RIZZ: Routing Interactions to Near Zero-Interference Zones for Continual Adaptation of Black-Box Agents
Pith reviewed 2026-06-28 10:01 UTC · model grok-4.3
The pith
RIZZ routes black-box agent interactions into dynamically spawned memory branches to control interference during continual adaptation.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that organizing input streams into dynamically spawned memory branches, combined with a context-aware router that retrieves multi-level context and compiles it into bounded prompts, allows black-box agents to adapt continually through verifier-gated memory updates while explicitly controlling interference between task families.
What carries the argument
Dynamically spawned memory branches selected or created by a context-aware router that compiles branch-local, global, graph-structured, and working-memory context into bounded prompts.
If this is right
- Black-box agents can improve through persistent natural-language feedback while operating online or offline under context budgets.
- Failures in one task family are prevented from contaminating behavior on unrelated tasks via branch isolation.
- Only verified interactions update memory or promote reusable rules, demote harmful rules, or create anti-patterns.
- The framework yields measurable gains against state-of-the-art baselines on competitive benchmarks for continual adaptation.
Where Pith is reading between the lines
- The router's ability to create branches on the fly could support adaptation in environments where the number of distinct task families is unknown in advance.
- Verifier-gated updates might enable safe promotion of rules across branches if the graph-structured context captures relevant similarities between tasks.
- Bounded prompt compilation suggests the method could scale to longer agent lifetimes by keeping context usage explicit and limited.
Load-bearing premise
Reliable task verifiers exist that can accurately gate memory updates and rule promotion without introducing bias or requiring unavailable human oversight.
What would settle it
A test showing that interactions from one task family contaminate performance on another despite the routing and verifier mechanism, or that verifiers systematically approve low-quality outputs leading to memory corruption.
Figures

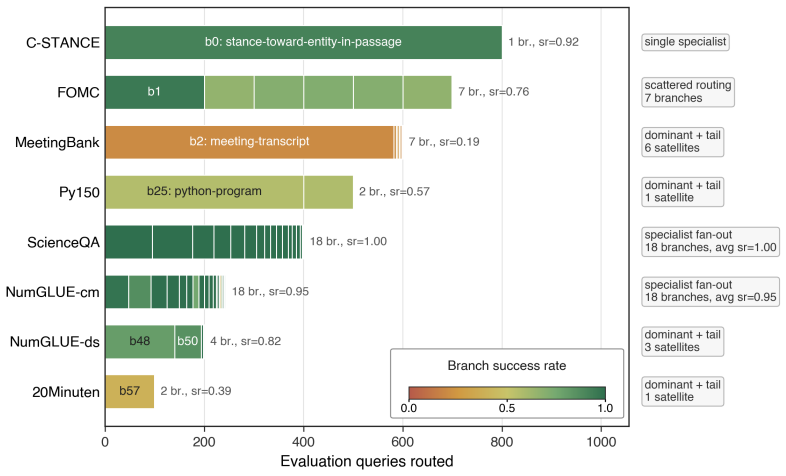
read the original abstract
Large language models are increasingly deployed as long-lived agents that must adapt across users, tasks, domains, modalities, and feedback regimes without access to model weights. Existing black-box adaptation methods typically optimize a single prompt, maintain an undifferentiated memory, or rely on repeated rollout-heavy search. However, these designs struggle when streams of input are nonstationary, feedback is sparse, and failures from one task family can contaminate behavior on another. We introduce RIZZ (Routing Interactions to Near Zero-interference Zones), a continual adaptation framework for compound language-model systems that learns entirely through verifier-gated memory, routing, and prompt compilation. RIZZ organizes input streams into dynamically spawned memory branches. At inference time, either while online or offline, a context-aware router selects or creates a branch that retrieves branch-local, global, graph-structured, and working-memory context, which is compiled into a bounded prompt together with retrieved task evidence. After the model acts, task verifiers score the output, and only verified interactions can update memory, promote reusable rules, demote harmful rules, or create anti-patterns. This yields a black-box agent that improves through persistent natural-language feedback while explicitly controlling interference. RIZZ targets the regime where adaptation must occur online under context budgets. Finally, we demonstrate the effectiveness of our framework against state-of-the-art baselines on competitive benchmarks.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces RIZZ, a continual adaptation framework for black-box LLM agents operating under context budgets. Input streams are organized into dynamically spawned memory branches; a context-aware router selects or creates a branch at inference time (online or offline), retrieves branch-local/global/graph-structured/working-memory context plus task evidence, and compiles this into a bounded prompt. After the model acts, task verifiers score the output, and only verified interactions are allowed to update memory branches, promote reusable rules, demote harmful rules, or create anti-patterns. The framework is claimed to enable persistent natural-language feedback while explicitly controlling interference across nonstationary task streams, with demonstrations against SOTA baselines on competitive benchmarks.
Significance. If the central mechanisms can be realized with reliable verifiers, the approach would address a genuine gap in black-box continual adaptation by providing an explicit routing and gating architecture that avoids undifferentiated memory contamination. The emphasis on bounded prompts, graph-structured context, and verifier-gated rule promotion/demotion offers a concrete design for online adaptation without weight access. However, the absence of any implementation details, experimental results, or analysis in the manuscript prevents assessment of whether these benefits are realized in practice.
major comments (2)
- [Abstract] The central claim of near zero-interference routing and persistent adaptation rests entirely on the task verifiers that gate memory updates, rule promotion/demotion, and anti-pattern creation. The manuscript provides no mechanism, training procedure, accuracy bounds, bias analysis, or implementation details for these verifiers, treating them as oracles. If verifiers are noisy or biased, the gating fails and cross-branch contamination reappears—the exact failure mode the method claims to solve.
- [Abstract] The abstract states that effectiveness is demonstrated against state-of-the-art baselines on competitive benchmarks, yet the manuscript contains no experimental setup, results tables, baseline descriptions, metrics, error analysis, or ablation studies. This absence makes it impossible to evaluate whether the routing and verifier mechanisms deliver the claimed interference control.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments correctly identify substantive gaps in the submitted manuscript. We address each point below and commit to a major revision that incorporates the requested clarifications and missing content.
read point-by-point responses
-
Referee: [Abstract] The central claim of near zero-interference routing and persistent adaptation rests entirely on the task verifiers that gate memory updates, rule promotion/demotion, and anti-pattern creation. The manuscript provides no mechanism, training procedure, accuracy bounds, bias analysis, or implementation details for these verifiers, treating them as oracles. If verifiers are noisy or biased, the gating fails and cross-branch contamination reappears—the exact failure mode the method claims to solve.
Authors: We agree that the verifiers are the linchpin of the interference-control claims and that the manuscript currently treats them as black-box oracles. In the revision we will add a dedicated subsection (tentatively “Verifier Assumptions and Robustness”) that (1) enumerates concrete verifier realizations (rule-based checkers, LLM-as-judge with temperature sampling, external tool calls), (2) states explicit accuracy and bias assumptions, and (3) analyzes failure modes when verifiers are noisy, including how anti-pattern creation and branch demotion can partially compensate. We will also add a short sensitivity experiment (or simulation) showing degradation under controlled verifier error rates. revision: yes
-
Referee: [Abstract] The abstract states that effectiveness is demonstrated against state-of-the-art baselines on competitive benchmarks, yet the manuscript contains no experimental setup, results tables, baseline descriptions, metrics, error analysis, or ablation studies. This absence makes it impossible to evaluate whether the routing and verifier mechanisms deliver the claimed interference control.
Authors: The submitted manuscript omitted the entire Experiments section because of an upload error; the complete draft contains evaluations on standard continual-adaptation and agent benchmarks (including interference metrics across task streams). In the revision we will restore the full experimental section with setup details, baseline descriptions, tables, metrics (including cross-branch contamination rates), error analysis, and ablations on the router and verifier components. revision: yes
Circularity Check
No circularity: purely architectural description with no derivations or reductions to inputs.
full rationale
The paper describes an architectural framework (memory branches, context-aware router, verifier-gated updates) without any equations, first-principles derivations, fitted parameters presented as predictions, or load-bearing self-citations. No step claims to derive a result that reduces by construction to its own inputs or to a self-referential ansatz. The central claims are design choices whose validity rests on external assumptions (e.g., reliable verifiers) rather than internal definitional closure. This is the expected non-finding for a systems/architectural paper.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab
Lakshya A Agrawal, Shangyin Tan, Dilara Soylu, Noah Ziems, Rishi Khare, Krista Opsahl- Ong, Arnav Singhvi, Herumb Shandilya, Michael J Ryan, Meng Jiang, Christopher Potts, Koushik Sen, Alexandros G. Dimakis, Ion Stoica, Dan Klein, Matei Zaharia, and Omar Khattab. Gepa: Reflective prompt evolution can outperform reinforcement learning, 2026. URL https: //a...
Pith/arXiv arXiv 2026
-
[2]
Introducing claude haiku 4.5
Anthropic. Introducing claude haiku 4.5. https://www.anthropic.com/news/ claude-haiku-4-5, October 2025. Accessed 2026-05-07
2025
-
[3]
Ju-Seung Byun, Jiyun Chun, Jihyung Kil, and Andrew Perrault. ARES: Alternating reinforce- ment learning and supervised fine-tuning for enhanced multi-modal chain-of-thought reasoning through diverse AI feedback. InProceedings of the 2024 Conference on Empirical Methods in Natural Language Processing, pages 4410–4430, Miami, Florida, USA, November 2024. As...
-
[4]
Beysengulov, Daniel C
Shuxiang Cao, Zijian Zhang, Abhishek Agarwal, Grace Bratrud, Niyaz R. Beysengulov, Daniel C. Cole, Alejandro Gómez Frieiro, Elena O. Glen, Hao Hsu, Gang Huang, Raymond Jow, Greshma Shaji, Tom Lubowe, Ligeng Zhu, Luis Mantilla Calderón, Nicola Pancotti, Joel Pendleton, Brandon Severin, Charles Etienne Staub, Sara Sussman, Antti Vepsäläinen, Neel Ra- jeshbh...
-
[5]
URLhttps://arxiv.org/abs/2604.25884
-
[6]
Cowan, Anna C
Emily T. Cowan, Anna C. Schapiro, Joseph E. Dunsmoor, et al. Memory consolidation as an adaptive process.Psychonomic Bulletin & Review, 28:1796–1810, 2021. doi: 10.3758/ s13423-021-01978-x
2021
-
[7]
Ella: Efficient lifelong learning for adapters in large language models, 2026
Shristi Das Biswas, Yue Zhang, Anwesan Pal, Radhika Bhargava, and Kaushik Roy. Ella: Efficient lifelong learning for adapters in large language models, 2026. URL https://arxiv. org/abs/2601.02232
arXiv 2026
-
[8]
Fernando Hernandez-Garcia, Parash Rahman, A
Shibhansh Dohare, J. Fernando Hernandez-Garcia, Parash Rahman, A. Rupam Mahmood, and Richard S. Sutton. Maintaining plasticity in deep continual learning, 2023. URL https: //arxiv.org/abs/2306.13812
arXiv 2023
-
[9]
Sweeping heterogeneity with smart mops: Mixture of prompts for llm task adaptation, 2025
Chen Dun, Mirian Hipolito Garcia, Guoqing Zheng, Ahmed Hassan Awadallah, Anastasios Kyrillidis, and Robert Sim. Sweeping heterogeneity with smart mops: Mixture of prompts for llm task adaptation, 2025. URLhttps://arxiv.org/abs/2310.02842
arXiv 2025
-
[10]
Timo Flesch, Andrew Saxe, and Christopher Summerfield. Continual task learning in natural and artificial agents.Trends in Neurosciences, 46(3):199–210, 2023. doi: 10.1016/j.tins.2022. 12.006
-
[11]
Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
Robert M French. Catastrophic forgetting in connectionist networks.Trends in cognitive sciences, 3(4):128–135, 1999
1999
-
[12]
Synaptic tagging and long-term potentiation.Nature, 385 (6616):533–536, 1997
Uwe Frey and Richard GM Morris. Synaptic tagging and long-term potentiation.Nature, 385 (6616):533–536, 1997
1997
-
[13]
Ian J Goodfellow, Mehdi Mirza, Da Xiao, Aaron Courville, and Yoshua Bengio. An empirical investigation of catastrophic forgetting in gradient-based neural networks.arXiv preprint arXiv:1312.6211, 2013
Pith/arXiv arXiv 2013
-
[14]
Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
Xu Huang, Weiwen Liu, Xiaolong Chen, Xingmei Wang, Hao Wang, Defu Lian, Yasheng Wang, Ruiming Tang, and Enhong Chen. Understanding the planning of llm agents: A survey.arXiv preprint arXiv:2402.02716, 2024
Pith/arXiv arXiv 2024
-
[15]
Efficient continual learning in language models via thalamically routed cortical columns, 2026
Afshin Khadangi. Efficient continual learning in language models via thalamically routed cortical columns, 2026. URLhttps://arxiv.org/abs/2602.22479. 10
Pith/arXiv arXiv 2026
-
[16]
Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts
Omar Khattab, Arnav Singhvi, Paridhi Maheshwari, Zhiyuan Zhang, Keshav Santhanam, Sri Vardhamanan, Saiful Haq, Ashutosh Sharma, Thomas T. Joshi, Hanna Moazam, Heather Miller, Matei Zaharia, and Christopher Potts. Dspy: Compiling declarative language model calls into self-improving pipelines, 2023. URLhttps://arxiv.org/abs/2310.03714
Pith/arXiv arXiv 2023
-
[17]
Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, et al
James Kirkpatrick, Razvan Pascanu, Neil Rabinowitz, Joel Veness, Guillaume Desjardins, Andrei A. Rusu, Kieran Milan, John Quan, Tiago Ramalho, Agnieszka Grabska-Barwinska, Demis Hassabis, Claudia Clopath, Dharshan Kumaran, and Raia Hadsell. Overcoming catas- trophic forgetting in neural networks.Proceedings of the National Academy of Sciences, 114(13):352...
-
[18]
Feedback descent: Open-ended text optimization via pairwise comparison, 2025
Yoonho Lee, Joseph Boen, and Chelsea Finn. Feedback descent: Open-ended text optimization via pairwise comparison, 2025. URLhttps://arxiv.org/abs/2511.07919
arXiv 2025
-
[19]
Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021
Patrick Lewis, Ethan Perez, Aleksandra Piktus, Fabio Petroni, Vladimir Karpukhin, Naman Goyal, Heinrich Küttler, Mike Lewis, Wen tau Yih, Tim Rocktäschel, Sebastian Riedel, and Douwe Kiela. Retrieval-augmented generation for knowledge-intensive nlp tasks, 2021. URL https://arxiv.org/abs/2005.11401
Pith/arXiv arXiv 2021
-
[20]
Mingxin Li, Yanzhao Zhang, Dingkun Long, Keqin Chen, Sibo Song, Shuai Bai, Zhibo Yang, Pengjun Xie, An Yang, Dayiheng Liu, Jingren Zhou, and Junyang Lin. Qwen3-vl-embedding and qwen3-vl-reranker: A unified framework for state-of-the-art multimodal retrieval and ranking, 2026. URLhttps://arxiv.org/abs/2601.04720
Pith/arXiv arXiv 2026
-
[21]
Gradient episodic memory for continual learning
David Lopez-Paz and Marc’Aurelio Ranzato. Gradient episodic memory for continual learning. InAdvances in Neural Information Processing Systems, 2017
2017
-
[22]
Self-refine: Iterative refinement with self-feedback, 2023
Aman Madaan, Niket Tandon, Prakhar Gupta, Skyler Hallinan, Luyu Gao, Sarah Wiegreffe, Uri Alon, Nouha Dziri, Shrimai Prabhumoye, Yiming Yang, Shashank Gupta, Bodhisattwa Prasad Majumder, Katherine Hermann, Sean Welleck, Amir Yazdanbakhsh, and Peter Clark. Self-refine: Iterative refinement with self-feedback, 2023. URL https://arxiv.org/abs/2303.17651
Pith/arXiv arXiv 2023
-
[23]
Patil, Ion Stoica, and Joseph E
Charles Packer, Sarah Wooders, Kevin Lin, Vivian Fang, Shishir G. Patil, Ion Stoica, and Joseph E. Gonzalez. Memgpt: Towards llms as operating systems, 2024. URL https: //arxiv.org/abs/2310.08560
Pith/arXiv arXiv 2024
-
[24]
German I. Parisi, Ronald Kemker, Jose L. Part, Christopher Kanan, and Stefan Wermter. Continual lifelong learning with neural networks: A review.Neural Networks, 113:54–71, 2019. doi: 10.1016/j.neunet.2019.01.012
-
[25]
Fine-tuning aligned language models compromises safety, even when users do not intend to!,
Xiangyu Qi, Yi Zeng, Tinghao Xie, Pin-Yu Chen, Ruoxi Jia, Prateek Mittal, and Peter Henderson. Fine-tuning aligned language models compromises safety, even when users do not intend to!,
-
[26]
URLhttps://arxiv.org/abs/2310.03693
-
[27]
On the plasticity and stability for post-training large language models, 2026
Wenwen Qiang, Ziyin Gu, Jiahuan Zhou, Jie Hu, Jingyao Wang, Changwen Zheng, and Hui Xiong. On the plasticity and stability for post-training large language models, 2026. URL https://arxiv.org/abs/2602.06453
arXiv 2026
-
[28]
Continual learning using only large language model prompting, 2024
Jiabao Qiu, Zixuan Ke, and Bing Liu. Continual learning using only large language model prompting, 2024. URLhttps://arxiv.org/abs/2412.15479
arXiv 2024
-
[29]
Toolformer: Language models can teach themselves to use tools, 2023
Timo Schick, Jane Dwivedi-Yu, Roberto Dessì, Roberta Raileanu, Maria Lomeli, Luke Zettle- moyer, Nicola Cancedda, and Thomas Scialom. Toolformer: Language models can teach themselves to use tools, 2023. URLhttps://arxiv.org/abs/2302.04761
Pith/arXiv arXiv 2023
-
[30]
Meta- learning characteristics and dynamics of quantum systems.arXiv preprint arXiv:2503.10492, 2025
Lucas Schorling, Pranav Vaidhyanathan, Jonas Schuff, Miguel J Carballido, Dominik Zumbühl, Gerard Milburn, Florian Marquardt, Jakob Foerster, Michael A Osborne, and Natalia Ares. Meta- learning characteristics and dynamics of quantum systems.arXiv preprint arXiv:2503.10492, 2025
arXiv 2025
-
[31]
Rethinking data selection for supervised fine-tuning.arXiv preprint arXiv:2402.06094, 2024
Ming Shen. Rethinking data selection for supervised fine-tuning.arXiv preprint arXiv:2402.06094, 2024. 11
arXiv 2024
-
[32]
Reflexion: Language agents with verbal reinforcement learning, 2023
Noah Shinn, Federico Cassano, Edward Berman, Ashwin Gopinath, Karthik Narasimhan, and Shunyu Yao. Reflexion: Language agents with verbal reinforcement learning, 2023. URL https://arxiv.org/abs/2303.11366
Pith/arXiv arXiv 2023
-
[33]
Openai gpt-5 system card, 2026
Aaditya Singh, Adam Fry, Adam Perelman, Adam Tart, Adi Ganesh, Ahmed El-Kishky, Aidan McLaughlin, Aiden Low, AJ Ostrow, Akhila Ananthram, Akshay Nathan, Alan Luo, Alec Helyar, Aleksander Madry, Aleksandr Efremov, Aleksandra Spyra, Alex Baker-Whitcomb, and et al. Openai gpt-5 system card, 2026. URLhttps://arxiv.org/abs/2601.03267
Pith/arXiv arXiv 2026
-
[34]
Dynamic cheatsheet: Test-time learning with adaptive memory, 2025
Mirac Suzgun, Mert Yuksekgonul, Federico Bianchi, Dan Jurafsky, and James Zou. Dynamic cheatsheet: Test-time learning with adaptive memory, 2025. URL https://arxiv.org/abs/ 2504.07952
arXiv 2025
-
[35]
Douglas Feitosa Tomé, Ying Zhang, Tomomi Aida, Olivia Mosto, Yifeng Lu, Mandy Chen, Sadra Sadeh, Dheeraj S. Roy, and Claudia Clopath. Dynamic and selective en- grams emerge with memory consolidation.Nature Neuroscience, 27:561–572, 2024. doi: 10.1038/s41593-023-01551-w
-
[36]
Sleep and the price of plasticity: from synaptic and cellular homeostasis to memory consolidation and integration.Neuron, 81(1):12–34, 2014
Giulio Tononi and Chiara Cirelli. Sleep and the price of plasticity: from synaptic and cellular homeostasis to memory consolidation and integration.Neuron, 81(1):12–34, 2014
2014
-
[37]
Pranav Vaidhyanathan, Aristotelis Papatheodorou, Mark T Mitchison, Natalia Ares, and Ioannis Havoutis. Metasym: A symplectic meta-learning framework for physical intelligence.arXiv preprint arXiv:2502.16667, 2025
arXiv 2025
-
[38]
Trace: A comprehensive benchmark for continual learning in large language models, 2023
Xiao Wang, Yuansen Zhang, Tianze Chen, Songyang Gao, Senjie Jin, Xianjun Yang, Zhiheng Xi, Rui Zheng, Yicheng Zou, Tao Gui, Qi Zhang, and Xuanjing Huang. Trace: A comprehensive benchmark for continual learning in large language models, 2023. URL https://arxiv.org/ abs/2310.06762
arXiv 2023
-
[39]
Learning to prompt for continual learning
Zifeng Wang, Zizhao Zhang, Chen-Yu Lee, Han Zhang, Ruoxi Sun, Xiaoqi Ren, Guolong Su, Vincent Perot, Jennifer Dy, and Tomas Pfister. Learning to prompt for continual learning. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 139–149, 2022
2022
-
[40]
Stream- bench: Towards benchmarking continuous improvement of language agents, 2024
Cheng-Kuang Wu, Zhi Rui Tam, Chieh-Yen Lin, Yun-Nung Chen, and Hung yi Lee. Stream- bench: Towards benchmarking continuous improvement of language agents, 2024. URL https://arxiv.org/abs/2406.08747
arXiv 2024
-
[41]
Long- memeval: Benchmarking chat assistants on long-term interactive memory, 2025
Di Wu, Hongwei Wang, Wenhao Yu, Yuwei Zhang, Kai-Wei Chang, and Dong Yu. Long- memeval: Benchmarking chat assistants on long-term interactive memory, 2025. URL https://arxiv.org/abs/2410.10813
Pith/arXiv arXiv 2025
-
[42]
A-mem: Agentic memory for llm agents, 2025
Wujiang Xu, Zujie Liang, Kai Mei, Hang Gao, Juntao Tan, and Yongfeng Zhang. A-mem: Agentic memory for llm agents, 2025. URLhttps://arxiv.org/abs/2502.12110
Pith/arXiv arXiv 2025
-
[43]
React: Synergizing reasoning and acting in language models, 2023
Shunyu Yao, Jeffrey Zhao, Dian Yu, Nan Du, Izhak Shafran, Karthik Narasimhan, and Yuan Cao. React: Synergizing reasoning and acting in language models, 2023. URL https: //arxiv.org/abs/2210.03629
Pith/arXiv arXiv 2023
-
[44]
τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024
Shunyu Yao, Noah Shinn, Pedram Razavi, and Karthik Narasimhan. τ-bench: A benchmark for tool-agent-user interaction in real-world domains, 2024. URL https://arxiv.org/abs/ 2406.12045
Pith/arXiv arXiv 2024
-
[45]
Mert Yuksekgonul, Federico Bianchi, Joseph Boen, Sheng Liu, Zhi Huang, Carlos Guestrin, and James Zou. Textgrad: Automatic "differentiation" via text, 2024. URL https://arxiv. org/abs/2406.07496
Pith/arXiv arXiv 2024
-
[46]
The shift from models to compound ai systems
Matei Zaharia, Omar Khattab, Lingjiao Chen, Jared Quincy Davis, Heather Miller, Chris Potts, James Zou, Michael Carbin, Jonathan Frankle, Naveen Rao, and Ali Ghodsi. The shift from models to compound ai systems. https://bair.berkeley.edu/blog/2024/02/18/ compound-ai-systems/, 2024. 12
2024
-
[47]
Qizheng Zhang, Changran Hu, Shubhangi Upasani, Boyuan Ma, Fenglu Hong, Vamsidhar Kamanuru, Jay Rainton, Chen Wu, Mengmeng Ji, Hanchen Li, Urmish Thakker, James Zou, and Kunle Olukotun. Agentic context engineering: Evolving contexts for self-improving language models, 2026. URLhttps://arxiv.org/abs/2510.04618. A RIZZ Formalism and Appendix Algorithms This ...
Pith/arXiv arXiv 2026
-
[48]
how should a prompt change?
extends the same principle to open-ended text-artifact optimization by preserving pairwise textual critiques as high-bandwidth directional information rather than collapsing comparisons to scalar preferences. RIZZ shares with these systems the premise that language is a useful optimization medium. However, the update target is different. GEPA and Feedback...
2000
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.