Eigenspace-Based Clustering for Personalized System Identification
Pith reviewed 2026-06-26 15:36 UTC · model grok-4.3
The pith
Systems with shared dynamics can be clustered by aligning the leading eigenspaces of their estimated state covariance matrices without training.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
The paper claims that the alignment between the leading eigenspaces of locally estimated state covariance matrices provides a similarity score that correctly identifies clusters of systems sharing the same underlying dynamics, with the score's reliability established by a perturbation analysis that links covariance estimation error to eigenspace deviations and by derived probability bounds on false merges together with an overall clustering success guarantee.
What carries the argument
The eigenspace alignment similarity score, which quantifies overlap between the dominant eigenvectors of each system's estimated state covariance matrix and thereby infers shared dynamics.
If this is right
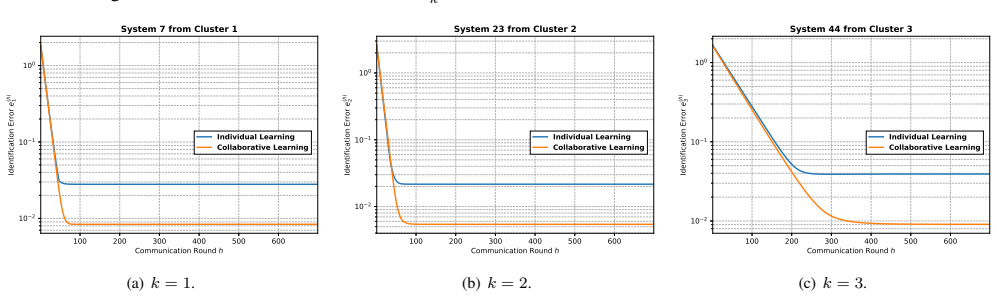
- The method yields lower personalized model-estimation error than both non-clustered baselines and training-based clustering approaches.
- The probability of pairwise false merges is bounded explicitly in terms of sample size and system dynamics.
- A global success probability guarantee follows directly from the pairwise bounds under the stated conditions on estimation error.
- The one-shot procedure avoids the sensitivity to model initialization and learning uncertainty that affects iterative cluster assignment.
Where Pith is reading between the lines
- The geometric view of system similarity via covariance eigenspaces could be tested on data with partial state observations to see whether the alignment score remains informative.
- If the perturbation bounds prove tight in practice, they could guide minimum data collection requirements before clustering decisions are made.
- The same covariance-eigenspace idea might transfer to other heterogeneous time-series settings where dynamics are unknown but local second-moment structure is observable.
Load-bearing premise
The leading eigenspaces of the estimated state covariance matrices align in a manner that reliably reflects shared underlying dynamics.
What would settle it
A simulation in which systems known to share identical dynamics produce leading covariance eigenspaces that are misaligned enough to cause false non-merges at a rate exceeding the paper's probability bound would falsify the finite-sample guarantee.
Figures


read the original abstract
We study the problem of system identification in heterogeneous settings, where different systems may follow distinct underlying dynamics. Existing clustered system identification approaches often rely on iterative training-based cluster assignment, which can be sensitive to learning uncertainty and model initialization. In contrast, we propose a one-shot, training-free clustering method that identifies similar systems using the structure of their locally observed data. Specifically, each system estimates a local state covariance matrix, and cluster identities are inferred by measuring the alignment between the leading covariance eigenspaces of different systems. We provide a mathematical interpretation of the proposed similarity score and develop a finite-sample analysis that characterizes how covariance estimation error induces eigenspace perturbations in terms of the underlying system dynamics. We then derive a probability bound for pairwise false merges and a global clustering success guarantee. Numerical experiments demonstrate that the proposed eigenspace-based clustering method effectively identifies systems with shared dynamics, leading to lower personalized model-estimation error compared with training-based clustering and non-clustered baselines.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper proposes a one-shot, training-free clustering method for personalized system identification in heterogeneous settings. Systems are clustered by measuring alignment of the leading eigenspaces of their locally estimated state covariance matrices; the method includes a mathematical interpretation of the similarity score, a finite-sample perturbation analysis relating covariance estimation error to eigenspace misalignment in terms of system dynamics, explicit probability bounds on pairwise false merges, and a global clustering success guarantee. Experiments show improved personalized model estimation error relative to iterative training-based clustering and non-clustered baselines.
Significance. If the finite-sample bounds and clustering guarantees hold, the approach supplies a non-iterative alternative to existing clustered system identification methods that avoids sensitivity to model initialization and training uncertainty. The explicit linkage of covariance perturbation to eigenspace error and the derivation of false-merge probabilities constitute a concrete theoretical contribution in the eess.SY setting.
minor comments (3)
- The abstract states that the similarity score receives a 'mathematical interpretation,' but the precise definition of the alignment metric (e.g., principal-angle or subspace-distance formula) should be stated explicitly in the main text before the perturbation analysis begins.
- In the finite-sample analysis, the dependence of the eigenspace perturbation bound on the system order n and the number of samples T should be made fully explicit; currently the scaling with respect to the smallest eigenvalue gap is only sketched.
- The experimental section should report the precise data-exclusion rules and the number of Monte-Carlo trials used to generate the error bars; without these details the comparison to training-based baselines is difficult to reproduce.
Simulated Author's Rebuttal
We thank the referee for the positive summary, significance assessment, and recommendation of minor revision. The report accurately captures the core contributions of the one-shot eigenspace-based clustering approach, including the finite-sample perturbation analysis and clustering guarantees. No specific major comments were raised in the report.
Circularity Check
No significant circularity in derivation chain
full rationale
The paper proposes an eigenspace alignment method for clustering systems by shared dynamics, then derives a finite-sample analysis of covariance estimation error inducing eigenspace perturbations, plus explicit probability bounds on false merges and a global clustering guarantee. These steps are presented as following from standard covariance perturbation results expressed in terms of the underlying dynamics, without any reduction of the claimed guarantees to fitted parameters, self-definitional constructs, or load-bearing self-citations. The analysis is self-contained against external mathematical benchmarks and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Covariance matrices estimated from local state data capture sufficient information about underlying linear dynamics for eigenspace comparison to indicate shared dynamics.
Reference graph
Works this paper leans on
-
[1]
H. B. McMahan, E. Moore, D. Ramage, S. Hampson, and B. A. y A rcas. Communication-efficient learning of deep networks from dec entralized data. In Proc. AISTATS, April 2017
2017
-
[2]
H. Wang, L. F. Toso, and J. Anderson. FedSysID: A federate d approach to sample-efficient system identification. In Proc. of The 5th Annual Learning for Dynamics and Control Conference , Jun 2023
2023
-
[3]
L. F. Toso, H. Wang, and J. Anderson. Learning personaliz ed models with clustered system identification. In Proc. IEEE CDC , 2023
2023
-
[4]
Kec ¸eci, M
E. Kec ¸eci, M. G¨ uzelkaya, and T. Kumbasar. A novel feder ated learning framework for system identification. In IEEE IDAP , September 2024
2024
-
[5]
E. Kec ¸eci, M. G¨ uzelkaya, and T. Kumbasar. Redefining cl ustered federated learning for system identification: The path of cl ustercraft. Available online:arXiv:2505.16857
-
[6]
M. M. Amiri, F. Berdoz, and R. Raskar. Fundamentals of tas k-agnostic data valuation. In Proc. AAAI , June 2023
2023
-
[7]
Ali and A
A. Ali and A. Arafa. Data similarity-based one-shot clus tering for multi- task hierarchical federated learning. In Proc. Asilomar, October 2024
2024
-
[8]
Ali and A
A. Ali and A. Arafa. RCC-PFL: Robust client clustering un der noisy labels in personalized federated learning. In Proc. ICC, June 2025
2025
-
[9]
FB-NLL: A Feature-Based Approach to Tackle Noisy Labels in Personalized Federated Learning
A. Ali and A. Arafa. FB-NLL: A feature-based approach to t ackle noisy labels in personalized federated learning. Availabl e online: arXiv:2604.19729
work page internal anchor Pith review Pith/arXiv arXiv
-
[10]
K. P . Murphy. Probabilistic Machine Learning: An introduction . MIT Press, 2022
2022
-
[11]
G. W. Stewart and Ji-guang Sun. Matrix Perturbation Theory. Academic Press, San Diego, 1990
1990
-
[12]
High-Dimensional Probability: An Introduction with Applications in Data Science
Roman V ershynin. High-Dimensional Probability: An Introduction with Applications in Data Science . Cambridge Series in Statistical and Probabilistic Mathematics. Cambridge University Press, C ambridge, 2 edition, 2026
2026
-
[13]
Kim, Jongwoo Ko, JinHwan Choi, Se-Y oung Y un, et al
T. Kim, Jongwoo Ko, JinHwan Choi, Se-Y oung Y un, et al. Fi ne samples for learning with noisy labels. In Proc. NeurIPS , December 2021
2021
- [14]
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.