (ICRA)
Sun, W., Lin, X., Shi, Y., Zhang, C., Wu, H., Zheng, S.: Sparsedrive: End-to-end autonomous driving via sparse scene representation. In: 2025 IEEE International Conference on Robotics and Automation (ICRA). pp. 8795–8801. IEEE (2025) 1, 11, 18
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.