CogniRoute: Learning to Route Social Evidence in Omni-Modal Models
Pith reviewed 2026-06-26 17:34 UTC · model grok-4.3
The pith
A cognitive schema guides expert routing in omni-modal models to select the right evidence from video, audio, and text for social questions.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
CogniRoute is a schema-guided Mixture-of-Experts framework for social omni reasoning that uses a training-only cognitive schema to factorize each example by cross-modal relation, reasoning demand, and temporal scope, aligns global routing signatures with this structure during supervised fine-tuning, and jointly optimizes token generation and expert allocation through route-aware reinforcement learning with rewards for answer correctness, modality-consistent reasoning, and cognitive temporal grounding. On the introduced OmniSocialBench it reaches 59.38 percent average accuracy, 15.33 points above the strongest proprietary baseline and 26.77 points above the strongest open-source omni baseline
What carries the argument
The cognitive schema that factorizes training examples by cross-modal relation, reasoning demand, and temporal scope to produce routing signatures for expert selection inside the Mixture-of-Experts model.
If this is right
- Accuracy rises most on questions that need audio-visual coordination or resolution of conflicts between what is said and what is shown.
- Route-aware reinforcement learning improves both answer correctness and the consistency of reasoning across modalities.
- Explicit schema labels on 118K examples enable finer-grained diagnosis of where social reasoning fails.
- The same routing signatures support better performance on temporally grounded inference tasks without requiring changes at inference time.
Where Pith is reading between the lines
- If the factorization produces signatures that transfer, the same schema approach could be applied to other evidence-selection problems such as medical video or meeting summarization.
- The separation of schema use to training only suggests a way to add new modalities without retraining the entire router from scratch.
- The benchmark's grounded traces and temporal spans make it possible to test whether routing improvements are truly driven by evidence selection rather than surface patterns.
Load-bearing premise
The cognitive schema factorizes examples so that the resulting routing signatures are causally responsible for the accuracy gains and generalize beyond the training distribution.
What would settle it
An ablation that removes the schema-guided alignment or the route-aware reinforcement learning and still obtains the same 15-point gain on the evaluation split of OmniSocialBench would falsify the claim that these components drive the reported improvements.
Figures

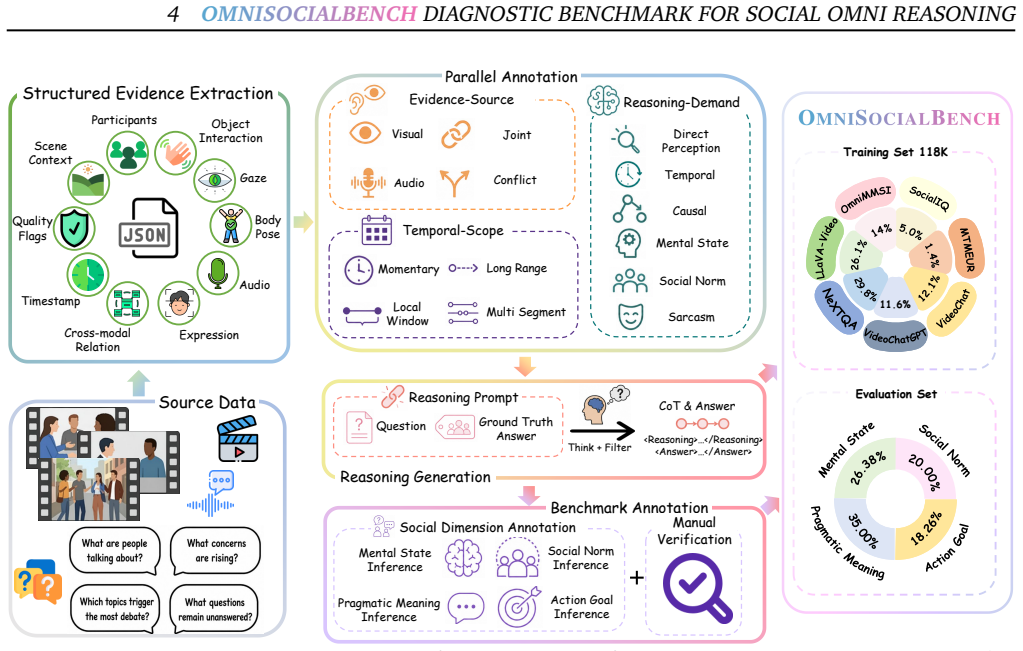
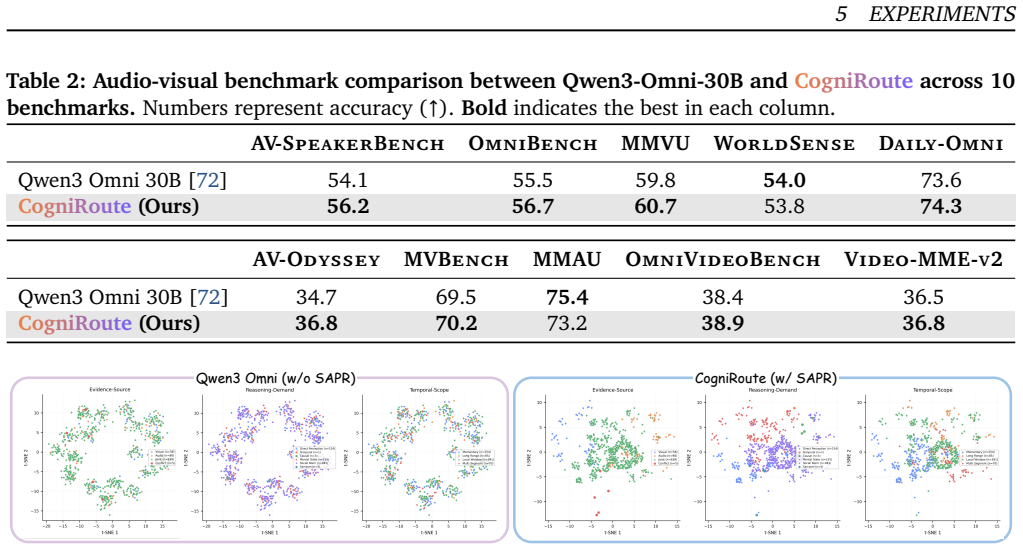
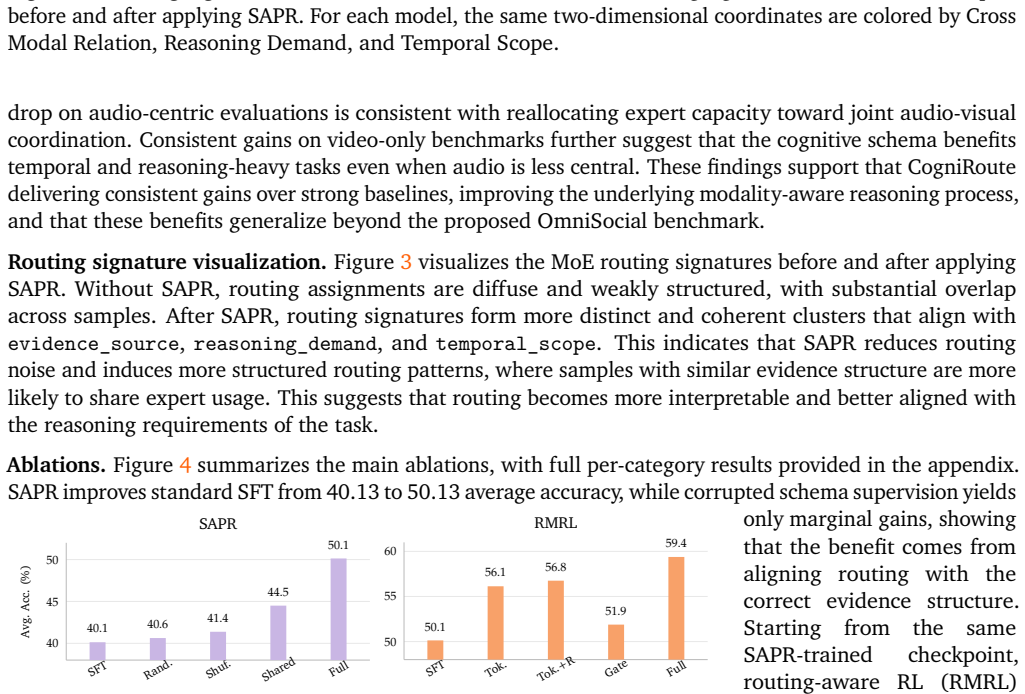














read the original abstract
Omni-modal models can ingest video, audio, and text, but unified access to multiple modalities does not guarantee that a model uses the right evidence. This gap is especially pronounced in social video question answering, where the answer may hinge on a gesture, vocal tone, temporal cue, or mismatch between what is said and what is visually expressed. We introduce CogniRoute, a schema-guided Mixture-of-Experts framework for social omni reasoning. CogniRoute uses a training-only cognitive schema that factorizes each example by cross-modal relation, reasoning demand, and temporal scope, and aligns global routing signatures with this structure during supervised fine-tuning. We further introduce route-aware reinforcement learning, which jointly optimizes token generation and expert allocation using rewards for answer correctness, modality-consistent reasoning, and cognitive temporal grounding. To support training and evaluation, we construct OmniSocialBench, a diagnostic social video QA resource with 118K structured training examples, grounded reasoning traces, schema labels, temporal evidence spans, and a manually verified evaluation split. CogniRoute achieves 59.38\% average accuracy on OmniSocialBench, improving over the strongest proprietary baseline by 15.33 percentage points and the strongest open-source omni baseline by 26.77 points, with the largest gains on questions requiring audio-visual coordination, conflict resolution, and temporally grounded social inference.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces CogniRoute, a schema-guided Mixture-of-Experts framework for omni-modal social video question answering. It factorizes training examples via a training-only cognitive schema along cross-modal relation, reasoning demand, and temporal scope dimensions, aligns routing signatures to this schema during supervised fine-tuning, and applies route-aware reinforcement learning that jointly optimizes generation and expert allocation with rewards for answer correctness, modality-consistent reasoning, and temporal grounding. The authors release OmniSocialBench (118K structured training examples plus manually verified evaluation split) and report 59.38% average accuracy, exceeding the strongest proprietary baseline by 15.33 points and the strongest open-source omni baseline by 26.77 points, with largest gains on audio-visual coordination, conflict resolution, and temporally grounded inference questions.
Significance. If the accuracy gains are shown to be causally attributable to the cognitive schema and route-aware routing rather than data volume or generic MoE fine-tuning, the work would offer a concrete mechanism for evidence routing in omni-modal models on social reasoning tasks. The construction of a large diagnostic benchmark containing grounded reasoning traces, schema labels, and temporal evidence spans would additionally provide a reusable resource for evaluating cross-modal social inference.
major comments (2)
- [§5] §5 (Experimental evaluation): The central claim attributes the 15.33 pp and 26.77 pp gains, and the largest improvements on audio-visual coordination/conflict/temporal questions, to the cognitive schema producing generalizable routing signatures. No ablation is reported that removes schema alignment during SFT while retaining the MoE architecture, SFT/RL pipeline, and training data volume, nor one that replaces schema-derived signatures with random or baseline routing under otherwise identical conditions. This omission leaves open the possibility that gains arise from benchmark construction artifacts or generic MoE benefits rather than the claimed factorization.
- [§4.3] §4.3 (Route-aware reinforcement learning): The method jointly optimizes token generation and expert allocation via rewards for answer correctness, modality-consistent reasoning, and cognitive temporal grounding. The manuscript provides no implementation details on reward weighting, how modality consistency and temporal grounding are automatically scored during RL, or whether these auxiliary rewards introduce additional learned parameters. Without these specifics or an ablation isolating the route-aware component, it is impossible to determine whether the RL stage is necessary for the reported performance or could be replaced by standard RLHF.
minor comments (2)
- [§1] The abstract and introduction use the term 'cognitive schema' without an explicit formal definition or pseudocode for how the three factorization axes are assigned to each of the 118K examples.
- [§5] Table reporting per-category accuracies (presumably in §5) should include the number of evaluation examples per category to allow assessment of whether largest gains occur on the smallest or largest subsets.
Simulated Author's Rebuttal
We thank the referee for the constructive feedback. The comments highlight important gaps in experimental validation and methodological transparency. We address each point below and commit to revisions that strengthen the attribution of results to the proposed components.
read point-by-point responses
-
Referee: [§5] §5 (Experimental evaluation): The central claim attributes the 15.33 pp and 26.77 pp gains, and the largest improvements on audio-visual coordination/conflict/temporal questions, to the cognitive schema producing generalizable routing signatures. No ablation is reported that removes schema alignment during SFT while retaining the MoE architecture, SFT/RL pipeline, and training data volume, nor one that replaces schema-derived signatures with random or baseline routing under otherwise identical conditions. This omission leaves open the possibility that gains arise from benchmark construction artifacts or generic MoE benefits rather than the claimed factorization.
Authors: We agree that the absence of these ablations weakens the causal attribution of gains specifically to schema-guided routing. In the revised manuscript we will add two controlled ablations: (1) training the same MoE architecture and pipeline without schema alignment during SFT (i.e., using only standard routing), and (2) replacing schema-derived signatures with random or baseline routing while keeping all other elements fixed. These experiments will be run on the same data volume and reported alongside the main results, allowing readers to isolate the contribution of the cognitive schema. revision: yes
-
Referee: [§4.3] §4.3 (Route-aware reinforcement learning): The method jointly optimizes token generation and expert allocation via rewards for answer correctness, modality-consistent reasoning, and cognitive temporal grounding. The manuscript provides no implementation details on reward weighting, how modality consistency and temporal grounding are automatically scored during RL, or whether these auxiliary rewards introduce additional learned parameters. Without these specifics or an ablation isolating the route-aware component, it is impossible to determine whether the RL stage is necessary for the reported performance or could be replaced by standard RLHF.
Authors: We acknowledge that the current manuscript lacks the requested implementation details and an isolating ablation. In revision we will add: (i) the exact reward weights used for correctness, modality consistency, and temporal grounding; (ii) the automatic scoring procedures (cross-modal consistency via embedding alignment for modality consistency; evidence-span overlap for temporal grounding); (iii) confirmation that no extra learned parameters are introduced beyond the existing router; and (iv) an ablation comparing route-aware RL against standard RLHF that optimizes only generation quality. These additions will clarify the necessity of the route-aware component. revision: yes
Circularity Check
No circularity: empirical ML results with no derivation chain reducing to inputs by construction
full rationale
The paper describes an empirical framework (schema-guided MoE with SFT and route-aware RL) evaluated on a newly constructed benchmark (OmniSocialBench). No mathematical equations, first-principles derivations, or 'predictions' are presented that could reduce to fitted parameters or self-citations by construction. Performance numbers (59.38% accuracy, gains over baselines) are reported empirical outcomes on held-out evaluation data, not quantities forced by the training procedure itself. The absence of visible equations or load-bearing self-citations in the provided text means the central claims do not exhibit any of the enumerated circularity patterns. This is the expected finding for a standard applied ML paper whose validity rests on external benchmarks and ablations rather than internal definitional equivalence.
Axiom & Free-Parameter Ledger
invented entities (2)
-
cognitive schema
no independent evidence
-
route-aware reinforcement learning
no independent evidence
Reference graph
Works this paper leans on
-
[2]
Qwen2.5-vl technical report, 2025 b
Shuai Bai, Keqin Chen, Xuejing Liu, Jialin Wang, Wenbin Ge, Sibo Song, Kai Dang, Peng Wang, Shijie Wang, Jun Tang, Humen Zhong, Yuanzhi Zhu, Mingkun Yang, Zhaohai Li, Jianqiang Wan, Pengfei Wang, Wei Ding, Zheren Fu, Yiheng Xu, Jiabo Ye, Xi Zhang, Tianbao Xie, Zesen Cheng, Hang Zhang, Zhibo Yang, Haiyang Xu, and Junyang Lin. Qwen2.5-vl technical report, 2025 b
2025
-
[3]
Vlmo: Unified vision-language pre-training with mixture-of-modality-experts
Hangbo Bao, Wenhui Wang, Li Dong, Qiang Liu, Owais Khan Mohammed, Kriti Aggarwal, Subhojit Som, Songhao Piao, and Furu Wei. Vlmo: Unified vision-language pre-training with mixture-of-modality-experts. Advances in neural information processing systems, 35: 0 32897--32912, 2022
2022
-
[4]
Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning, 2026
Meng Cao, Haoze Zhao, Can Zhang, Xiaojun Chang, Ian Reid, and Xiaodan Liang. Ground-r1: Incentivizing grounded visual reasoning via reinforcement learning, 2026
2026
-
[6]
Eve: Efficient vision-language pre-training with masked prediction and modality-aware moe
Junyi Chen, Longteng Guo, Jia Sun, Shuai Shao, Zehuan Yuan, Liang Lin, and Dongyu Zhang. Eve: Efficient vision-language pre-training with masked prediction and modality-aware moe. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 38, pages 1110--1119, 2024 a
2024
-
[7]
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks
Zhe Chen, Jiannan Wu, Wenhai Wang, Weijie Su, Guo Chen, Sen Xing, Muyan Zhong, Qinglong Zhang, Xizhou Zhu, Lewei Lu, et al. Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pages 24185--24198, 2024 b
2024
-
[8]
On the representation collapse of sparse mixture of experts
Zewen Chi, Li Dong, Shaohan Huang, Damai Dai, Shuming Ma, Barun Patra, Saksham Singhal, Payal Bajaj, Xia Song, Xian-Ling Mao, et al. On the representation collapse of sparse mixture of experts. Advances in Neural Information Processing Systems, 35: 0 34600--34613, 2022
2022
-
[9]
Qwen look again: Guiding vision-language reasoning models to re-attention visual information, 2025
Xu Chu, Xinrong Chen, Guanyu Wang, Zhijie Tan, Kui Huang, Wenyu Lv, Tong Mo, and Weiping Li. Qwen look again: Guiding vision-language reasoning models to re-attention visual information, 2025
2025
-
[11]
Got-r1: Unleashing reasoning capability of mllm for visual generation with reinforcement learning, 2025
Chengqi Duan, Rongyao Fang, Yuqing Wang, Kun Wang, Linjiang Huang, Xingyu Zeng, Hongsheng Li, and Xihui Liu. Got-r1: Unleashing reasoning capability of mllm for visual generation with reinforcement learning, 2025
2025
-
[13]
Grit: Teaching mllms to think with images, 2025
Yue Fan, Xuehai He, Diji Yang, Kaizhi Zheng, Ching-Chen Kuo, Yuting Zheng, Sravana Jyothi Narayanaraju, Xinze Guan, and Xin Eric Wang. Grit: Teaching mllms to think with images, 2025
2025
-
[20]
Beyond emotion recognition: A multi-turn multimodal emotion understanding and reasoning benchmark
Jinpeng Hu, Hongchang Shi, Chongyuan Dai, Zhuo Li, Peipei Song, and Meng Wang. Beyond emotion recognition: A multi-turn multimodal emotion understanding and reasoning benchmark. In Proceedings of the 33rd ACM International Conference on Multimedia, pages 5814--5823, 2025
2025
-
[22]
Tutel: Adaptive mixture-of-experts at scale
Changho Hwang, Wei Cui, Yifan Xiong, Ziyue Yang, Ze Liu, Han Hu, Zilong Wang, Rafael Salas, Jithin Jose, Prabhat Ram, et al. Tutel: Adaptive mixture-of-experts at scale. Proceedings of Machine Learning and Systems, 5: 0 269--287, 2023
2023
-
[28]
Mvbench: A comprehensive multi-modal video understanding benchmark
Kunchang Li, Yali Wang, Yinan He, Yizhuo Li, Yi Wang, Yi Liu, Zun Wang, Jilan Xu, Guo Chen, Ping Luo, et al. Mvbench: A comprehensive multi-modal video understanding benchmark. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 22195--22206, 2024 c
2024
-
[29]
Videochat: Chat-centric video understanding
KunChang Li, Yinan He, Yi Wang, Yizhuo Li, Wenhai Wang, Ping Luo, Yali Wang, Limin Wang, and Yu Qiao. Videochat: Chat-centric video understanding. Science China Information Sciences, 68 0 (10): 0 200102, 2025 b
2025
-
[33]
Pace: Unified multi-modal dialogue pre-training with progressive and compositional experts
Yunshui Li, Binyuan Hui, ZhiChao Yin, Min Yang, Fei Huang, and Yongbin Li. Pace: Unified multi-modal dialogue pre-training with progressive and compositional experts. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 13402--13416, 2023
2023
-
[34]
Uni-moe: Scaling unified multimodal llms with mixture of experts
Yunxin Li, Shenyuan Jiang, Baotian Hu, Longyue Wang, Wanqi Zhong, Wenhan Luo, Lin Ma, and Min Zhang. Uni-moe: Scaling unified multimodal llms with mixture of experts. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2025 d
2025
-
[35]
Let's verify step by step
Hunter Lightman, Vineet Kosaraju, Yuri Burda, Harrison Edwards, Bowen Baker, Teddy Lee, Jan Leike, John Schulman, Ilya Sutskever, and Karl Cobbe. Let's verify step by step. In The twelfth international conference on learning representations, 2023
2023
-
[36]
Video-llava: Learning united visual representation by alignment before projection
Bin Lin, Yang Ye, Bin Zhu, Jiaxi Cui, Munan Ning, Peng Jin, and Li Yuan. Video-llava: Learning united visual representation by alignment before projection. In Proceedings of the 2024 conference on empirical methods in natural language processing, pages 5971--5984, 2024
2024
-
[37]
Moe-llava: Mixture of experts for large vision-language models
Bin Lin, Zhenyu Tang, Yang Ye, Jinfa Huang, Junwu Zhang, Yatian Pang, Peng Jin, Munan Ning, Jiebo Luo, and Li Yuan. Moe-llava: Mixture of experts for large vision-language models. IEEE Transactions on Multimedia, 2026
2026
-
[38]
Visual instruction tuning
Haotian Liu, Chunyuan Li, Qingyang Wu, and Yong Jae Lee. Visual instruction tuning. Advances in neural information processing systems, 36: 0 34892--34916, 2023
2023
-
[39]
Tackling data bias in music-avqa: Crafting a balanced dataset for unbiased question-answering
Xiulong Liu, Zhikang Dong, and Peng Zhang. Tackling data bias in music-avqa: Crafting a balanced dataset for unbiased question-answering. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, pages 4478--4487, 2024
2024
-
[41]
Multiway-adapater: Adapting large-scale multi-modal models for scalable image-text retrieval, 2024
Zijun Long, George Killick, Richard McCreadie, and Gerardo Aragon Camarasa. Multiway-adapater: Adapting large-scale multi-modal models for scalable image-text retrieval, 2024
2024
-
[42]
Multimodal contrastive learning with limoe: the language-image mixture of experts
Basil Mustafa, Carlos Riquelme, Joan Puigcerver, Rodolphe Jenatton, and Neil Houlsby. Multimodal contrastive learning with limoe: the language-image mixture of experts. Advances in Neural Information Processing Systems, 35: 0 9564--9576, 2022
2022
-
[44]
Training vision-language process reward models for test-time scaling in multimodal reasoning: Key insights and lessons learned, 2025
Brandon Ong, Tej Deep Pala, Vernon Toh, William Chandra Tjhi, and Soujanya Poria. Training vision-language process reward models for test-time scaling in multimodal reasoning: Key insights and lessons learned, 2025
2025
-
[45]
Fsmoe: A flexible and scalable training system for sparse mixture-of-experts models
Xinglin Pan, Wenxiang Lin, Lin Zhang, Shaohuai Shi, Zhenheng Tang, Rui Wang, Bo Li, and Xiaowen Chu. Fsmoe: A flexible and scalable training system for sparse mixture-of-experts models. In Proceedings of the 30th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 1, pages 524--539, 2025
2025
-
[46]
Assessing modality bias in video question answering benchmarks with multimodal large language models
Jean Park, Kuk Jin Jang, Basam Alasaly, Sriharsha Mopidevi, Andrew Zolensky, Eric Eaton, Insup Lee, and Kevin Johnson. Assessing modality bias in video question answering benchmarks with multimodal large language models. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 39, pages 19821--19829, 2025
2025
-
[47]
Scaling vision with sparse mixture of experts
Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, Andr \'e Susano Pinto, Daniel Keysers, and Neil Houlsby. Scaling vision with sparse mixture of experts. Advances in Neural Information Processing Systems, 34: 0 8583--8595, 2021
2021
-
[49]
Rome: Role-aware mixture-of-expert transformer for text-to-video retrieval, 2022
Burak Satar, Hongyuan Zhu, Hanwang Zhang, and Joo Hwee Lim. Rome: Role-aware mixture-of-expert transformer for text-to-video retrieval, 2022
2022
-
[50]
Zhihong Shao, Peiyi Wang, Qihao Zhu, Runxin Xu, Junxiao Song, Xiao Bi, Haowei Zhang, Mingchuan Zhang, Y. K. Li, Y. Wu, and Daya Guo. Deepseekmath: Pushing the limits of mathematical reasoning in open language models, 2024
2024
-
[51]
Vlm-r1: A stable and generalizable r1-style large vision-language model, 2025
Haozhan Shen, Peng Liu, Jingcheng Li, Chunxin Fang, Yibo Ma, Jiajia Liao, Qiaoli Shen, Zilun Zhang, Kangjia Zhao, Qianqian Zhang, Ruochen Xu, and Tiancheng Zhao. Vlm-r1: A stable and generalizable r1-style large vision-language model, 2025
2025
-
[52]
Mome: Mixture of multimodal experts for generalist multimodal large language models
Leyang Shen, Gongwei Chen, Rui Shao, Weili Guan, and Liqiang Nie. Mome: Mixture of multimodal experts for generalist multimodal large language models. Advances in neural information processing systems, 37: 0 42048--42070, 2024
2024
-
[54]
Fine-grained preference optimization improves spatial reasoning in vlms
Yifan Shen, Yuanzhe Liu, Jingyuan Zhu, Xu Cao, Xiaofeng Zhang, Yixiao He, Wenming Ye, James Rehg, and Ismini Lourentzou. Fine-grained preference optimization improves spatial reasoning in vlms. Advances in Neural Information Processing Systems, 38: 0 17929--17960, 2026 b
2026
-
[56]
Openthinkimg: Learning to think with images via visual tool reinforcement learning, 2025
Zhaochen Su, Linjie Li, Mingyang Song, Yunzhuo Hao, Zhengyuan Yang, Jun Zhang, Guanjie Chen, Jiawei Gu, Juntao Li, Xiaoye Qu, and Yu Cheng. Openthinkimg: Learning to think with images via visual tool reinforcement learning, 2025
2025
-
[61]
Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology, 2026
Haochen Wang, Xiangtai Li, Zilong Huang, Anran Wang, Jiacong Wang, Tao Zhang, Jiani Zheng, Sule Bai, Zijian Kang, Jiashi Feng, Zhuochen Wang, and Zhaoxiang Zhang. Traceable evidence enhanced visual grounded reasoning: Evaluation and methodology, 2026
2026
-
[63]
Visualprm: An effective process reward model for multimodal reasoning, 2025 b
Weiyun Wang, Zhangwei Gao, Lianjie Chen, Zhe Chen, Jinguo Zhu, Xiangyu Zhao, Yangzhou Liu, Yue Cao, Shenglong Ye, Xizhou Zhu, Lewei Lu, Haodong Duan, Yu Qiao, Jifeng Dai, and Wenhai Wang. Visualprm: An effective process reward model for multimodal reasoning, 2025 b
2025
-
[64]
Vg-refiner: Towards tool-refined referring grounded reasoning via agentic reinforcement learning, 2025 c
Yuji Wang, Wenlong Liu, Jingxuan Niu, Haoji Zhang, and Yansong Tang. Vg-refiner: Towards tool-refined referring grounded reasoning via agentic reinforcement learning, 2025 c
2025
-
[65]
Longvideobench: A benchmark for long-context interleaved video-language understanding
Haoning Wu, Dongxu Li, Bei Chen, and Junnan Li. Longvideobench: A benchmark for long-context interleaved video-language understanding. Advances in Neural Information Processing Systems, 37: 0 28828--28857, 2024
2024
-
[66]
Routing experts: Learning to route dynamic experts in existing multi-modal large language models
Qiong Wu, Zhaoxi Ke, Yiyi Zhou, Xiaoshuai Sun, and Rongrong Ji. Routing experts: Learning to route dynamic experts in existing multi-modal large language models. In The Thirteenth International Conference on Learning Representations, 2025
2025
-
[69]
Next-qa: Next phase of question-answering to explaining temporal actions
Junbin Xiao, Xindi Shang, Angela Yao, and Tat-Seng Chua. Next-qa: Next phase of question-answering to explaining temporal actions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), pages 9777--9786, June 2021
2021
-
[71]
Qwen2.5-omni technical report, 2025 a
Jin Xu, Zhifang Guo, Jinzheng He, Hangrui Hu, Ting He, Shuai Bai, Keqin Chen, Jialin Wang, Yang Fan, Kai Dang, Bin Zhang, Xiong Wang, Yunfei Chu, and Junyang Lin. Qwen2.5-omni technical report, 2025 a
2025
-
[76]
R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization, 2025 c
Yi Yang, Xiaoxuan He, Hongkun Pan, Xiyan Jiang, Yan Deng, Xingtao Yang, Haoyu Lu, Dacheng Yin, Fengyun Rao, Minfeng Zhu, Bo Zhang, and Wei Chen. R1-onevision: Advancing generalized multimodal reasoning through cross-modal formalization, 2025 c
2025
-
[79]
Social-iq: A question answering benchmark for artificial social intelligence
Amir Zadeh, Michael Chan, Paul Pu Liang, Edmund Tong, and Louis-Philippe Morency. Social-iq: A question answering benchmark for artificial social intelligence. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 8807--8817, 2019
2019
-
[82]
Video instruction tuning with synthetic data, 2024
Yuanhan Zhang, Jinming Wu, Wei Li, Bo Li, Zejun Ma, Ziwei Liu, and Chunyuan Li. Video instruction tuning with synthetic data, 2024
2024
-
[85]
Mmvu: Measuring expert-level multi-discipline video understanding
Yilun Zhao, Haowei Zhang, Lujing Xie, Tongyan Hu, Guo Gan, Yitao Long, Zhiyuan Hu, Weiyuan Chen, Chuhan Li, Zhijian Xu, et al. Mmvu: Measuring expert-level multi-discipline video understanding. In Proceedings of the Computer Vision and Pattern Recognition Conference, pages 8475--8489, 2025 c
2025
-
[86]
thinking with images
Ziwei Zheng, Michael Yang, Jack Hong, Chenxiao Zhao, Guohai Xu, Le Yang, Chao Shen, and Xing Yu. Deepeyes: Incentivizing "thinking with images" via reinforcement learning, 2026
2026
-
[87]
aha moment
Hengguang Zhou, Xirui Li, Ruochen Wang, Minhao Cheng, Tianyi Zhou, and Cho-Jui Hsieh. R1-zero's "aha moment" in visual reasoning on a 2b non-sft model, 2025 a
2025
-
[89]
arXiv preprint arXiv:2409.12191 , year=
Qwen2-vl: Enhancing vision-language model's perception of the world at any resolution , author=. arXiv preprint arXiv:2409.12191 , year=
-
[90]
arXiv preprint arXiv:2603.16859 , year=
SocialOmni: Benchmarking Audio-Visual Social Interactivity in Omni Models , author=. arXiv preprint arXiv:2603.16859 , year=
-
[91]
arXiv preprint arXiv:2506.21277 , year=
Humanomniv2: From understanding to omni-modal reasoning with context , author=. arXiv preprint arXiv:2506.21277 , year=
-
[92]
arXiv preprint arXiv:2503.05379 , year=
R1-omni: Explainable omni-multimodal emotion recognition with reinforcement learning , author=. arXiv preprint arXiv:2503.05379 , year=
-
[93]
arXiv preprint arXiv:2501.15111 , year=
Humanomni: A large vision-speech language model for human-centric video understanding , author=. arXiv preprint arXiv:2501.15111 , year=
-
[94]
2025 , eprint=
Qwen2.5-VL Technical Report , author=. 2025 , eprint=
2025
-
[95]
arXiv preprint arXiv:2509.04500 , year=
Context Engineering for Trustworthiness: Rescorla Wagner Steering Under Mixed and Inappropriate Contexts , author=. arXiv preprint arXiv:2509.04500 , year=
-
[96]
arXiv preprint arXiv:2601.07060 , year=
PALM: Progress-Aware Policy Learning via Affordance Reasoning for Long-Horizon Robotic Manipulation , author=. arXiv preprint arXiv:2601.07060 , year=
-
[97]
arXiv preprint arXiv:2603.20169 , year=
Egoforge: Goal-directed egocentric world simulator , author=. arXiv preprint arXiv:2603.20169 , year=
-
[98]
doi:10.20944/preprints202606.0173.v1 , year = 2026, month =
Haichao Zhang and Mingfei Chen and Shwai He and Zhengtong Xu and others , title =. doi:10.20944/preprints202606.0173.v1 , year = 2026, month =
-
[99]
arXiv preprint arXiv:2602.01541 , year=
Toward Cognitive Supersensing in Multimodal Large Language Model , author=. arXiv preprint arXiv:2602.01541 , year=
-
[100]
arXiv preprint arXiv:2511.21631 , year=
Qwen3-vl technical report , author=. arXiv preprint arXiv:2511.21631 , year=
-
[101]
arXiv preprint arXiv:2406.10424 , year=
What is the visual cognition gap between humans and multimodal llms? , author=. arXiv preprint arXiv:2406.10424 , year=
-
[102]
Advances in Neural Information Processing Systems , volume=
Fine-grained preference optimization improves spatial reasoning in vlms , author=. Advances in Neural Information Processing Systems , volume=
-
[103]
arXiv preprint arXiv:2506.09344 , year=
Ming-omni: A unified multimodal model for perception and generation , author=. arXiv preprint arXiv:2506.09344 , year=
-
[104]
arXiv preprint arXiv:2512.09841 , year=
ChronusOmni: Improving Time Awareness of Omni Large Language Models , author=. arXiv preprint arXiv:2512.09841 , year=
-
[105]
Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks , author=. Proceedings of the IEEE/CVF conference on computer vision and pattern recognition , pages=
-
[106]
arXiv preprint arXiv:2504.18425 , year=
Kimi-audio technical report , author=. arXiv preprint arXiv:2504.18425 , year=
-
[107]
arXiv preprint arXiv:2507.20939 , year=
Arc-hunyuan-video-7b: Structured video comprehension of real-world shorts , author=. arXiv preprint arXiv:2507.20939 , year=
-
[108]
arXiv preprint arXiv:2408.03326 , year=
Llava-onevision: Easy visual task transfer , author=. arXiv preprint arXiv:2408.03326 , year=
-
[109]
Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
Video-llava: Learning united visual representation by alignment before projection , author=. Proceedings of the 2024 conference on empirical methods in natural language processing , pages=
2024
-
[110]
Advances in neural information processing systems , volume=
Visual instruction tuning , author=. Advances in neural information processing systems , volume=
-
[111]
2025 , eprint=
Gemma 3 Technical Report , author=. 2025 , eprint=
2025
-
[112]
arXiv preprint arXiv:2504.07491 , year=
Kimi-vl technical report , author=. arXiv preprint arXiv:2504.07491 , year=
-
[113]
arXiv preprint arXiv:2501.13106 , year=
Videollama 3: Frontier multimodal foundation models for image and video understanding , author=. arXiv preprint arXiv:2501.13106 , year=
-
[114]
arXiv preprint arXiv:2312.11805 , year=
Gemini: a family of highly capable multimodal models , author=. arXiv preprint arXiv:2312.11805 , year=
-
[115]
arXiv preprint arXiv:2403.05530 , year=
Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context , author=. arXiv preprint arXiv:2403.05530 , year=
-
[116]
arXiv preprint arXiv:2507.06261 , year=
Gemini 2.5: Pushing the frontier with advanced reasoning, multimodality, long context, and next generation agentic capabilities , author=. arXiv preprint arXiv:2507.06261 , year=
-
[117]
arXiv preprint arXiv:2501.01957 , year=
Vita-1.5: Towards gpt-4o level real-time vision and speech interaction , author=. arXiv preprint arXiv:2501.01957 , year=
-
[118]
arXiv preprint arXiv:2410.21276 , year=
Gpt-4o system card , author=. arXiv preprint arXiv:2410.21276 , year=
-
[119]
arXiv preprint arXiv:2501.15368 , year=
Baichuan-omni-1.5 technical report , author=. arXiv preprint arXiv:2501.15368 , year=
-
[120]
arXiv preprint arXiv:2410.11190 , year=
Mini-omni2: Towards open-source gpt-4o with vision, speech and duplex capabilities , author=. arXiv preprint arXiv:2410.11190 , year=
-
[121]
2025 , eprint=
Qwen2.5-Omni Technical Report , author=. 2025 , eprint=
2025
-
[122]
arXiv preprint arXiv:2410.18325 , year=
Avhbench: A cross-modal hallucination benchmark for audio-visual large language models , author=. arXiv preprint arXiv:2410.18325 , year=
-
[123]
Proceedings of the AAAI Conference on Artificial Intelligence , volume=
Assessing modality bias in video question answering benchmarks with multimodal large language models , author=. Proceedings of the AAAI Conference on Artificial Intelligence , volume=
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.