A-Evolve-Training: Autonomous Post-Training of a 30B Model
Pith reviewed 2026-06-27 13:09 UTC · model grok-4.3
The pith
An autonomous loop post-trained a 30B model to 0.86 leaderboard score and revised its search policy after detecting a misleading dev metric.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
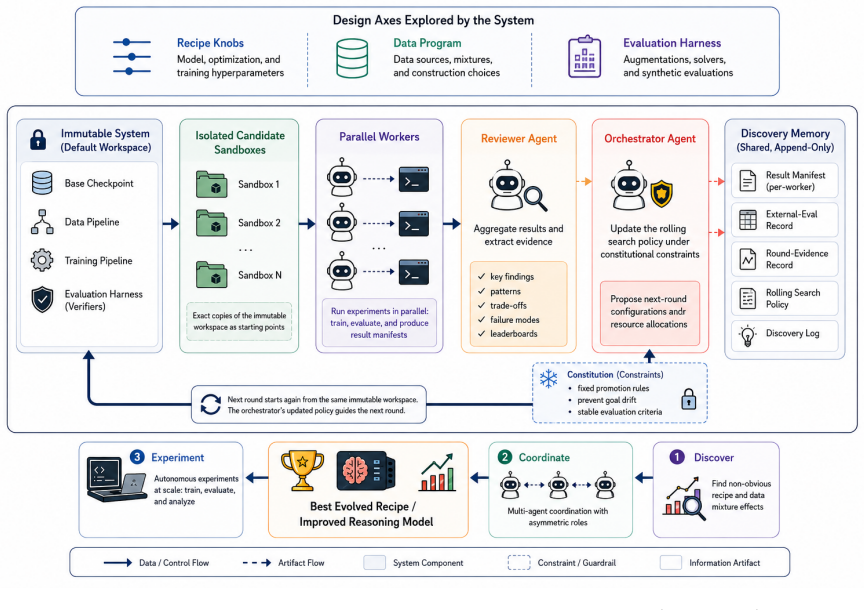
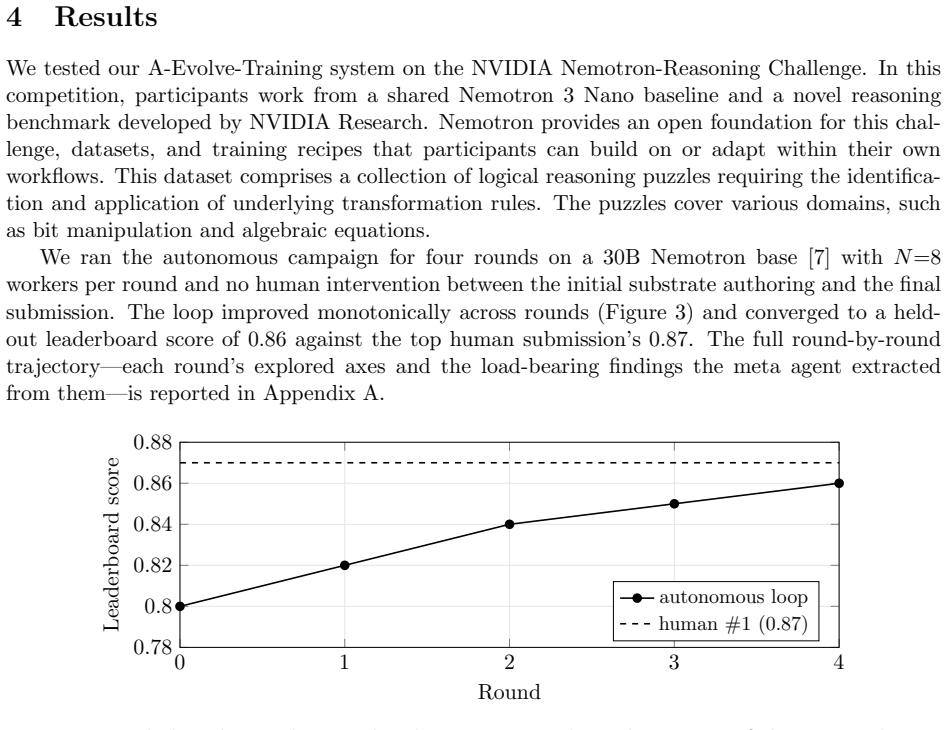
The autonomous system completed multiple weeks of post-training on the 30B Nemotron model and reached competitive held-out performance. It detected that candidate models were driving the internal dev metric to new highs without advancing the external target on one domain, then revised its search policy to seek changes that reduced the now-misleading proxy while raising the external score. This supplies an auditable record that the loop altered what counted as evidence inside its own process.
What carries the argument
The monitoring component inside the autonomous loop that compares dev-metric trajectories against external targets and triggers a policy revision when decoupling is observed.
If this is right
- The same loop architecture can close at 120B and 550B scales.
- An autonomous system can identify when its internal proxy has decoupled from the intended objective.
- Search policies can be updated mid-run on the basis of that detection without external direction.
- This constitutes one datapoint toward the operational requirement for recursive self-improvement.
- Prior public autonomous ML demonstrations remained at approximately 124M parameter budgets.
Where Pith is reading between the lines
- The detection mechanism could be applied to other evaluation suites to test whether similar metric drift occurs and triggers policy change.
- If the initial monitoring rules were altered, the frequency or type of self-correction might change.
- Repeating the experiment with an external target that is harder to measure could reveal limits on what kinds of decoupling the loop can detect.
- The approach suggests a route to systems that periodically audit and replace their own evaluation criteria.
Load-bearing premise
The observed policy revision qualifies as evidence of discovery and recursive self-improvement rather than the direct output of its pre-coded monitoring rules.
What would settle it
If external performance after the policy revision had remained no better than performance under continued dev-metric maximization, the claim that the revision produced discovery would not hold.
Figures

read the original abstract
Post-training a frontier model is normally weeks of human work: proposing data and recipe changes, launching runs, reading evals, deciding what to keep. We report an autonomous system that runs this loop with no human in the loop, post-training a 30B Nemotron across four rounds over multiple weeks. The autonomously produced model reaches a held-out score of 0.86 against the top human submission's 0.87 on the public NVIDIA Nemotron-Reasoning Challenge leaderboard, placing 8th of ~4000 at the time of writing. More striking than the number: the loop detected that its own dev metric had stopped tracking external performance on the weakest domain -- candidates drove dev to record highs without moving the external target -- and revised its own search policy, no longer maximizing dev but seeking interventions that lowered the now-misleading proxy while improving the external target. We treat this as direct, auditable evidence that a scaled autonomous loop can produce discovery, not only optimization: it detected that its measurement frame had become misleading and changed what counted as evidence. We take the operational view that any system worth the "recursive self-improvement" label must eventually perform end-to-end post-training of a frontier-class model; this is one datapoint of that bar being cleared. We do not claim a "first autonomous match" of human researchers. The claim we make is narrower and auditable: to our knowledge, this is the first publicly reported autonomous post-training run at this scale, where prior public autonomous-ML-research demonstrations sit at GPT-2-class (~124M) budgets. The same system also post-trains the 120B and 550B Nemotron; with no public human baseline there, this shows only that the loop closes at that scale, not that its output is competitive -- infrastructure evidence, with the effectiveness claim deferred until a comparable human anchor exists.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper claims that an autonomous system performed end-to-end post-training of a 30B Nemotron model over four rounds without human intervention, reaching a held-out score of 0.86 on the NVIDIA Nemotron-Reasoning Challenge (8th place). It further claims that the system detected its dev metric had become misleading on the weakest domain (candidates maximized dev without improving the external target) and autonomously revised its search policy to de-emphasize the proxy, treating this as direct auditable evidence of discovery and recursive self-improvement at frontier scale, beyond prior public demonstrations limited to ~124M models.
Significance. If the implementation details and logs substantiate the metric-revision claim, the result would be significant as the first public report of a closed autonomous post-training loop at 30B scale, supplying infrastructure evidence that such loops can operate at frontier budgets and explicitly revising an internal measurement frame. The narrower, auditable framing (rather than claiming first match to human researchers) and the explicit contrast with smaller-scale prior work are strengths.
major comments (2)
- [Abstract] Abstract: the central claim that the system 'detected that its own dev metric had stopped tracking external performance' and 'revised its own search policy' constitutes 'direct, auditable evidence' of discovery is load-bearing for the recursive-self-improvement interpretation, yet the manuscript supplies no description of the monitoring implementation, threshold logic, decision procedure, or logs that produced the revision; without these it is impossible to determine whether the behavior was an execution of pre-specified rules or an unanticipated change.
- [Abstract] Abstract: the soundness assessment of the 0.86 held-out score and the four-round autonomous run is undermined by the absence of any verification method, controls, or reproducibility details for the candidate generation, evaluation, and policy-revision steps; this directly affects whether the external-target improvement can be attributed to the reported policy change.
Simulated Author's Rebuttal
We thank the referee for identifying the need for greater transparency on implementation details. The comments correctly note that the submitted manuscript did not provide sufficient description of the monitoring, decision logic, or controls. We will revise the paper to include these elements in a dedicated methods subsection.
read point-by-point responses
-
Referee: [Abstract] Abstract: the central claim that the system 'detected that its own dev metric had stopped tracking external performance' and 'revised its own search policy' constitutes 'direct, auditable evidence' of discovery is load-bearing for the recursive-self-improvement interpretation, yet the manuscript supplies no description of the monitoring implementation, threshold logic, decision procedure, or logs that produced the revision; without these it is impossible to determine whether the behavior was an execution of pre-specified rules or an unanticipated change.
Authors: We agree that the initial submission omitted these specifics. The revised manuscript will add a new subsection detailing the monitoring implementation (including the exact divergence detection logic between dev and external metrics), the threshold values and statistical criteria used, the rule-based decision procedure that triggered the policy revision, and anonymized log excerpts showing the sequence of observations and the resulting policy update. This will demonstrate that the change followed the system's pre-specified autonomous rules. revision: yes
-
Referee: [Abstract] Abstract: the soundness assessment of the 0.86 held-out score and the four-round autonomous run is undermined by the absence of any verification method, controls, or reproducibility details for the candidate generation, evaluation, and policy-revision steps; this directly affects whether the external-target improvement can be attributed to the reported policy change.
Authors: We accept this point. The revision will incorporate a reproducibility and controls section describing verification methods for candidate generation and evaluation (e.g., independent re-evaluation protocols and logging), experimental controls used during the four-round run, and how the policy revision's contribution to external-target gains was isolated and logged. These additions will allow readers to assess attribution. revision: yes
Circularity Check
No circularity: empirical report of observed system behavior
full rationale
The paper is an empirical report of an autonomous post-training run on a 30B model, describing observed outcomes including a policy revision after detecting a dev metric mismatch with external performance. No equations, fitted parameters renamed as predictions, or self-citation chains are present in the provided text that would reduce the claimed discovery to the system's input rules by construction. The central claim rests on the auditable run log rather than any definitional equivalence or imported uniqueness theorem, making the derivation self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
Chris Lu, Cong Lu, Robert Tjarko Lange, Jakob Foerster, Jeff Clune, and David Ha.The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery. arXiv:2408.06292, 2024
work page internal anchor Pith review Pith/arXiv arXiv 2024
-
[2]
Bingchen Zhao, Despoina Magka, Minqi Jiang, et al.The Automated LLM Speedrunning Bench- mark: Reproducing NanoGPT Improvements. arXiv:2506.22419, 2025
-
[3]
AlphaEvolve: A coding agent for scientific and algorithmic discovery
Alexander Novikov, Ngˆ an V˜ u, Marvin Eisenberger, et al.AlphaEvolve: A coding agent for scientific and algorithmic discovery. Google DeepMind white paper, arXiv:2506.13131, 2025. 10
work page internal anchor Pith review Pith/arXiv arXiv 2025
-
[4]
OpenEvolve: open-source implementation of AlphaEvolve.https://github.com/codelion/ openevolve
-
[5]
Xin He, Kaiyong Zhao, and Xiaowen Chu.AutoML: A Survey of the State-of-the-Art. arXiv:1908.00709, 2019
-
[6]
Andrej Karpathy.nanoGPT: the simplest, fastest repository for training/finetuning medium- sized GPTs.https://github.com/karpathy/nanoGPT
-
[7]
Technical report, 2025.https://arxiv.org/abs/2512.20848
NVIDIA.Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning. Technical report, 2025.https://arxiv.org/abs/2512.20848
-
[8]
A-EVO Lab.A-Evolve: open-source framework for self-evolving LLM agents and autonomous research loops.https://github.com/A-EVO-Lab/a-evolve
-
[9]
Research memo, 2026.https://github.com/A-EVO-Lab/.github/blob/main/ memo_AEVOLVE_AI_as_Researcher.pdf
Hanqing Lu.A-Evolve: Our Shared Mental Model — Self-Evolving Agents with Frontier Models as Researchers. Research memo, 2026.https://github.com/A-EVO-Lab/.github/blob/main/ memo_AEVOLVE_AI_as_Researcher.pdf. 11 A Round-by-round trajectory Table 2: Round-by-round trajectory of the autonomous campaign. Scores mirror Figure 3. The central discovery is a stra...
2026
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.