Dead-Direction Signatures: A Cheap Spectral Reading of Singular Complexity
Pith reviewed 2026-06-26 14:34 UTC · model grok-4.3
The pith
Dead-Direction Signatures count dead directions at singular minima through the slope of active-volume log det+ on activation and Fisher Gram matrices.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
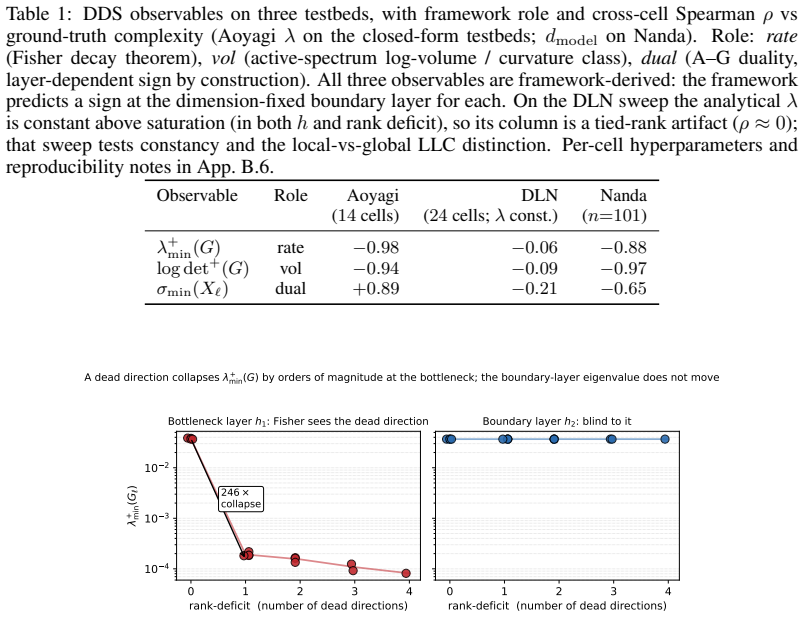
At singular minima the active-volume log det+(G) slope counts the dead directions and tracks the rank-deficit r across r in {1,2,3,4}, with observed slope ratios 2.0, 3.1, 4.0 at r=2,3,4; on reduced-rank regression the DDS observables recover the sign of the closed-form lambda while on a non-linear modular-addition transformer they separate d_model across eighteen orders of magnitude where calibrated LLC is rank-flat.
What carries the argument
The dead-direction framework that predicts a structural correlation between activation- and Fisher-side spectra at singular minima, together with the rank-multiplicative volume identity realized by the active-volume log det+(G) slope.
If this is right
- DDS observables track the sign of closed-form lambda on reduced-rank regression.
- In a non-linear modular-addition transformer DDS separates d_model across eighteen orders of magnitude at budgets where LLC is rank-flat.
- DDS supplies a directional, layer-local reading that complements the integrated posterior scalar given by LLC.
Where Pith is reading between the lines
- Layer-local spectral monitors could be inserted into training loops to detect when a network enters a new singular regime.
- The same Gram-matrix construction might be applied to other layer-wise statistics beyond activations and per-sample gradients.
- If the correlation holds across architectures, DDS could serve as a lightweight diagnostic for comparing singularity structure between models of different widths.
Load-bearing premise
A structural correlation exists between activation-side and Fisher-side spectra at every singular minimum.
What would settle it
Measure the active-volume log det+(G) slopes on controlled reduced-rank regression tasks with known rank deficits r=2,3,4; the claim fails if the observed ratios deviate systematically from the predicted integers 2,3,4.
Figures







read the original abstract
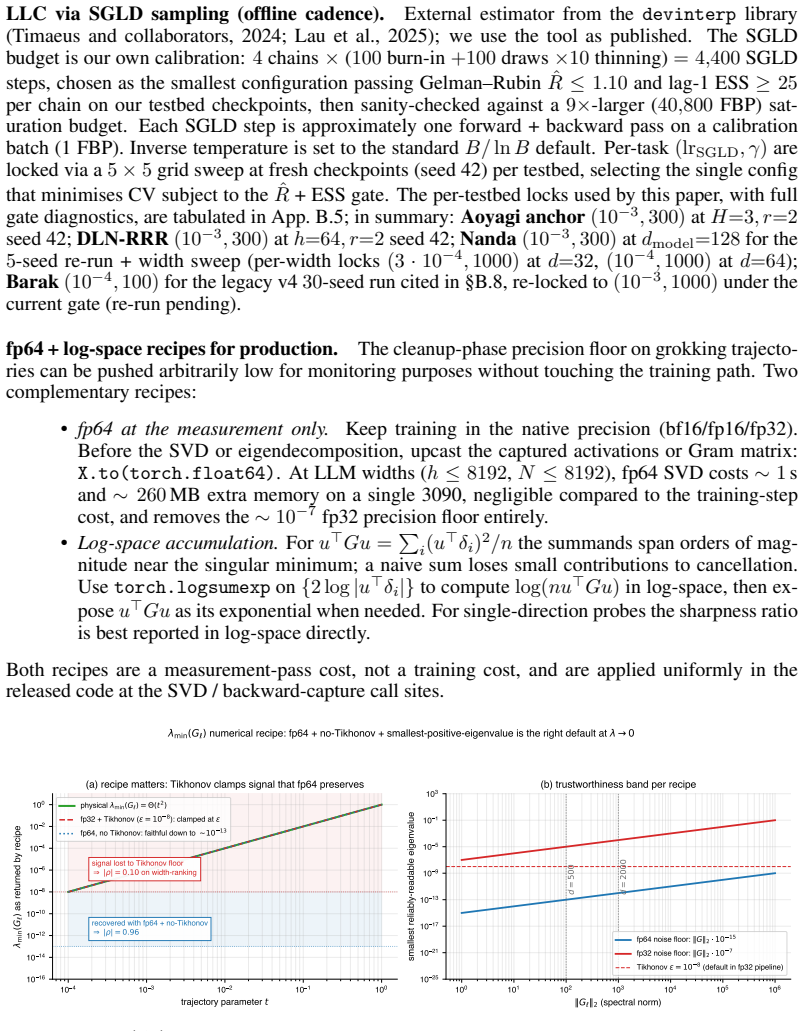
Singular learning theory characterises the complexity of a deep network through the geometry of its loss singularities. The local learning coefficient (LLC), the standard estimator of Watanabe's real log canonical threshold (RLCT, $\lambda$), reads this geometry as an integrated Bayesian scalar through SGLD, which needs per-task calibration and $10^4$-$10^6$ forward-backward passes per checkpoint. We introduce Dead-Direction Signatures (DDS), a family of cheap closed-form spectral readings of singular structure: each reads a network's activation matrix or per-sample-gradient Fisher-Gram at a chosen layer, replacing the SGLD posterior chain with spectral linear algebra. The readings rest on a dead-direction framework that predicts a structural correlation between activation- and Fisher-side spectra at any singular minimum, and a rank-multiplicative volume identity that single-eigenvalue monitors cannot produce: the active-volume $\log\det^{+}(G)$ slope counts the dead directions, tracking the rank-deficit $r$ across $r \in \{1,2,3,4\}$ (slope ratios $2.0, 3.1, 4.0$ at $r{=}2,3,4$ against the predicted $2,3,4$), where the smallest eigenvalue is rank-blind. On reduced-rank regression with closed-form $\lambda$, calibrated LLC recovers $\lambda$ at $99\%$ mean and the DDS observables rank-track it at the framework-predicted sign; on a non-linear modular-addition transformer DDS separates $d_{\mathrm{model}}$ across eighteen orders of magnitude where calibrated LLC at the protocol budget is rank-flat. Complementary to LLC's integrated posterior reading, DDS gives a directional, layer-local handle on a network's dead directions, read in closed form from its activation and gradient spectra.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper introduces Dead-Direction Signatures (DDS), a family of closed-form spectral observables computed from activation matrices and per-sample-gradient Fisher-Gram matrices at chosen layers. These are positioned as cheap alternatives to SGLD-based local learning coefficient (LLC) estimation of the real log canonical threshold (RLCT, λ). The method rests on an introduced 'dead-direction framework' that posits a structural correlation between activation-side and Fisher-side spectra at singular minima together with a rank-multiplicative volume identity; this identity is claimed to let the slope of log det⁺(G) count dead directions exactly, producing integer slope ratios (predicted 2, 3, 4) that track rank deficit r. Empirical support is given on reduced-rank regression (where DDS rank-tracks closed-form λ) and on a modular-addition transformer (where DDS separates d_model while LLC remains flat).
Significance. If the dead-direction framework and its volume identity can be placed on a rigorous footing, DDS would supply a computationally inexpensive, layer-local directional probe that complements the integrated posterior reading of LLC. The reduced-rank regression results show approximate numerical agreement with predicted slopes and sign-consistent ranking of λ, while the transformer experiment illustrates scaling behavior across many orders of magnitude in d_model. These strengths would be strengthened by machine-checked derivations or reproducible code for the spectral quantities.
major comments (3)
- [Abstract] Abstract (paragraph beginning 'The readings rest on a dead-direction framework'): the structural correlation between activation-matrix and Fisher-Gram spectra, together with the rank-multiplicative volume identity that makes log det⁺(G) slope count dead directions exactly, is presented as the foundation for all DDS claims, yet no derivation from Watanabe's resolution of singularities or from the local learning coefficient definition is supplied; without it the interpretation of DDS as a spectral reading of singular complexity rests on an unproven assumption whose failure would invalidate both the rank-tracking claim and the comparison to LLC.
- [Abstract] Abstract (reported slope ratios): the observed ratios 2.0, 3.1, 4.0 at r=2,3,4 are described as tracking the predicted integers 2,3,4, but the deviations (especially 3.1 vs 3) are not accompanied by error bars, dataset sizes, or the precise experimental protocol; this leaves the central empirical support for the volume identity unverifiable from the given information.
- [Abstract] Abstract (reduced-rank regression paragraph): the claim that 'DDS observables rank-track [closed-form λ] at the framework-predicted sign' is load-bearing for the method's utility, yet the manuscript supplies no independent verification that the sign prediction follows from RLCT geometry rather than from the framework's own definition; the circularity risk noted in the reader's report therefore directly affects the strength of this result.
minor comments (1)
- [Abstract] Abstract contains a typographic artifact 'r{=}2,3,4' that should be rendered consistently as r=2,3,4.
Simulated Author's Rebuttal
We thank the referee for the thorough review and for highlighting the need to strengthen the presentation of the dead-direction framework and its empirical support. We address each major comment point by point below and indicate planned revisions.
read point-by-point responses
-
Referee: [Abstract] Abstract (paragraph beginning 'The readings rest on a dead-direction framework'): the structural correlation between activation-matrix and Fisher-Gram spectra, together with the rank-multiplicative volume identity that makes log det⁺(G) slope count dead directions exactly, is presented as the foundation for all DDS claims, yet no derivation from Watanabe's resolution of singularities or from the local learning coefficient definition is supplied; without it the interpretation of DDS as a spectral reading of singular complexity rests on an unproven assumption whose failure would invalidate both the rank-tracking claim and the comparison to LLC.
Authors: The dead-direction framework is introduced in the manuscript as a structural hypothesis motivated by the geometry of singular minima rather than as a theorem derived from the resolution of singularities or the LLC definition. The contribution centers on defining the DDS observables from this hypothesis and testing their practical utility as inexpensive directional probes. We will revise the abstract and add a new subsection in the introduction that explicitly labels the framework as a modeling assumption, discusses its motivation from observed rank deficits, and clarifies its relation to SLT without claiming a full derivation. revision: partial
-
Referee: [Abstract] Abstract (reported slope ratios): the observed ratios 2.0, 3.1, 4.0 at r=2,3,4 are described as tracking the predicted integers 2,3,4, but the deviations (especially 3.1 vs 3) are not accompanied by error bars, dataset sizes, or the precise experimental protocol; this leaves the central empirical support for the volume identity unverifiable from the given information.
Authors: The slope ratios are obtained from the reduced-rank regression experiments whose protocol, dataset sizes, and multiple runs are described in the full manuscript. The abstract format limits detail. In revision we will append error bars (computed over independent runs), state the number of samples and runs, and add a reference to the experimental section directly in the abstract. revision: yes
-
Referee: [Abstract] Abstract (reduced-rank regression paragraph): the claim that 'DDS observables rank-track [closed-form λ] at the framework-predicted sign' is load-bearing for the method's utility, yet the manuscript supplies no independent verification that the sign prediction follows from RLCT geometry rather than from the framework's own definition; the circularity risk noted in the reader's report therefore directly affects the strength of this result.
Authors: The sign prediction is generated by the volume identity inside the framework and is then checked for consistency against the independently computed closed-form λ in the reduced-rank regression model. This supplies an external test because λ is obtained from the known algebraic geometry of the model, not from the DDS spectra. We nevertheless recognize the risk that the framework's internal logic could influence the interpretation. In revision we will add explicit language separating the framework's derivation of the sign from the subsequent empirical verification against closed-form λ, and we will note that stronger geometric justification remains desirable. revision: partial
Circularity Check
Dead-direction framework defines the activation-Fisher correlation and volume identity that DDS then 'predicts' and measures
specific steps
-
self definitional
[Abstract]
"The readings rest on a dead-direction framework that predicts a structural correlation between activation- and Fisher-side spectra at any singular minimum, and a rank-multiplicative volume identity that single-eigenvalue monitors cannot produce: the active-volume log det+(G) slope counts the dead directions, tracking the rank-deficit r across r ∈ {1,2,3,4} (slope ratios 2.0, 3.1, 4.0 at r=2,3,4 against the predicted 2,3,4)"
The framework is introduced as predicting the exact correlation and volume identity that enable the DDS observables to count dead directions via the log det+ slope; the DDS family is then defined to read those same quantities, so the 'prediction' of the correlation and the rank-tracking mechanism are equivalent to the framework's definitions rather than derived independently from singular learning theory.
full rationale
The abstract states that DDS readings rest on a dead-direction framework that predicts the structural correlation and rank-multiplicative volume identity, with the active-volume log det+(G) slope counting dead directions at the predicted integer ratios. The framework is presented as foundational without a shown derivation from RLCT geometry or LLC in the provided text, and the observables are constructed directly from the framework's posited correlation and identity. This reduces the central claim (DDS as a spectral reading of singular complexity) to consistency with the framework's own assumptions by construction, with empirical slope ratios (2.0, 3.1, 4.0) serving as confirmation rather than independent test. No self-citation chain is involved; the circularity is internal to the framework-observable pairing.
Axiom & Free-Parameter Ledger
axioms (1)
- ad hoc to paper Structural correlation exists between activation-side and Fisher-side spectra at any singular minimum
invented entities (1)
-
dead directions
no independent evidence
Forward citations
Cited by 1 Pith paper
-
Dead-Direction Conditioners: Gauge-Equivariant Preconditioning for Deep Networks
Dead-Direction Conditioners provide gauge-equivariant preconditioning by conditioning optimizer state on symmetry orbits, yielding improved resistance to over-training collapse and higher detection of dead directions ...
Reference graph
Works this paper leans on
-
[1]
M. Aoyagi. Consideration on the learning efficiency of multiple-layered neural networks with linear units. Neural Networks, 172: 0 106132, 2024. URL https://doi.org/10.1016/j.neunet.2024.106132
-
[2]
M. Aoyagi and S. Watanabe. Stochastic complexities of reduced rank regression in B ayesian estimation. Neural Networks, 18 0 (7): 0 924--933, 2005. URL https://doi.org/10.1016/j.neunet.2005.03.014
- [3]
-
[4]
E. Boix-Adsera, E. Littwin, E. Abbe, S. Bengio, and J. Susskind. Transformers learn through gradual rank increase. In Advances in Neural Information Processing Systems (NeurIPS), 2023. URL https://arxiv.org/abs/2306.07042
arXiv 2023
-
[5]
Y. Dong, J.-B. Cordonnier, and A. Loukas. Attention is not all you need: pure attention loses rank doubly exponentially with depth. In International Conference on Machine Learning (ICML), 2021. URL https://arxiv.org/abs/2103.03404
arXiv 2021
-
[6]
Elhage, T
N. Elhage, T. Hume, C. Olsson, N. Nanda, T. Henighan, S. Johnston, S. E. Showk, N. Joseph, N. DasSarma, B. Mann, D. Hernandez, A. Askell, K. Ndousse, A. Jones, D. Drain, A. Chen, Y. Bai, D. Ganguli, L. Lovitt, Z. Hatfield-Dodds, J. Kernion, T. Conerly, S. Kravec, S. Fort, S. Kadavath, J. Jacobson, E. Tran-Johnson, J. Kaplan, J. Clark, T. Brown, S. McCandl...
2022
-
[7]
Eschenhagen, A
R. Eschenhagen, A. Immer, R. E. Turner, F. Schneider, and P. Hennig. K ronecker-factored approximate curvature for modern neural network architectures. In NeurIPS, 2023
2023
- [8]
-
[9]
George, C
T. George, C. Laurent, X. Bouthillier, N. Ballas, and P. Vincent. Fast approximate natural gradient descent in a K ronecker-factored eigenbasis. In NeurIPS, 2018
2018
-
[10]
Ghorbani, S
B. Ghorbani, S. Krishnan, and Y. Xiao. An investigation into neural net optimization via H essian eigenvalue density. In ICML, 2019
2019
-
[11]
R. Grosse and J. Martens. A K ronecker-factored approximate F isher matrix for convolution layers. In ICML, 2016. URL https://arxiv.org/abs/1602.01407
Pith/arXiv arXiv 2016
- [12]
-
[13]
J. Hoogland, G. Wang, M. Farrugia-Roberts, L. Carroll, S. Wei, and D. Murfet. Loss landscape degeneracy and stagewise development in transformers. Transactions on Machine Learning Research, 2024. URL https://arxiv.org/abs/2402.02364
arXiv 2024
-
[14]
N. K. Jha and B. Reagen. NerVE : Nonlinear eigenspectrum dynamics in LLM feed-forward networks. arXiv:2603.06922, 2026
arXiv 2026
-
[15]
Karakida, S
R. Karakida, S. Akaho, and S.-i. Amari. Universal statistics of F isher information in deep neural networks: Mean field approach. In AISTATS, 2019
2019
-
[16]
Karakida, S
R. Karakida, S. Akaho, and S.-i. Amari. Pathological spectra of the F isher information metric and its variants in deep neural networks. Neural Computation, 33 0 (8): 0 2274--2307, 2021
2021
-
[17]
T. X. Khanh, T. Q. Hoa, L. D. Trung, and P. T. Duc. Spectral entropy collapse as an empirical signature of delayed generalisation in grokking. arXiv:2604.13123, 2026
Pith/arXiv arXiv 2026
-
[18]
F. Kunstner, L. Balles, and P. Hennig. Limitations of the empirical F isher approximation for natural gradient descent. In NeurIPS, 2019. URL https://arxiv.org/abs/1905.12558
arXiv 2019
-
[19]
E. Lau, Z. Furman, G. Wang, D. Murfet, and S. Wei. The local learning coefficient: A singularity-aware complexity measure. In AISTATS, 2025. URL https://proceedings.mlr.press/v258/lau25a.html
2025
-
[20]
J. Martens and R. Grosse. Optimizing neural networks with Kronecker -factored approximate curvature. In ICML, 2015. URL https://arxiv.org/abs/1503.05671
arXiv 2015
-
[21]
N. Nanda, L. Chan, T. Lieberum, J. Smith, and J. Steinhardt. Progress measures for grokking via mechanistic interpretability. In ICLR, 2023. URL https://arxiv.org/abs/2301.05217
Pith/arXiv arXiv 2023
-
[22]
L. Noci, S. Anagnostidis, L. Biggio, A. Orvieto, S. P. Singh, and A. Lucchi. Signal propagation in transformers: Theoretical perspectives and the role of rank collapse. In Advances in Neural Information Processing Systems (NeurIPS), 2022. URL https://arxiv.org/abs/2206.03126
arXiv 2022
-
[23]
Pennington and P
J. Pennington and P. Worah. The spectrum of the F isher information matrix of a single-hidden-layer neural network. In NeurIPS, 2018
2018
-
[24]
A. Power, Y. Burda, H. Edwards, I. Babuschkin, and V. Misra. Grokking: Generalization beyond overfitting on small algorithmic datasets. arXiv:2201.02177, 2022
Pith/arXiv arXiv 2022
-
[25]
L. Sagun, U. Evci, V. U. G \"u ney, Y. Dauphin, and L. Bottou. Empirical analysis of the H essian of over-parametrized neural networks. In ICLR Workshop, 2018. arXiv:1706.04454
Pith/arXiv arXiv 2018
-
[26]
T. P. Shirodkar. Dead directions: Geometric singular learning, 2026. URL https://arxiv.org/abs/2606.05957
Pith/arXiv arXiv 2026
-
[27]
T. P. Shirodkar and P. J. Narayanan. Algebraic dead directions in LayerNorm transformers: A forward-pass-only diagnostic at LLM scale, 2026. URL https://arxiv.org/abs/2606.19491
Pith/arXiv arXiv 2026
- [28]
-
[29]
devinterp : A library for developmental interpretability
Timaeus and collaborators. devinterp : A library for developmental interpretability. https://github.com/timaeus-research/devinterp, 2024. Python package
2024
-
[30]
G. Wang, J. Hoogland, S. van Wingerden, Z. Furman, and D. Murfet. Differentiation and specialization of attention heads via the refined local learning coefficient. In International Conference on Learning Representations (ICLR), 2025. URL https://arxiv.org/abs/2410.02984. Spotlight
arXiv 2025
-
[31]
Cambridge Monographs on Applied and Computational Mathematics, vol
S. Watanabe. Algebraic Geometry and Statistical Learning Theory. Cambridge University Press, 2009. URL https://doi.org/10.1017/CBO9780511800474
- [32]
-
[33]
Y. Xu. Spectral edge dynamics of training trajectories: Signal--noise geometry across scales. arXiv:2603.15678, 2026
arXiv 2026
-
[34]
Z. Yao, A. Gholami, K. Keutzer, and M. W. Mahoney. PyHessian : Neural networks through the lens of the H essian. In IEEE BigData, 2020
2020
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.