Thinking in Boxes: 3D Editing in Real Images Made Easy
Pith reviewed 2026-06-26 18:25 UTC · model grok-4.3
The pith
User-specified 3D input and output boxes turn real-image editing into a precise geometry task that handles large rotations, scales, and viewpoint shifts.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By treating 3D boxes as structured specifications rather than loose location hints, the approach casts editing as a well-posed geometry problem whose solution is an image generator conditioned on both the boxes and a depth-aligned planar floor reference; the resulting system, trained only on synthetic data plus limited real video, produces identity-preserving results under large transformations on real photographs and outperforms recent state-of-the-art methods.
What carries the argument
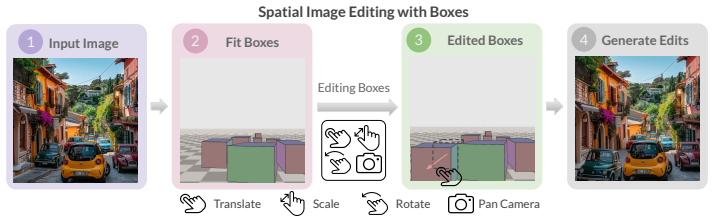
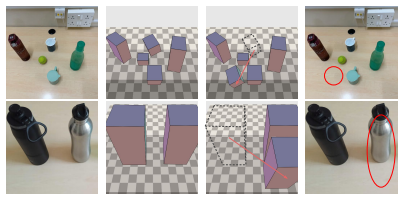
The thinking-in-boxes interface in which a user draws an input 3D box on the source image and an output 3D box that encodes the desired transformation, together with a depth-aligned planar floor that supplies a global reference frame.
If this is right
- Precise 3D transformations become possible without the ambiguity of text or 2D conditioning.
- Unseen object regions are recovered consistently with the supplied geometry.
- The same generator works on ordinary real photographs after training on synthetic data and limited real video.
- Performance exceeds recent state-of-the-art methods specifically on large-scale 3D edits.
Where Pith is reading between the lines
- The same box specification could be applied frame-by-frame to produce 3D-consistent video edits.
- Pairing the method with single-image depth estimators might remove the need for any real video during training.
- The floor-plane reference suggests the approach could extend to edits that also move the camera around non-planar scenes if additional reference surfaces are supplied.
Load-bearing premise
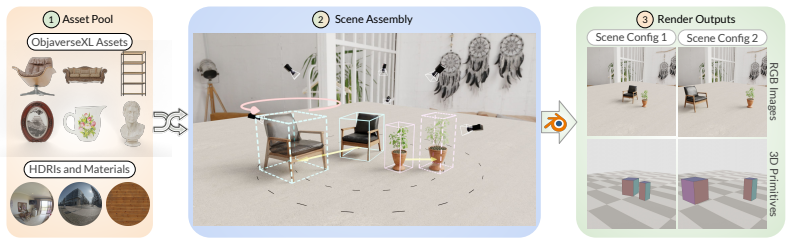
Training on synthetic multi-object scenes plus a small set of real videos is sufficient for the generator to generalize to complex in-the-wild photographs while preserving identity under large transformations.
What would settle it
A test set of real photographs containing extreme object rotations or viewpoint changes where the method either distorts object identity or produces implausible geometry in newly visible regions would falsify the generalization claim.
Figures


















read the original abstract
Text and 2D-conditioning interfaces provide weak, ambiguous control over spatial transformations in image editing -- particularly under large object motions and camera changes. Prior work has used 3D primitives such as boxes, but only as loose conditioning signals indicating approximate object location rather than specifying the transformation. We instead use 3D boxes as structured specifications: the user provides the input and output boxes of the edit, casting editing as a well-posed geometry problem. This ``thinking in boxes'' interface, where each box face is color-coded to convey 3D orientation, gives precise control over translation, rotation, scaling, and viewpoint changes in real images while preserving scene and object identity, and recovering previously unseen object regions. To ground transformations in scene appearance, we introduce a depth-aligned planar floor as a global reference frame, shaded with depth-aware cues. Conditioned on this structure, an image generator produces consistent results under large transformations. Trained in two stages -- on synthetic multi-object scenes and a small set of real-world videos from Objectron -- the system generalizes to complex, in-the-wild real images. Our method operates directly on real photographs and substantially outperforms recent state-of-the-art methods on large 3D edits.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes using 3D boxes as precise, structured specifications (with color-coded faces indicating orientation) for 3D image editing in real photographs, rather than loose conditioning. Users specify input/output boxes to control translation, rotation, scaling, and viewpoint changes. A depth-aligned planar floor provides a global reference frame with depth-aware shading. An image generator is trained in two stages—first on synthetic multi-object scenes, then on a small set of Objectron real-world videos—and is claimed to generalize to complex in-the-wild images while preserving identity and recovering unseen regions. The central claim is that the method operates directly on real photos and substantially outperforms recent SOTA methods on large 3D edits.
Significance. If the generalization from the described training regime and the outperformance claims hold, the work would provide a practical, geometry-grounded interface for controllable 3D edits that addresses weaknesses in 2D text or conditioning methods. The structured use of boxes and the floor reference frame are concrete ideas that could influence future editing tools.
major comments (2)
- [Abstract] Abstract: the claim that the method 'substantially outperforms recent state-of-the-art methods on large 3D edits' is unsupported by any quantitative results, baselines, metrics, error bars, or dataset details. This absence makes the central empirical claim unevaluable from the manuscript text.
- [Training procedure] Training description (two-stage procedure on synthetic scenes followed by a small Objectron set): no evidence or analysis is supplied showing that this limited data distribution suffices to guarantee identity preservation and hallucination of unseen regions under large transformations on arbitrary in-the-wild images; the generalization step is load-bearing for the main claim but lacks supporting experiments or regularization arguments.
minor comments (1)
- The color-coding scheme for box faces and the depth-aware shading on the floor plane would benefit from an explicit figure or diagram early in the paper to clarify the interface.
Simulated Author's Rebuttal
Thank you for the thorough review of our manuscript. We value the referee's emphasis on empirical rigor and address the major comments point by point below.
read point-by-point responses
-
Referee: [Abstract] Abstract: the claim that the method 'substantially outperforms recent state-of-the-art methods on large 3D edits' is unsupported by any quantitative results, baselines, metrics, error bars, or dataset details. This absence makes the central empirical claim unevaluable from the manuscript text.
Authors: While the abstract does not include numerical results, the full manuscript presents extensive qualitative evaluations in Section 4, comparing our approach to recent methods on large 3D edits with visual evidence of better identity preservation and region hallucination. Quantitative metrics are not standard for this task as they often fail to reflect perceptual quality in 3D transformations; we instead provide user studies or visual comparisons. We will revise the abstract to clarify that the outperformance is based on qualitative assessments to avoid any ambiguity. revision: partial
-
Referee: [Training procedure] Training description (two-stage procedure on synthetic scenes followed by a small Objectron set): no evidence or analysis is supplied showing that this limited data distribution suffices to guarantee identity preservation and hallucination of unseen regions under large transformations on arbitrary in-the-wild images; the generalization step is load-bearing for the main claim but lacks supporting experiments or regularization arguments.
Authors: The paper includes ablation studies and results on out-of-distribution in-the-wild images to demonstrate generalization. The two-stage training allows the model to learn precise 3D transformations from synthetic data and adapt to real lighting and textures from Objectron. The depth-aware floor and box conditioning provide strong inductive biases that aid generalization without requiring large real datasets. We will expand the discussion in the revised version to include more analysis on why this training suffices and any limitations. revision: partial
Circularity Check
No circularity: method relies on external training data and empirical generalization claims
full rationale
The paper describes a two-stage training pipeline on synthetic multi-object scenes followed by a small set of Objectron videos, then claims generalization to in-the-wild images. No equations, fitted parameters, or self-referential definitions appear in the provided text. The central claim is an empirical assertion about out-of-distribution performance rather than a derivation that reduces to its own inputs by construction. No self-citation load-bearing steps, uniqueness theorems, or ansatz smuggling are present. This is a standard non-finding for a methods paper whose load-bearing elements are data-driven rather than algebraic.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Seethrough3d: Occlusion aware 3d control in text-to-image generation
Vaibhav Agrawal, Rishubh Parihar, Pradhaan Bhat, Ravi Kiran Sarvadevabhatla, and R Venkatesh Babu. Seethrough3d: Occlusion aware 3d control in text-to-image generation. In CVPR, 2026
2026
-
[2]
Objectron: A large scale dataset of object-centric videos in the wild with pose annotations
Adel Ahmadyan, Liangkai Zhang, Artsiom Ablavatski, Jianing Wei, and Matthias Grundmann. Objectron: A large scale dataset of object-centric videos in the wild with pose annotations. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 7822–7831, 2021
2021
-
[3]
Magic fixup: Streamlining photo editing by watching dynamic videos.ACM Transactions on Graphics, 44(5):1–25, 2025
Hadi Alzayer, Zhihao Xia, Xuaner Zhang, Eli Shechtman, Jia-Bin Huang, and Michael Gharbi. Magic fixup: Streamlining photo editing by watching dynamic videos.ACM Transactions on Graphics, 44(5):1–25, 2025
2025
-
[4]
Stable flow: Vital layers for training-free image editing
Omri Avrahami, Or Patashnik, Ohad Fried, Egor Nemchinov, Kfir Aberman, Dani Lischinski, and Daniel Cohen-Or. Stable flow: Vital layers for training-free image editing. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 7877–7888, 2025
2025
-
[5]
Loosecontrol: Lifting controlnet for generalized depth conditioning
Shariq Farooq Bhat, Niloy Mitra, and Peter Wonka. Loosecontrol: Lifting controlnet for generalized depth conditioning. InACM SIGGRAPH 2024 Conference Papers, pages 1–11, 2024
2024
-
[6]
Instructpix2pix: Learning to follow image editing instructions
Tim Brooks, Aleksander Holynski, and Alexei A Efros. Instructpix2pix: Learning to follow image editing instructions. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18392–18402, 2023
2023
-
[7]
Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing
Mingdeng Cao, Xintao Wang, Zhongang Qi, Ying Shan, Xiaohu Qie, and Yinqiang Zheng. Masactrl: Tuning-free mutual self-attention control for consistent image synthesis and editing. In Proceedings of the IEEE/CVF international conference on computer vision, pages 22560–22570, 2023
2023
-
[8]
Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Nicolas Carion, Laura Gustafson, Yuan-Ting Hu, Shoubhik Debnath, Ronghang Hu, Didac Suris, Chaitanya Ryali, Kalyan Vasudev Alwala, Haitham Khedr, Andrew Huang, et al. Sam 3: Segment anything with concepts.arXiv preprint arXiv:2511.16719, 2025
Pith/arXiv arXiv 2025
-
[9]
Jiacheng Chen, Ramin Mehran, Xuhui Jia, Saining Xie, and Sanghyun Woo. Blenderfusion: 3d-grounded visual editing and generative compositing.arXiv preprint arXiv:2506.17450, 2025
arXiv 2025
-
[10]
Anydoor: Zero-shot object-level image customization
Xi Chen, Lianghua Huang, Yu Liu, Yujun Shen, Deli Zhao, and Hengshuang Zhao. Anydoor: Zero-shot object-level image customization. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6593–6602, 2024. 10
2024
-
[11]
Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Xingyu Chen, Fu-Jen Chu, Pierre Gleize, Kevin J Liang, Alexander Sax, Hao Tang, Weiyao Wang, Michelle Guo, Thibaut Hardin, Xiang Li, et al. Sam 3d: 3dfy anything in images.arXiv preprint arXiv:2511.16624, 2025
Pith/arXiv arXiv 2025
-
[12]
Learning continuous 3d words for text-to-image generation
Ta-Ying Cheng, Matheus Gadelha, Thibault Groueix, Matthew Fisher, Radomir Mech, Andrew Markham, and Niki Trigoni. Learning continuous 3d words for text-to-image generation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 6753–6762, 2024
2024
-
[13]
Marble: Material recomposi- tion and blending in clip-space
Ta Ying Cheng, Prafull Sharma, Mark Boss, and Varun Jampani. Marble: Material recomposi- tion and blending in clip-space. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 13061–13071, 2025
2025
-
[14]
3d-fixup: Advancing photo editing with 3d priors
Yen-Chi Cheng, Krishna Kumar Singh, Jae Shin Yoon, Alexander Schwing, Liang-Yan Gui, Matheus Gadelha, Paul Guerrero, and Nanxuan Zhao. 3d-fixup: Advancing photo editing with 3d priors. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–10, 2025
2025
-
[15]
Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813, 2023
Matt Deitke, Ruoshi Liu, Matthew Wallingford, Huong Ngo, Oscar Michel, Aditya Kusupati, Alan Fan, Christian Laforte, Vikram V oleti, Samir Yitzhak Gadre, et al. Objaverse-xl: A universe of 10m+ 3d objects.Advances in Neural Information Processing Systems, 36:35799–35813, 2023
2023
-
[16]
Strobl, Matthias Humt, and Rudolph Triebel
Maximilian Denninger, Dominik Winkelbauer, Martin Sundermeyer, Wout Boerdijk, Markus Knauer, Klaus H. Strobl, Matthias Humt, and Rudolph Triebel. Blenderproc2: A procedural pipeline for photorealistic rendering.Journal of Open Source Software, 8(82):4901, 2023
2023
-
[17]
Abdelrahman Eldesokey and Peter Wonka. Build-a-scene: Interactive 3d layout control for diffusion-based image generation.arXiv preprint arXiv:2408.14819, 2024
arXiv 2024
-
[18]
Alejandro Escontrela, Shrinu Kushagra, Sjoerd van Steenkiste, Yulia Rubanova, Aleksander Holynski, Kelsey Allen, Kevin Murphy, and Thomas Kipf. Neural usd: An object-centric framework for iterative editing and control.arXiv preprint arXiv:2510.23956, 2025
arXiv 2025
-
[19]
Scaling rectified flow trans- formers for high-resolution image synthesis
Patrick Esser, Sumith Kulal, Andreas Blattmann, Rahim Entezari, Jonas Müller, Harry Saini, Yam Levi, Dominik Lorenz, Axel Sauer, Frederic Boesel, et al. Scaling rectified flow trans- formers for high-resolution image synthesis. InForty-first international conference on machine learning, 2024
2024
-
[20]
Stephanie Fu, Netanel Tamir, Shobhita Sundaram, Lucy Chai, Richard Zhang, Tali Dekel, and Phillip Isola. Dreamsim: Learning new dimensions of human visual similarity using synthetic data.arXiv preprint arXiv:2306.09344, 2023
Pith/arXiv arXiv 2023
-
[21]
An image is worth one word: Personalizing text-to-image generation using textual inversion
Rinon Gal, Yuval Alaluf, Yuval Atzmon, Or Patashnik, Amit Haim Bermano, Gal Chechik, and Daniel Cohen-Or. An image is worth one word: Personalizing text-to-image generation using textual inversion. InThe Eleventh International Conference on Learning Representations
-
[22]
Concept sliders: Lora adaptors for precise control in diffusion models
Rohit Gandikota, Joanna Materzy´nska, Tingrui Zhou, Antonio Torralba, and David Bau. Concept sliders: Lora adaptors for precise control in diffusion models. InEuropean Conference on Computer Vision, pages 172–188. Springer, 2024
2024
-
[23]
Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions On Graphics (TOG), 44(4):1–11, 2025
Daniel Garibi, Shahar Yadin, Roni Paiss, Omer Tov, Shiran Zada, Ariel Ephrat, Tomer Michaeli, Inbar Mosseri, and Tali Dekel. Tokenverse: Versatile multi-concept personalization in token modulation space.ACM Transactions On Graphics (TOG), 44(4):1–11, 2025
2025
-
[24]
Prompt-to-prompt image editing with cross attention control
Amir Hertz, Ron Mokady, Jay Tenenbaum, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Prompt-to-prompt image editing with cross attention control. 2022
2022
-
[25]
Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022
Edward J Hu, Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Liang Wang, Weizhu Chen, et al. Lora: Low-rank adaptation of large language models.Iclr, 1(2):3, 2022. 11
2022
-
[26]
Wilddet3d: Scaling promptable 3d detection in the wild.arXiv preprint arXiv:2604.08626, 2026
Weikai Huang, Jieyu Zhang, Sijun Li, Taoyang Jia, Jiafei Duan, Yunqian Cheng, Jaemin Cho, Mattew Wallingford, Rustin Soraki, Chris Dongjoo Kim, et al. Wilddet3d: Scaling promptable 3d detection in the wild.arXiv preprint arXiv:2604.08626, 2026
Pith/arXiv arXiv 2026
-
[27]
Clipdrag: Combining text-based and drag-based instructions for image editing
Ziqi Jiang, Zhen Wang, and Long Chen. Clipdrag: Combining text-based and drag-based instructions for image editing. InInternational Conference on Learning Representations, volume 2025, pages 5237–5253, 2025
2025
-
[28]
Ronen Kamenetsky, Sara Dorfman, Daniel Garibi, Roni Paiss, Or Patashnik, and Daniel Cohen- Or. Saedit: Token-level control for continuous image editing via sparse autoencoder.arXiv preprint arXiv:2510.05081, 2025
arXiv 2025
-
[29]
Imagic: Text-based real image editing with diffusion models
Bahjat Kawar, Shiran Zada, Oran Lang, Omer Tov, Huiwen Chang, Tali Dekel, Inbar Mosseri, and Michal Irani. Imagic: Text-based real image editing with diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6007–6017, 2023
2023
-
[30]
Customizing text-to-image diffusion with object viewpoint control
Nupur Kumari, Grace Su, Richard Zhang, Taesung Park, Eli Shechtman, and Jun-Yan Zhu. Customizing text-to-image diffusion with object viewpoint control. InSIGGRAPH Asia 2024 Conference Papers, pages 1–13, 2024
2024
-
[31]
Generating multi-image synthetic data for text-to-image customization
Nupur Kumari, Xi Yin, Jun-Yan Zhu, Ishan Misra, and Samaneh Azadi. Generating multi-image synthetic data for text-to-image customization. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 16524–16534, 2025
2025
-
[32]
Multi- concept customization of text-to-image diffusion
Nupur Kumari, Bingliang Zhang, Richard Zhang, Eli Shechtman, and Jun-Yan Zhu. Multi- concept customization of text-to-image diffusion. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 1931–1941, 2023
1931
-
[33]
Flux.https://github.com/black-forest-labs/flux, 2024
Black Forest Labs. Flux.https://github.com/black-forest-labs/flux, 2024
2024
-
[34]
Black Forest Labs, Stephen Batifol, Andreas Blattmann, Frederic Boesel, Saksham Consul, Cyril Diagne, Tim Dockhorn, Jack English, Zion English, Patrick Esser, et al. Flux. 1 kontext: Flow matching for in-context image generation and editing in latent space.arXiv preprint arXiv:2506.15742, 2025
Pith/arXiv arXiv 2025
-
[35]
Lightlab: Controlling light sources in images with diffusion models
Nadav Magar, Amir Hertz, Eric Tabellion, Yael Pritch, Alex Rav-Acha, Ariel Shamir, and Yedid Hoshen. Lightlab: Controlling light sources in images with diffusion models. InProceedings of the Special Interest Group on Computer Graphics and Interactive Techniques Conference Conference Papers, pages 1–11, 2025
2025
-
[37]
Object 3dit: Language-guided 3d-aware image editing.Advances in Neural Information Processing Systems, 36:3497–3516, 2023
Oscar Michel, Anand Bhattad, Eli VanderBilt, Ranjay Krishna, Aniruddha Kembhavi, and Tanmay Gupta. Object 3dit: Language-guided 3d-aware image editing.Advances in Neural Information Processing Systems, 36:3497–3516, 2023
2023
-
[38]
Origen: Zero-shot 3d orientation grounding in text-to-image generation
Yunhong Min, Daehyeon Choi, Kyeongmin Yeo, Jihyun Lee, and Minhyuk Sung. Origen: Zero-shot 3d orientation grounding in text-to-image generation. InThe Thirty-ninth Annual Conference on Neural Information Processing Systems
-
[39]
Prodigy: An expeditiously adaptive parameter-free learner.arXiv preprint arXiv:2306.06101, 2023
Konstantin Mishchenko and Aaron Defazio. Prodigy: An expeditiously adaptive parameter-free learner.arXiv preprint arXiv:2306.06101, 2023
arXiv 2023
-
[40]
Null-text inversion for editing real images using guided diffusion models
Ron Mokady, Amir Hertz, Kfir Aberman, Yael Pritch, and Daniel Cohen-Or. Null-text inversion for editing real images using guided diffusion models. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 6038–6047, 2023
2023
-
[41]
Dragondiffusion: Enabling drag-style manipulation on diffusion models
Chong Mou, Xintao Wang, Jiechong Song, Ying Shan, and Jian Zhang. Dragondiffusion: Enabling drag-style manipulation on diffusion models. InInternational Conference on Learning Representations, volume 2024, pages 31620–31631, 2024. 12
2024
-
[42]
Diffusion handles enabling 3d edits for diffusion models by lifting activations to 3d
Karran Pandey, Paul Guerrero, Matheus Gadelha, Yannick Hold-Geoffroy, Karan Singh, and Niloy J Mitra. Diffusion handles enabling 3d edits for diffusion models by lifting activations to 3d. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 7695–7704, 2024
2024
-
[43]
Compass control: Multi object orientation control for text-to-image generation
Rishubh Parihar, Vaibhav Agrawal, Sachidanand VS, and Venkatesh Babu Radhakrishnan. Compass control: Multi object orientation control for text-to-image generation. InProceedings of the Computer Vision and Pattern Recognition Conference, pages 2791–2801, 2025
2025
-
[44]
Rishubh Parihar, Or Patashnik, Daniil Ostashev, R Venkatesh Babu, Daniel Cohen-Or, and Kuan-Chieh Wang. Kontinuous kontext: Continuous strength control for instruction-based image editing.arXiv preprint arXiv:2510.08532, 2025
arXiv 2025
-
[45]
Zero-shot depth aware image editing with diffusion models
Rishubh Parihar, Sachidanand VS, and R Venkatesh Babu. Zero-shot depth aware image editing with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 15748–15759, 2025
2025
-
[46]
Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
Adam Paszke, Sam Gross, Francisco Massa, Adam Lerer, James Bradbury, Gregory Chanan, Trevor Killeen, Zeming Lin, Natalia Gimelshein, Luca Antiga, et al. Pytorch: An imperative style, high-performance deep learning library.Advances in neural information processing systems, 32, 2019
2019
-
[47]
Unidepth: Universal monocular metric depth estimation
Luigi Piccinelli, Yung-Hsu Yang, Christos Sakaridis, Mattia Segu, Siyuan Li, Luc Van Gool, and Fisher Yu. Unidepth: Universal monocular metric depth estimation. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 10106–10116, 2024
2024
-
[48]
Tianhe Ren, Shilong Liu, Ailing Zeng, Jing Lin, Kunchang Li, He Cao, Jiayu Chen, Xinyu Huang, Yukang Chen, Feng Yan, et al. Grounded sam: Assembling open-world models for diverse visual tasks.arXiv preprint arXiv:2401.14159, 2024
Pith/arXiv arXiv 2024
-
[49]
Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation
Nataniel Ruiz, Yuanzhen Li, Varun Jampani, Yael Pritch, Michael Rubinstein, and Kfir Aberman. Dreambooth: Fine tuning text-to-image diffusion models for subject-driven generation. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 22500–22510, 2023
2023
-
[50]
Geodiffuser: Geometry-based image editing with diffusion models
Rahul Sajnani, Jeroen Vanbaar, Jie Min, Kapil D Katyal, and Srinath Sridhar. Geodiffuser: Geometry-based image editing with diffusion models. InProceedings of the Winter Conference on Applications of Computer Vision, pages 472–482, 2025
2025
-
[51]
Alchemist: Parametric control of material properties with diffusion models
Prafull Sharma, Varun Jampani, Yuanzhen Li, Xuhui Jia, Dmitry Lagun, Fredo Durand, Bill Freeman, and Mark Matthews. Alchemist: Parametric control of material properties with diffusion models. InProceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 24130–24141, 2024
2024
-
[53]
Dragdiffusion: Harnessing diffusion models for interactive point-based image editing
Yujun Shi, Chuhui Xue, Jun Hao Liew, Jiachun Pan, Hanshu Yan, Wenqing Zhang, Vincent YF Tan, and Song Bai. Dragdiffusion: Harnessing diffusion models for interactive point-based image editing. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 8839–8849, 2024
2024
-
[54]
Oriane Siméoni, Huy V V o, Maximilian Seitzer, Federico Baldassarre, Maxime Oquab, Cijo Jose, Vasil Khalidov, Marc Szafraniec, Seungeun Yi, Michaël Ramamonjisoa, et al. Dinov3. arXiv preprint arXiv:2508.10104, 2025
Pith/arXiv arXiv 2025
-
[55]
Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020
Jiaming Song, Chenlin Meng, and Stefano Ermon. Denoising diffusion implicit models.arXiv preprint arXiv:2010.02502, 2020. 13
Pith/arXiv arXiv 2010
-
[56]
Ominicontrol: Minimal and universal control for diffusion transformer
Zhenxiong Tan, Songhua Liu, Xingyi Yang, Qiaochu Xue, and Xinchao Wang. Ominicontrol: Minimal and universal control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 14940–14950, 2025
2025
-
[57]
Zhenxiong Tan, Qiaochu Xue, Xingyi Yang, Songhua Liu, and Xinchao Wang. Ominicontrol2: Efficient conditioning for diffusion transformers.arXiv preprint arXiv:2503.08280, 2025
arXiv 2025
-
[58]
Emer- gent correspondence from image diffusion.Advances in neural information processing systems, 36:1363–1389, 2023
Luming Tang, Menglin Jia, Qianqian Wang, Cheng Perng Phoo, and Bharath Hariharan. Emer- gent correspondence from image diffusion.Advances in neural information processing systems, 36:1363–1389, 2023
2023
-
[59]
Raft: Recurrent all-pairs field transforms for optical flow
Zachary Teed and Jia Deng. Raft: Recurrent all-pairs field transforms for optical flow. In European conference on computer vision, pages 402–419. Springer, 2020
2020
-
[60]
Gener- ative blocks world: Moving things around in pictures
Vaibhav Vavilala, Seemandhar Jain, Rahul Vasanth, David Forsyth, and Anand Bhattad. Gener- ative blocks world: Moving things around in pictures. InICLR, 2026
2026
-
[61]
Diffusers: State-of-the-art diffusion models
Patrick von Platen, Suraj Patil, Anton Lozhkov, Pedro Cuenca, Nathan Lambert, Kashif Rasul, Mishig Davaadorj, Dhruv Nair, Sayak Paul, William Berman, Yiyi Xu, Steven Liu, and Thomas Wolf. Diffusers: State-of-the-art diffusion models. https://github.com/huggingface/ diffusers, 2022
2022
-
[62]
Bovik, H.R
Zhou Wang, A.C. Bovik, H.R. Sheikh, and E.P. Simoncelli. Image quality assessment: from error visibility to structural similarity.IEEE Transactions on Image Processing, 13(4):600–612, 2004
2004
-
[63]
Qwen-image technical report, 2025
Chenfei Wu, Jiahao Li, Jingren Zhou, Junyang Lin, Kaiyuan Gao, Kun Yan, Sheng ming Yin, Shuai Bai, Xiao Xu, Yilei Chen, Yuxiang Chen, Zecheng Tang, Zekai Zhang, Zhengyi Wang, An Yang, Bowen Yu, Chen Cheng, Dayiheng Liu, Deqing Li, Hang Zhang, Hao Meng, Hu Wei, Jingyuan Ni, Kai Chen, Kuan Cao, Liang Peng, Lin Qu, Minggang Wu, Peng Wang, Shuting Yu, Tingkun...
2025
-
[64]
Neural assets: 3d-aware multi-object scene synthesis with image diffusion models.Advances in Neural Information Processing Systems, 37:76289–76318, 2024
Ziyi Wu, Yulia Rubanova, Rishabh Kabra, Drew A Hudson, Igor Gilitschenski, Yusuf Aytar, Sjoerd Van Steenkiste, Kelsey R Allen, and Thomas Kipf. Neural assets: 3d-aware multi-object scene synthesis with image diffusion models.Advances in Neural Information Processing Systems, 37:76289–76318, 2024
2024
-
[65]
Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Jianfeng Xiang, Xiaoxue Chen, Sicheng Xu, Ruicheng Wang, Zelong Lv, Yu Deng, Hongyuan Zhu, Yue Dong, Hao Zhao, Nicholas Jing Yuan, et al. Native and compact structured latents for 3d generation.arXiv preprint arXiv:2512.14692, 2025
Pith/arXiv arXiv 2025
-
[66]
Spatialedit: Benchmarking fine-grained image spatial editing.arXiv preprint arXiv:2604.04911, 2026
Yicheng Xiao, Wenhu Zhang, Lin Song, Yukang Chen, Wenbo Li, Nan Jiang, Tianhe Ren, Haokun Lin, Wei Huang, Haoyang Huang, et al. Spatialedit: Benchmarking fine-grained image spatial editing.arXiv preprint arXiv:2604.04911, 2026
Pith/arXiv arXiv 2026
-
[67]
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, and Ying Shan. In- stantmesh: Efficient 3d mesh generation from a single image with sparse-view large reconstruc- tion models.arXiv preprint arXiv:2404.07191, 2024
Pith/arXiv arXiv 2024
-
[68]
Paint by example: Exemplar-based image editing with diffusion models
Binxin Yang, Shuyang Gu, Bo Zhang, Ting Zhang, Xuejin Chen, Xiaoyan Sun, Dong Chen, and Fang Wen. Paint by example: Exemplar-based image editing with diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 18381–18391, 2023
2023
-
[69]
Depth anything: Unleashing the power of large-scale unlabeled data
Lihe Yang, Bingyi Kang, Zilong Huang, Xiaogang Xu, Jiashi Feng, and Hengshuang Zhao. Depth anything: Unleashing the power of large-scale unlabeled data. InProceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 10371–10381, 2024
2024
-
[70]
Hu Ye, Jun Zhang, Sibo Liu, Xiao Han, and Wei Yang. Ip-adapter: Text compatible image prompt adapter for text-to-image diffusion models.arXiv preprint arXiv:2308.06721, 2023. 14
Pith/arXiv arXiv 2023
-
[71]
Ze-Xin Yin, Liu Liu, Xinjie Wang, Wei Sui, Zhizhong Su, Jian Yang, and Jin Xie. 3d- fixer: Coarse-to-fine in-place completion for 3d scenes from a single image.arXiv preprint arXiv:2604.04406, 2026
Pith/arXiv arXiv 2026
-
[72]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InIEEE International Conference on Computer Vision (ICCV), 2023
2023
-
[73]
Adding conditional control to text-to-image diffusion models
Lvmin Zhang, Anyi Rao, and Maneesh Agrawala. Adding conditional control to text-to-image diffusion models. InProceedings of the IEEE/CVF international conference on computer vision, pages 3836–3847, 2023
2023
-
[74]
The unrea- sonable effectiveness of deep features as a perceptual metric
Richard Zhang, Phillip Isola, Alexei A Efros, Eli Shechtman, and Oliver Wang. The unrea- sonable effectiveness of deep features as a perceptual metric. InProceedings of the IEEE conference on computer vision and pattern recognition, pages 586–595, 2018
2018
-
[75]
Shuo Zhang, Wenzhuo Wu, Huayu Zhang, Jiarong Cheng, Xianghao Zang, Chao Ban, Hao Sun, Zhongjiang He, Tianwei Cao, Kongming Liang, et al. Geometric image editing via effects- sensitive in-context inpainting with diffusion transformers.arXiv preprint arXiv:2602.08388, 2026
arXiv 2026
-
[76]
Easycontrol: Adding efficient and flexible control for diffusion transformer
Yuxuan Zhang, Yirui Yuan, Yiren Song, Haofan Wang, and Jiaming Liu. Easycontrol: Adding efficient and flexible control for diffusion transformer. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19513–19524, 2025
2025
-
[77]
Gooddrag: Towards good practices for drag editing with diffusion models
Zewei Zhang, Huan Liu, Jun Chen, and Xiangyu Xu. Gooddrag: Towards good practices for drag editing with diffusion models. InInternational Conference on Learning Representations, volume 2025, pages 13785–13808, 2025
2025
-
[78]
Stable virtual camera: Generative view synthesis with diffusion models
Jensen Zhou, Hang Gao, Vikram V oleti, Aaryaman Vasishta, Chun-Han Yao, Mark Boss, Philip Torr, Christian Rupprecht, and Varun Jampani. Stable virtual camera: Generative view synthesis with diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 12405–12414, 2025
2025
-
[79]
Training-free geometric image editing on diffusion models
Hanshen Zhu, Zhen Zhu, Kaile Zhang, Yiming Gong, Yuliang Liu, and Xiang Bai. Training-free geometric image editing on diffusion models. InProceedings of the IEEE/CVF International Conference on Computer Vision, pages 19130–19140, 2025. 15 Supplemental Materials Table of Contents A.Additional Results. . . . . . . . . . . . . . . . . . . . . . . . . . . . ....
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.