ReSequel: Robust LLM-assisted Query Rewriting and Optimization using Templatization and Sampling
Pith reviewed 2026-06-26 14:55 UTC · model grok-4.3
The pith
ReSequel uses LLM query rewriting with templatization and sampling to deliver up to 16x speedups over native DBMSs.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
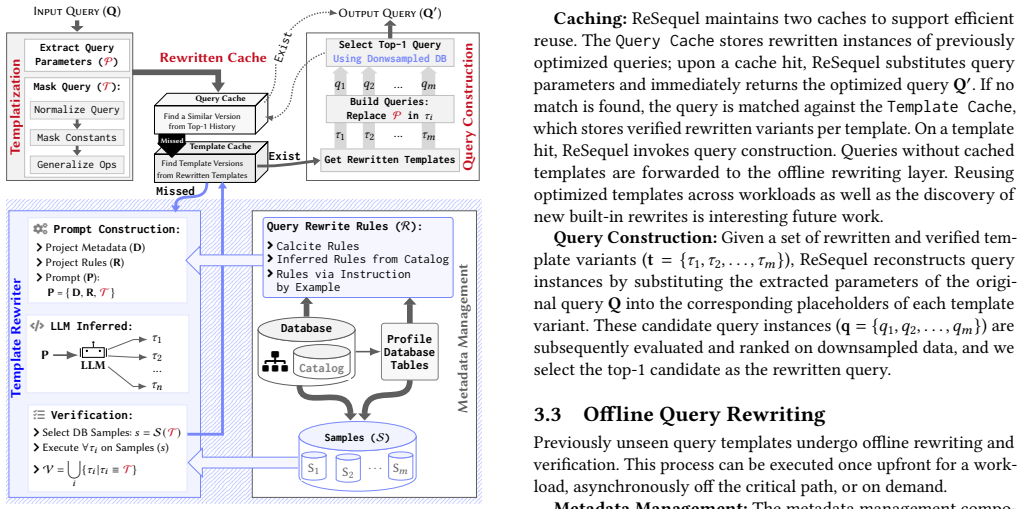
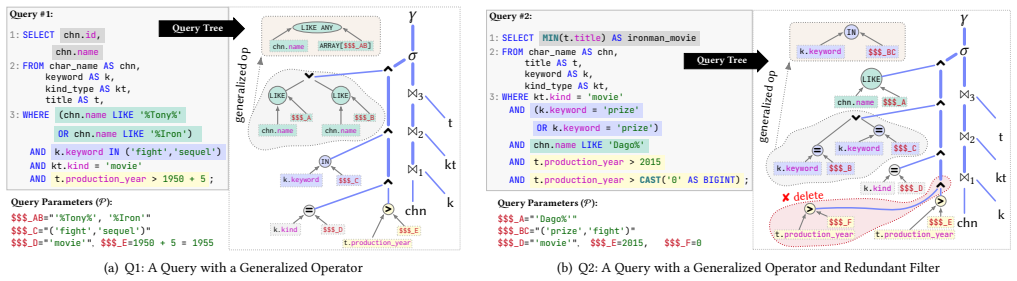
ReSequel is an outer optimization layer on top of existing DBMSs that rewrites SQL queries using LLMs guided by template-specific rules inferred from catalog and statistical metadata. Rewritten query variants are generated, verified for result correctness, and ranked by runtime on sampled data to ensure both semantic equivalence and performance improvements.
What carries the argument
Templatization to infer template-specific rules from metadata that guide the LLM, combined with sampling-based generation, verification, and ranking of query variants.
If this is right
- Workload-level speedups of up to 16x over native DBMSs.
- Up to 22x speedups over LLM-based systems.
- Individual queries can see speedups exceeding 600x.
- Consistent gains across eight benchmarks including JOB, TPC-H, and three DBMSs: PostgreSQL, MySQL, DuckDB.
Where Pith is reading between the lines
- The method could potentially be adapted for other data query languages beyond SQL.
- Integration with cost-based optimizers might further enhance the rewrites.
- Long-term, this could shift focus from maintaining static rewrite rules to dynamic, data-driven ones.
- Further testing on production workloads with varying data distributions would strengthen the approach.
Load-bearing premise
That verification and performance measurement on sampled data accurately predicts behavior on the full dataset without issues from data distribution shifts or rare values.
What would settle it
A rewritten query that passes verification and shows improvement on samples but fails to produce correct results or delivers no speedup when executed on the complete dataset.
Figures











read the original abstract
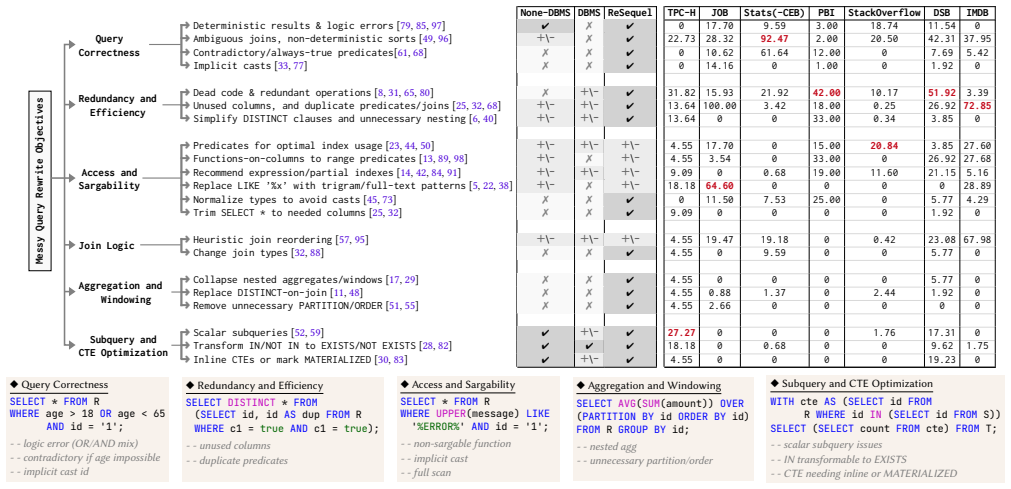
Heuristic query rewriting has long complemented cost-based optimization to improve performance. Such rewrites transform SQL queries into semantically equivalent forms that are easier or faster to execute. Examples are standardizing expressions, eliminating redundancy, propagating constants, pushing down selections and projections, unnesting queries, and utilizing constraints. Modern DBMSs implement hundreds to thousands of such rules, but maintaining them is notoriously difficult. The interactions among rules are complex, and their static nature and application order prevent adaptation to specific query and database characteristics. Recent approaches that use large language models (LLMs) for query rewriting show promise but face challenges regarding the large search space, reliable query verification, and exploitation of metadata. We present ReSequel, an outer optimization layer on top of existing DBMSs to rewrite SQL queries using LLMs. ReSequel leverages catalog and statistical metadata to infer template-specific rules that guide the LLM toward effective query transformations. We generate, verify, and rank rewritten query variants on sampled data to ensure result correctness and runtime improvements. Our experiments cover eight benchmarks: JOB, TPC-H, Stats(-CEB), Public BI, IMDB, DSB, and StackOverflow; multiple DBMSs: PostgreSQL, MySQL, and DuckDB; as well as LLM-based query rewriting baselines. ReSequel yields workload-level speedups of up to 16x over native DBMSs and 22x over LLM-based systems, with individual queries exceeding 600x, across eight benchmarks and three DBMSs.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. ReSequel is presented as an outer optimization layer atop existing DBMSs that uses LLMs guided by catalog/statistical metadata and template-specific rules to generate SQL rewrites; rewrites are generated, verified for semantic equivalence, and ranked for runtime improvement by execution on sampled data, with experiments across eight benchmarks (JOB, TPC-H, Stats-CEB, Public BI, IMDB, DSB, StackOverflow) and three DBMSs (PostgreSQL, MySQL, DuckDB) claiming workload speedups up to 16× over native engines and 22× over prior LLM baselines, with individual queries exceeding 600×.
Significance. If the central empirical claims hold under rigorous full-data verification, the work would be significant for demonstrating a practical, metadata-aware LLM integration into query optimization that addresses rule-maintenance difficulties in traditional rewriters while providing measurable gains over both native and prior LLM approaches; the multi-DBMS, multi-benchmark scope and use of templatization to constrain the search space are strengths.
major comments (3)
- [§4] §4 (Experimental Methodology) and abstract: the reported speedups rest on sampled-data verification of both equivalence and runtime; the manuscript provides no quantitative characterization of sample sizes, sampling method (e.g., uniform vs. stratified), or failure rates of the verification step, leaving open whether rare predicates, low-selectivity joins, or skewed aggregates are adequately covered.
- [§3.3] Verification procedure (likely §3.3): semantic equivalence and runtime gains observed on a sample do not necessarily transfer to the full dataset when cardinality estimates, plan selection, or I/O behavior change with full data volume; the headline 16× workload and 600× single-query claims therefore require explicit evidence that sampled checks are sufficient proxies.
- [Results tables] Table or figure reporting per-benchmark results: without disclosure of how many rewrites were rejected by the verifier, how often the LLM produced syntactically invalid SQL, or the distribution of speedups conditional on successful verification, the aggregate speedup numbers cannot be interpreted as robust.
minor comments (2)
- [§3.1] Notation for template rules and metadata usage could be formalized with a small example query and its template to improve reproducibility.
- [Abstract and §4] The abstract lists eight benchmarks but the text should explicitly state whether all were run on all three DBMSs or whether some combinations were omitted.
Simulated Author's Rebuttal
Thank you for the thorough review and constructive feedback on our manuscript. We appreciate the referee's recognition of the significance of our work and address each major comment point by point below. We will make revisions to improve the clarity and robustness of the experimental methodology section.
read point-by-point responses
-
Referee: [§4] §4 (Experimental Methodology) and abstract: the reported speedups rest on sampled-data verification of both equivalence and runtime; the manuscript provides no quantitative characterization of sample sizes, sampling method (e.g., uniform vs. stratified), or failure rates of the verification step, leaving open whether rare predicates, low-selectivity joins, or skewed aggregates are adequately covered.
Authors: We acknowledge that the current manuscript does not provide sufficient quantitative details on the sampling procedure used for verification. In the revised manuscript, we will expand §4 to include: (1) the sampling method, which is uniform random sampling of a fixed number of rows (10,000 rows for large tables, or 1% for smaller ones); (2) sample sizes for each benchmark; and (3) failure rates, which were approximately 15% for equivalence checks across the experiments. We will also add a discussion on how the metadata-guided templatization helps in covering diverse query patterns, including those with rare predicates. revision: yes
-
Referee: [§3.3] Verification procedure (likely §3.3): semantic equivalence and runtime gains observed on a sample do not necessarily transfer to the full dataset when cardinality estimates, plan selection, or I/O behavior change with full data volume; the headline 16× workload and 600× single-query claims therefore require explicit evidence that sampled checks are sufficient proxies.
Authors: This point highlights a potential limitation of sampling-based verification. While we believe the sampled verification is a reasonable proxy because the rewrites are semantically equivalent and the runtime improvements are measured on the same DBMS, we agree that explicit evidence is valuable. In the revision, we will add a new experiment section where we verify a random sample of 50 queries on the full dataset to confirm that the speedups are consistent. We will report the correlation between sample and full-data speedups. However, full verification for all queries is not feasible due to time constraints, which is why sampling is used in the first place. revision: partial
-
Referee: [Results tables] Table or figure reporting per-benchmark results: without disclosure of how many rewrites were rejected by the verifier, how often the LLM produced syntactically invalid SQL, or the distribution of speedups conditional on successful verification, the aggregate speedup numbers cannot be interpreted as robust.
Authors: We agree that additional transparency on the verification outcomes would strengthen the results. We will revise the results section to include a new table or subsection reporting: the average number of rewrites generated per query, the percentage of rewrites rejected due to failed equivalence or runtime regression, the rate of invalid SQL (which was low at under 5% due to our templatization), and the distribution of speedups (e.g., median, quartiles) for accepted rewrites. This will allow readers to better interpret the aggregate numbers. revision: yes
Circularity Check
No significant circularity; empirical results on external benchmarks
full rationale
The paper describes a system (ReSequel) that applies LLMs to SQL rewriting guided by templates and metadata, then verifies/ranks candidates via execution on sampled data before reporting full-dataset speedups. All load-bearing claims are direct experimental measurements (workload speedups up to 16×, single-query up to 600×) on eight named external benchmarks across three DBMSs. No equations, fitted parameters, or self-referential derivations appear; the sampling step is a methodological choice whose validity is an empirical question, not a definitional reduction. No self-citation chains are invoked as uniqueness theorems or load-bearing premises. The derivation chain is therefore self-contained against external benchmarks.
Axiom & Free-Parameter Ledger
axioms (2)
- domain assumption LLMs guided by template-specific rules inferred from catalog and statistical metadata will produce semantically equivalent and faster query rewrites
- domain assumption Verification of equivalence and performance on sampled data generalizes to the full dataset
Reference graph
Works this paper leans on
-
[1]
Apache Calcite is a dynamic data management framework
2025. Apache Calcite is a dynamic data management framework. https: //calcite.apache.org/
2025
-
[2]
Groq Cloud
2025. Groq Cloud. https://console.groq.com/
2025
-
[3]
Peter Akioyamen, Zixuan Yi, and Ryan Marcus. 2024. The Unreasonable Effectiveness of LLMs for Query Optimization.NeurIPS(2024). https: //doi.org/10.48550/ARXIV.2411.02862
-
[4]
Morton M. Astrahan et al. 1976. System R: Relational Approach to Database Management.ACM Trans. Database Syst.1, 2 (1976), 97–137. https://doi.org/10. 1145/320455.320457
arXiv 1976
-
[5]
Qiushi Bai, Sadeem Alsudais, and Chen Li. 2023. QueryBooster: Improving SQL Performance Using Middleware Services for Human-Centered Query Rewriting. PVLDB16, 11 (2023), 2911–2924. https://doi.org/10.14778/3611479.3611497
-
[6]
Eirik Bakke and David R. Karger. 2016. Expressive Query Construction through Direct Manipulation of Nested Relational Results. InSIGMOD. 1377–1392. https: //doi.org/10.1145/2882903.2915210
-
[7]
Zhuowei Bao, Benny Kimelfeld, and Yunyao Li. 2012. Automatic suggestion of query-rewrite rules for enterprise search. InSIGIR. 591–600. https://doi.org/10. 1145/2348283.2348363
arXiv 2012
-
[8]
Alexander Baumstark, Muhammad Attahir Jibril, and Kai-Uwe Sattler. 2023. Adaptive query compilation in graph databases.Distributed Parallel Databases 41, 3 (2023), 359–386. https://doi.org/10.1007/S10619-023-07430-4
-
[9]
Edmon Begoli, Jesús Camacho-Rodríguez, Julian Hyde, Michael J. Mior, and Daniel Lemire. 2018. Apache Calcite: A Foundational Framework for Optimized Query Processing Over Heterogeneous Data Sources. InSIGMOD. 221–230. https://doi.org/10.1145/3183713.3190662
-
[10]
Hal Berenson, Philip A. Bernstein, Jim Gray, Jim Melton, Elizabeth J. O’Neil, and Patrick E. O’Neil. 1995. A Critique of ANSI SQL Isolation Levels. InSIGMOD. 1–10. https://doi.org/10.1145/223784.223785
-
[11]
Altan Birler, Alfons Kemper, and Thomas Neumann. 2024. Robust Join Pro- cessing with Diamond Hardened Joins.PVLDB17, 11 (2024), 3215–3228. https://doi.org/10.14778/3681954.3681995
-
[12]
Burdick, Alexandre V
Matthias Böhm, Douglas R. Burdick, Alexandre V. Evfimievski, Berthold Rein- wald, Frederick R. Reiss, Prithviraj Sen, Shirish Tatikonda, and Yuanyuan Tian
-
[13]
Bull.37, 3 (2014), 52–62
SystemML’s Optimizer: Plan Generation for Large-Scale Machine Learn- ing Programs.Data Eng. Bull.37, 3 (2014), 52–62. http://sites.computer.org/ debull/A14sept/p52.pdf
2014
-
[14]
Nicolas Bruno and Surajit Chaudhuri. 2006. To Tune or not to Tune? A Light- weight Physical Design Alerter. InVLDB. 499–510. http://dl.acm.org/citation. cfm?id=1164171
2006
-
[15]
Sunil Chakkappen, Shreya Kunjibettu, Daniel Mcgreer, Masoomeh Kishi, Hong Su, Mohamed Ziauddin, Mohamed Zaït, Zhan Li, and Yuying Zhang. 2025. Automatic Indexing in Oracle.PVLDB18, 12 (2025), 4924–4937. https://doi.org/ 10.14778/3750601.3750616
-
[16]
Donald D. Chamberlin, Morton M. Astrahan, Kapali P. Eswaran, Patricia P. Griffiths, Raymond A. Lorie, James W. Mehl, Phyllis Reisner, and Bradford W. Wade. 1976. SEQUEL 2: A Unified Approach to Data Definition, Manipulation, and Control.IBM J. Res. Dev.20, 6 (1976), 560–575. https://doi.org/10.1147/RD. 206.0560
work page doi:10.1147/rd 1976
-
[17]
Donald D. Chamberlin and Raymond F. Boyce. 1974. SEQUEL: A Structured English Query Language. InSIGMOD. 249–264. https://doi.org/10.1145/800296. 811515
-
[18]
Ioannidis
Konstantinos Chasialis, Yannis Foufoulas, Alkis Simitsis, and Yannis E. Ioannidis
-
[19]
Optimizing UDF Queries in SQL Data Engines. InEDBT. https://doi.org/ 10.48786/EDBT.2026.21
-
[20]
Surajit Chaudhuri and Kyuseok Shim. 1994. Including Group-By in Query Optimization. InVLDB. 354–366. http://www.vldb.org/conf/1994/P354.PDF
1994
-
[21]
Transaction Processing Council. 2025. https://www.tpc.org/tpch
2025
-
[22]
Bailu Ding, Surajit Chaudhuri, Johannes Gehrke, and Vivek Narasayya. 2021. DSB: A decision support benchmark for workload-driven and traditional data- base systems.PVLDB14, 13 (2021), 3376–3388. https://doi.org/10.14778/3484224. 3484234
-
[23]
Haoran Ding, Zhaoguo Wang, Yicun Yang, Dexin Zhang, Zhenglin Xu, Haibo Chen, Ruzica Piskac, and Jinyang Li. 2023. Proving Query Equivalence Using Linear Integer Arithmetic.Proc. ACM Manag. Data1, 4 (2023), 227:1–227:26. https://doi.org/10.1145/3626768
-
[24]
Jens Dittrich and Joris Nix. 2020. The Case for Deep Query Optimisation. In CIDR. http://cidrdb.org/cidr2020/papers/p3-dittrich-cidr20.pdf
2020
-
[25]
Jens Dittrich, Joris Nix, and Christian Schön. 2021. The next 50 Years in Database Indexing or: The Case for Automatically Generated Index Structures.PVLDB 15, 3 (2021), 527–540. https://doi.org/10.14778/3494124.3494136
-
[26]
Rui Dong, Jie Liu, Yuxuan Zhu, Cong Yan, Barzan Mozafari, and Xinyu Wang
-
[27]
VLDB Endow.16, 11 (2023), 3151–3164
SlabCity: Whole-Query Optimization Using Program Synthesis.PVLDB 16, 11 (2023), 3151–3164. https://doi.org/10.14778/3611479.3611515
-
[28]
Markus Dreseler, Martin Boissier, Tilmann Rabl, and Matthias Uflacker. 2020. Quantifying TPC-H Choke Points and Their Optimizations.VLDB13, 8 (2020), 1206–1220. https://doi.org/10.14778/3389133.3389138
-
[29]
Evfimievski, Shirish Tatikonda, Berthold Reinwald, and Prithviraj Sen
Tarek Elgamal, Shangyu Luo, Matthias Boehm, Alexandre V. Evfimievski, Shirish Tatikonda, Berthold Reinwald, and Prithviraj Sen. 2017. SPOOF: Sum-Product Optimization and Operator Fusion for Large-Scale Machine Learning. InCIDR. http://cidrdb.org/cidr2017/papers/p3-elgamal-cidr17.pdf
2017
-
[30]
Jingzhi Fang, Yanyan Shen, Yue Wang, and Lei Chen. 2020. Optimizing DNN Computation Graph using Graph Substitutions.PVLDB13, 11 (2020), 2734–2746. http://www.vldb.org/pvldb/vol13/p2734-fang.pdf
2020
-
[31]
Amela Fejza, Pierre Genevès, and Nabil Layaïda. 2024. Efficient Enumeration of Recursive Plans in Transformation-based Query Optimizers.PVLDB17, 11 (2024), 3095–3108. https://doi.org/10.14778/3681954.3681986
-
[32]
Philipp Fent, Altan Birler, and Thomas Neumann. 2023. Practical planning and execution of groupjoin and nested aggregates.VLDB J.32, 6 (2023), 1165–1190. https://doi.org/10.1007/S00778-022-00765-X
-
[33]
Sofoklis Floratos, Ahmad Ghazal, Jason Sun, Jianjun Chen, and Xiaodong Zhang
-
[34]
DBSpinner: Making a Case for Iterative Processing in Databases. InICDE. 2399–2410. https://doi.org/10.1109/ICDE51399.2021.00273
-
[35]
Yannis Foufoulas and Alkis Simitsis. 2023. Efficient Execution of User-Defined Functions in SQL Queries.VLDB16, 12 (2023), 3874–3877. https://doi.org/10. 14778/3611540.3611574
arXiv 2023
-
[36]
Freitag, Maximilian Bandle, Tobias Schmidt, Alfons Kemper, and Thomas Neumann
Michael J. Freitag, Maximilian Bandle, Tobias Schmidt, Alfons Kemper, and Thomas Neumann. 2020. Adopting Worst-Case Optimal Joins in Relational Database Systems.VLDB13, 11 (2020), 1891–1904. http://www.vldb.org/pvldb/ vol13/p1891-freitag.pdf
2020
-
[37]
Jonathan Fürst, Catherine Kosten, Farhad Nooralahzadeh, Yi Zhang, and Kurt Stockinger. 2025. Evaluating the Data Model Robustness of Text-to-SQL Systems Based on Real User Queries. InEDBT. https://doi.org/10.48786/EDBT.2025.13
-
[38]
Rainer Gemulla, Philipp Rösch, and Wolfgang Lehner. 2008. Linked Bernoulli Synopses: Sampling along Foreign Keys. InSSDBM, Vol. 5069. 6–23. https: //doi.org/10.1007/978-3-540-69497-7_4
-
[39]
Parke Godfrey, Jarek Gryz, Andrzej Hoppe, Wenbin Ma, and Calisto Zuzarte
-
[40]
Query Rewrites with Views for XML in DB2. InICDE. 1339–1350. https: //doi.org/10.1109/ICDE.2009.131
-
[41]
Google. 2025. https://gemini.google.com
2025
-
[42]
Goetz Graefe. 1995. The Cascades Framework for Query Optimization.Data Eng. Bull.18, 3 (1995), 19–29. http://sites.computer.org/debull/95SEP-CD.pdf
1995
-
[43]
Luca Gretscher and Jens Dittrich. 2025. How to Optimize SQL Queries? A Comparison Between Split, Holistic, and Hybrid Approaches.PVLDB18, 11 (2025), 3910–3922. https://doi.org/10.14778/3749646.3749663
-
[44]
CWI Database Architectures Group. 2025. https://github.com/cwida/public_bi_ benchmark
2025
-
[45]
Immanuel Haffner and Jens Dittrich. 2023. A simplified Architecture for Fast, Adaptive Compilation and Execution of SQL Queries. InEDBT. https://doi.org/ 10.48786/EDBT.2023.01
-
[46]
Yuxing Han et al. 2021. Cardinality Estimation in DBMS: A Comprehensive Benchmark Evaluation.PVLDB15, 4 (2021), 752–765. https://doi.org/10.14778/ 3503585.3503586
arXiv 2021
-
[47]
Cinda Heeren, H. V. Jagadish, and Leonard Pitt. 2003. Optimal indexing using near-minimal space. InPODS. 244–251. https://doi.org/10.1145/773153.773177
-
[48]
Gerald Held, Michael Stonebraker, and Eugene Wong. 1975. INGRES: A Rela- tional Data Base System. InAFIPS, Vol. 44. 409–416. https://doi.org/10.1145/ 1499949.1500029
arXiv 1975
-
[49]
Waddington, and Adam Mor- rison
Moshik Hershcovitch, Artem Khyzha, Daniel G. Waddington, and Adam Mor- rison. 2022. Elastic Indexes: Dynamic Space vs. Query Efficiency Tuning for In-Memory Database Indexing. InEDBT. https://doi.org/10.48786/EDBT.2022.18
-
[50]
Zezhou Huang, Rathijit Sen, Jiaxiang Liu, and Eugene Wu. 2023. JoinBoost: Grow Trees Over Normalized Data Using Only SQL.PVLDB16, 11 (2023), 3071–3084. https://doi.org/10.14778/3611479.3611509
-
[51]
Zhihao Jia, Oded Padon, James Thomas, Todd Warszawski, Matei Zaharia, and Alex Aiken. 2019. TASO: optimizing deep learning computation with automatic generation of graph substitutions. InSOSP. 47–62. https://doi.org/10.1145/ 3341301.3359630
arXiv 2019
-
[52]
Zhihao Jia, James Thomas, Todd Warszawski, Mingyu Gao, Matei Zaharia, and Alex Aiken. 2019. Optimizing DNN Computation with Relaxed Graph Substitutions. InMLSys. https://proceedings.mlsys.org/paper_files/paper/2019/ hash/
2019
-
[53]
David Justen, Daniel Ritter, Campbell Fraser, Andrew Lamb, Nga Tran, Allison Lee, Thomas Bodner, Mhd Yamen Haddad, Steffen Zeuch, Volker Markl, and Matthias Boehm. 2024. POLAR: Adaptive and Non-invasive Join Order Selection via Plans of Least Resistance.PVLDB17, 6 (2024), 1350–1363. https://doi.org/ 10.14778/3648160.3648175
-
[54]
George Katsogiannis-Meimarakis and Georgia Koutrika. 2021. A Deep Dive into Deep Learning Approaches for Text-to-SQL Systems. InSIGMOD. 2846–2851. https://doi.org/10.1145/3448016.3457543
-
[55]
Kester, Manos Athanassoulis, and Stratos Idreos
Michael S. Kester, Manos Athanassoulis, and Stratos Idreos. 2017. Access Path Selection in Main-Memory Optimized Data Systems: Should I Scan or Should I Probe?. InSIGMOD. 715–730. https://doi.org/10.1145/3035918.3064049
-
[56]
Steffen Kläbe and Kai-Uwe Sattler. 2023. Patched Multi-Key Partitioning for Robust Query Performance. InEDBT. https://doi.org/10.48786/EDBT.2023.26
-
[57]
Jan Kossmann, Thorsten Papenbrock, and Felix Naumann. 2023. Correction to: Data dependencies for query optimization: a survey.VLDB J.32, 2 (2023), 471. https://doi.org/10.1007/S00778-021-00710-4
-
[58]
Warner, Vikas Arora, and Susan Kotsovolos
Muralidhar Krishnaprasad, Zhen Hua Liu, Anand Manikutty, James W. Warner, Vikas Arora, and Susan Kotsovolos. 2004. Query Rewrite for XML in Oracle XML DB. InVLDB. 1122–1133. https://doi.org/10.1016/B978-012088469-8.50098-X
-
[59]
Boncz, Alfons Kemper, and Thomas Neumann
Viktor Leis, Andrey Gubichev, Atanas Mirchev, Peter A. Boncz, Alfons Kemper, and Thomas Neumann. 2015. How Good Are Query Optimizers, Really?PVLDB 9, 3 (2015), 204–215. https://doi.org/10.14778/2850583.2850594
-
[60]
Viktor Leis, Kan Kundhikanjana, Alfons Kemper, and Thomas Neumann. 2015. Efficient Processing of Window Functions in Analytical SQL Queries.PVLDB8, 10 (2015), 1058–1069. https://doi.org/10.14778/2794367.2794375
-
[61]
Viktor Leis, Bernhard Radke, Andrey Gubichev, Alfons Kemper, and Thomas Neumann. 2017. Cardinality Estimation Done Right: Index-Based Join Sampling. InCIDR. http://cidrdb.org/cidr2017/papers/p9-leis-cidr17.pdf
2017
-
[62]
Viktor Leis, Bernhard Radke, Andrey Gubichev, Atanas Mirchev, Peter Boncz, Alfons Kemper, and Thomas Neumann. 2018. Query optimization through the looking glass, and what we found running the Join Order Benchmark.VLDB J. 27, 5 (2018), 643–668. https://doi.org/10.1007/S00778-017-0480-7
-
[63]
Zhaodonghui Li, Haitao Yuan, Huiming Wang, Gao Cong, and Lidong Bing
-
[64]
LLM-R2: A Large Language Model Enhanced Rule-Based Rewrite System for Boosting Query Efficiency.PVLDB18, 1 (2024), 53–65. https://doi.org/10. 14778/3696435.3696440
arXiv 2024
-
[65]
Daniel Lindner, Daniel Ritter, and Felix Naumann. 2024. Enabling Data Dependency-based Query Optimization.CoRRabs/2406.06886 (2024). https: //doi.org/10.48550/ARXIV.2406.06886
work page internal anchor Pith review Pith/arXiv arXiv doi:10.48550/arxiv.2406.06886 2024
-
[66]
Jie Liu and Barzan Mozafari. 2026. GenRewrite: Query Rewriting via Large Language Models.SIGMOD4, 1 (2026), 1–26. https://dl.acm.org/doi/pdf/10. 1145/3786684
2026
-
[67]
Ilyas, Benny Kimelfeld, and Sudeepa Roy
Ester Livshits, Rina Kochirgan, Segev Tsur, Ihab F. Ilyas, Benny Kimelfeld, and Sudeepa Roy. 2021. Properties of Inconsistency Measures for Databases. In SIGMOD. 1182–1194. https://doi.org/10.1145/3448016.3457310
-
[68]
Guy Lohman. 2002. The DB2 Universal Database Optimizer. Guest Lecture. https://cs.uwaterloo.ca/~ilyas/CS448W14/ibm.pdf
2002
-
[69]
Guy Lohman. 2014. Is Query Optimization a “Solved” Problem? ACM SIGMOD Blog. https://wp.sigmod.org/?p=1075
2014
-
[70]
Toby Mao. 2024. SQLGlot. GitHub repository. Retrieved April 29, 2026 from https://github.com/tobymao/sqlglot
2024
-
[71]
Volker Markl, Vijayshankar Raman, David E. Simmen, Guy M. Lohman, and Hamid Pirahesh. 2004. Robust Query Processing through Progressive Optimiza- tion. InSIGMOD. 659–670. https://doi.org/10.1145/1007568.1007642
-
[72]
Guido Moerkotte. 2025. Building Query Compilers. https://pi3.informatik.uni- mannheim.de/~moer/querycompiler.pdf Last Accessed: October 03, 2025
2025
-
[73]
Guido Moerkotte and Thomas Neumann. 2011. Accelerating Queries with Group-By and Join by Groupjoin.PVLDB4, 11 (2011), 843–851. http://www. vldb.org/pvldb/vol4/p843-moerkotte.pdf
2011
-
[74]
Magnus Müller, Lucas Woltmann, and Wolfgang Lehner. 2023. Enhanced Fea- turization of Queries with Mixed Combinations of Predicates for ML-based Cardinality Estimation. InEDBT. https://doi.org/10.48786/EDBT.2023.22
-
[75]
Parimarjan Negi, Ryan Marcus, Andreas Kipf, Hongzi Mao, Nesime Tatbul, Tim Kraska, and Mohammad Alizadeh. 2021. Flow-Loss: Learning Cardinality Estimates That Matter.PVLDB14, 11 (jul 2021), 2019–2032. https://doi.org/10. 14778/3476249.3476259
arXiv 2021
-
[76]
Thomas Neumann and Alfons Kemper. 2015. Unnesting Arbitrary Queries. In BTW, Vol. P-241. 383–402. https://dl.gi.de/handle/20.500.12116/2418
2015
-
[77]
Thomas Neumann and Viktor Leis. 2024. A Critique of Modern SQL and a Proposal Towards a Simple and Expressive Query Language. InCIDR. https: //www.cidrdb.org/cidr2024/papers/p48-neumann.pdf
2024
-
[78]
Oleksii Vasyliev. 2025. https://pgtune.leopard.in.ua
2025
-
[79]
Amy Ousterhout, Steven McCanne, Henri Dubois-Ferrière, Silvery Fu, Sylvia Ratnasamy, and Noah Treuhaft. 2023. Zed: Leveraging Data Types to Pro- cess Eclectic Data. InCIDR. https://www.cidrdb.org/cidr2023/papers/p52- ousterhout.pdf
2023
-
[80]
Simone Papicchio, Paolo Papotti, and Luca Cagliero. 2023. QATCH: Benchmarking SQL-centric tasks with Table Representation Learn- ing Models on Your Data. InNeurIPS. http://papers.nips.cc/paper_ files/paper/2023/hash/62a24b69b820d30e9e5ad4f15ff7bf72-Abstract- Datasets_and_Benchmarks.html
2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.