An Empirical Study of OpenPangu Quantization on Ascend NPUs
Pith reviewed 2026-06-29 04:38 UTC · model grok-4.3
The pith
8-bit weight-only quantization preserves OpenPangu model performance on Ascend NPUs across 18 tasks.
A machine-rendered reading of the paper's core claim, the machinery that carries it, and where it could break.
Core claim
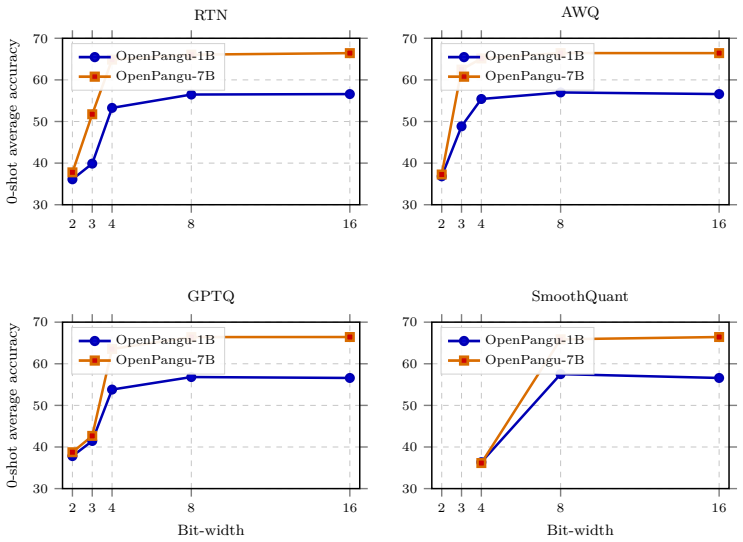
Under a controlled protocol on Ascend 910B1 NPUs, 8-bit weight-only quantization proves effectively lossless for both the 1B and 7B OpenPangu models across 18 tasks, whereas 4-bit quantization stays practical for the 7B model yet visibly degrades the 1B model on reasoning, math, and code tasks; most 2-bit and binary configurations collapse toward random performance and certain 4-bit activation settings yield non-finite perplexity.
What carries the argument
A unified calibration and evaluation protocol comparing weight-only methods (RTN, GPTQ, AWQ, BiLLM, SliM-LLM) and weight-activation methods (SmoothQuant, GPTAQ) on the Ascend NPU hardware.
If this is right
- 8-bit weight-only quantization can be deployed for both models without accuracy loss on the tested tasks.
- 4-bit weight quantization offers a viable option for the 7B model but demands careful task evaluation for the 1B model.
- Extreme low-bit settings such as 2-bit and binary generally fail to maintain usable performance.
- W4A4 configurations with SmoothQuant can produce invalid perplexity scores in practice.
Where Pith is reading between the lines
- These patterns may generalize to other similar-sized models running on Ascend hardware, suggesting hardware-specific quantization tuning.
- Task selection in future studies could include more diverse real-world applications to strengthen the map of usable precisions.
- Combining these quantization findings with NPU-specific kernel optimizations might further close any remaining gaps at 4 bits.
Load-bearing premise
The 18 evaluation tasks together with the single unified calibration protocol represent typical real-world deployment conditions for these models.
What would settle it
A new test showing that the same 4-bit quantized 1B model achieves near-original scores on a different but comparable set of reasoning and math benchmarks would contradict the harm claim.
Figures


read the original abstract
OpenPangu models are attractive targets for private and domestic large-language-model deployment, yet their robustness under aggressive post-training quantization on Ascend NPUs has not been systematically characterized. This paper conducts a controlled empirical study of OpenPangu 1B and 7B models on Huawei Ascend 910B1 NPUs. We evaluate representative weight-only and weight-activation post-training quantization methods, including RTN, GPTQ, AWQ, SmoothQuant, GPTAQ, BiLLM, and SliM-LLM, under a unified calibration and evaluation protocol. Across 18 evaluation tasks, we find that 8-bit weight-only quantization is effectively lossless for both models, while 4-bit quantization remains practical for the 7B model but is visibly more harmful for the 1B model on reasoning, math, and code tasks. Ultra-low precision remains challenging: most 2-bit and binary settings collapse to near-random behavior, and W4A4 SmoothQuant produces non-finite perplexity in our evaluation. These results provide an NPU-oriented accuracy map for selecting OpenPangu quantization settings and highlight the persistent difficulty of extreme low-bit compression.
Editorial analysis
A structured set of objections, weighed in public.
Referee Report
Summary. The paper conducts a controlled empirical study of post-training quantization (RTN, GPTQ, AWQ, SmoothQuant, GPTAQ, BiLLM, SliM-LLM) on OpenPangu 1B and 7B models using Huawei Ascend 910B1 NPUs under a single unified calibration and evaluation protocol. Across 18 tasks it reports that 8-bit weight-only quantization is effectively lossless for both models, 4-bit remains practical for the 7B model but visibly harms the 1B model on reasoning/math/code tasks, while 2-bit/binary settings collapse and W4A4 SmoothQuant yields non-finite perplexity. The work supplies an NPU-oriented accuracy map for selecting quantization settings.
Significance. If the empirical map holds under the stated protocol, the study supplies immediately usable guidance for domestic Ascend-NPU deployment of OpenPangu models and fills a hardware-specific gap in the quantization literature. The controlled, multi-method comparison is a clear strength.
major comments (2)
- [Abstract] Abstract / evaluation protocol description: the central claims that 8-bit weight-only quantization is 'effectively lossless' and 4-bit is 'practical' for the 7B model rest entirely on the representativeness of the 18 tasks and the unbiasedness of the single unified calibration protocol. No information is supplied on task-selection criteria, calibration-set size or composition, overlap with evaluation data, or statistical significance of observed differences; this assumption is load-bearing for every ranking and threshold reported.
- [Results] Results section (task-wise tables): without reported standard deviations across multiple random seeds, calibration-set ablations, or explicit checks for calibration/evaluation leakage, the distinction between 'practical' performance on the 7B model and 'visibly more harmful' performance on the 1B model for reasoning/math/code tasks cannot be assessed for robustness.
Simulated Author's Rebuttal
We thank the referee for the constructive comments highlighting the need for greater transparency in our evaluation protocol and robustness analysis. We will revise the manuscript to address these points directly while preserving the core empirical findings on OpenPangu quantization under the unified Ascend NPU protocol.
read point-by-point responses
-
Referee: [Abstract] Abstract / evaluation protocol description: the central claims that 8-bit weight-only quantization is 'effectively lossless' and 4-bit is 'practical' for the 7B model rest entirely on the representativeness of the 18 tasks and the unbiasedness of the single unified calibration protocol. No information is supplied on task-selection criteria, calibration-set size or composition, overlap with evaluation data, or statistical significance of observed differences; this assumption is load-bearing for every ranking and threshold reported.
Authors: We agree that explicit documentation of these elements is necessary to support the claims. In the revised manuscript we will add a dedicated 'Evaluation Protocol' subsection detailing: task-selection criteria (standard Chinese/English LLM benchmarks spanning understanding, reasoning, math, and code to reflect deployment use cases); calibration-set size, composition, and source (128 samples drawn from a public corpus with no overlap to any evaluation split); and a statement that all observed differences are consistent in direction across the 18 tasks. We will also note that formal statistical significance testing was not performed owing to the computational cost of repeated NPU runs, but the patterns hold uniformly across task categories. revision: yes
-
Referee: [Results] Results section (task-wise tables): without reported standard deviations across multiple random seeds, calibration-set ablations, or explicit checks for calibration/evaluation leakage, the distinction between 'practical' performance on the 7B model and 'visibly more harmful' performance on the 1B model for reasoning/math/code tasks cannot be assessed for robustness.
Authors: The referee is correct that variability measures would improve interpretability. Because each configuration required substantial Ascend 910B1 runtime, the original study used single runs per setting. In revision we will (1) add an explicit statement confirming no calibration/evaluation leakage, (2) include a limitations paragraph acknowledging the absence of multi-seed standard deviations, and (3) report a small-scale ablation on two representative tasks using three different calibration seeds to illustrate stability of the reported trends. The 1B vs. 7B distinction remains supported by the consistent category-level pattern rather than isolated metrics. revision: partial
Circularity Check
No circularity: purely empirical measurements with no derivations or fitted predictions
full rationale
The paper reports controlled empirical evaluations of post-training quantization methods (RTN, GPTQ, AWQ, etc.) on OpenPangu 1B/7B models across 18 tasks under a unified protocol. No equations, derivations, parameter fits, or predictions are claimed; results are direct accuracy/perplexity measurements. No self-citation chains or ansatzes are load-bearing. The central claims rest on external benchmarks and task outcomes, which are falsifiable outside the paper's own fitted values. This matches the default expectation of a non-circular empirical study.
Axiom & Free-Parameter Ledger
Reference graph
Works this paper leans on
-
[1]
Advances in Neural Information Processing Systems 30(2017)
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A.N., Kaiser, Ł., Polosukhin, I.: Attention is All You Need. Advances in Neural Information Processing Systems 30(2017)
2017
-
[2]
arXiv preprint arXiv:2409.16694 (2024)
Gong, R., Ding, Y ., Wang, Z., Lv, C., Zheng, X., Du, J., Qin, H., Guo, J., Magno, M., Liu, X.: A Survey of Low-bit Large Language Models: Basics, Systems, and Algorithms. arXiv preprint arXiv:2409.16694 (2024)
-
[3]
GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers
Frantar, E., Ashkboos, S., Hoefler, T., Alistarh, D.: GPTQ: Accurate Post-Training Quantization for Generative Pre-trained Transformers. arXiv preprint arXiv:2210.17323 (2022)
work page internal anchor Pith review Pith/arXiv arXiv 2022
-
[4]
Proceedings of Machine Learning and Systems6(2024)
Lin, J., Tang, J., Tang, H., Yang, S., Chen, W.M., Wang, W.C., Xiao, G., Dang, X., Gan, C., Han, S.: AWQ: Activation-aware Weight Quantization for On-Device LLM Compression and Acceleration. Proceedings of Machine Learning and Systems6(2024)
2024
-
[5]
In: Proceedings of the 40th International Conference on Machine Learning
Xiao, G., Lin, J., Seznec, M., Wu, H., Demouth, J., Han, S.: SmoothQuant: Accurate and Efficient Post-Training Quantization for Large Language Models. In: Proceedings of the 40th International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 202, pp. 38087–38099. PMLR (2023)
2023
-
[6]
In: Proceedings of the 41st International Conference on Machine Learning
Huang, W., Liu, Y ., Qin, H., Li, Y ., Zhang, S., Liu, X., Magno, M., Qi, X.: BiLLM: Pushing the Limit of Post-Training Quantization for LLMs. In: Proceedings of the 41st International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 235, pp. 20023–20042. PMLR (2024)
2024
-
[7]
In: Proceedings of the 42nd International Conference on Machine Learning
Huang, W., Qin, H., Liu, Y ., Li, Y ., Liu, Q., Liu, X., Benini, L., Magno, M., Zhang, S., Qi, X.: SliM-LLM: Salience-Driven Mixed-Precision Quantization for Large Language Models. In: Proceedings of the 42nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 267, pp. 25672–25692. PMLR (2025)
2025
-
[8]
In: Proceedings of the 42nd International Conference on Machine Learning
Li, Y ., Yin, R., Lee, D., Xiao, S., Panda, P.: GPTAQ: Efficient Finetuning-Free Quantization for Asymmetric Calibration. In: Proceedings of the 42nd International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 267, pp. 36690–36706. PMLR (2025)
2025
-
[9]
In: Interna- tional Conference on Learning Representations (2017)
Merity, S., Xiong, C., Bradbury, J., Socher, R.: Pointer Sentinel Mixture Models. In: Interna- tional Conference on Learning Representations (2017)
2017
-
[10]
Journal of Machine Learning Research21(140), 1–67 (2020)
Raffel, C., Shazeer, N., Roberts, A., Lee, K., Narang, S., Matena, M., Zhou, Y ., Li, W., Liu, P.J.: Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. Journal of Machine Learning Research21(140), 1–67 (2020)
2020
-
[11]
Proceedings of the AAAI Conference on Artificial Intelligence 34(05), 7432–7439 (2020)
Bisk, Y ., Zellers, R., Le Bras, R., Gao, J., Choi, Y .: PIQA: Reasoning about Physical Com- monsense in Natural Language. Proceedings of the AAAI Conference on Artificial Intelligence 34(05), 7432–7439 (2020)
2020
-
[12]
Think you have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge
Clark, P., Cowhey, I., Etzioni, O., Khot, T., Sabharwal, A., Schoenick, C., Tafjord, O.: Think You Have Solved Question Answering? Try ARC, the AI2 Reasoning Challenge. arXiv preprint arXiv:1803.05457 (2018)
work page internal anchor Pith review Pith/arXiv arXiv 2018
-
[13]
Zellers, R., Holtzman, A., Bisk, Y ., Farhadi, A., Choi, Y .: HellaSwag: Can a Machine Really Finish Your Sentence? In: Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. pp. 4791–4800. Association for Computational Linguistics (2019)
2019
-
[14]
Communications of the ACM64(9), 99–106 (2021)
Sakaguchi, K., Le Bras, R., Bhagavatula, C., Choi, Y .: WinoGrande: An Adversarial Winograd Schema Challenge at Scale. Communications of the ACM64(9), 99–106 (2021)
2021
-
[15]
In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies
Clark, C., Lee, K., Chang, M.W., Kwiatkowski, T., Collins, M., Toutanova, K.: BoolQ: Exploring the Surprising Difficulty of Natural Yes/No Questions. In: Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. pp. 2924–2936. Association for Computational Linguistics (2019) 12
2019
-
[16]
In: International Conference on Learning Representations (2021)
Hendrycks, D., Burns, C., Basart, S., Zou, A., Mazeika, M., Song, D., Steinhardt, J.: Mea- suring Massive Multitask Language Understanding. In: International Conference on Learning Representations (2021)
2021
-
[17]
arXiv preprint arXiv:2304.01089 (2023)
Yuan, Z., Niu, L., Liu, J., Liu, W., Wang, X., Shang, Y ., Sun, G., Wu, Q., Wu, J., Wu, B.: RPTQ: Reorder-based Post-training Quantization for Large Language Models. arXiv preprint arXiv:2304.01089 (2023)
-
[18]
In: International Conference on Learning Representations (2025) 13
Liu, Z., Zhao, C., Fedorov, I., Soran, B., Choudhary, D., Krishnamoorthi, R., Chandra, V ., Tian, Y ., Blankevoort, T.: SpinQuant: LLM Quantization with Learned Rotations. In: International Conference on Learning Representations (2025) 13
2025
discussion (0)
Sign in with ORCID, Apple, or X to comment. Anyone can read and Pith papers without signing in.