Multi-Source Prediction-Powered Inference
Pith reviewed 2026-06-26 13:51 UTC · model grok-4.3
The pith
Aggregating multiple pseudo-labeled datasets with weights chosen to minimize asymptotic confidence-region volume produces valid inference whose region is asymptotically as small as the oracle best weighting.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
By estimating aggregation weights that minimize the asymptotic volume of the confidence region formed from multiple pseudo-labeled datasets, the multi-source prediction-powered inference estimator achieves asymptotic normality and produces a confidence-region volume that is asymptotically equivalent to the oracle-optimal volume attainable within the proposed linear weighting class; the same construction yields smaller regions than either classical target-only inference or single-source prediction-powered inference under the conditions characterized in the paper.
What carries the argument
Aggregation weights estimated by minimizing the asymptotic volume of the resulting confidence region; the weights determine how much each pseudo-labeled source contributes to the final estimator while preserving asymptotic validity.
If this is right
- The estimator is asymptotically normal under both homogeneous and heterogeneous source-target distributions.
- The achieved confidence-region volume equals the oracle minimum inside the linear weighting class.
- The method produces strictly smaller regions than target-only inference whenever at least one source carries usable information.
- The method produces strictly smaller regions than any single-source predictor-powered procedure when the optimal weights are interior to the simplex.
- Coverage remains valid even when the sources arise from covariate or domain shift.
Where Pith is reading between the lines
- The same weighting objective could be applied to combine predictions from an arbitrary number of black-box models without retraining them.
- If the volume-minimizing weights concentrate on a small subset of sources, the procedure automatically performs a form of source selection.
- The approach may extend to settings where the target parameter itself is high-dimensional, provided the volume functional can still be estimated consistently.
Load-bearing premise
The asymptotic volume of the confidence region can be written as a function of the weights and estimated consistently from the observed data without introducing bias that invalidates the inference.
What would settle it
A simulation or real-data experiment in which the estimated weights produce a confidence region whose actual coverage falls below the nominal level or whose volume exceeds that of the single-source baseline by more than sampling error.
Figures

read the original abstract
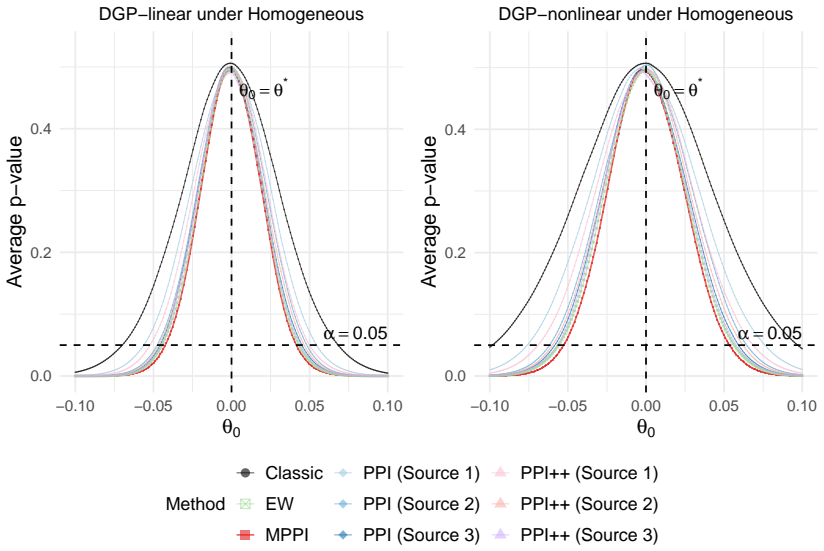
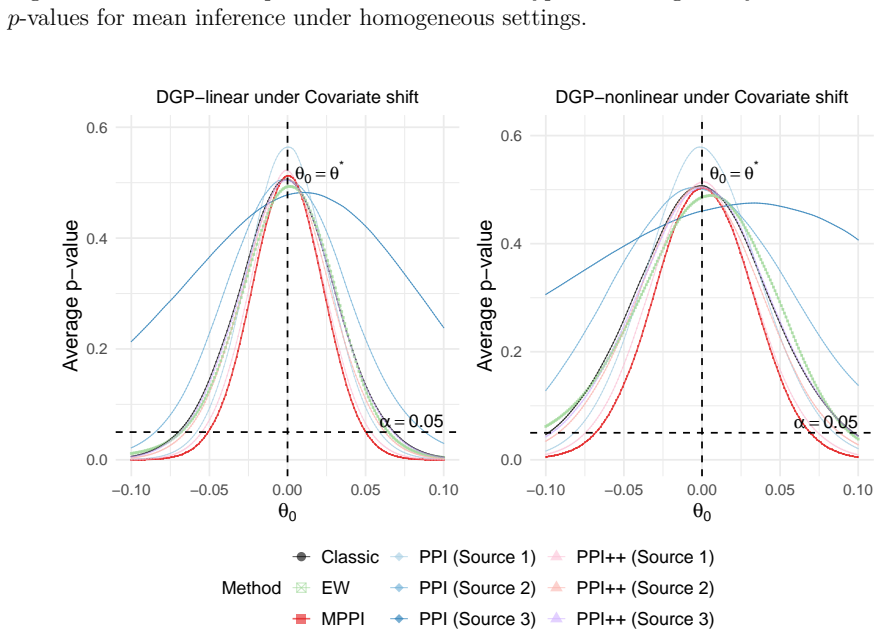
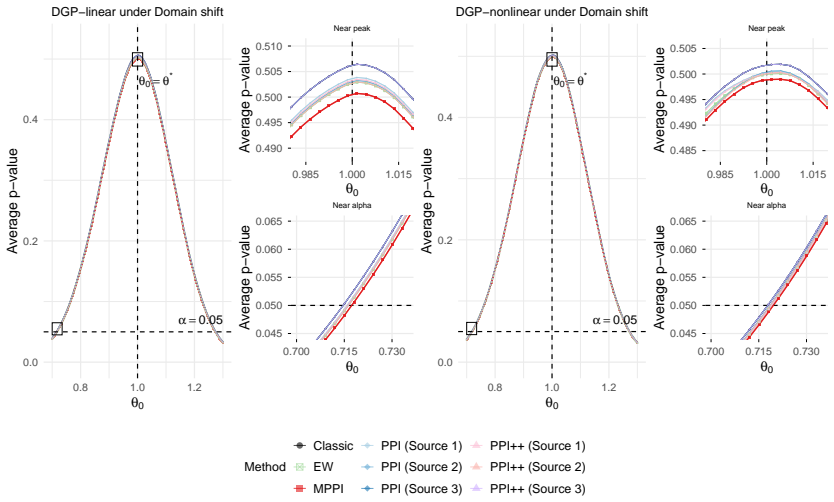
Prediction-powered inference integrates a small gold-standard dataset with large pseudo-labeled data, whose labels are generated by machine learning methods, to enhance statistical inference. In modern applications, multiple data sources and diverse machine learning methods often give rise to multiple pseudo-labeled datasets, each encoding potentially different aspects of the underlying information. However, how to optimally combine multiple data sources and machine learning methods for statistical inference remains unclear. To address this problem, we propose a multi-source prediction-powered inference method by aggregating multiple pseudo-labeled datasets together, where the aggregation weights are estimated by minimizing the asymptotic volume of the resulting confidence region. We study both homogeneous settings, where the source and target distributions coincide, and heterogeneous settings, where distributional discrepancies arise between source and target distributions, including covariate shift and domain shift. Theoretically, we establish the asymptotic normality of the proposed estimator and show that the resulting confidence-region volume is asymptotically equivalent to the oracle optimal volume within the proposed weighting class. We further characterize when our method yields smaller confidence regions compared with both classical target-only inference and single-source prediction-powered inference. Simulation studies and a real-data application on dual-energy X-ray absorptiometry measured high body fat prevalence show that MPPI can reduce confidence-region volume while maintaining inferential validity in the settings considered.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The manuscript proposes a multi-source prediction-powered inference (MPPI) procedure that aggregates multiple pseudo-labeled datasets by estimating aggregation weights via minimization of the asymptotic volume of the resulting confidence region. It establishes asymptotic normality of the aggregated estimator and shows that the achieved confidence-region volume is asymptotically equivalent to the oracle-optimal volume within the proposed weighting class, for both homogeneous settings and heterogeneous settings (covariate shift and domain shift). The method is compared to target-only inference and single-source PPI, with supporting simulation studies and a real-data application on dual-energy X-ray absorptiometry body-fat prevalence.
Significance. If the central asymptotic claims hold under the stated conditions, the work supplies a principled, data-driven extension of prediction-powered inference to multiple sources that can reduce confidence-region volume while retaining validity. The explicit treatment of heterogeneous regimes and the oracle-equivalence result within the weighting class are the primary theoretical contributions; the empirical section provides concrete evidence that the procedure can outperform baselines in the regimes examined.
major comments (2)
- [§3] §3 (weight estimation objective): the asymptotic volume functional that is minimized to obtain the weights is itself a function of plug-in estimators for the relevant variances (and, in heterogeneous cases, density ratios or shift parameters). The manuscript must supply explicit rates on these plug-in estimators (or uniform consistency arguments) showing that their estimation error does not appear in the leading term of the asymptotic distribution of the weighted estimator; without this, the claimed oracle equivalence cannot be verified from the given argument.
- [§4] Theorem establishing oracle equivalence (likely §4): the proof sketch asserts that the estimated weights yield a volume asymptotically equivalent to the oracle volume, but the argument appears to rely on the weight estimator converging sufficiently fast relative to the n^{-1/2} rate of the target estimator. An explicit statement of the required convergence rate (or a uniform law of large numbers that absorbs the weight estimation error) is needed to confirm that no additional bias or variance term arises.
minor comments (2)
- [Simulations] Table 1 and the simulation section: report the exact number of Monte Carlo replications and the precise parameter values used to generate the covariate-shift and domain-shift regimes so that the reported coverage and volume reductions can be reproduced.
- [§2–3] Notation for the estimated weights: introduce a distinct symbol (e.g., ilde{w}) when the weights are data-dependent rather than oracle, to avoid any ambiguity when stating the asymptotic results.
Simulated Author's Rebuttal
We thank the referee for the detailed and constructive report. The two major comments correctly identify places where the current proofs would benefit from additional explicit rates and uniformity arguments to fully justify the oracle-equivalence claim. We will incorporate the requested details in the revision.
read point-by-point responses
-
Referee: [§3] §3 (weight estimation objective): the asymptotic volume functional that is minimized to obtain the weights is itself a function of plug-in estimators for the relevant variances (and, in heterogeneous cases, density ratios or shift parameters). The manuscript must supply explicit rates on these plug-in estimators (or uniform consistency arguments) showing that their estimation error does not appear in the leading term of the asymptotic distribution of the weighted estimator; without this, the claimed oracle equivalence cannot be verified from the given argument.
Authors: We agree that the current argument would be strengthened by explicit rates. In the revised manuscript we will add the required convergence rates for the plug-in estimators of the variances, density ratios, and shift parameters (showing they are o_p(n^{-1/2}) under standard regularity conditions on the ML predictors and the density-ratio estimators). We will also insert a short uniform-consistency lemma establishing that the plug-in error does not enter the leading term of the asymptotic distribution of the weighted estimator. revision: yes
-
Referee: [§4] Theorem establishing oracle equivalence (likely §4): the proof sketch asserts that the estimated weights yield a volume asymptotically equivalent to the oracle volume, but the argument appears to rely on the weight estimator converging sufficiently fast relative to the n^{-1/2} rate of the target estimator. An explicit statement of the required convergence rate (or a uniform law of large numbers that absorbs the weight estimation error) is needed to confirm that no additional bias or variance term arises.
Authors: We accept the need for an explicit rate. The revision will state that the weight estimator converges at rate o_p(1) (which is already implied by the consistency result in §3 but will now be made quantitative) and will include a uniform law of large numbers argument showing that the difference between the estimated-weight and oracle-weight volumes is o_p(n^{-1}). This absorbs the weight-estimation error into the remainder term and confirms the claimed asymptotic equivalence. revision: yes
Circularity Check
No circularity: weight estimation and oracle equivalence rely on standard consistency arguments with external gold-standard data
full rationale
The derivation estimates aggregation weights by minimizing a plug-in estimator of the asymptotic confidence-region volume and proves asymptotic normality plus equivalence to the oracle volume within the weighting class. This is a conventional adaptive procedure whose validity rests on consistency rates for the plug-in quantities (including any density-ratio terms in heterogeneous settings) and the presence of separate gold-standard target data; it does not reduce by construction to the inputs. No self-definitional steps, fitted quantities renamed as predictions, or load-bearing self-citations appear in the abstract or described chain. The result remains falsifiable via the external labeled sample and does not invoke uniqueness theorems or ansatzes from prior author work.
Axiom & Free-Parameter Ledger
free parameters (1)
- aggregation weights
axioms (1)
- domain assumption asymptotic normality of the aggregated estimator holds under the stated homogeneous and heterogeneous regimes
Reference graph
Works this paper leans on
-
[1]
and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I
Angelopoulos, Anastasios N. and Bates, Stephen and Fannjiang, Clara and Jordan, Michael I. and Zrnic, Tijana , title =. Science , volume =
-
[2]
2000 , publisher=
Asymptotic Statistics , author=. 2000 , publisher=
2000
-
[3]
Correcting Sample Selection Bias by Unlabeled Data , volume =
Huang, Jiayuan and Gretton, Arthur and Borgwardt, Karsten and Sch\". Correcting Sample Selection Bias by Unlabeled Data , volume =. Advances in Neural Information Processing Systems , editor =
-
[4]
Annals of the Institute of Statistical Mathematics , volume=
Direct importance estimation for covariate shift adaptation , author=. Annals of the Institute of Statistical Mathematics , volume=. 2008 , publisher=
2008
-
[5]
Journal of Machine Learning Research , volume=
Discriminative learning under covariate shift , author=. Journal of Machine Learning Research , volume=. 2009 , pages=
2009
-
[6]
Angelopoulos, Anastasios N. and Duchi, John C. and Zrnic, Tijana , year =. 2311.01453 , archivePrefix =
-
[7]
Self and Kung-Yee Liang , journal =
Steven G. Self and Kung-Yee Liang , journal =. Asymptotic Properties of Maximum Likelihood Estimators and Likelihood Ratio Tests Under Nonstandard Conditions , urldate =
-
[8]
Shapiro , journal =
A. Shapiro , journal =. Towards a Unified Theory of Inequality Constrained Testing in Multivariate Analysis , urldate =
-
[9]
2017 , url =
Bohn, Sarah and Cuellar Mejia, Marisol , title =. 2017 , url =
2017
-
[10]
Understanding unemployment across
Feasel, Edward M and Rodini, Mark L , journal=. Understanding unemployment across. 2002 , publisher=
2002
-
[11]
Demographic research , volume=
The Great Recession and America’s geography of unemployment , author=. Demographic research , volume=
-
[12]
Cross-prediction-powered inference , journal =
Zrnic, Tijana and Cand. Cross-prediction-powered inference , journal =
-
[13]
Domain Adaptation in Computer Vision Applications , pages =
Sun, Baochen and Feng, Jiashi and Saenko, Kate , title =. Domain Adaptation in Computer Vision Applications , pages =. 2017 , publisher =
2017
-
[14]
Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
Adversarial Discriminative Domain Adaptation , author =. Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition , year =
-
[15]
International Conference on Learning Representations , year =
Seguy, Vivien and Damodaran, Bharath Bhushan and Flamary, Remi and Courty, Nicolas and Rolet, Antoine and Blondel, Mathieu , title =. International Conference on Learning Representations , year =
-
[16]
Proceedings of the 37th International Conference on Machine Learning , series =
Optimal Transport Mapping via Input Convex Neural Networks , author =. Proceedings of the 37th International Conference on Machine Learning , series =. 2020 , publisher =
2020
-
[17]
The Annals of Statistics , number =
Vincent Divol and Jonathan Niles-Weed and Aram-Alexandre Pooladian , title =. The Annals of Statistics , number =
-
[18]
Advances in Neural Information Processing Systems , volume =
Rates of Estimation of Optimal Transport Maps using Plug-in Estimators via Barycentric Projections , author =. Advances in Neural Information Processing Systems , volume =
-
[19]
and Foygel Barber, Rina and Cand
Tibshirani, Ryan J. and Foygel Barber, Rina and Cand. Conformal Prediction Under Covariate Shift , booktitle =
-
[20]
Journal of the American Statistical Association , volume=
Optimal Transport based Cross-Domain Integration for Heterogeneous Data , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
2025
-
[21]
Journal of the American Statistical Association , volume=
Distribution-free prediction intervals under covariate shift, with an application to causal inference , author=. Journal of the American Statistical Association , volume=. 2025 , publisher=
2025
-
[22]
2023 , eprint=
Model-free selective inference under covariate shift via weighted conformal p -values , author=. 2023 , eprint=
2023
-
[23]
Advances in Neural Information Processing Systems , volume=
Optimal aggregation of prediction intervals under unsupervised domain shift , author=. Advances in Neural Information Processing Systems , volume=
-
[24]
Journal of Machine Learning Research , volume=
Covariate shift adaptation by importance weighted cross validation , author=. Journal of Machine Learning Research , volume=
-
[25]
Dataset Shift in Machine Learning , editor=
Covariate shift by kernel mean matching , author=. Dataset Shift in Machine Learning , editor=
-
[26]
Spear.Building Ontologies with Basic Formal Ontology
Semi-Supervised Learning , publisher =. 2006 , month =. doi:10.7551/mitpress/9780262033589.001.0001 , url =
-
[27]
Highly accurate protein structure prediction with
Jumper, John and Evans, Richard and Pritzel, Alexander and Green, Tim and Figurnov, Michael and Ronneberger, Olaf and Tunyasuvunakool, Kathryn and Bates, Russ and. Highly accurate protein structure prediction with. Nature , year =
-
[28]
Science , year =
Combining satellite imagery and machine learning to predict poverty , author =. Science , year =
-
[29]
Least squares model averaging by
Wan, Alan TK and Zhang, Xinyu and Zou, Guohua , journal=. Least squares model averaging by. 2010 , publisher=
2010
-
[30]
Journal of the American Statistical Association , volume =
Unified optimal model averaging with a general loss function based on cross-validation , author=. Journal of the American Statistical Association , volume =. 2025 , publisher=
2025
-
[31]
Journal of the American Statistical Association , volume=
Combining linear regression models: When and how? , author=. Journal of the American Statistical Association , volume=. 2005 , publisher=
2005
-
[32]
2008 , publisher=
Optimal Transport: Old and New , author=. 2008 , publisher=
2008
-
[33]
Nature , volume=
Highly accurate protein structure prediction for the human proteome , author=. Nature , volume=. 2021 , publisher=
2021
-
[34]
Science , volume=
Evolutionary-scale prediction of atomic-level protein structure with a language model , author=. Science , volume=. 2023 , publisher=
2023
-
[35]
2023 , publisher=
Zheng, Zhiling and Zhang, Oufan and Borgs, Christian and Chayes, Jennifer T and Yaghi, Omar M , journal=. 2023 , publisher=
2023
-
[36]
Mathematical Programming , volume=
Proximal alternating linearized minimization for nonconvex and nonsmooth problems , author=. Mathematical Programming , volume=. 2014 , publisher=
2014
-
[37]
Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-
Attouch, H. Proximal alternating minimization and projection methods for nonconvex problems: An approach based on the Kurdyka-. Mathematics of Operations Research , volume=. 2010 , publisher=
2010
-
[38]
Journal of the American Statistical Association , volume =
Xinyu Zhang and Dalei Yu and Guohua Zou and Hua Liang , title =. Journal of the American Statistical Association , volume =. 2016 , publisher =
2016
-
[39]
International Conference on Emerging Systems and Intelligent Computing (ESIC) , pages =
Panda, Amiya Ranjan and Pinnamaraju, Poojith and Tongbram, Alina and Sinha, Amit Kumar and Gourisaria, Mahendra Kumar and Mishra, Manoj Kumar , title =. International Conference on Emerging Systems and Intelligent Computing (ESIC) , pages =. 2025 , publisher =
2025
-
[40]
British Journal of Nutrition , volume=
Body mass index as a measure of body fatness: Age- and sex-specific prediction formulas , author=. British Journal of Nutrition , volume=. 1991 , publisher=
1991
-
[41]
Diabetes Care , volume=
Clinical usefulness of a new equation for estimating body fat , author=. Diabetes Care , volume=. 2012 , publisher=
2012
-
[42]
The American Journal of Clinical Nutrition , volume =
Dympna Gallagher and Steven B Heymsfield and Moonseong Heo and Susan A Jebb and Peter R Murgatroyd and Yoichi Sakamoto , title =. The American Journal of Clinical Nutrition , volume =
-
[43]
Percentage of body fat cutoffs by sex, age, and race-ethnicity in the
Heo, Moonseong and Faith, Myles S and Pietrobelli, Angelo and Heymsfield, Steven B , journal=. Percentage of body fat cutoffs by sex, age, and race-ethnicity in the. 2012 , publisher=
2012
-
[44]
Journal of Machine Learning Research , year =
Xiaonan Hu and Xinyu Zhang , title =. Journal of Machine Learning Research , year =
-
[45]
Journal of Business & Economic Statistics , volume =
Xinyu Zhang and Huihang Liu and Yizheng Wei and Yanyuan Ma , title =. Journal of Business & Economic Statistics , volume =. 2024 , publisher =
2024
-
[46]
2024 , eprint=
Double Debiased Covariate Shift Adaptation Robust to Density-Ratio Estimation , author=. 2024 , eprint=
2024
-
[47]
Jiawei Shan and Zhifeng Chen and Yiming Dong and Yazhen Wang and Jiwei Zhao , year=. 2509.21707 , archivePrefix=
-
[48]
Supplement to ``
Li, Wenhui and Jiang, Fen and Zhang, Xinyu , year =. Supplement to ``
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.