Ω: Operator-based Mixture Ensemble for Generative Assimilation
Pith reviewed 2026-06-26 17:49 UTC · model grok-4.3
The pith
Ω reconstructs full non-Gaussian posteriors in data assimilation by learning residual discrepancies from ensemble trajectories alone.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
Ω integrates conditional Gaussian surrogate modeling, unsupervised score learning, and generative sampling. It exploits closed-form conditional distributions to analytically recover unobserved variables, learns only the residual discrepancy beyond this baseline through denoising score matching on ensemble trajectories, reconstructs the full non-Gaussian posterior of observed and unobserved variables via a Gaussian mixture representation, and applies annealed Langevin sampling to refine ensembles toward the target distribution.
What carries the argument
The operator-based mixture ensemble that uses a conditional Gaussian surrogate as analytical baseline and learns residual non-Gaussian corrections via denoising score matching.
If this is right
- Unobserved variables are recovered analytically from closed-form conditional posteriors, reducing the curse of dimensionality.
- Training uses only ensemble trajectories, eliminating the requirement for supervised ground-truth posterior samples.
- The Gaussian mixture representation captures multimodal, skewed, and heavy-tailed posterior statistics.
- Annealed Langevin sampling iteratively refines baseline ensembles toward the target non-Gaussian distribution.
- Posterior accuracy improves consistently on turbulent models with intermittency and extreme events.
Where Pith is reading between the lines
- The hybrid analytical-generative structure may extend to other Bayesian inverse problems where a tractable baseline approximation exists.
- Similar residual-learning strategies could lower data requirements in generative modeling for scientific simulation.
- The mixture representation might enable direct computation of certain posterior functionals without full sampling.
- Performance on real observational datasets from fluid or atmospheric systems would test whether ensemble-only training generalizes beyond synthetic turbulence.
Load-bearing premise
The residual discrepancy beyond the conditional Gaussian surrogate baseline can be accurately learned through denoising score matching using only ensemble trajectories without ground-truth posterior samples, and the resulting Gaussian mixture plus annealed Langevin sampling recovers the target non-Gaussian posterior.
What would settle it
Apply Ω to a low-dimensional nonlinear test system where the exact posterior can be computed independently by direct integration or long-run MCMC, then check whether the generated Gaussian mixture matches the true density in modes, skewness, and tail behavior.
Figures

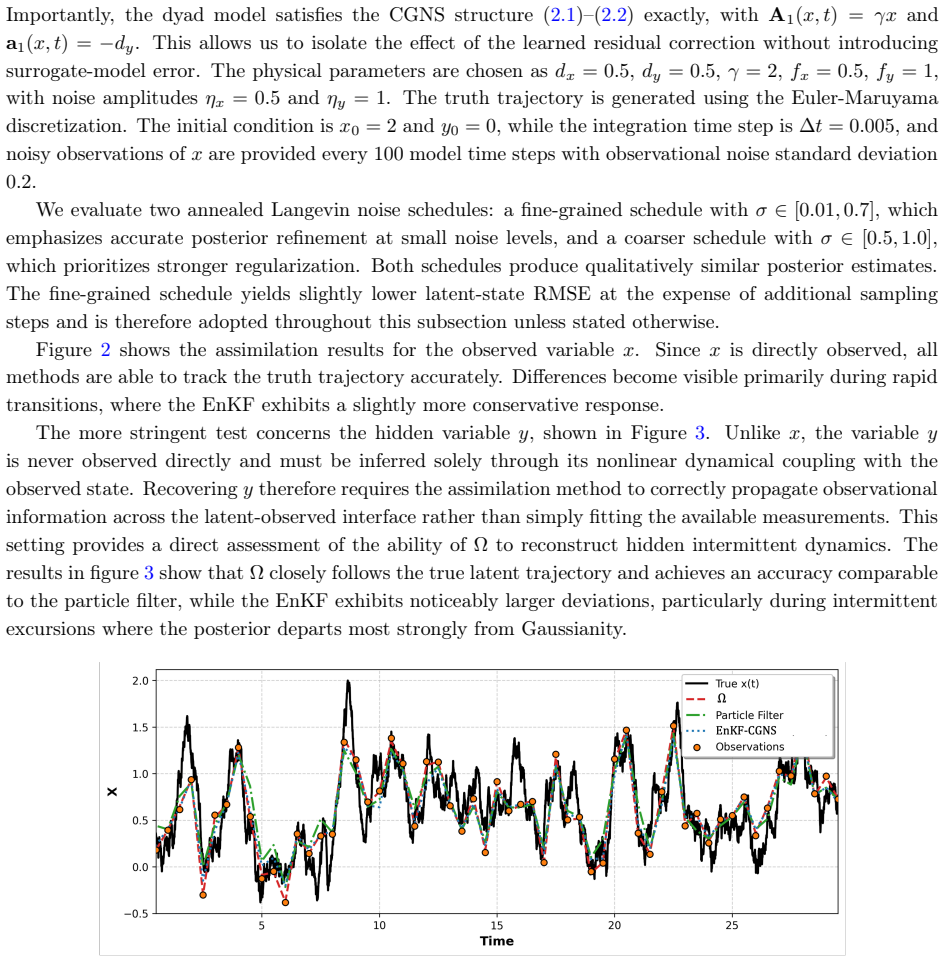
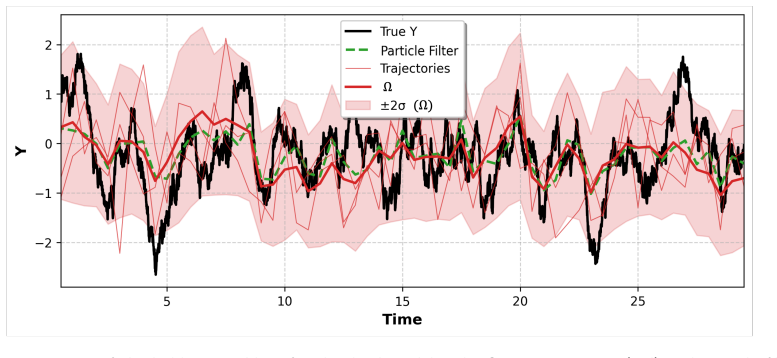
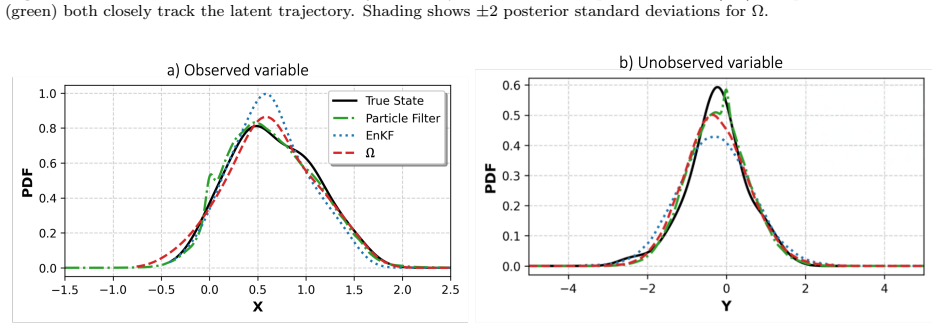
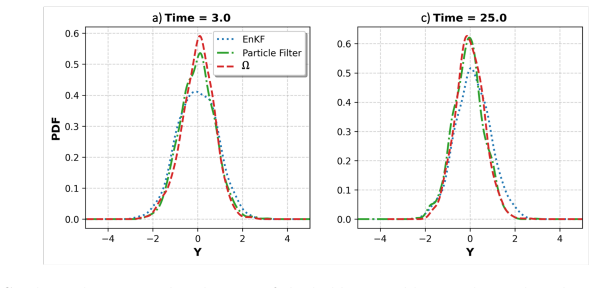

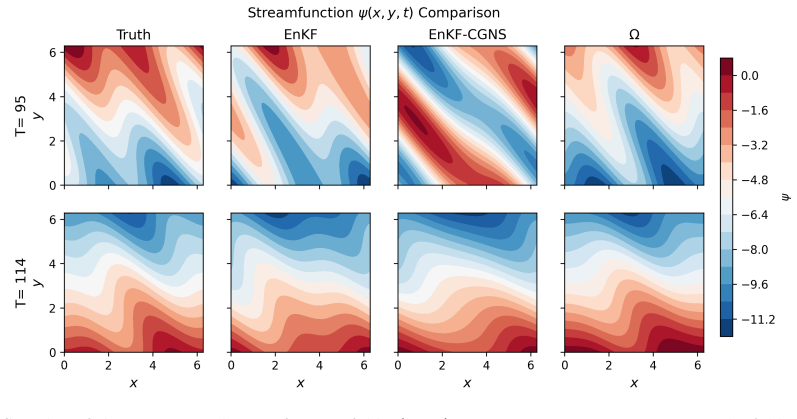

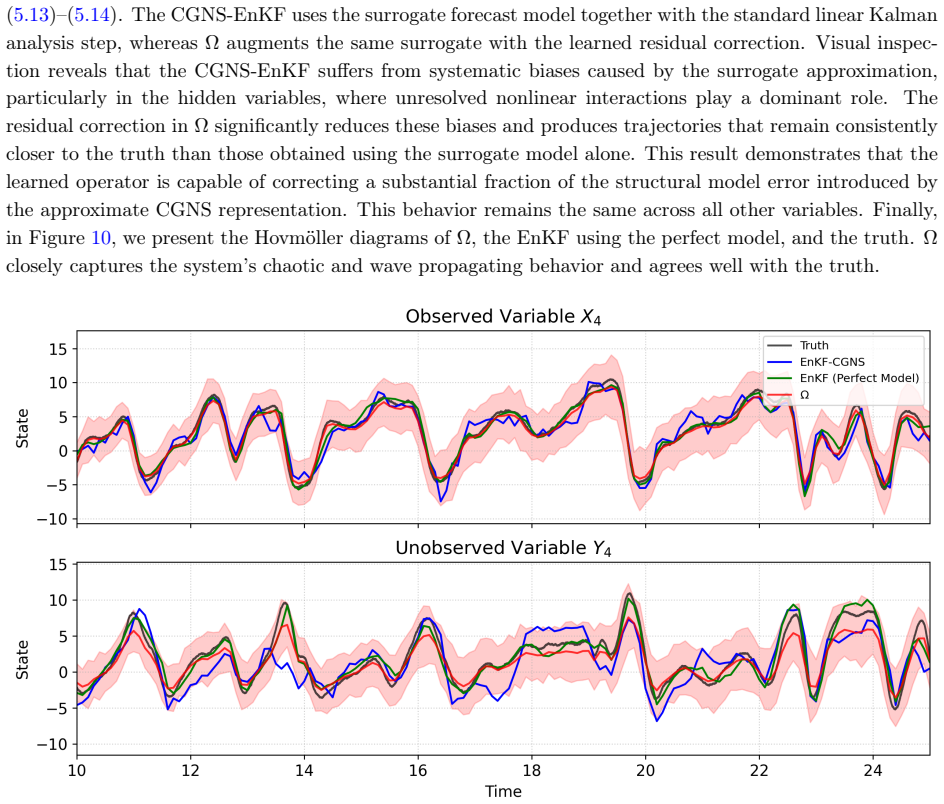
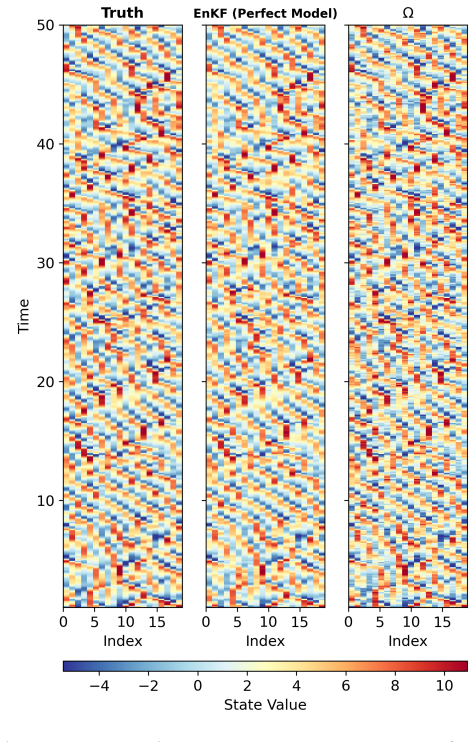
read the original abstract
Characterizing non-Gaussian posterior distributions in partially observed high-dimensional nonlinear systems remains a fundamental challenge in data assimilation. Ensemble Kalman filters rely on Gaussian approximations that can be inaccurate for strongly non-Gaussian posteriors, whereas particle filters suffer from severe scalability limitations. Recent score-based generative approaches improve posterior characterization but typically require supervised training with ground-truth posterior samples, which are unavailable in most practical applications. We introduce $\Omega$ (Operator-based Mixture Ensemble for Generative Assimilation), a scalable framework that integrates conditional Gaussian surrogate modeling, unsupervised score learning, and generative sampling. The conditional Gaussian surrogate provides a nonlinear non-Gaussian baseline approximation while admitting closed-form conditional posterior distributions for the unresolved variables. First, $\Omega$ exploits these closed-form conditional distributions to analytically recover the high-dimensional unobserved component, reducing computational cost and mitigating the curse of dimensionality. Second, $\Omega$ learns only the residual discrepancy beyond an analytical baseline through denoising score matching using ensemble trajectories alone, eliminating the need for ground-truth posterior samples and substantially reducing the learning burden. Third, $\Omega$ reconstructs the full non-Gaussian posterior distribution of both observed and unobserved variables via a Gaussian mixture representation, capturing multimodal, skewed, and heavy-tailed statistics. Finally, $\Omega$ employs annealed Langevin sampling to iteratively refine ensemble members from the baseline toward the target posterior. $\Omega$ is validated on several turbulent models with intermittency and extreme events, consistently improving posterior accuracy.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript introduces the Ω framework for data assimilation in partially observed high-dimensional nonlinear systems. It combines a conditional Gaussian surrogate providing closed-form conditionals for unobserved variables, unsupervised denoising score matching to learn residual discrepancies from ensemble trajectories alone (no ground-truth posterior samples), a Gaussian mixture representation of the posterior, and annealed Langevin sampling to generate samples from the target non-Gaussian posterior. The approach is claimed to capture multimodal, skewed, and heavy-tailed statistics and is validated on turbulent models with intermittency and extreme events, consistently improving posterior accuracy.
Significance. If the unsupervised residual learning step is shown to target the true observation-conditioned posterior, the work would be significant for offering a scalable generative method that avoids both Gaussian approximations in EnKF and the need for supervised training with inaccessible ground-truth samples, with potential applications to systems exhibiting intermittency.
major comments (2)
- [Abstract (method overview)] The central mechanism—that denoising score matching on ensemble trajectories learns only the residual discrepancy beyond the conditional Gaussian surrogate to recover the target posterior—is load-bearing but lacks an explicit loss function, conditioning mechanism on observations, or derivation establishing that the learned score matches the true posterior rather than the forecast marginal or surrogate (see abstract description of the unsupervised step).
- [Abstract (generative sampling step)] The reconstruction of the full non-Gaussian posterior via Gaussian mixture plus annealed Langevin sampling assumes the sampling converges to the observation-conditioned target; no analysis of the score estimator's conditioning, mixture construction, or sampling error relative to the closed-form baseline is provided to support this.
minor comments (1)
- The title references an 'Operator-based' component that is not elaborated in the abstract; clarifying its role in the surrogate or mixture would improve readability.
Simulated Author's Rebuttal
We thank the referee for the constructive and detailed review. We address each major comment point by point below, indicating where revisions will be made to improve clarity and rigor.
read point-by-point responses
-
Referee: [Abstract (method overview)] The central mechanism—that denoising score matching on ensemble trajectories learns only the residual discrepancy beyond the conditional Gaussian surrogate to recover the target posterior—is load-bearing but lacks an explicit loss function, conditioning mechanism on observations, or derivation establishing that the learned score matches the true posterior rather than the forecast marginal or surrogate (see abstract description of the unsupervised step).
Authors: The manuscript (Section 3) defines the unsupervised step via denoising score matching applied exclusively to the residual after subtracting the closed-form conditional Gaussian baseline; the network is conditioned on observations through the surrogate operator, and the loss is the standard DSM objective on the residual score. Because the baseline already encodes the exact conditional Gaussian given the observations, the residual score is derived to target the non-Gaussian correction to the true posterior rather than the forecast marginal. We acknowledge the abstract is high-level and will revise it to reference the explicit loss and conditioning; we will also add a compact derivation paragraph in Section 3 for completeness. revision: partial
-
Referee: [Abstract (generative sampling step)] The reconstruction of the full non-Gaussian posterior via Gaussian mixture plus annealed Langevin sampling assumes the sampling converges to the observation-conditioned target; no analysis of the score estimator's conditioning, mixture construction, or sampling error relative to the closed-form baseline is provided to support this.
Authors: Section 4 constructs the mixture by modulating the conditional Gaussian density with the integrated residual score and initializes annealed Langevin dynamics from the baseline ensemble. Empirical results on turbulent models with intermittency show consistent improvement over the baseline, supporting practical convergence. We agree that a dedicated discussion of the score estimator's conditioning, mixture normalization, and sampling error bounds relative to the closed-form surrogate would strengthen the claims; we will add this analysis subsection in the revised manuscript. revision: yes
Circularity Check
No significant circularity in derivation chain
full rationale
The paper presents a framework combining a conditional Gaussian surrogate (with closed-form conditionals for unresolved variables), unsupervised denoising score matching on ensemble trajectories to learn residual discrepancy, Gaussian mixture reconstruction, and annealed Langevin sampling. No equations or steps in the provided abstract reduce by construction to fitted inputs, self-definitions, or self-citation chains. The unsupervised step is explicitly framed as independent of ground-truth posterior samples, and no load-bearing uniqueness theorems or ansatzes from prior self-work are invoked. The derivation remains self-contained against external benchmarks with independent content.
Axiom & Free-Parameter Ledger
axioms (1)
- domain assumption Ensemble trajectories alone contain sufficient information to learn the score function of the residual discrepancy via denoising score matching.
invented entities (1)
-
Ω framework
no independent evidence
Reference graph
Works this paper leans on
-
[1]
K. Law, A. Stuart, K. Zygalakis, Data assimilation, Cham, Switzerland: Springer 214 (2015) 52
2015
-
[2]
A. J. Majda, J. Harlim, Filtering complex turbulent systems, Cambridge University Press, 2012. 27
2012
-
[3]
M. Asch, M. Bocquet, M. Nodet, Data assimilation: methods, algorithms, and applications, SIAM, 2016
2016
-
[4]
Evensen, F
G. Evensen, F. C. Vossepoel, P. J. Van Leeuwen, Data assimilation fundamentals: A unified formulation of the state and parameter estimation problem, Springer Nature, 2022
2022
-
[5]
Poulet, P
T. Poulet, P. Behnoudfar, Slip tendency analysis from sparse stress and satellite data using physics- guided deep neural networks, Geophysical Research Letters 51 (2024) e2024GL109524
2024
-
[6]
Bocquet, C
M. Bocquet, C. A. Pires, L. Wu, Beyond gaussian statistical modeling in geophysical data assimilation, Monthly Weather Review 138 (2010) 2997–3023
2010
-
[7]
P. J. Van Leeuwen, H. R. Künsch, L. Nerger, R. Potthast, S. Reich, Particle filters for high-dimensional geoscience applications: A review, Quarterly Journal of the Royal Meteorological Society 145 (2019) 2335–2365
2019
-
[8]
M. A. Freitag, R. W. E. Potthast, Synergy of inverse problems and data assimilation techniques, DE GRUYTER, 2013, pp. 1–54. doi:10.1515/9783110282269.1
-
[9]
Chen, Stochastic Methods for Modeling and Predicting Complex Dynamical Systems, Springer, 2023
N. Chen, Stochastic Methods for Modeling and Predicting Complex Dynamical Systems, Springer, 2023
2023
-
[10]
B. Wang, X. Zou, J. Zhu, Data assimilation and its applications, Proceedings of the National Academy of Sciences 97 (2000) 11143–11144
2000
-
[11]
Y. Chen, S. N. Stechmann, Multi-model communication and data assimilation for mitigating model error and improving forecasts, Chinese Annals of Mathematics, Series B 40 (2019) 689–720
2019
-
[12]
Poulet, P
T. Poulet, P. Behnoudfar, Physics-informed neural network reconciles australian displacements and tectonic stresses, Scientific Reports 13 (2023) 23095
2023
-
[13]
G. Evensen, Sequential data assimilation with a nonlinear quasi-geostrophic model using monte carlo methods to forecast error statistics, Journal of Geophysical Research: Oceans 99 (1994) 10143–10162
1994
-
[14]
Evensen, The ensemble kalman filter: Theoretical formulation and practical implementation, Ocean dynamics 53 (2003) 343–367
G. Evensen, The ensemble kalman filter: Theoretical formulation and practical implementation, Ocean dynamics 53 (2003) 343–367
2003
-
[15]
P. L. Houtekamer, H. L. Mitchell, Ensemble Kalman filtering, Quarterly Journal of the Royal Meteoro- logical Society: A journal of the atmospheric sciences, applied meteorology and physical oceanography 131 (2005) 3269–3289
2005
-
[16]
P. Behnoudfar, N. Chen, Rl-daunce: Reinforcement learning-driven data assimilation with uncertainty- aware constrained ensembles, Journal of Computational Physics 562 (2026) 115035. doi:https://doi. org/10.1016/j.jcp.2026.115035
-
[17]
D. L. T. Anderson, J. Sheinbaum, K. Haines, Data assimilation in ocean models, Reports on Progress in Physics 59 (1996) 1209–1266. doi:10.1088/0034-4885/59/10/001
-
[18]
Kalnay, Atmospheric modeling, data assimilation and predictability, Cambridge university press, 2003
E. Kalnay, Atmospheric modeling, data assimilation and predictability, Cambridge university press, 2003
2003
-
[19]
J. A. Vrugt, H. V. Gupta, W. Bouten, S. Sorooshian, A shuffled complex evolution metropolis algorithm for optimization and uncertainty assessment of hydrologic model parameters, Water resources research 39 (2003)
2003
-
[20]
W. A. Lahoz, P. Schneider, Data assimilation: making sense of earth observation, Frontiers in Envi- ronmental Science 2 (2014) 16. 28
2014
-
[21]
J. L. Anderson, Localization and sampling error correction in ensemble Kalman filter data assimilation, Monthly Weather Review 140 (2012) 2359–2371
2012
-
[22]
J. L. Anderson, Exploring the need for localization in ensemble data assimilation using a hierarchical ensemble filter, Physica D: Nonlinear Phenomena 230 (2007) 99–111
2007
-
[23]
Buehner, M
M. Buehner, M. Charron, Spectral and spatial localization of background-error correlations for data assimilation, Quarterly Journal of the Royal Meteorological Society: A journal of the atmospheric sciences, applied meteorology and physical oceanography 133 (2007) 615–630
2007
-
[24]
J. S. Whitaker, T. M. Hamill, Evaluating methods to account for system errors in ensemble data assimilation, Monthly Weather Review 140 (2012) 3078–3089
2012
-
[25]
Van Der Merwe, A
R. Van Der Merwe, A. Doucet, N. De Freitas, E. Wan, The unscented particle filter, Advances in neural information processing systems 13 (2000)
2000
-
[26]
Gustafsson, Particle filter theory and practice with positioning applications, IEEE Aerospace and Electronic Systems Magazine 25 (2010) 53–82
F. Gustafsson, Particle filter theory and practice with positioning applications, IEEE Aerospace and Electronic Systems Magazine 25 (2010) 53–82
2010
-
[27]
Elfring, E
J. Elfring, E. Torta, R. Van De Molengraft, Particle filters: A hands-on tutorial, Sensors 21 (2021) 438
2021
-
[28]
Rezende, S
D. Rezende, S. Mohamed, Variational inference with normalizing flows, in: International conference on machine learning, PMLR, 2015, pp. 1530–1538
2015
-
[29]
Kobyzev, S
I. Kobyzev, S. J. Prince, M. A. Brubaker, Normalizing flows: An introduction and review of current methods, IEEE transactions on pattern analysis and machine intelligence 43 (2020) 3964–3979
2020
-
[30]
Papamakarios, E
G. Papamakarios, E. Nalisnick, D. J. Rezende, S. Mohamed, B. Lakshminarayanan, Normalizing flows for probabilistic modeling and inference, Journal of Machine Learning Research 22 (2021) 1–64
2021
-
[31]
D. P. Kingma, M. Welling, Auto-encoding variational bayes, arXiv preprint arXiv:1312.6114 (2013)
work page internal anchor Pith review Pith/arXiv arXiv 2013
-
[32]
Khemakhem, D
I. Khemakhem, D. Kingma, R. Monti, A. Hyvarinen, Variational autoencoders and nonlinear ica: A unifying framework, in: International conference on artificial intelligence and statistics, PMLR, 2020, pp. 2207–2217
2020
-
[33]
Behnoudfar, C
P. Behnoudfar, C. Moser, M. Bocquet, S. Cheng, N. Chen, Bridging idealized and operational models: an explainable ai framework for earth system emulators, npj Climate and Atmospheric Science (2026)
2026
-
[34]
Y. Song, J. Sohl-Dickstein, D. P. Kingma, A. Kumar, S. Ermon, B. Poole, Score-based generative modeling through stochastic differential equations, arXiv preprint arXiv:2011.13456 (2020)
work page internal anchor Pith review Pith/arXiv arXiv 2011
-
[35]
J. Ho, A. Jain, P. Abbeel, Denoising diffusion probabilistic models, Advances in neural information processing systems 33 (2020) 6840–6851
2020
-
[36]
Manshausen, Y
P. Manshausen, Y. Cohen, P. Harrington, J. Pathak, M. Pritchard, P. Garg, M. Mardani, K. Kashinath, S. Byrne, N. Brenowitz, Generative data assimilation of sparse weather station observations at kilometer scales, Journal of Advances in Modeling Earth Systems 17 (2025) e2024MS004505
2025
-
[37]
Z. Xun, S. Gupta, E. Price, Posterior sampling by combining diffusion models with annealed langevin dynamics, Advances in Neural Information Processing Systems 38 (2026) 76108–76165
2026
-
[38]
Rozet, G
F. Rozet, G. Louppe, Score-based data assimilation, Advances in Neural Information Processing Systems 36 (2023) 40521–40541
2023
-
[39]
G. Batzolis, J. Stanczuk, C.-B. Schönlieb, C. Etmann, Conditional image generation with score-based diffusion models, arXiv preprint arXiv:2111.13606 (2021). 29
-
[40]
Price, A
I. Price, A. Sanchez-Gonzalez, F. Alet, T. R. Andersson, A. El-Kadi, D. Masters, T. Ewalds, J. Stott, S. Mohamed, P. Battaglia, et al., Probabilistic weather forecasting with machine learning, Nature 637 (2025) 84–90
2025
-
[41]
M. R. Hasan, P. Behnoudfar, D. MacKinlay, T. Poulet, Pc-srgan: Physically consistent super-resolution generative adversarial network for general transient simulations, IEEE Transactions on Pattern Analysis and Machine Intelligence (2025)
2025
-
[42]
N. Chen, A. J. Majda, Conditional gaussian systems for multiscale nonlinear stochastic systems: Prediction, state estimation and uncertainty quantification, Entropy 20 (2018) 509
2018
-
[43]
N. Chen, Y. Li, H. Liu, Conditional gaussian nonlinear system: A fast preconditioner and a cheap surrogate model for complex nonlinear systems, Chaos: An Interdisciplinary Journal of Nonlinear Science 32 (2022)
2022
-
[44]
Noise2Noise: Learning Image Restoration without Clean Data
J. Lehtinen, J. Munkberg, J. Hasselgren, S. Laine, T. Karras, M. Aittala, T. Aila, Noise2noise: Learning image restoration without clean data, arXiv preprint arXiv:1803.04189 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[45]
R. S. Liptser, A. N. Shiryaev, Statistics of random processes II: Applications, volume 6, Springer Science & Business Media, 2013
2013
-
[46]
N. Chen, A. J. Majda, D. Giannakis, Predicting the cloud patterns of the Madden-Julian oscillation through a low-order nonlinear stochastic model, Geophysical Research Letters 41 (2014) 5612–5619
2014
-
[47]
N. Chen, S. Fu, G. E. Manucharyan, An efficient and statistically accurate Lagrangian data assimilation algorithm with applications to discrete element sea ice models, Journal of Computational Physics 455 (2022) 111000
2022
-
[48]
N. Chen, A. J. Majda, X. T. Tong, Information barriers for noisy Lagrangian tracers in filtering random incompressible flows, Nonlinearity 27 (2014) 2133
2014
-
[49]
A. J. Majda, N. Chen, Model error, information barriers, state estimation and prediction in complex multiscale systems, Entropy 20 (2018) 644
2018
-
[50]
N. Chen, A. J. Majda, Beating the curse of dimension with accurate statistics for the Fokker–Planck equation in complex turbulent systems, Proceedings of the National Academy of Sciences 114 (2017) 12864–12869
2017
-
[51]
Grooms, A
I. Grooms, A. J. Majda, Efficient stochastic superparameterization for geophysical turbulence, Pro- ceedings of the National Academy of Sciences 110 (2013) 4464–4469
2013
-
[52]
Branicki, A
M. Branicki, A. J. Majda, Dynamic stochastic superresolution of sparsely observed turbulent systems, Journal of Computational Physics 241 (2013) 333–363
2013
-
[53]
Andreou, N
M. Andreou, N. Chen, A martingale-free introduction to conditional gaussian nonlinear systems, En- tropy 27 (2024) 2
2024
-
[54]
C. Chen, Z. Wang, N. Chen, J.-L. Wu, Modeling partially observed nonlinear dynamical systems and efficient data assimilation via discrete-time conditional gaussian koopman network, Computer Methods in Applied Mechanics and Engineering 445 (2025) 118189
2025
-
[55]
Burgers, P
G. Burgers, P. Jan van Leeuwen, G. Evensen, Analysis scheme in the ensemble kalman filter, Monthly weather review 126 (1998) 1719–1724
1998
-
[56]
C. Chen, N. Chen, Y. Zhang, J.-L. Wu, Cgkn: A deep learning framework for modeling complex dynamical systems and efficient data assimilation, Journal of Computational Physics 532 (2025) 113950. 30
2025
-
[57]
Vincent, A connection between score matching and denoising autoencoders, Neural computation 23 (2011) 1661–1674
P. Vincent, A connection between score matching and denoising autoencoders, Neural computation 23 (2011) 1661–1674
2011
-
[58]
Y. Song, S. Ermon, Improved techniques for training score-based generative models, Advances in neural information processing systems 33 (2020) 12438–12448
2020
-
[59]
Durmus, S
A. Durmus, S. Majewski, B. Miasojedow, Analysis of langevin monte carlo via convex optimization, Journal of Machine Learning Research 20 (2019) 1–46
2019
-
[60]
Mechanisms and Pathways of Extreme Events in Partially-Observed Stochastic Dynamical Systems
C. Moser, N. Chen, M. Andreou, Mechanisms and pathways of extreme events in partially-observed stochastic dynamical systems, arXiv preprint arXiv:2605.22692 (2026)
work page internal anchor Pith review Pith/arXiv arXiv 2026
-
[61]
A. J. Majda, J. Harlim, Physics constrained nonlinear regression models for time series, Nonlinearity 26 (2013) 201–217
2013
-
[62]
Majda, X
A. Majda, X. Wang, Nonlinear dynamics and statistical theories for basic geophysical flows, Cambridge University Press, 2006
2006
-
[63]
N. Chen, A. J. Majda, Predicting observed and hidden extreme events in complex nonlinear dynamical systems with partial observations and short training time series, Chaos: An Interdisciplinary Journal of Nonlinear Science 30 (2020)
2020
-
[64]
G. K. Vallis, Atmospheric and oceanic fluid dynamics, Cambridge University Press, 2017
2017
-
[65]
E. N. Lorenz, Predictability: A problem partly solved, in: Proc. Seminar on predictability, volume 1, Reading, 1996, pp. 1–18
1996
-
[66]
Arnold, I
H. Arnold, I. Moroz, T. Palmer, Stochastic parametrizations and model uncertainty in the Lorenz’96 system, Philosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 371 (2013)
2013
-
[67]
C. M. Stein, Estimation of the mean of a multivariate normal distribution, The annals of Statistics (1981) 1135–1151
1981
-
[68]
M. Chen, K. Huang, T. Zhao, M. Wang, Score approximation, estimation and distribution recovery of diffusion models on low-dimensional data, in: International Conference on Machine Learning, PMLR, 2023, pp. 4672–4712
2023
-
[69]
Mandel, L
J. Mandel, L. Cobb, J. D. Beezley, On the convergence of the ensemble kalman filter, Applications of Mathematics 56 (2011) 533–541
2011
-
[70]
B. Efron, Tweedie’s formula and selection bias, Journal of the American Statistical Association 106 (2011) 1602–1614. doi:10.1198/jasa.2011.tm11181
-
[71]
M. Raphan, E. P. Simoncelli, Least squares estimation without priors or supervision, Neural Compu- tation 23 (2011) 374–420. doi:10.1162/NECO_a_00076
-
[72]
E. A. Carlen, D. W. Stroock, An application of the bakry-emery criterion to infinite dimensional diffusions, in: Séminaire de Probabilités XX 1984/85: Proceedings, Springer, 2006, pp. 341–348
1984
-
[73]
Prékopa, On logarithmic concave measures and functions, Acta Sci
A. Prékopa, On logarithmic concave measures and functions, Acta Sci. Math. 34 (1973) 335
1973
-
[74]
On the Measure of Intelligence
A. Wibisono, Proximal Langevin algorithm: Rapid convergence under isoperimetry, arXiv preprint arXiv:1911.01547 (2019)
work page internal anchor Pith review Pith/arXiv arXiv 1911
-
[75]
A. J. Majda, D. Qi, Strategies for reduced-order models for predicting the statistical responses and uncertainty quantification in complex turbulent dynamical systems, SIAM Review 60 (2018) 491–549. 31
2018
-
[76]
Sznitman, Topics in propagation of chaos, volume 1464 of lecture notes in mathematics, 1991
A.-S. Sznitman, Topics in propagation of chaos, volume 1464 of lecture notes in mathematics, 1991
1991
-
[77]
Moral, Feynman-Kac formulae: genealogical and interacting particle systems with applications, Springer, 2004
P. Moral, Feynman-Kac formulae: genealogical and interacting particle systems with applications, Springer, 2004
2004
-
[78]
Leshno, V
M. Leshno, V. Y. Lin, A. Pinkus, S. Schocken, Multilayer feedforward networks with a nonpolynomial activation function can approximate any function, Neural networks 6 (1993) 861–867. Appendix A. Proof of Theorem 1 Proof.DSM identity.Write ˜Vk =V k +σϵwithϵ∼ N(0,I)and lets tot,k =s EnKF,k +s θ. The DSM objective (4.12) is L(θ) =E Vk,ϵ σ2 stot,k( ˜Vk) + ϵ σ...
1993
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.