Automating SKILL.md Generation for Computer-Using Agents via Interaction Trajectory Mining
Pith reviewed 2026-06-26 17:00 UTC · model grok-4.3
The pith
Trajectory mining from GUI interactions produces readable skill clusters but does not reliably improve agent policies on new tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
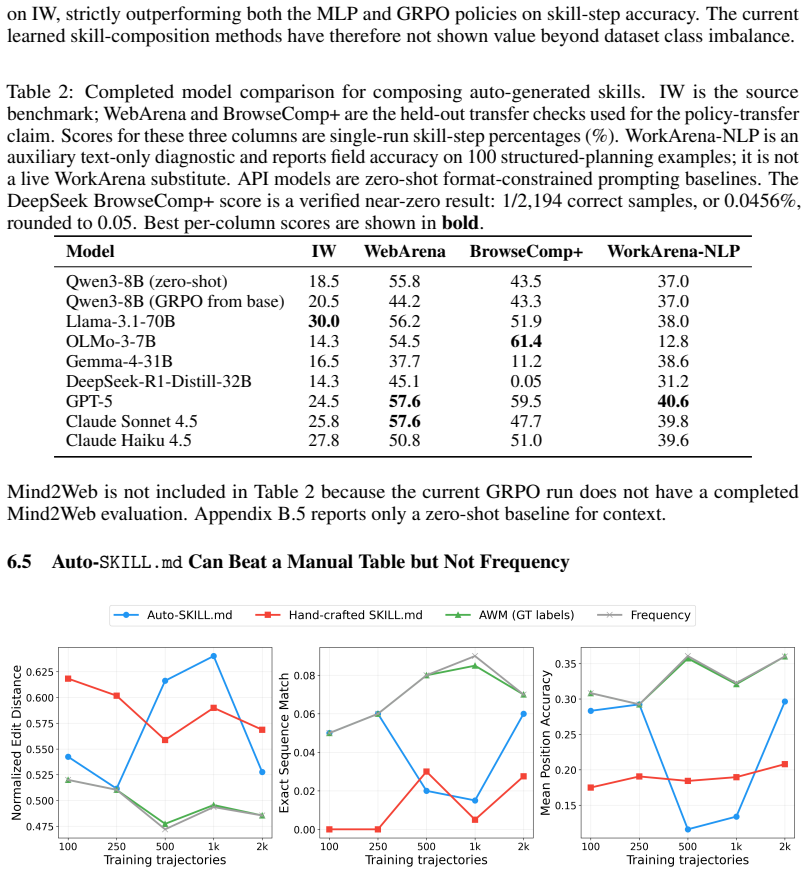
Explicit skill libraries make computer-using agents easier to inspect, but it remains unclear whether such libraries can be mined from interaction data in a way that improves downstream policies. We study this question through a three-stage pipeline that segments GUI trajectories, clusters segments into candidate skills, and trains a skill-aware policy from the resulting annotations. The mined clusters are readable on the source benchmark: five of eight clusters have at least 0.95 purity against InteraSkill Workflows labels. However, readability does not imply transfer. GRPO improves IW skill-step accuracy only from 18.5% to 20.5%, leaves BrowseComp+ essentially unchanged, and underperforms
What carries the argument
A three-stage pipeline that segments GUI trajectories, clusters segments into candidate skills, and trains a skill-aware policy from the annotations.
If this is right
- Five of eight mined clusters achieve at least 0.95 purity against InteraSkill Workflows labels on the source benchmark.
- GRPO training on the mined skills raises skill-step accuracy on IW from 18.5% to 20.5%.
- Performance on the BrowseComp+ benchmark remains essentially unchanged after training.
- The skill-aware policy underperforms simple frequency-based priors on several source-domain metrics.
Where Pith is reading between the lines
- A boundary detector that more accurately identifies skill transitions could allow the same clustering step to produce clusters that support larger policy gains.
- Replacing the orderless segment representation with one that preserves sequence order might capture dependencies that current clusters miss.
- Switching from an offline reward model to one that is updated during policy training could reduce the gap to frequency priors observed on source metrics.
- Applying the pipeline to additional held-out domains beyond IW and BrowseComp+ would test whether the reported insufficiency is specific to those benchmarks.
Load-bearing premise
High purity of mined clusters against InteraSkill Workflows labels indicates transferable skills that will improve policies on held-out benchmarks like BrowseComp+.
What would settle it
A controlled experiment that keeps all other components fixed but replaces the current boundary detector with one that achieves near-perfect segment boundaries, then measures whether GRPO training produces gains on BrowseComp+ larger than the observed zero change.
Figures

read the original abstract
Explicit skill libraries make computer-using agents easier to inspect, but it remains unclear whether such libraries can be mined from interaction data in a way that improves downstream policies. We study this question through a three-stage pipeline that segments GUI trajectories, clusters segments into candidate skills, and trains a skill-aware policy from the resulting annotations. The mined clusters are readable on the source benchmark: five of eight clusters have at least 0.95 purity against InteraSkill Workflows labels. However, readability does not imply transfer. GRPO improves IW skill-step accuracy only from 18.5\% to 20.5\%, leaves BrowseComp+ essentially unchanged, and underperforms trivial frequency priors on key source-domain metrics. We therefore present the method as a diagnostic study: trajectory mining can expose inspectable skill structure, but the current boundary detector, orderless segment representation, and offline reward model are insufficient for reliable cross-domain policy improvement.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper describes a three-stage pipeline (trajectory segmentation, segment clustering into candidate skills, and GRPO-based skill-aware policy training) for automatically generating inspectable skill libraries from GUI interaction data. It reports that five of eight mined clusters achieve ≥0.95 purity against InteraSkill Workflows labels on the source domain, yet GRPO yields only a 2-point gain in IW skill-step accuracy (18.5% → 20.5%), no improvement on BrowseComp+, and underperforms frequency priors; the work is framed as a diagnostic study showing that current boundary detection, orderless segment representations, and offline rewards are insufficient for reliable cross-domain policy gains.
Significance. If the negative result is robust, the paper supplies a concrete falsification that high source-domain cluster purity does not imply transferable policy improvement, identifying three specific pipeline bottlenecks. This diagnostic framing is useful for the computer-using agents literature and avoids overclaiming positive transfer. The explicit comparison against both external labels and trivial baselines strengthens the evidentiary value.
major comments (2)
- [§4] §4 (Results): the central insufficiency claim rests on the GRPO vs. frequency-prior comparison and the +2% IW gain, yet the text provides only point estimates with no error bars, run-to-run variance, or statistical significance tests; without these, it is impossible to judge whether the observed gaps are reliable enough to support the conclusion that the three pipeline components are insufficient.
- [§3.2–3.3] §3.2–3.3 (Boundary detector and segment representation): the paper identifies these as load-bearing limitations but reports no ablation that isolates their individual contributions to the transfer failure (e.g., replacing the orderless representation with an ordered one while keeping the same clusters); the diagnostic conclusion therefore remains partly qualitative.
minor comments (2)
- [Abstract, §4] Abstract and §4: the purity and accuracy numbers are given without reference to the exact number of trajectories or episodes used, making it hard to assess sample size.
- [Figures] Figure captions: several figures lack axis labels or legend entries that would allow a reader to verify the reported purity and accuracy values directly from the plots.
Simulated Author's Rebuttal
We thank the referee for the positive assessment of the work's significance and the recommendation for minor revision. The comments identify key areas where additional rigor can strengthen the diagnostic claims regarding the pipeline's limitations. Below we provide point-by-point responses.
read point-by-point responses
-
Referee: [§4] §4 (Results): the central insufficiency claim rests on the GRPO vs. frequency-prior comparison and the +2% IW gain, yet the text provides only point estimates with no error bars, run-to-run variance, or statistical significance tests; without these, it is impossible to judge whether the observed gaps are reliable enough to support the conclusion that the three pipeline components are insufficient.
Authors: We agree with this assessment. The current manuscript reports only single-run point estimates for the skill-step accuracy improvements. In the revised version, we will rerun the GRPO training multiple times to compute means and standard deviations, and include statistical tests (such as Wilcoxon signed-rank tests) comparing against the frequency prior baseline. This will allow readers to better evaluate the reliability of the +2% gain and the underperformance relative to priors. revision: yes
-
Referee: [§3.2–3.3] §3.2–3.3 (Boundary detector and segment representation): the paper identifies these as load-bearing limitations but reports no ablation that isolates their individual contributions to the transfer failure (e.g., replacing the orderless representation with an ordered one while keeping the same clusters); the diagnostic conclusion therefore remains partly qualitative.
Authors: We acknowledge that the identification of specific bottlenecks is based on the overall experimental outcomes rather than isolated ablations. Conducting the suggested ablations would require substantial additional engineering and compute to implement ordered segment representations and alternative boundary detectors while controlling for other variables. As this is framed as a diagnostic study highlighting insufficiencies, we believe the current evidence suffices to motivate future work on these components. We will revise the text to more clearly state the qualitative basis of these claims and their implications. revision: partial
Circularity Check
No significant circularity
full rationale
The paper is framed explicitly as a diagnostic study: it mines clusters from trajectories, reports high source-domain purity (0.95 on five of eight clusters vs. InteraSkill labels), then shows that the resulting annotations yield only marginal GRPO gains (+2% IW accuracy) and no BrowseComp+ improvement while underperforming frequency priors. This negative result is supported by direct empirical comparisons to external baselines and does not rely on any derivation that reduces a claimed prediction or uniqueness result to fitted parameters, self-citations, or definitional equivalence. No load-bearing step invokes the enumerated circularity patterns.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
WebShop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
Shunyu Yao, Howard Chen, John Yang, and Karthik Narasimhan. WebShop: Towards scalable real-world web interaction with grounded language agents.Advances in Neural Information Processing Systems, 35:20744–20757, 2022
2022
-
[2]
Mind2Web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
Xiang Deng, Yu Gu, Boyuan Zheng, Shijie Chen, Sam Stevens, Boshi Wang, Huan Sun, and Yu Su. Mind2Web: Towards a generalist agent for the web.Advances in Neural Information Processing Systems, 36:28091–28114, 2023
2023
-
[3]
Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig
Shuyan Zhou, Frank F. Xu, Hao Zhu, Xuhui Zhou, Robert Lo, Abishek Sridhar, Xianyi Cheng, Yonatan Bisk, Daniel Fried, Uri Alon, and Graham Neubig. WebArena: A realistic web environment for building autonomous agents. InInternational Conference on Learning Representations, 2024. 9
2024
-
[4]
VisualWebArena: Evaluating multimodal agents on realistic visual web tasks
Jing Yu Koh, Robert Lo, Lawrence Jang, Vikram Duvvur, Ming Chong Lim, Po-Yu Huang, Graham Neubig, Shuyan Zhou, Ruslan Salakhutdinov, and Daniel Fried. VisualWebArena: Evaluating multimodal agents on realistic visual web tasks. InProceedings of the 62nd Annual Meeting of the Association for Computational Linguistics, 2024
2024
-
[5]
Laradji, Manuel Del Verme, Tom Marty, Leo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste
Alexandre Drouin, Maxime Gasse, Massimo Caccia, Issam H. Laradji, Manuel Del Verme, Tom Marty, Leo Boisvert, Megh Thakkar, Quentin Cappart, David Vazquez, Nicolas Chapados, and Alexandre Lacoste. WorkArena: How capable are web agents at solving common knowledge work tasks? InInternational Conference on Machine Learning, 2024
2024
-
[6]
OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments
Tianbao Xie, Danyang Zhang, Jixuan Chen, Xiaochuan Li, Siheng Zhao, Ruisheng Cao, Toh Jing Hua, Zhoujun Cheng, Dongchan Shin, Fangyu Lei, Yitao Liu, Yiheng Xu, Shuyan Zhou, Silvio Savarese, Caiming Xiong, Victor Zhong, and Tao Yu. OSWorld: Benchmarking multimodal agents for open-ended tasks in real computer environments. InAdvances in Neural Information P...
2024
-
[7]
OpAgent: Operator agent for web navigation
Yuyu Guo, Wenjie Yang, Siyuan Yang, et al. OpAgent: Operator agent for web navigation. arXiv preprint arXiv:2602.13559, 2026
Pith/arXiv arXiv 2026
-
[8]
OpenCUA: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
Xinyuan Wang, Bowen Wang, Dunjie Lu, et al. OpenCUA: Open foundations for computer-use agents.arXiv preprint arXiv:2508.09123, 2025
arXiv 2025
-
[9]
Yuhao Yang, Zhen Yang, Zi-Yi Dou, et al. UltraCUA: A foundation model for computer use agents with hybrid action.arXiv preprint arXiv:2510.17790, 2025
Pith/arXiv arXiv 2025
-
[10]
Yuexing Hao, Zeyu Liu, Bob Riter, and Saleh Kalantari. Advancing patient-centered shared decision-making with AI systems for older adult cancer patients. InProceedings of the CHI Conference on Human Factors in Computing Systems, pages 1–19, 2024. doi: 10.1145/3613904. 3642353
-
[11]
Waddle, Brian J
Yuexing Hao, Jason Holmes, Mark R. Waddle, Brian J. Davis, Nathan Y . Yu, Kristin Vickers, Heather Preston, Drew Margolin, Corinna E. Lockenhoff, Aditya Vashistha, Saleh Kalantari, Marzyeh Ghassemi, and Wei Liu. Personalizing prostate cancer education for patients using an EHR-integrated LLM agent.npj Digital Medicine, 2025
2025
-
[12]
Yuexing Hao, Kumail Alhamoud, Hyewon Jeong, Haoran Zhang, Isha Puri, Philip Torr, Mike Schaekermann, Ariel D. Stern, and Marzyeh Ghassemi. MedPAIR: Measuring physicians and AI relevance alignment in medical question answering.arXiv preprint arXiv:2505.24040, 2025
arXiv 2025
-
[13]
Xiaomin Li, Mingye Gao, Yuexing Hao, Taoran Li, Guangya Wan, Zihan Wang, and Yijun Wang. MedGUIDE: Benchmarking clinical decision-making in large language models.arXiv preprint arXiv:2505.11613, 2025
arXiv 2025
-
[14]
Selection of LLM fine-tuning data based on orthogonal rules.arXiv preprint arXiv:2410.04715, 2024
Xiaomin Li, Mingye Gao, Zhiwei Zhang, Chang Yue, and Hong Hu. Selection of LLM fine-tuning data based on orthogonal rules.arXiv preprint arXiv:2410.04715, 2024
arXiv 2024
-
[15]
Data-adaptive safety rules for training reward models.arXiv preprint arXiv:2501.15453, 2025
Xiaomin Li, Mingye Gao, Zhiwei Zhang, Jingxuan Fan, and Weiyu Li. Data-adaptive safety rules for training reward models.arXiv preprint arXiv:2501.15453, 2025
arXiv 2025
-
[16]
Zora Zhiruo Wang, Jiayuan Mao, Daniel Fried, and Graham Neubig. Agent workflow memory. arXiv preprint arXiv:2409.07429, 2024
Pith/arXiv arXiv 2024
-
[17]
Boyuan Zheng, Michael Y . Fatemi, Xiaolong Jin, Zora Zhiruo Wang, Apurva Gandhi, Yueqi Song, Yu Gu, Jayanth Srinivasa, Gaowen Liu, Graham Neubig, and Yu Su. SkillWeaver: Web agents can self-improve by discovering and honing skills.arXiv preprint arXiv:2504.07079, 2025
Pith/arXiv arXiv 2025
-
[18]
AutoManual: Constructing instruction manuals by LLM agents via interactive environmental learning
Minghao Chen, Yihang Li, Yanting Yang, Shiyu Yu, Binbin Lin, and Xiaofei He. AutoManual: Constructing instruction manuals by LLM agents via interactive environmental learning. In Advances in Neural Information Processing Systems, 2024
2024
-
[19]
Tarr, William W
Gabriel Sarch, Lawrence Jang, Michael J. Tarr, William W. Cohen, Kenneth Marino, and Katerina Fragkiadaki. VLM agents generate their own memories: Distilling experience into embodied programs of thought. InAdvances in Neural Information Processing Systems, 2024. 10
2024
-
[20]
Guangyi Liu, Pengxiang Zhao, Liang Liu, Zhiyong Chen, Yuning Chai, Shuai Ren, Hao Wang, Shixiang He, and Wanli Meng. LearnAct: Few-shot mobile GUI agent with a unified demonstration benchmark.arXiv preprint arXiv:2504.13805, 2025
arXiv 2025
-
[21]
Open-world skill discovery from unsegmented demonstration videos
Jingwen Deng, Zihao Wang, Shaofei Cai, Anji Liu, and Yitao Liang. Open-world skill discovery from unsegmented demonstration videos. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 10708–10718, 2025
2025
-
[22]
Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
Richard S Sutton, Doina Precup, and Satinder Singh. Between MDPs and semi-MDPs: A framework for temporal abstraction in reinforcement learning.Artificial intelligence, 112(1-2): 181–211, 1999
1999
-
[23]
The option-critic architecture
Pierre-Luc Bacon, Jean Harb, and Doina Precup. The option-critic architecture. InProceedings of the AAAI Conference on Artificial Intelligence, 2017
2017
-
[24]
Kulkarni, Karthik R
Tejas D. Kulkarni, Karthik R. Narasimhan, Ardavan Saeedi, and Joshua B. Tenenbaum. Hierar- chical deep reinforcement learning: Integrating temporal abstraction and intrinsic motivation. InAdvances in Neural Information Processing Systems, 2016
2016
-
[25]
FeUdal networks for hierarchical reinforcement learning
Alexander Sasha Vezhnevets, Simon Osindero, Tom Schaul, Nicolas Heess, Max Jaderberg, David Silver, and Koray Kavukcuoglu. FeUdal networks for hierarchical reinforcement learning. InProceedings of the 34th International Conference on Machine Learning, pages 3540–3549. PMLR, 2017
2017
-
[26]
Data-efficient hierarchical reinforcement learning
Ofir Nachum, Shixiang Gu, Honglak Lee, and Sergey Levine. Data-efficient hierarchical reinforcement learning. InAdvances in Neural Information Processing Systems, 2018
2018
-
[27]
Learning abstract options
Matthew Riemer, Miao Liu, and Gerald Tesauro. Learning abstract options. InAdvances in Neural Information Processing Systems, 2018
2018
-
[28]
Hierarchical reinforcement learning with advantage-based auxiliary rewards
Siyuan Li, Rui Wang, Minxue Tang, and Chongjie Zhang. Hierarchical reinforcement learning with advantage-based auxiliary rewards. InAdvances in Neural Information Processing Systems, 2019
2019
-
[29]
Meta learning shared hierarchies
Kevin Frans, Jonathan Ho, Xi Chen, Pieter Abbeel, and John Schulman. Meta learning shared hierarchies. InInternational Conference on Learning Representations, 2018
2018
-
[30]
OPAL: Offline primitive discovery for accelerating offline reinforcement learning
Anurag Ajay, Aviral Kumar, Pulkit Agrawal, Sergey Levine, and Ofir Nachum. OPAL: Offline primitive discovery for accelerating offline reinforcement learning. InInternational Conference on Learning Representations, 2021
2021
-
[31]
Variational intrinsic control
Karol Gregor, Danilo Jimenez Rezende, and Daan Wierstra. Variational intrinsic control. In International Conference on Learning Representations, 2017
2017
-
[32]
Diversity is all you need: Learning skills without a reward function
Benjamin Eysenbach, Abhishek Gupta, Julian Ibarz, and Sergey Levine. Diversity is all you need: Learning skills without a reward function. InInternational Conference on Learning Representations, 2019
2019
-
[33]
Dynamics- aware unsupervised discovery of skills
Archit Sharma, Shixiang Gu, Sergey Levine, Vikash Kumar, and Karol Hausman. Dynamics- aware unsupervised discovery of skills. InInternational Conference on Learning Representa- tions, 2020
2020
-
[34]
Unsupervised reinforcement learning with contrastive intrinsic control
Michael Laskin, Hao Liu, Xue Bin Peng, Denis Yarats, Aravind Rajeswaran, and Pieter Abbeel. Unsupervised reinforcement learning with contrastive intrinsic control. InAdvances in Neural Information Processing Systems, 2022
2022
-
[35]
Learning actionable representations with goal-conditioned policies
Dibya Ghosh, Abhishek Gupta, and Sergey Levine. Learning actionable representations with goal-conditioned policies. InInternational Conference on Learning Representations, 2019
2019
-
[36]
The information geometry of unsupervised reinforcement learning
Benjamin Eysenbach, Ruslan Salakhutdinov, and Sergey Levine. The information geometry of unsupervised reinforcement learning. InInternational Conference on Learning Representations, 2022. 11
2022
-
[37]
DigiRL: Training in-the-wild device-control agents with autonomous reinforcement learning
Hao Bai, Yifei Zhou, Mert Cemri, Jiayi Pan, Alane Suhr, Sergey Levine, and Aviral Kumar. DigiRL: Training in-the-wild device-control agents with autonomous reinforcement learning. InAdvances in Neural Information Processing Systems, 2024
2024
-
[38]
WebRL: Training LLM web agents via self-evolving online curriculum reinforcement learning
Zehan Qi, Xiao Liu, Iat Long Iong, Hanyu Lai, Xueqiao Sun, Wenhan Zhao, Yuxiao Yang, Xiao Yang, Jiadai Sun, Shuntian Yao, Tianjie Zhang, Wei Xu, Jie Tang, and Yuxiao Dong. WebRL: Training LLM web agents via self-evolving online curriculum reinforcement learning. InInternational Conference on Learning Representations, 2025
2025
-
[39]
AgentTrek: Agent trajectory synthesis via guiding replay with web tutorials
Yiheng Xu, Dunjie Lu, Zhennan Shen, Junli Wang, Zekun Wang, Yuchen Mao, Caiming Xiong, and Tao Yu. AgentTrek: Agent trajectory synthesis via guiding replay with web tutorials. In International Conference on Learning Representations, 2025
2025
-
[40]
OS-Genesis: Automating GUI agent trajectory construction via reverse task synthesis
Qiushi Sun, Kanzhi Cheng, Zichen Ding, Chuanyang Jin, Yian Wang, Fangzhi Xu, Zhenyu Wu, Chengyou Jia, Liheng Chen, Zhoumianze Liu, Ben Kao, Guohao Li, Junxian He, Yu Qiao, and Zhiyong Wu. OS-Genesis: Automating GUI agent trajectory construction via reverse task synthesis. InProceedings of the 63rd Annual Meeting of the Association for Computational Lingui...
2025
-
[41]
Proposer-agent-evaluator (PAE): Autonomous skill discovery for foundation model internet agents
Yifei Zhou, Qianlan Yang, Kaixiang Lin, Min Bai, Xiong Zhou, Yu-Xiong Wang, Sergey Levine, and Erran Li. Proposer-agent-evaluator (PAE): Autonomous skill discovery for foundation model internet agents. InProceedings of the 42nd International Conference on Machine Learning, 2025
2025
-
[42]
Yu Tian, Jiawei Chen, Lifan Zheng, Mingxiang Tao, Xinyi Zeng, Zhaoxia Yin, Hang Su, and Xian Sun. Skills-coach: A self-evolving skill optimizer via training-free GRPO.arXiv preprint arXiv:2604.27488, 2026
Pith/arXiv arXiv 2026
-
[43]
Selective review of offline change point detection methods
Charles Truong, Laurent Oudre, and Nicolas Vayatis. Selective review of offline change point detection methods.Signal Processing, 167:107299, 2020. doi: 10.1016/j.sigpro.2019.107299
-
[44]
D. C. Dowson and B. V . Landau. The Fréchet distance between multivariate normal distributions. Journal of Multivariate Analysis, 12(3):450–455, 1982
1982
-
[45]
Computational optimal transport: With applications to data science.Foundations and Trends in Machine Learning, 11(5–6):355–607, 2019
Gabriel Peyré and Marco Cuturi. Computational optimal transport: With applications to data science.Foundations and Trends in Machine Learning, 11(5–6):355–607, 2019
2019
-
[46]
Sinkhorn distances: Lightspeed computation of optimal transportation distances
Marco Cuturi. Sinkhorn distances: Lightspeed computation of optimal transportation distances. InAdvances in Neural Information Processing Systems, pages 2292–2300, 2013
2013
-
[47]
held-out benchmark correctness
Prannay Khosla, Piotr Teterwak, Chen Wang, Aaron Sarna, Yonglong Tian, Phillip Isola, Aaron Maschinot, Ce Liu, and Dilip Krishnan. Supervised contrastive learning. InAdvances in Neural Information Processing Systems, 2020. 12 A Appendix A.1 Additional GRPO Training Sessions We also run a scale-control GRPO session on Llama-3.1-70B-Instruct with quantized ...
arXiv 2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.