Geometric Entropy: When Trajectory Diversity Helps and Hurts in Imitation Learning
Pith reviewed 2026-06-26 16:55 UTC · model grok-4.3
The pith
Geometric diversity in demonstrations forms an inverted-U with imitation learning success.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
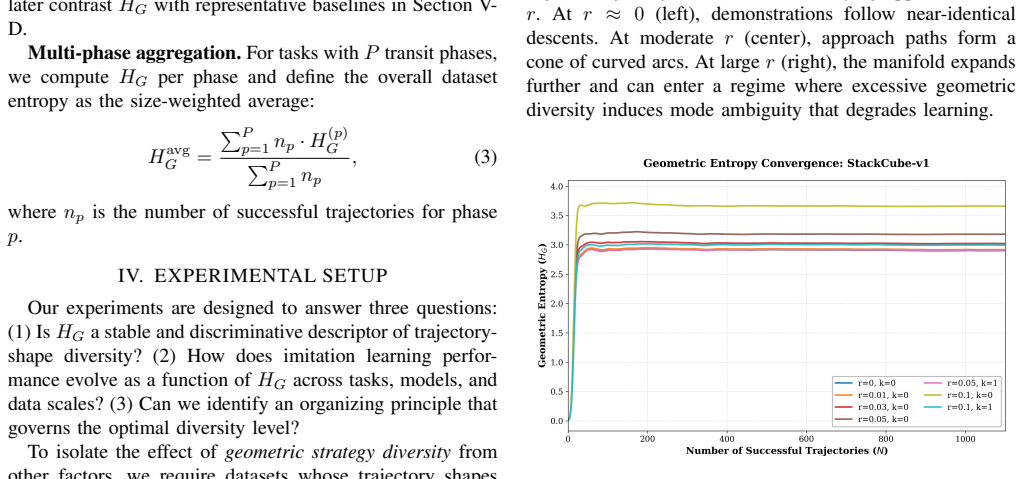
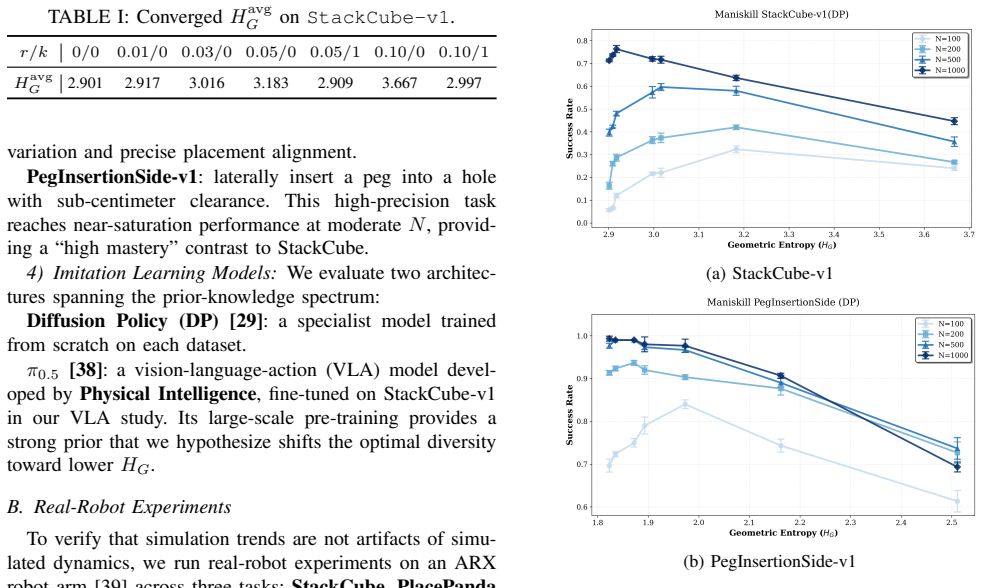
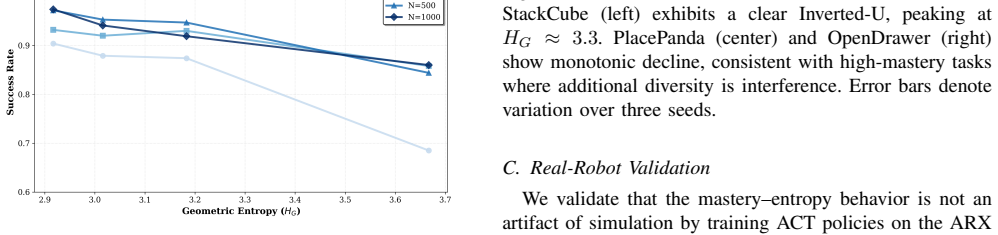
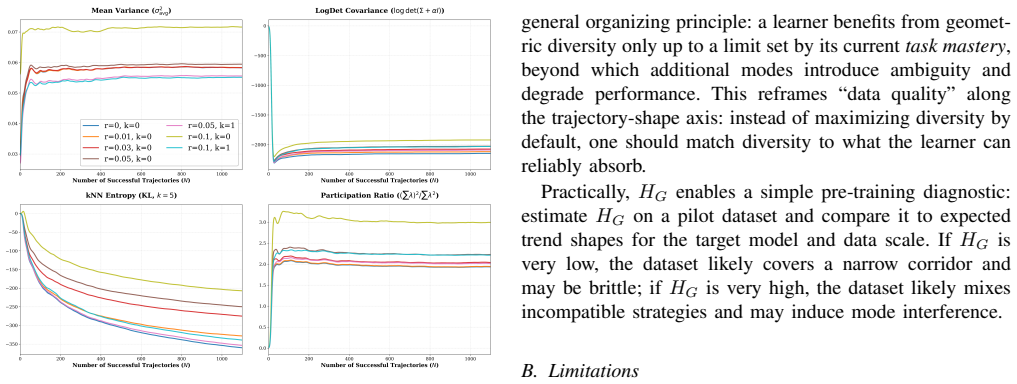
Geometric Entropy (H_G) is obtained by aligning each trajectory to a common target frame, removing extrinsic pose and scale variation so that only intrinsic shape diversity remains. Across several imitation-learning architectures and both simulated and real contact-rich manipulation tasks, success rate traces an inverted-U against H_G: moderate geometric diversity improves robustness while excess diversity produces strategy ambiguity that lowers performance. The entropy value that maximizes success decreases as task mastery increases through added data, easier tasks, or stronger priors, and becomes effectively monotonic for a pretrained vision-language-action model.
What carries the argument
Geometric Entropy (H_G), a task-agnostic scalar obtained by target-frame alignment that isolates intrinsic trajectory-shape diversity from extrinsic pose and scale factors.
If this is right
- Success peaks at intermediate rather than minimal or maximal geometric diversity.
- The diversity level that maximizes success drops as datasets enlarge or tasks become easier.
- Pretrained vision-language-action models show steadily falling performance with rising geometric diversity.
- H_G supplies a fast pre-training check that flags whether a demonstration set lies inside the learnable diversity band.
Where Pith is reading between the lines
- Dataset collection protocols could be designed to target the intermediate entropy band identified by the metric.
- The same alignment-plus-entropy procedure might be tested on sequential tasks outside contact-rich manipulation to check whether the inverted-U pattern generalizes.
- An online version of the metric could be used to decide when to stop adding new demonstrations or to trigger data filtering during training.
Load-bearing premise
Target-frame alignment removes all extrinsic variation so that the remaining quantity truly reflects only intrinsic trajectory-shape diversity and predicts learning outcomes.
What would settle it
A controlled experiment that varies only intrinsic trajectory shape while holding goal poses and scales fixed and finds success rates that are flat or strictly monotonic with diversity instead of inverted-U.
Figures


read the original abstract
We study how trajectory-shape diversity in demonstrations affects imitation learning (IL) performance across models, tasks, and data scales. We introduce Geometric Entropy (H_G), a task-agnostic metric that quantifies the intrinsic diversity of transit trajectories after normalizing away extrinsic variation, such as goal pose and workspace scale, via target-frame alignment. Across multiple IL architectures and both simulated and real-robot contact-rich manipulation tasks, we observe a consistent inverted-U relationship between success and H_G: increasing geometric diversity improves robustness in low-diversity regimes but degrades performance once diversity induces strategy ambiguity. Moreover, the optimal entropy shifts toward lower values as task mastery increases through more data, easier tasks, or stronger priors, and for a pretrained vision-language-action model the trend becomes effectively monotonic decreasing. Practically, H_G enables fast pre-training auditing of demonstration datasets and offers a simple guideline for calibrating demonstrations toward the learnable regime.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Geometric Entropy (H_G) as a task-agnostic metric quantifying intrinsic trajectory-shape diversity in imitation learning demonstrations after target-frame alignment to normalize extrinsic factors such as goal pose and workspace scale. Across multiple IL architectures and both simulated and real-robot contact-rich manipulation tasks, it reports a consistent inverted-U relationship between H_G and task success: moderate geometric diversity improves robustness while higher diversity induces strategy ambiguity. The optimal H_G shifts lower with increased data, easier tasks, or stronger model priors, becoming monotonic for a pretrained VLA model. H_G is positioned as a practical tool for pre-training dataset auditing and demonstration calibration.
Significance. If the metric isolation holds and the inverted-U is robust, the work supplies an actionable, pre-training heuristic for demonstration selection in robotics IL that could improve performance in contact-rich settings without requiring additional training runs. The cross-architecture and real-robot consistency strengthens the empirical observation, though the result remains observational rather than derived from first principles.
major comments (2)
- [Target-frame alignment / H_G definition] Target-frame alignment section: the claim that alignment isolates intrinsic shape diversity (making H_G task-agnostic and predictive) lacks an explicit post-alignment invariance test or ablation (e.g., residual correlation of H_G with goal pose, scale, or contact geometry). This is load-bearing for the inverted-U interpretation, as performance drops at high H_G could instead reflect increasing extrinsic task difficulty.
- [Results / Experiments] Experimental reporting: the abstract and results claim consistent inverted-U observations across architectures, data scales, and real/simulated tasks, yet provide no quantitative details on statistical tests, multiple-comparison corrections, or exclusion criteria for trajectories. This weakens confidence that the relationship is not driven by post-hoc analysis choices.
minor comments (2)
- [Metric definition] Clarify the precise normalization steps and any free parameters in the H_G formula to allow direct reproduction.
- [Results] Add a table or figure explicitly showing the shift in optimal H_G across data regimes, task difficulties, and model strengths.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. We address each major comment below and are prepared to revise the manuscript accordingly to strengthen the claims.
read point-by-point responses
-
Referee: [Target-frame alignment / H_G definition] Target-frame alignment section: the claim that alignment isolates intrinsic shape diversity (making H_G task-agnostic and predictive) lacks an explicit post-alignment invariance test or ablation (e.g., residual correlation of H_G with goal pose, scale, or contact geometry). This is load-bearing for the inverted-U interpretation, as performance drops at high H_G could instead reflect increasing extrinsic task difficulty.
Authors: We agree that an explicit post-alignment invariance test would strengthen the interpretation that H_G isolates intrinsic trajectory-shape diversity. The alignment procedure normalizes goal pose and workspace scale by transforming to a common target frame, but the manuscript does not include a quantitative ablation (such as residual correlations with extrinsic factors). We will add this analysis in the revision, including correlation checks and an ablation on alignment variants, to confirm the metric's task-agnostic property. revision: yes
-
Referee: [Results / Experiments] Experimental reporting: the abstract and results claim consistent inverted-U observations across architectures, data scales, and real/simulated tasks, yet provide no quantitative details on statistical tests, multiple-comparison corrections, or exclusion criteria for trajectories. This weakens confidence that the relationship is not driven by post-hoc analysis choices.
Authors: We acknowledge that the current reporting lacks explicit statistical details. While the inverted-U pattern is observed consistently across the reported experiments, we did not include quantitative tests (e.g., significance of quadratic terms) or clarify exclusion criteria. In the revised manuscript we will add appropriate statistical analyses, multiple-comparison corrections where relevant, and explicit statements on trajectory inclusion/exclusion criteria. revision: yes
Circularity Check
No circularity; H_G is a fixed normalization metric and the inverted-U is an empirical observation
full rationale
The paper defines Geometric Entropy (H_G) through an explicit target-frame alignment procedure that normalizes pose and scale, then reports an observational inverted-U relationship between H_G and IL success rates across architectures and tasks. No derivation, prediction, or first-principles result reduces to the metric's own inputs by construction. The relationship is presented as data-driven rather than forced by the definition of H_G, and the alignment step is a preprocessing choice whose validity is external to the metric itself. No self-citation chains, fitted parameters renamed as predictions, or ansatzes smuggled via prior work appear in the load-bearing steps. The central claim remains falsifiable via the reported experiments and does not collapse to a tautology.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Target-frame alignment removes extrinsic variation (goal pose, workspace scale) without distorting intrinsic trajectory diversity
Reference graph
Works this paper leans on
-
[1]
Rt-1: Robotics transformer for real-world control at scale,
A. Brohan, N. Brown, J. Carbajal, Y . Chebotar, J. Dabis, C. Finn, K. Gopalakrishnan, K. Hausman, A. Herzog, J. Hsuet al., “Rt-1: Robotics transformer for real-world control at scale,”arXiv preprint arXiv:2212.06817, 2022
Pith/arXiv arXiv 2022
-
[2]
Rt-2: Vision-language-action models transfer web knowledge to robotic control,
B. Zitkovich, T. Yu, S. Xu, P. Xu, T. Xiao, F. Xia, J. Wu, P. Wohlhart, S. Welker, A. Wahidet al., “Rt-2: Vision-language-action models transfer web knowledge to robotic control,” inConference on Robot Learning. PMLR, 2023, pp. 2165–2183
2023
-
[3]
Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,
A. O’Neill, A. Rehman, A. Maddukuri, A. Gupta, A. Padalkar, A. Lee, A. Pooley, A. Gupta, A. Mandlekar, A. Jainet al., “Open x-embodiment: Robotic learning datasets and rt-x models: Open x- embodiment collaboration 0,” in2024 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2024, pp. 6892–6903
2024
-
[4]
Droid: A large-scale in-the-wild robot manipulation dataset,
A. Khazatsky, K. Pertsch, S. Nair, A. Balakrishna, S. Dasari, S. Karam- cheti, S. Nasiriany, M. K. Srirama, L. Y . Chen, K. Elliset al., “Droid: A large-scale in-the-wild robot manipulation dataset,”arXiv preprint arXiv:2403.12945, 2024
Pith/arXiv arXiv 2024
-
[5]
Octo: An open-source generalist robot policy,
Octo Model Team, D. Ghosh, H. Walke, K. Pertsch, K. Black, O. Mees, S. Dasari, J. Hejna, C. Xu, J. Luo, T. Kreiman, Y . Tan, L. Y . Chen, P. Sanketi, Q. Vuong, T. Xiao, D. Sadigh, C. Finn, and S. Levine, “Octo: An open-source generalist robot policy,” inProceedings of Robotics: Science and Systems, Delft, Netherlands, 2024
2024
-
[6]
Openvla: An open-source vision-language-action model,
M. Kim, K. Pertsch, S. Karamcheti, T. Xiao, A. Balakrishna, S. Nair, R. Rafailov, E. Foster, G. Lam, P. Sanketi, Q. Vuong, T. Kollar, B. Burchfiel, R. Tedrake, D. Sadigh, S. Levine, P. Liang, and C. Finn, “Openvla: An open-source vision-language-action model,” arXiv preprint arXiv:2406.09246, 2024
Pith/arXiv arXiv 2024
-
[7]
Bc-z: Zero-shot task generalization with robotic imitation learning,
E. Jang, A. Irpan, M. Khansari, D. Kappler, F. Ebert, C. Lynch, S. Levine, and C. Finn, “Bc-z: Zero-shot task generalization with robotic imitation learning,” inconference on Robot Learning. PMLR, 2022, pp. 991–1002
2022
-
[8]
Robocat: A self- improving generalist agent for robotic manipulation,
K. Bousmalis, G. Vezzani, D. Rao, C. Devin, A. X. Lee, M. Bauz ´a, T. Davchev, Y . Zhou, A. Gupta, A. Rajuet al., “Robocat: A self- improving generalist agent for robotic manipulation,”arXiv preprint arXiv:2306.11706, 2023
arXiv 2023
-
[9]
Palm-e: an embodied multimodal language model,
D. Driess, F. Xia, M. S. Sajjadi, C. Lynch, A. Chowdhery, B. Ichter, A. Wahid, J. Tompson, Q. Vuong, T. Yuet al., “Palm-e: an embodied multimodal language model,” inProceedings of the 40th International Conference on Machine Learning, 2023, pp. 8469–8488
2023
-
[10]
Vima: General robot manipulation with multimodal prompts,
Y . Jiang, A. Gupta, Z. Zhang, G. Wang, Y . Dou, Y . Chen, L. Fei- Fei, A. Anandkumar, Y . Zhu, and L. Fan, “Vima: General robot manipulation with multimodal prompts,” inFortieth International Conference on Machine Learning, 2023
2023
-
[11]
Aw-opt: Learning robotic skills with imitation andreinforcement at scale,
Y . Lu, K. Hausman, Y . Chebotar, M. Yan, E. Jang, A. Herzog, T. Xiao, A. Irpan, M. Khansari, D. Kalashnikovet al., “Aw-opt: Learning robotic skills with imitation andreinforcement at scale,” inConference on Robot Learning. PMLR, 2022, pp. 1078–1088
2022
-
[12]
Data quality in imitation learning,
S. Belkhale, Y . Cui, and D. Sadigh, “Data quality in imitation learning,”Advances in neural information processing systems, vol. 36, pp. 80 375–80 395, 2023
2023
-
[13]
A reduction of imitation learning and structured prediction to no-regret online learning,
S. Ross, G. Gordon, and D. Bagnell, “A reduction of imitation learning and structured prediction to no-regret online learning,” inProceedings of the fourteenth international conference on artificial intelligence and statistics. JMLR Workshop and Conference Proceedings, 2011, pp. 627–635
2011
-
[14]
Dart: Noise injection for robust imitation learning,
M. Laskey, J. Lee, R. Fox, A. Dragan, and K. Goldberg, “Dart: Noise injection for robust imitation learning,” inConference on robot learning. PMLR, 2017, pp. 143–156
2017
-
[15]
What matters in learning from offline human demonstrations for robot manipula- tion,
A. Mandlekar, D. Xu, J. Wong, S. Nasiriany, C. Wang, R. Kulkarni, L. Fei-Fei, S. Savarese, Y . Zhu, and R. Mart´ın-Mart´ın, “What matters in learning from offline human demonstrations for robot manipula- tion,” inConference on Robot Learning. PMLR, 2022, pp. 1678– 1690
2022
-
[16]
Discriminator-weighted offline imitation learning from suboptimal demonstrations,
H. Xu, X. Zhan, H. Yin, and H. Qin, “Discriminator-weighted offline imitation learning from suboptimal demonstrations,” inInternational Conference on Machine Learning. PMLR, 2022, pp. 24 725–24 742
2022
-
[17]
Scizor: Self-supervised data curation for large-scale imitation learn- ing,
Y . Zhang, Y . Xie, H. Liu, R. Shah, M. Wan, L. Fan, and Y . Zhu, “Scizor: Self-supervised data curation for large-scale imitation learn- ing,” inIEEE International Conference on Robotics and Automation (ICRA), 2026
2026
-
[18]
Cupid: Curating data your robot loves with influence functions,
C. Agia, R. Sinha, J. Yang, R. Antonova, M. Pavone, H. Nishimura, M. Itkina, and J. Bohg, “Cupid: Curating data your robot loves with influence functions,”arXiv preprint arXiv:2506.19121, 2025
arXiv 2025
-
[19]
Curating demon- strations using online experience,
A. S. Chen, A. M. Lessing, Y . Liu, and C. Finn, “Curating demon- strations using online experience,”arXiv preprint arXiv:2503.03707, 2025
arXiv 2025
-
[20]
Learning from imperfect demonstrations with self-supervision for robotic manipulation,
K. Wu, N. Liu, Z. Zhao, D. Qiu, J. Li, Z. Che, Z. Xu, and J. Tang, “Learning from imperfect demonstrations with self-supervision for robotic manipulation,” in2025 IEEE International Conference on Robotics and Automation (ICRA). IEEE, 2025, pp. 16 899–16 906
2025
-
[21]
Mimicgen: A data generation system for scalable robot learning using human demonstrations,
A. Mandlekar, S. Nasiriany, B. Wen, I. Akinola, Y . Narang, L. Fan, Y . Zhu, and D. Fox, “Mimicgen: A data generation system for scalable robot learning using human demonstrations,” inConference on Robot Learning. PMLR, 2023, pp. 1820–1864
2023
-
[22]
Demogen: Synthetic demonstration generation for data-efficient visuomotor pol- icy learning,
Z. Xue, S. Deng, Z. Chen, Y . Wang, Z. Yuan, and H. Xu, “Demogen: Synthetic demonstration generation for data-efficient visuomotor pol- icy learning,” in7th Robot Learning Workshop: Towards Robots with Human-Level Abilities, 2025
2025
-
[23]
Manibox: Enhancing spatial grasping generalization via scalable simulation data generation,
H. Tan, X. Xu, C. Ying, X. Mao, S. Liu, X. Zhang, H. Su, and J. Zhu, “Manibox: Enhancing spatial grasping generalization via scalable simulation data generation,”arXiv preprint arXiv:2411.01850, 2024
arXiv 2024
-
[24]
S. Huang, Y . Liao, S. Feng, S. Jiang, S. Liu, H. Li, M. Yao, and G. Ren, “Adversarial data collection: Human-collaborative perturba- tions for efficient and robust robotic imitation learning,”arXiv preprint arXiv:2503.11646, 2025
arXiv 2025
-
[25]
Fieldgen: From teleoperated pre-manipulation trajectories to field-guided data generation,
W. Wang, K. Ye, X. Zhou, T. Chen, C. Min, Q. Zhu, X. Yang, P. Luo, Y . Shen, Y . Yanget al., “Fieldgen: From teleoperated pre-manipulation trajectories to field-guided data generation,”arXiv preprint arXiv:2510.20774, 2025
arXiv 2025
-
[26]
H. Wang, C. B. Chen, Y . Yue, D. Tao, T. Guo, S. Xie, D. Huang, S. Song, G. Yao, and G. Huang, “Move: A simple motion-based data collection paradigm for spatial generalization in robotic manipulation,” arXiv preprint arXiv:2512.04813, 2025
arXiv 2025
-
[27]
Multi-modal imitation learning from unstructured demonstrations using generative adversarial nets,
K. Hausman, Y . Chebotar, S. Schaal, G. Sukhatme, and J. J. Lim, “Multi-modal imitation learning from unstructured demonstrations using generative adversarial nets,”Advances in neural information processing systems, vol. 30, 2017
2017
-
[28]
Behavior transformers: Cloningkmodes with one stone,
N. M. Shafiullah, Z. Cui, A. A. Altanzaya, and L. Pinto, “Behavior transformers: Cloningkmodes with one stone,”Advances in neural information processing systems, vol. 35, pp. 22 955–22 968, 2022
2022
-
[29]
Diffusion policy: Visuomotor policy learning via action diffusion,
C. Chi, Z. Xu, S. Feng, E. Cousineau, Y . Du, B. Burchfiel, R. Tedrake, and S. Song, “Diffusion policy: Visuomotor policy learning via action diffusion,”The International Journal of Robotics Research, vol. 44, no. 10-11, pp. 1684–1704, 2025
2025
-
[30]
Implicit behavioral cloning,
P. Florence, C. Lynch, A. Zeng, O. A. Ramirez, A. Wahid, L. Downs, A. Wong, J. Lee, I. Mordatch, and J. Tompson, “Implicit behavioral cloning,” inConference on robot learning. PMLR, 2022, pp. 158– 168
2022
-
[31]
Behavior generation with latent actions,
S. Lee, Y . Wang, H. Etukuru, H. J. Kim, N. M. M. Shafiullah, and L. Pinto, “Behavior generation with latent actions,” inInternational Conference on Machine Learning. PMLR, 2024, pp. 26 991–27 008
2024
-
[32]
Baku: An efficient transformer for multi-task policy learning,
S. Haldar, Z. Peng, and L. Pinto, “Baku: An efficient transformer for multi-task policy learning,”Advances in Neural Information Process- ing Systems, vol. 37, pp. 141 208–141 239, 2024
2024
-
[33]
Towards diverse behaviors: A benchmark for imitation learning with human demonstrations,
X. Jia, D. Blessing, X. Jiang, M. Reuss, A. Donat, R. Lioutikov, and G. Neumann, “Towards diverse behaviors: A benchmark for imitation learning with human demonstrations,” inThe Twelfth International Conference on Learning Representations, 2024
2024
-
[34]
Generative adversarial imitation learning,
J. Ho and S. Ermon, “Generative adversarial imitation learning,” Advances in neural information processing systems, vol. 29, 2016
2016
-
[35]
Is diversity all you need for scalable robotic manipulation?
M. Shi, L. Chen, J. Chen, Y . Lu, C. Liu, G. Ren, P. Luo, D. Huang, M. Yao, and H. Li, “Is diversity all you need for scalable robotic manipulation?”arXiv preprint arXiv:2507.06219, 2025
Pith/arXiv arXiv 2025
-
[36]
Dynamic programming algorithm optimiza- tion for spoken word recognition,
H. Sakoe and S. Chiba, “Dynamic programming algorithm optimiza- tion for spoken word recognition,”IEEE transactions on acoustics, speech, and signal processing, vol. 26, no. 1, pp. 43–49, 1978
1978
-
[37]
Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,
S. Tao, F. Xiang, A. Shukla, Y . Qin, X. Hinrichsen, X. Yuan, C. Bao, X. Lin, Y . Liu, T.-k. Chanet al., “Maniskill3: Gpu parallelized robotics simulation and rendering for generalizable embodied ai,” arXiv preprint arXiv:2410.00425, 2024
arXiv 2024
-
[38]
π 0.5: a vision-language-action model with open-world generalization,
P. Intelligence, K. Black, N. Brown, J. Darpinian, K. Dhabalia, D. Driess, A. Esmail, M. Equi, C. Finn, N. Fusaiet al., “π 0.5: a vision-language-action model with open-world generalization,”arXiv preprint arXiv:2504.16054, 2025
Pith/arXiv arXiv 2025
-
[39]
Arx robotics,
“Arx robotics,” https://arx-x.com/
-
[40]
Learning fine-grained bimanual manipulation with low-cost hardware,
T. Z. Zhao, V . Kumar, S. Levine, and C. Finn, “Learning fine-grained bimanual manipulation with low-cost hardware,”arXiv preprint arXiv:2304.13705, 2023
Pith/arXiv arXiv 2023
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.